PyTorch training estimator plugin — benchmark locally, estimate full training cost/time/CO₂, compare against Crusoe Cloud GPUs

Project description
Green Love 💚
A PyTorch plugin that benchmarks your training loop locally, estimates total training time, electricity cost, and CO₂ emissions, then compares against all Crusoe Cloud GPU options — presented in a polished interactive HTML report.
The motivation for this project originated from a Crusoe workshop, where we got insight into the company's mission and how its infrastructure operates using 100% renewable energy sources. Our team found this concept both inspiring and highly practical — beneficial for users while also reducing environmental impact.
Our goal is to make this idea accessible to a wider audience by providing a tool that helps users save time and resources while making more environmentally conscious decisions.
This plugin uses data in very smart ways — it samples only a tiny fraction of your dataset and epochs, then leverages linear scaling laws and statistical inference to accurately predict full-training costs, time, and carbon emissions without ever running the full workload.
What It Does
Green Love takes your existing PyTorch training loop and provides:
- Estimated total training time with confidence intervals
- Estimated electricity cost based on your location
- Estimated CO₂ emissions during training
- Crusoe Cloud GPU comparisons — estimated time, cost, and CO₂ for each available GPU
- Savings overview — how much time, money, and carbon you save by switching to Crusoe Cloud
- Interactive HTML dashboard with all metrics visualized
Recommended Models
Our estimator is designed for models whose training time scales linearly with respect to both the number of data samples and the number of epochs. This covers the vast majority of machine learning models — essentially any architecture trained with some variant of Gradient Descent or Stochastic Gradient Descent (SGD), where each iteration processes a fixed amount of computation per sample.
| Architecture | Why It Works |
|---|---|
| Linear / Logistic Regression | Fixed per-sample cost with SGD |
| MLPs (Feedforward NNs) | Constant cost per sample per epoch |
| CNNs (ResNet, VGG, EfficientNet, etc.) | Fixed conv ops per sample |
| RNNs / LSTMs / GRUs (fixed seq length) | Constant per-sample cost |
| Transformers (fixed seq length) | Fixed attention cost per sample |
| Fine-tuning (BERT, GPT, etc.) | Standard SGD/Adam iteration |
Not recommended for: variable-length Transformers, Graph Neural Networks, KNN/kernel methods, models with dynamic computation graphs.
Installation
pip install green-love
Or install from source:
git clone <repo-url>
cd green-love
pip install -e ".[dev]"
Requirements
- Python ≥ 3.9
- PyTorch ≥ 2.0
- NVIDIA GPU with drivers (for power monitoring via NVML)
jinja2,requests,nvidia-ml-py
Quick Start
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from green_love import GreenLoveEstimator, sample_dataloader
# Your model and data
model = nn.Linear(784, 10).cuda()
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
dataset = TensorDataset(torch.randn(10000, 784), torch.randint(0, 10, (10000,)))
full_loader = DataLoader(dataset, batch_size=64, shuffle=True)
# Create estimator
total_epochs = 100
estimator = GreenLoveEstimator(
total_epochs=total_epochs,
sample_data_pct=10.0, # benchmark on 10% of data
sample_epochs_pct=10.0, # run 10% of epochs for benchmark
warmup_epochs=2, # discard first 2 epochs
)
# Create a sampled dataloader for the benchmark phase
benchmark_loader = sample_dataloader(full_loader, sample_pct=10.0)
for epoch in range(total_epochs):
estimator.on_epoch_start(epoch)
# Use sampled data during benchmark, full data after
loader = benchmark_loader if estimator.is_benchmarking else full_loader
for x, y in loader:
x, y = x.cuda(), y.cuda()
optimizer.zero_grad()
loss = criterion(model(x), y)
loss.backward()
optimizer.step()
# on_epoch_end returns False if user chooses to stop
if not estimator.on_epoch_end(epoch):
break
estimator.cleanup()
After the benchmark epochs complete:
- An HTML report opens in your browser with full cost/time/CO₂ analysis
- The terminal shows a summary and prompts:
Continue training locally? [y/N]
Mathematical Foundations
Core Problem: Estimating Training Time
We model training time as a random variable:
$$T(n, B_e)$$
where $n$ is the sample size and $B_e$ is the number of training epochs.
The expected training time is approximately linear in both variables — multiplying either by $k$ results in roughly $k$ times longer training. We validated this hypothesis empirically by training multiple model architectures on MNIST across a range of sample sizes.
Empirical Evidence: Neural Networks
The plots below show that training time scales linearly with sample size, and that individual epochs are roughly the same:
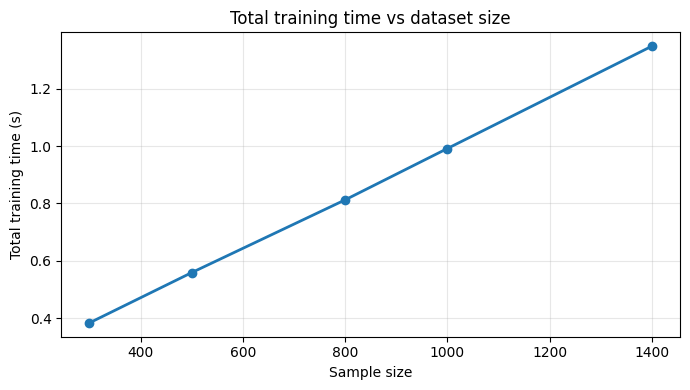
Total training time grows linearly with dataset size — the foundation of our estimation model.
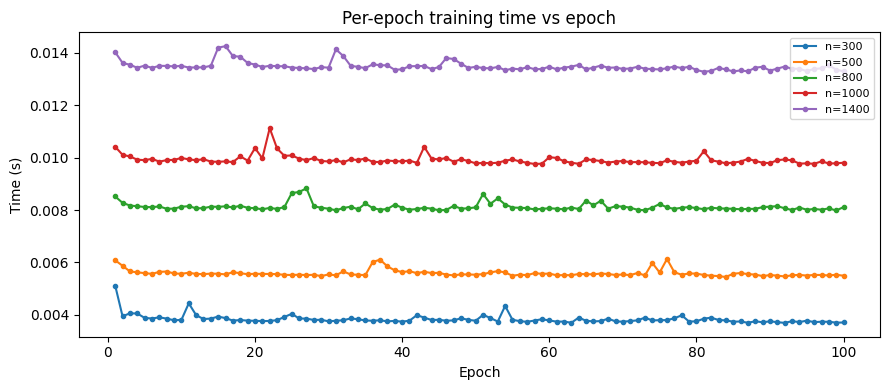
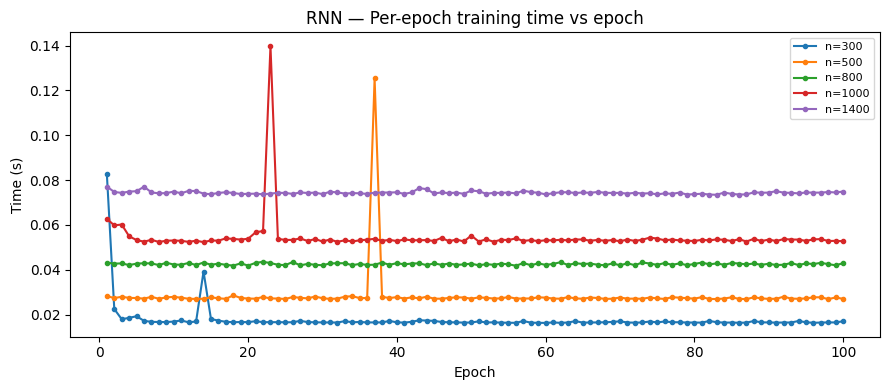
Per-epoch timing: the first 1–3 epochs are slower (data loading & initialization overhead), then times stabilize. Occasional spikes are caused by RAM saturation triggering disk swaps.
Other Model Architectures
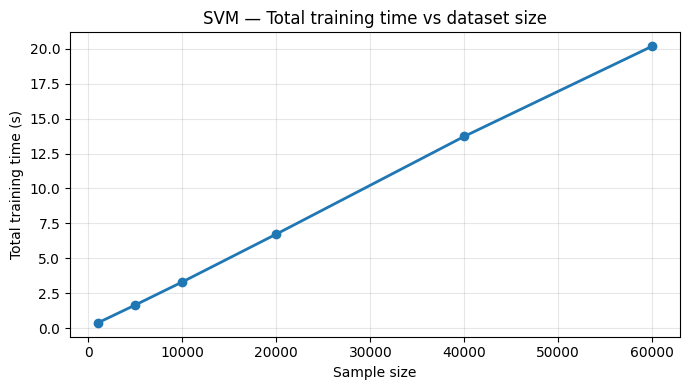
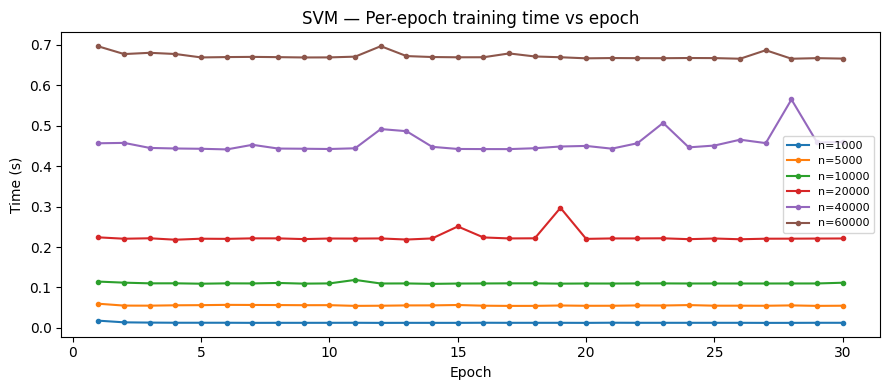
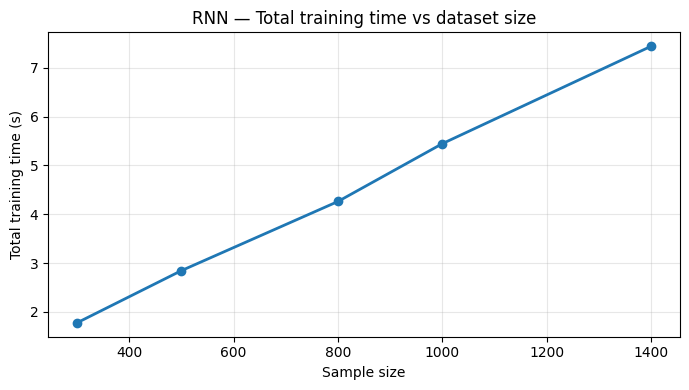
We repeated the experiment on SVMs, RNNs, and Random Forests. All exhibited the same linear scaling behavior:
SVM results
RNN results
Random Forest results
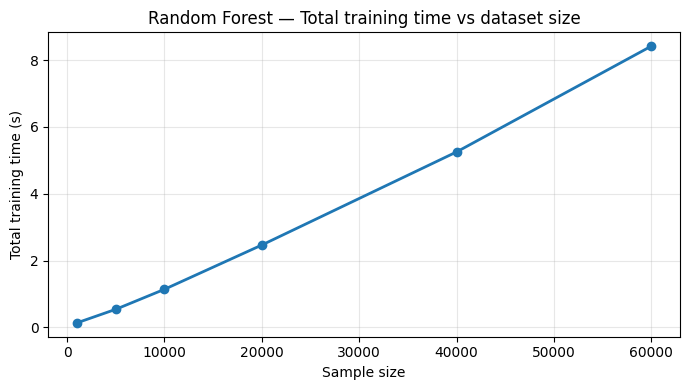
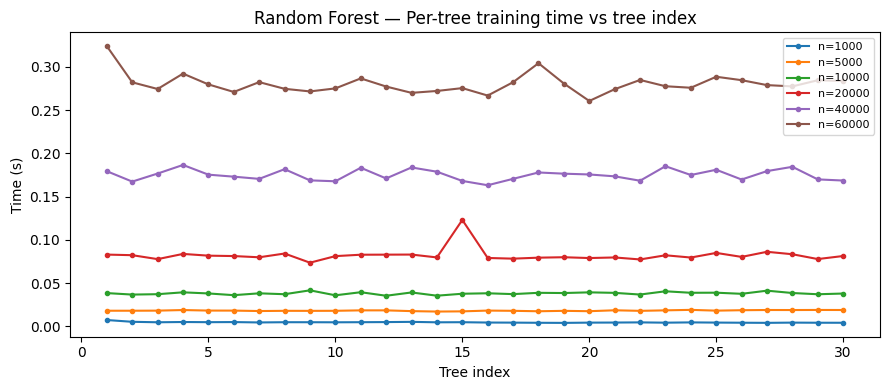
All models confirmed our two key assumptions: (1) linear time scaling with sample size, and (2) warmup epochs being consistently slower than steady-state epochs.
The Training Time Formula
Based on these observations, we separate the first three (slower) epochs from the rest:
$$T(n, B_e) \approx e_1(n) + e_2(n) + e_3(n) + (B_e - 3) \cdot \bar{A}_e(n)$$
where $\bar{A}_e(n)$ is the average epoch duration after the third epoch. The warmup epochs are modeled independently because they include one-time costs (JIT compilation, CUDA context setup, data loader prefetching) that don't repeat.
Linear Scaling with Sample Size
Since per-epoch time is proportional to the number of samples processed:
$$e_i(N) \approx e_i(n) \cdot \frac{N}{n}$$
This is what makes the "smart data" approach work — we can train on just 10% of the data and multiply the measured epoch time by 10 to get the full-data estimate, with high accuracy.
Confidence Intervals
By the Central Limit Theorem, the confidence interval for total training time is:
$$\bar{A}e(n) \cdot B_e ;\pm; \sqrt{B_e} \cdot \sigma(n) \cdot z{\alpha}$$
where $\sigma(n)$ is the standard deviation of epoch times scaled to sample size $n$.
Configuration
| Parameter | Type | Default | Description |
|---|---|---|---|
total_epochs |
int |
required | Total planned training epochs |
sample_data_pct |
float |
100.0 |
% of data used during benchmark |
sample_epochs_pct |
float |
10.0 |
% of epochs to run before estimating |
warmup_epochs |
int |
2 |
Epochs to discard from timing |
country_code |
str |
auto-detect | ISO country code (e.g., "US", "DE") |
carbon_intensity |
float |
auto-lookup | Grid carbon intensity (gCO₂/kWh) |
electricity_price |
float |
auto-lookup | Electricity price ($/kWh) |
electricity_maps_api_key |
str |
None |
API key for live carbon intensity |
gpu_name |
str |
auto-detect | GPU name override |
gpu_index |
int |
0 |
NVIDIA GPU device index |
manual_tdp_watts |
float |
None |
Manual TDP if NVML unavailable |
manual_gpu_utilization |
float |
0.70 |
GPU utilization fraction |
benchmark_task |
str |
None |
Task-specific benchmark comparison |
precision |
str |
"fp16" |
"fp16" or "fp32" benchmark table |
custom_speedup |
dict |
None |
Custom speedup ratios per Crusoe GPU |
report_dir |
str |
"./crusoe_reports" |
HTML report output directory |
auto_open_report |
bool |
True |
Auto-open report in browser |
power_poll_interval |
float |
1.0 |
Seconds between power readings |
Benchmark Task Options
For task-specific speed comparison, set benchmark_task to one of:
"resnet50"— Image classification (best for CNN workloads)"bert_base_squad"— NLP fine-tuning (best for small Transformers)"bert_large_squad"— NLP fine-tuning (best for large Transformers)"gnmt"— Machine translation (best for seq2seq models)"tacotron2"— Text-to-speech"waveglow"— Audio generation
If not set, uses geometric mean across all tasks (recommended for general workloads).
Custom Speedup Ratios
Override benchmark-based speed estimation for specific GPUs:
estimator = GreenLoveEstimator(
total_epochs=100,
custom_speedup={
"H100 HGX 80GB": 2.5, # your measured speedup
"A100 SXM 80GB": 1.8,
}
)
Manual Environment Configuration
estimator = GreenLoveEstimator(
total_epochs=100,
country_code="DE", # Germany
carbon_intensity=332, # gCO₂/kWh
electricity_price=0.40, # $/kWh
manual_tdp_watts=350, # if NVML unavailable
manual_gpu_utilization=0.75, # estimated utilization
)
How It Works
- Benchmark Phase: Runs
benchmark_epochsonsample_data_pct% of data - Warmup Discard: First
warmup_epochsare excluded from timing (they are consistently slower due to initialization) - Median Timing: Takes median of measured epoch times (robust to outliers and RAM spikes)
- Linear Scaling:
median_epoch_time × (100 / sample_data_pct)to estimate full-data epoch - Total Estimate:
full_data_epoch × total_epochs - Confidence Intervals: 95% CI via Student's t-distribution
- Power Monitoring: GPU power sampled via NVML → total energy (kWh)
- CO₂ & Cost: Energy × grid carbon intensity / electricity price (offline tables for 70+ countries, or live via Electricity Maps API)
- Crusoe Comparison: Speed ratios from Lambda Labs benchmarks (or TFLOPS+bandwidth weighted fallback) → estimated time, cost, CO₂ for each Crusoe GPU
- Report: Interactive HTML dashboard with CSS-only visualizations
- Prompt: Terminal prompt to continue training or stop
GPU Speed Estimation
Green Love uses two strategies to estimate how fast Crusoe Cloud GPUs would train your model:
Strategy 1: Lambda Labs Benchmark Ratios (preferred)
When your local GPU exists in the benchmark table, speed ratios are computed directly from published benchmark data across multiple tasks (ResNet-50, BERT, GNMT, etc.).
Strategy 2: TFLOPS + Bandwidth Fallback
When your local GPU is NOT in the benchmark table, Green Love uses a weighted formula:
$$\text{speedup} = 0.7 \times \frac{\text{TFLOPS}{\text{cloud}}}{\text{TFLOPS}{\text{local}}} + 0.3 \times \frac{\text{BW}{\text{cloud}}}{\text{BW}{\text{local}}}$$
This covers 50+ GPU models including consumer cards (RTX 3050, 3060, etc.) that lack published benchmarks.
Data Sources
| Data | Source | Last Updated |
|---|---|---|
| GPU Benchmarks | Lambda Labs | Dec 2025 |
| Crusoe Pricing | crusoe.ai/cloud/pricing | Dec 2025 |
| Carbon Intensity | Ember 2025, IEA 2023, EPA eGRID 2023 | 2025 |
| Electricity Prices | GlobalPetrolPrices Q4 2025 | 2025 |
| CO₂ Equivalences | EPA, IEA | 2024 |
License
MIT
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file green_love-0.1.1.tar.gz.
File metadata
- Download URL: green_love-0.1.1.tar.gz
- Upload date:
- Size: 47.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cc508e7a731f124ec7ca9dd84872d83c6d4552f4fca76dfc33c5591bc9924658
|
|
| MD5 |
1ccb4844761ba1db995ca0562f1465f8
|
|
| BLAKE2b-256 |
259f9cb9fa2595d285ca661b4ebc5491f2a3c6f4891e8dedf05c253df99d6181
|
File details
Details for the file green_love-0.1.1-py3-none-any.whl.
File metadata
- Download URL: green_love-0.1.1-py3-none-any.whl
- Upload date:
- Size: 38.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b2f4a49cde9c9cd7b114535e978e029acf282594e0dee81d4ccfa1fa54b1ddb7
|
|
| MD5 |
d0a9d313391b627ac53267367ee1c1db
|
|
| BLAKE2b-256 |
2eb5ce1575038a6a85c0dff5cf1293483efc90a5146f443109202f14318ab499
|







