Download Google Image search results with free proxies

Project description
Download Google Image search results with free proxies
pip install gimagedownload
First step
Create a proxy pkl file using [freeproxydownloader](freeproxydownloader · PyPI)
If you have already installed [site2hdd](site2hdd · PyPI) (before 2023-01-24 , you need to update it)
pip install --upgrade site2hdd
or
pip install --upgrade gimagedownload
from site2hdd import download_url_list,get_proxies,download_webpage
xlsxfile,pklfile = get_proxies(
save_path_proxies_all_filtered='c:\\newfilepath\\myproxiefile\\proxy', # path doesn't have to exist, it will be created, last
# part (proxy) is the name of the file - pkl and xlsx will be added
# important: There will be 2 files, in this case: c:\\newfilepath\\myproxiefile\\proxy.pkl and c:\\newfilepath\\myproxiefile\\proxy.xlsx
http_check_timeout=4, # if proxy can't connect within 4 seconds to wikipedia, it is invalid
threads_httpcheck=50, # threads to check if the http connection is working
threads_ping=100 , # before the http test, there is a ping test to check if the server exists
silent=False, # show results when a working server has been found
max_proxies_to_check=20000, # stops the search at 20000
)
CLI
#You can download the pictures using the command line:
python "C:\Users\Gamer\anaconda3\envs\dfdir\Lib\site-packages\gimagedownload\__init__.py" -p c:\newfilepath\myproxiefile\proxy.pkl -s house,elephant,lion -d f:\googleimgdownload -v 3 -t 50 -r 7 -q 9
#Underlines are converted to space
python "C:\Users\Gamer\anaconda3\envs\dfdir\googleimgs.py" -p c:\newfilepath\myproxiefile\proxy.pkl -s brazilian_food,ferrari,Los_Angeles -d f:\googleimgdownload -v 3 -t 50 -r 7 -q 9
CLI Arguments
#arguments:
-p / --proxy_pickle_file
The proxy pkl file created with freeproxydownloader
# pip install freeproxydownloader
-s / --search
Search terms separated by comma: house,elephant,lion
-d / --download_folder
Download folder, will be created if it doesn't exist
default: os.path.join(os.getcwd(), "GOOGLE_IMAGE_DOWNLOADS")
-v / --variations
Grab links from slightly different search terms
dog/DoG/Dog/doG (only uppercase/lowercase variations)
with different proxies. Don't exaggerate. It might get very slow, but it helps to get more results. 3 or 4 is a good start
default = 3
-t / --threads
How many requests threads
default = 50
-r / --requests_timeout
Timeout in seconds for requests
default = 7
-q / --thread_timeout
Timeout in seconds for running thread. It should be higher than the timeout for requests to avoid problems.
default = 9
Import the function
from gimagedownload import start_image_download
start_image_download(
ProxyPickleFile=r'c:\newfilepath\myproxiefilexxx\proxy.pkl', # pip install freeproxydownloader
search_terms=['halloween'],
download_folder=r'f:\googleimgdownload',
search_variations=3,
threadlimit=50,
RequestsTimeout=7,
ThreadTimeout=9,
)
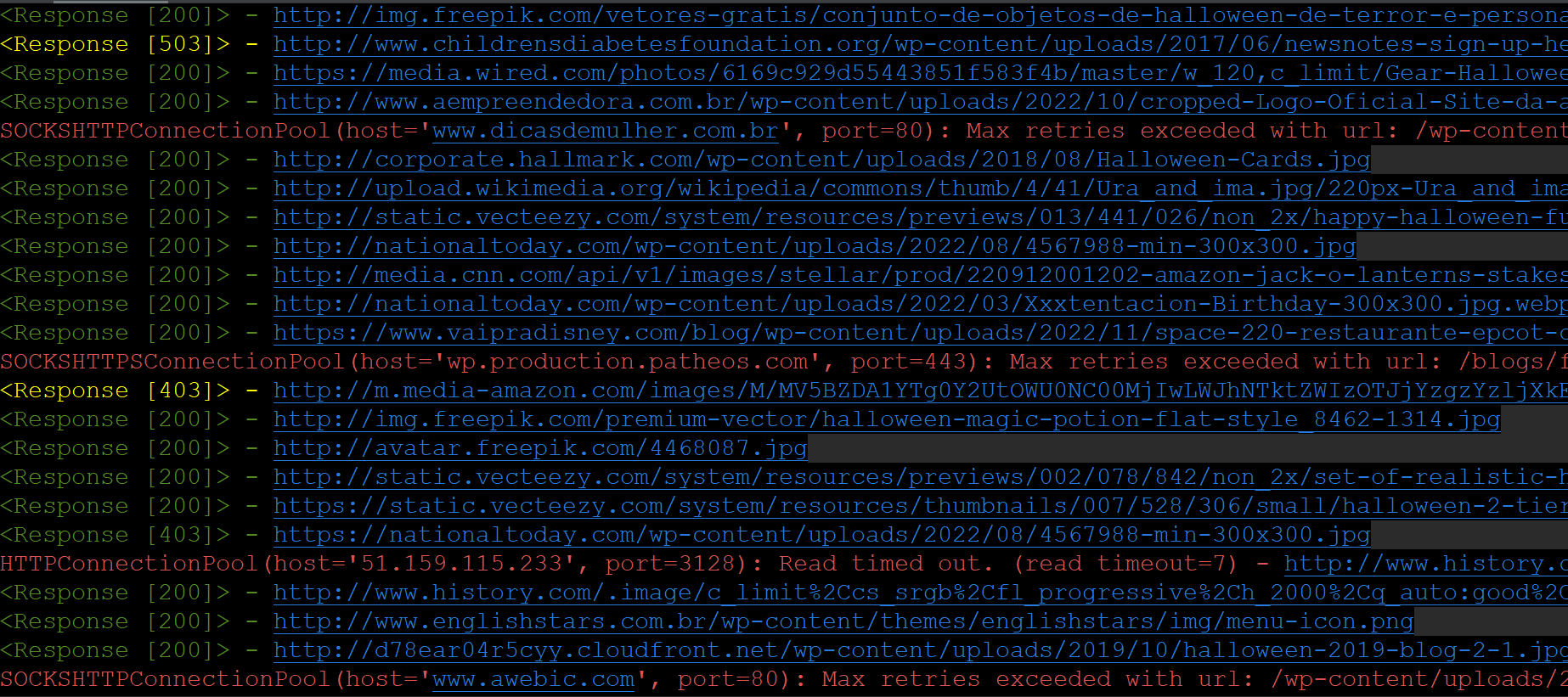
Results "brazilian_food"
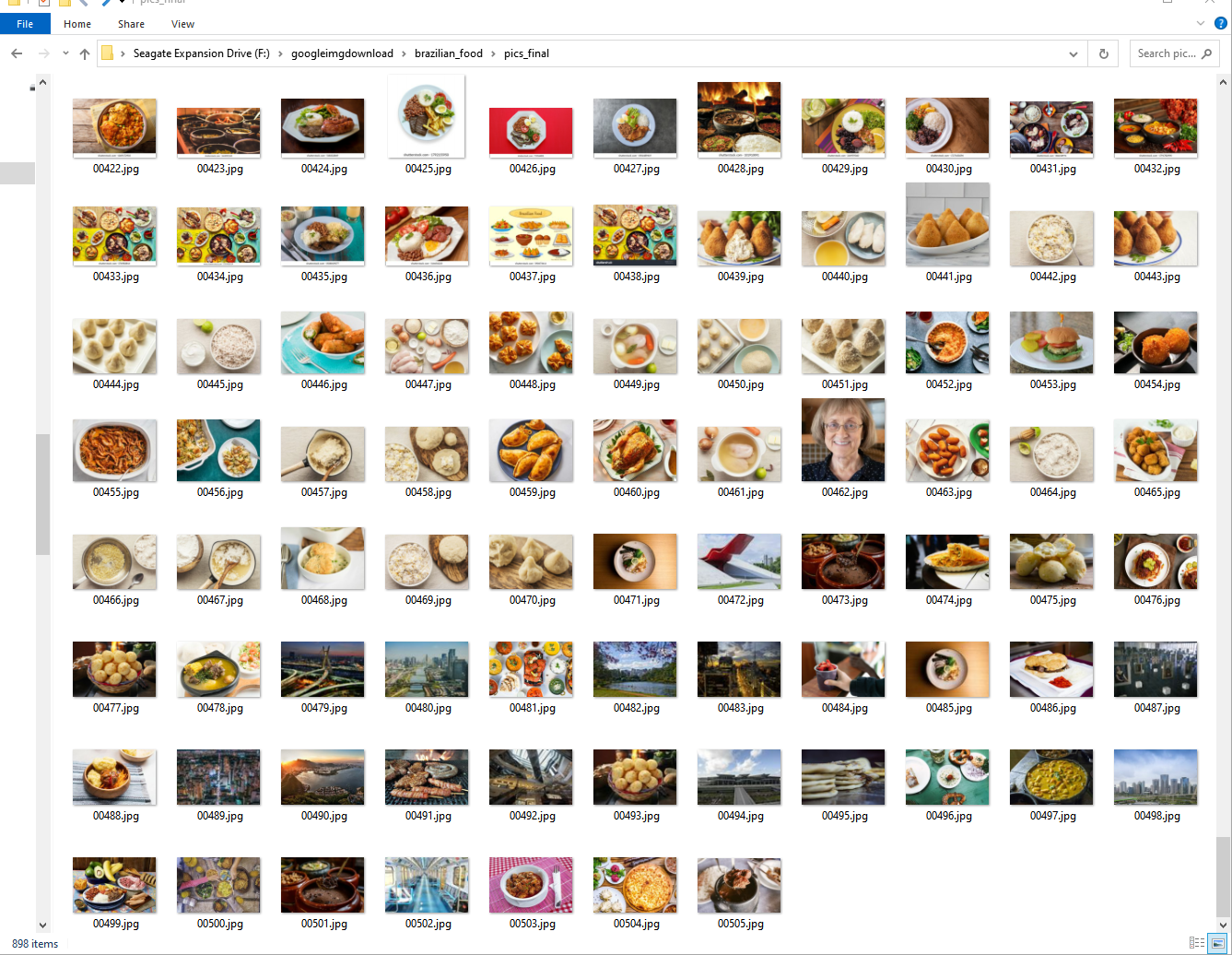
Results "elephant"
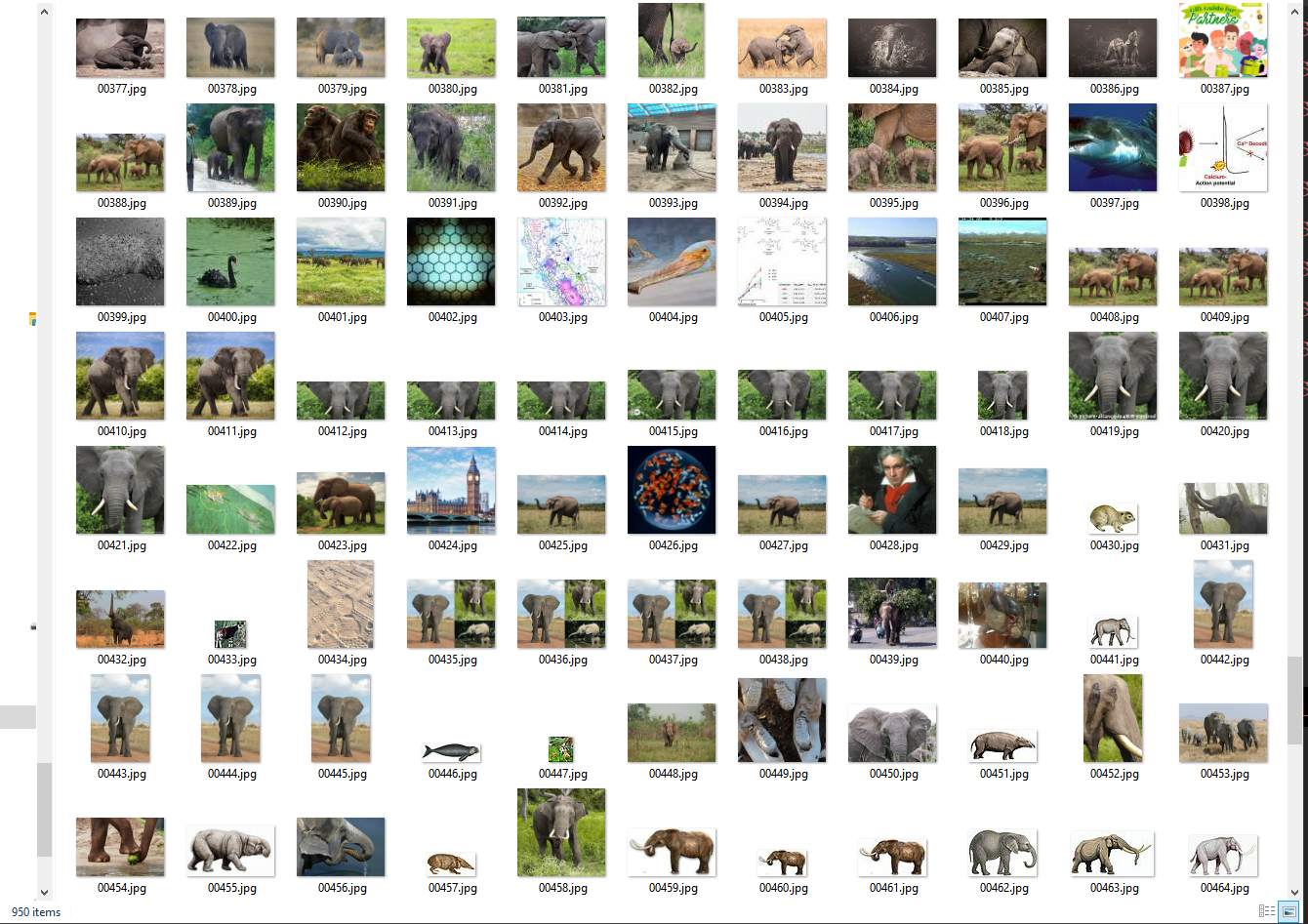
Results "ferrari"
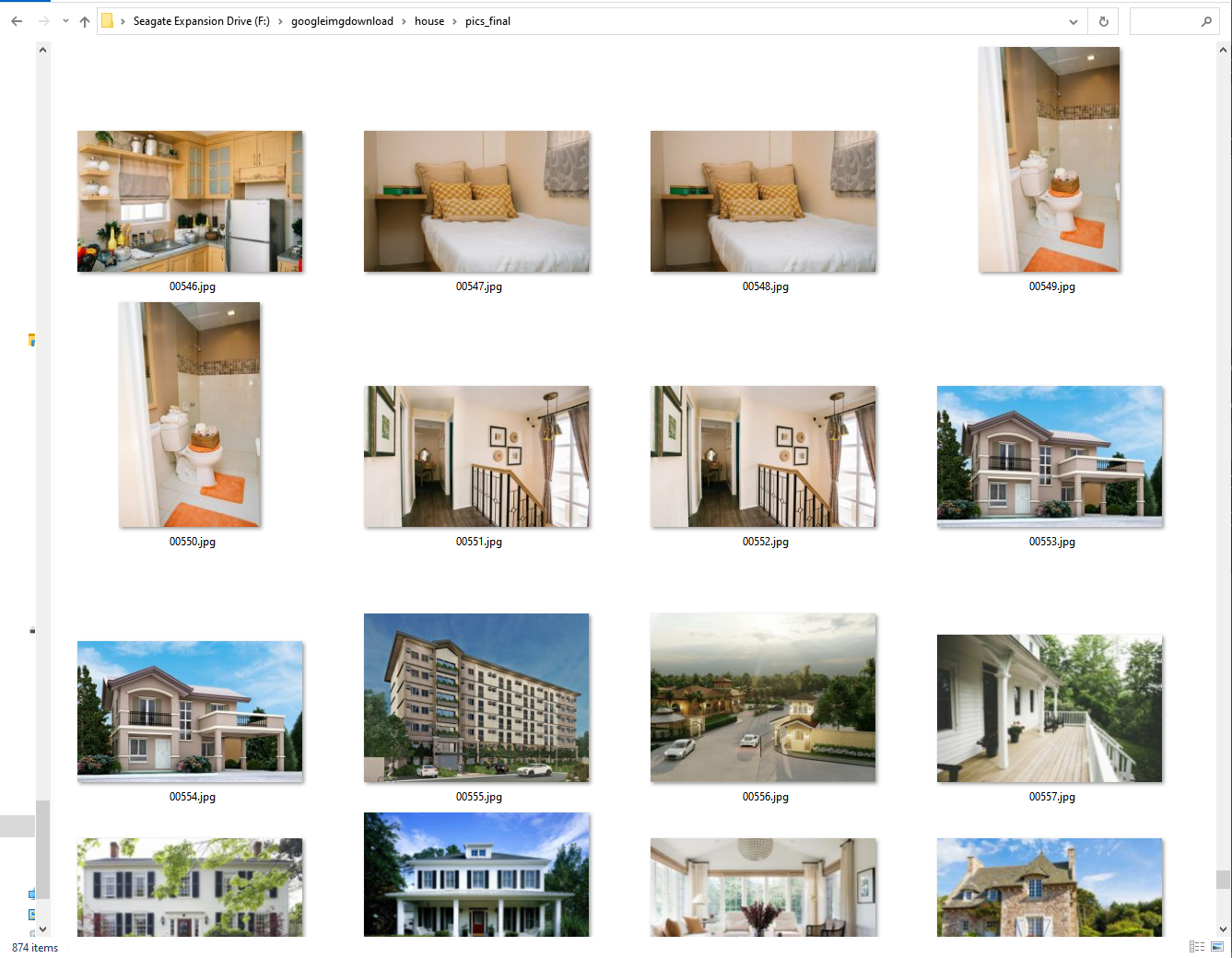
Results "house"
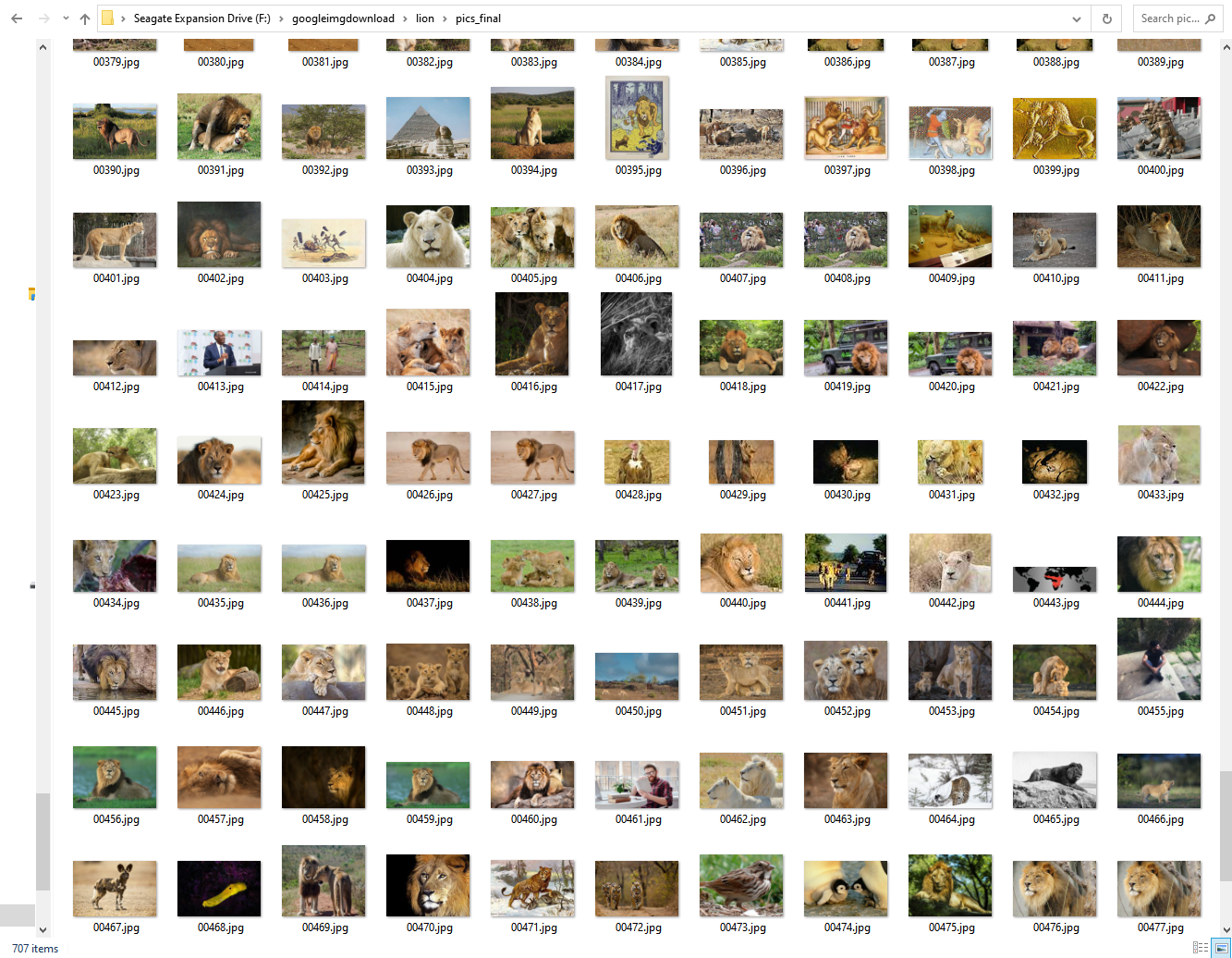
Results "lion"
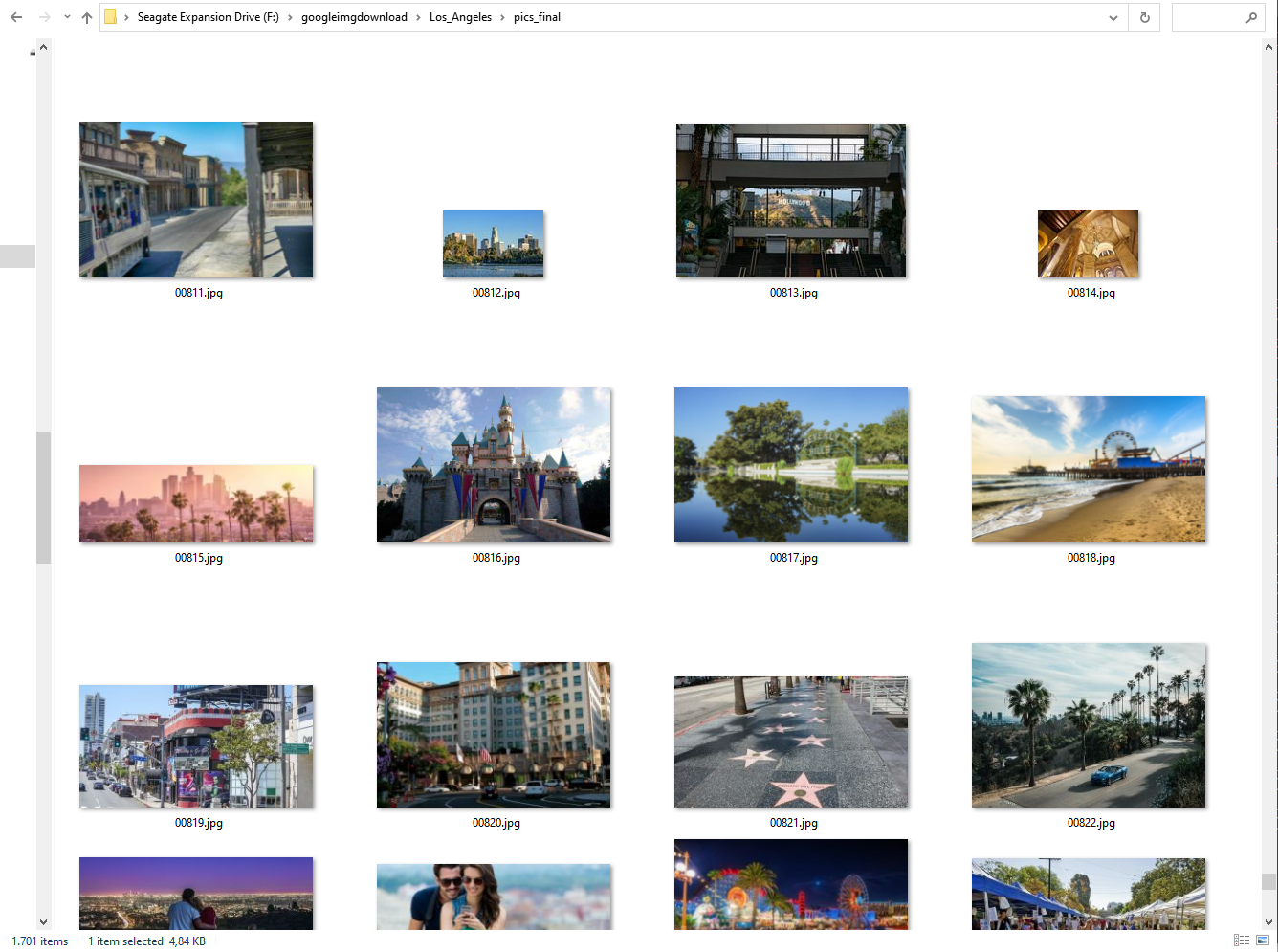
Results "los_angeles"
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
gimagedownload-0.10.tar.gz
(7.9 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gimagedownload-0.10.tar.gz.
File metadata
- Download URL: gimagedownload-0.10.tar.gz
- Upload date:
- Size: 7.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d9fdb3827bdf054e6f76471ca58c213cd7f23fb4549f8febc8b4c35c6b8d34d3
|
|
| MD5 |
db812d0d898bc38234d4c64a9be90093
|
|
| BLAKE2b-256 |
1201af67a3ccca305141c4385ca400dbeafbe4e48e000a782bc27163626e6931
|
File details
Details for the file gimagedownload-0.10-py3-none-any.whl.
File metadata
- Download URL: gimagedownload-0.10-py3-none-any.whl
- Upload date:
- Size: 9.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
829d707888391a994ae6458e371723b2eafa6200599ca8c7845c00d1b7449c88
|
|
| MD5 |
66a7f9d58e3f423e6fb8c1a9cd4d78ce
|
|
| BLAKE2b-256 |
c3bd4151c941a12fe058e13d7b98e3d50b61d4e42ba6e8c036ac59189f5989b7
|







