A package for fast bayesian inference of expensive Likelihoods

Project description
- Source:
- Documentation:
- License:
LGPL + mandatory bug reporting asap + mandatory arXiv’ing of publications using it (see LICENSE for exceptions). The documentation is licensed under the GFDL.
- Support:
For questions drop me an email. For issues/bugs please use GitHub’s Issues.
- Installation:
pip install gpry (for MPI and nested samplers, see here)
GPry is a drop-in alternative to traditional Monte Carlo samplers (such as MCMC or Nested Sampling), for likelihood-based inference. It is aimed at speeding up posterior exploration and inference of marginal quantities from computationally expensive likelihoods, reducing the cost of inference by a factor of 100 or more.
GPry can be installed with pip (python -m pip install gpry), and needs only a callable likelihood and some bounds:
def log_likelihood(x, y):
return [...]
bounds = [[..., ...], [..., ...]]
from gpry import Runner
runner = Runner(log_likelihood, bounds, checkpoint="output/")
runner.run()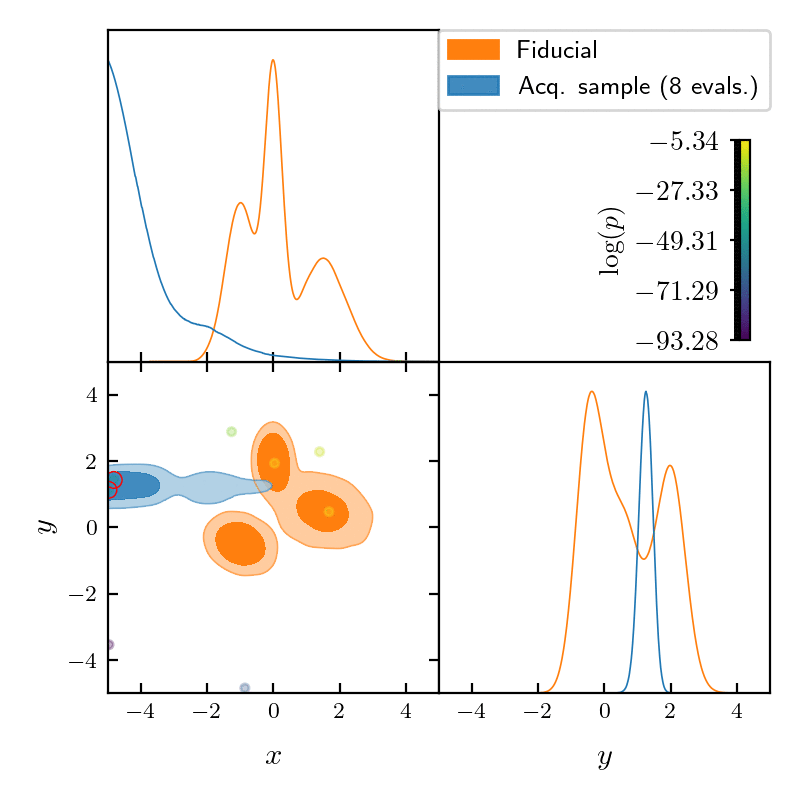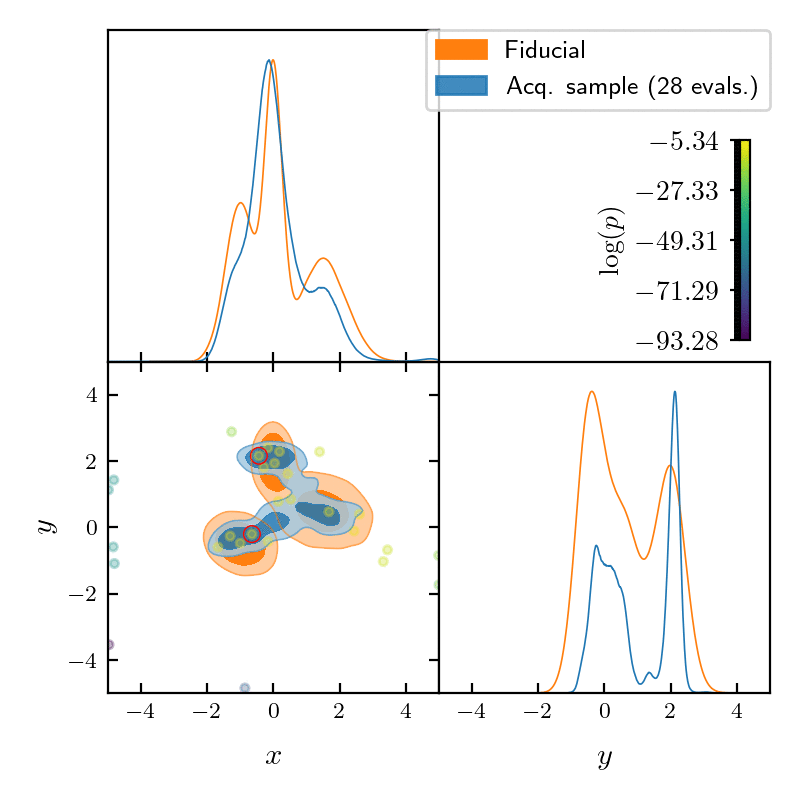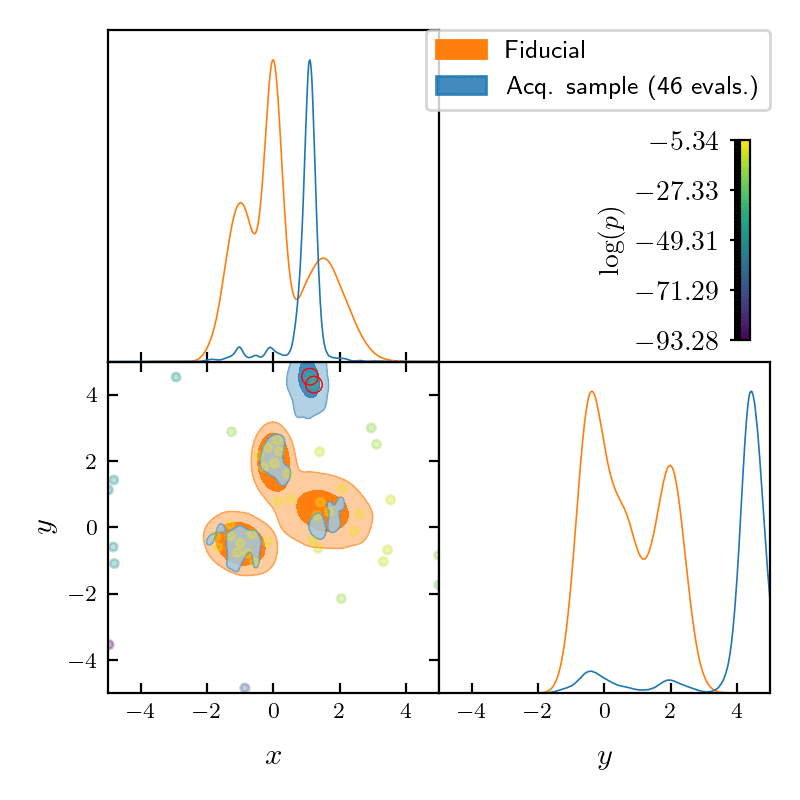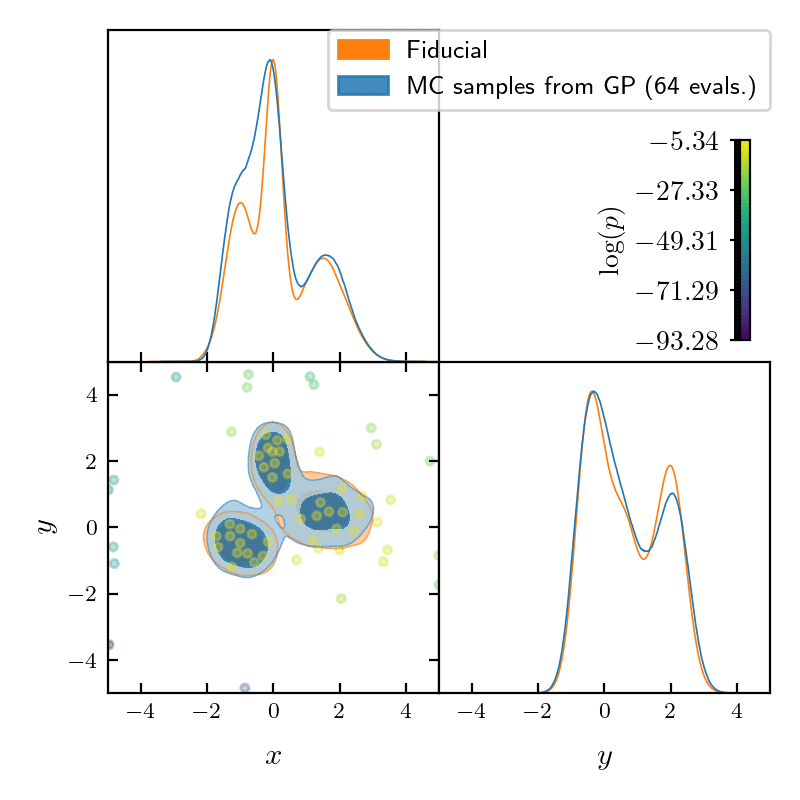
An interface to the Cobaya sampler is available, for richer model especification, and direct access to some physical likelihood pipelines.
GPry was developed as part of J. El Gammal’s M.Sc. and Ph.D. thesis projects.
How it works
GPry uses a Gaussian Process (GP) to create an interpolating model of the log-posterior density function, using as few evaluations as possible. It achieves that using active learning: starting from a minimal set of training samples, the next ones are chosen so that they maximise the information gained on the posterior shape. For more details, see section How GPry works of the documentation, and check out the GPry papers (see below).
GPry introduces some innovations with respect to previous similar approaches:
It imposes weakly-informative priors on the target function, based on a comparison with an n-dimensional Gaussian, and uses that information e.g. for convergence metrics, balancing exploration vs. exploitation, etc.
It introduces a parallelizable batch acquisition algorithm (NORA) which increases robustness, reduces overhead and enables the evaluation of the likelihood/posterior in parallel using multiple cores.
Complementing the GP model, it implements an SVM classifier that learns the shape of uninteresting regions, where proposal are discarded, wherever the value of the likelihood is very-low (for increased efficiency) or undefined (for increased robustness).
At the moment, GPry utilizes a modification of the CPU-based scikit-learn GP implementation.
What kinds of likelihoods/posteriors should work with GPry?
Non-stochastic log-probability density functions, smooth up to a small amount of (deterministic) numerical noise (less than 0.1 in log posterior).
Large evaluation times, so that the GPry overhead is subdominant with respect to posterior evaluation. How slow depends on the number of dimensions and expected shape of the posterior distribution but as a rule of thumb, if an MCMC takes longer to converge than you’re willing to wait you should give it a shot.
The parameter space needs to be low-dimensional (less than 20 as a rule of thumb). In higher dimensions you might still gain considerable improvements in speed if your likelihood is sufficiently slow but the computational overhead of the algorithm increases considerably.
What may not work so well:
Highly multimodal posteriors, especially if the separation between modes is large.
Highly non-Gaussian posteriors, that would not be well modelled by orthogonal constant correlation lengths.
GPry is under active developing, in order to mitigate some of those issues, so look out for new versions!
It does not work!
Please check out the Strategy and Troubleshooting page, or get in touch for issues or more general discussions.
What to cite
If you use GPry, please cite the following papers:
arXiv:2211.02045 for the core algorithm.
arXiv:2305.19267 for the NORA Nested-Sampling acquisition engine.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gpry-3.0.0.tar.gz.
File metadata
- Download URL: gpry-3.0.0.tar.gz
- Upload date:
- Size: 214.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
01e1e9f4fda542303bc172a04bbcd021aff683fce94b244fbf2f6e40fa15ef40
|
|
| MD5 |
cbcbd66c94155696078c43922cb2bf2d
|
|
| BLAKE2b-256 |
46999b3042a4af091a1c3e462d5a366e1050787520f5a05bfbc062d83b2db985
|
File details
Details for the file gpry-3.0.0-py3-none-any.whl.
File metadata
- Download URL: gpry-3.0.0-py3-none-any.whl
- Upload date:
- Size: 196.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fd01980741bf13a25e86dff4a9e1926e5c611f1bf5b07ec64b9ddcddcbe34f15
|
|
| MD5 |
90cc06343c9c0225efb269bdacb5c5c2
|
|
| BLAKE2b-256 |
862e79e6c9e5b0d509cecad12acf09f76ccdb461879892836b1b3cf49d79e114
|







