PySpark bindings for H3, a hierarchical hexagonal geospatial indexing system

Project description

h3-pyspark: Uber's H3 Hexagonal Hierarchical Geospatial Indexing System in PySpark




PySpark bindings for the H3 core library.
For available functions, please see the vanilla Python binding documentation at:
Installation
Via PyPI:
pip install h3-pyspark
Via conda-forge:
conda install -c conda-forge h3-pyspark
Usage
>>> from pyspark.sql import SparkSession, functions as F
>>> import h3_pyspark
>>>
>>> spark = SparkSession.builder.getOrCreate()
>>> df = spark.createDataFrame([{"lat": 37.769377, "lng": -122.388903, 'resolution': 9}])
>>>
>>> df = df.withColumn('h3_9', h3_pyspark.geo_to_h3('lat', 'lng', 'resolution'))
>>> df.show()
+---------+-----------+----------+---------------+
| lat| lng|resolution| h3_9|
+---------+-----------+----------+---------------+
|37.769377|-122.388903| 9|89283082e73ffff|
+---------+-----------+----------+---------------+
Extension Functions
There are also various extension functions available for geospatial common operations which are not available in the vanilla H3 library.
Assumptions
- You use GeoJSON to represent geometries in your PySpark pipeline (as opposed to WKT)
- Geometries are stored in a GeoJSON
stringwithin a column (such asgeometry) in your PySpark dataset - Individual H3 cells are stored as a
stringcolumn (such ash3_9) - Sets of H3 cells are stored in an
array(string)column (such ash3_9)
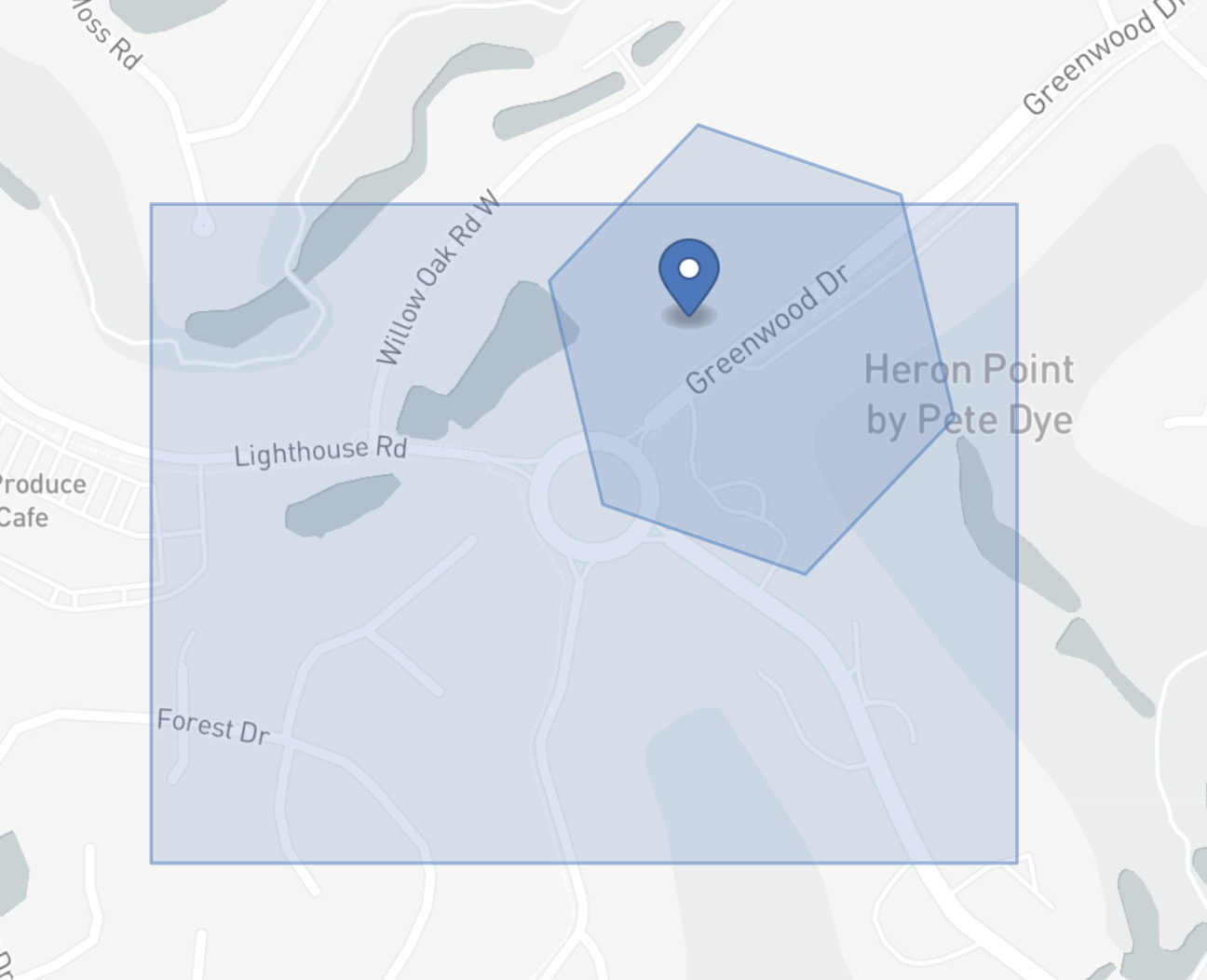
Indexing
index_shape(geometry: Column, resolution: Column)
Generate an H3 spatial index for an input GeoJSON geometry column.
This function accepts GeoJSON Point, LineString, Polygon, MultiPoint, MultiLineString, and MultiPolygon
input features, and returns the set of H3 cells at the specified resolution which completely cover them
(could be more than one cell for a substantially large geometry and substantially granular resolution).
The schema of the output column will be T.ArrayType(T.StringType()), where each value in the array is an H3 cell.
This spatial index can then be used for bucketing, clustering, and joins in Spark via an explode() operation.
>>> from pyspark.sql import SparkSession, functions as F
>>> from h3_pyspark.indexing import index_shape
>>> spark = SparkSession.builder.getOrCreate()
>>>
>>> df = spark.createDataFrame([{
'geometry': '{ "type": "MultiPolygon", "coordinates": [ [ [ [ -80.79442262649536, 32.13522895845023 ], [ -80.79298496246338, 32.13522895845023 ], [ -80.79298496246338, 32.13602844594619 ], [ -80.79442262649536, 32.13602844594619 ], [ -80.79442262649536, 32.13522895845023 ] ] ], [ [ [ -80.7923412322998, 32.1330848437511 ], [ -80.79073190689087, 32.1330848437511 ], [ -80.79073190689087, 32.13375715632646 ], [ -80.7923412322998, 32.13375715632646 ], [ -80.7923412322998, 32.1330848437511 ] ] ] ] }',
'resolution': 9
}])
>>>
>>> df = df.withColumn('h3_9', index_shape('geometry', 'resolution'))
>>> df.show()
+----------------------+----------+------------------------------------+
| geometry|resolution| h3_9|
+----------------------+----------+------------------------------------+
| { "type": "MultiP... | 9| [8944d551077ffff, 8944d551073ffff] |
+----------------------+----------+------------------------------------+
Optionally, add another column h3_9_geometry for the GeoJSON representation of each cell in the h3_9 column to easily map the result alongside your original input geometry:
>>> df = df.withColumn('h3_9_geometry', h3_pyspark.h3_set_to_multi_polygon(F.col('h3_9'), F.lit(True)))
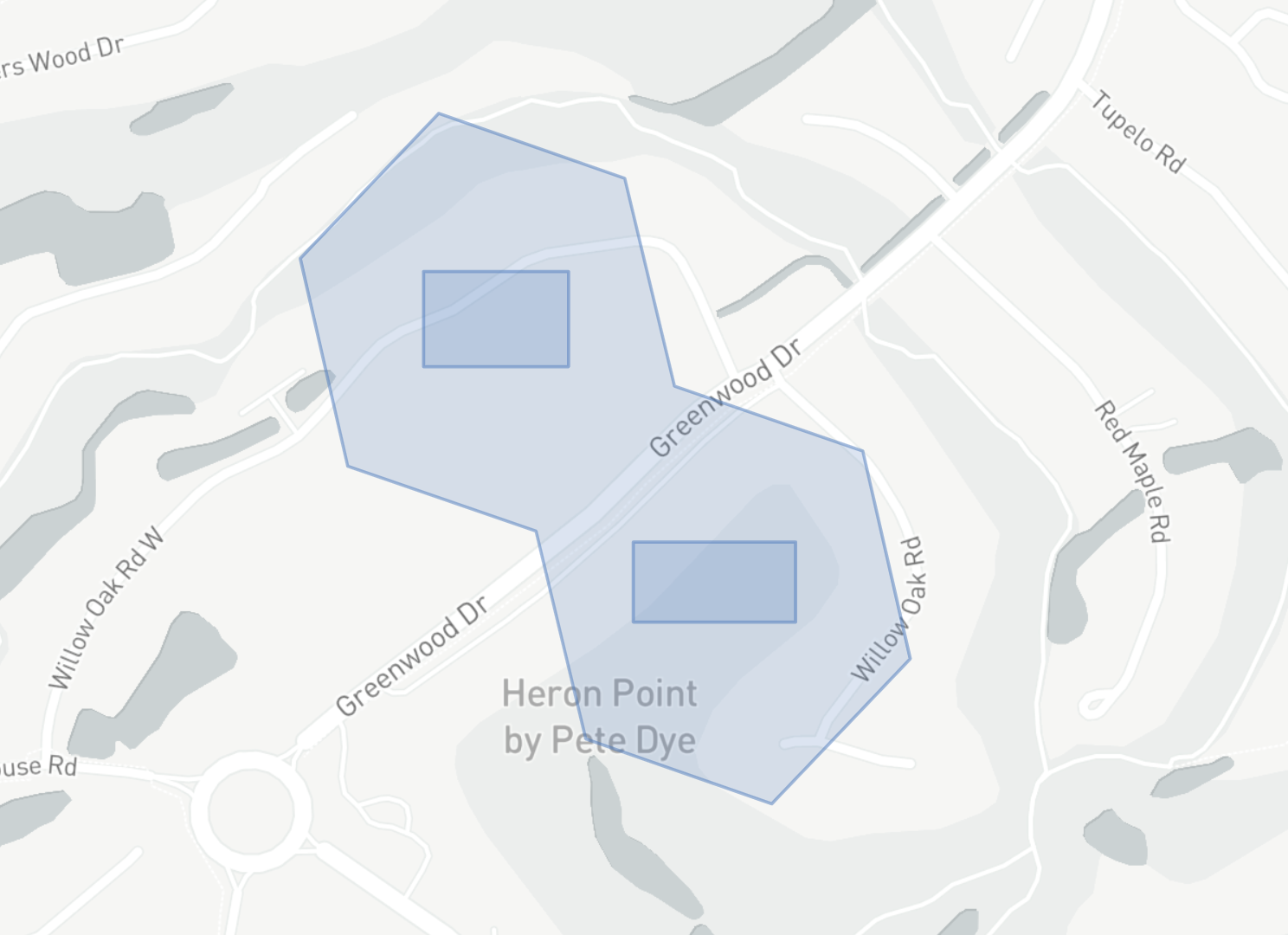
Buffers
k_ring_distinct(cells: Column, distance: Column)
Takes in an array of input cells, perform a k-ring operation on each cell, and return the distinct set of output cells.
The schema of the output column will be T.ArrayType(T.StringType()), where each value in the array is an H3 cell.
Since we know the edge length & diameter (2 * edge length) of each H3 cell resolution, we can use this to efficiently generate a "buffered" index of our input geometry (useful for operations such as distance joins):
>>> from pyspark.sql import SparkSession, functions as F
>>> from h3_pyspark.indexing import index_shape
>>> from h3_pyspark.traversal import k_ring_distinct
>>> spark = SparkSession.builder.getOrCreate()
>>>
>>> df = spark.createDataFrame([{
'geometry': '{ "type": "MultiPolygon", "coordinates": [ [ [ [ -80.79442262649536, 32.13522895845023 ], [ -80.79298496246338, 32.13522895845023 ], [ -80.79298496246338, 32.13602844594619 ], [ -80.79442262649536, 32.13602844594619 ], [ -80.79442262649536, 32.13522895845023 ] ] ], [ [ [ -80.7923412322998, 32.1330848437511 ], [ -80.79073190689087, 32.1330848437511 ], [ -80.79073190689087, 32.13375715632646 ], [ -80.7923412322998, 32.13375715632646 ], [ -80.7923412322998, 32.1330848437511 ] ] ] ] }',
'resolution': 9
}])
>>>
>>> df = df.withColumn('h3_9', index_shape('geometry', 'resolution'))
>>> df = df.withColumn('h3_9_buffer', k_ring_distinct('h3_9', 1))
>>> df.show()
+--------------------+----------+--------------------+--------------------+
| geometry|resolution| h3_9| h3_9_buffer|
+--------------------+----------+--------------------+--------------------+
|{ "type": "MultiP...| 9|[8944d551077ffff,...|[8944d551073ffff,...|
+--------------------+----------+--------------------+--------------------+
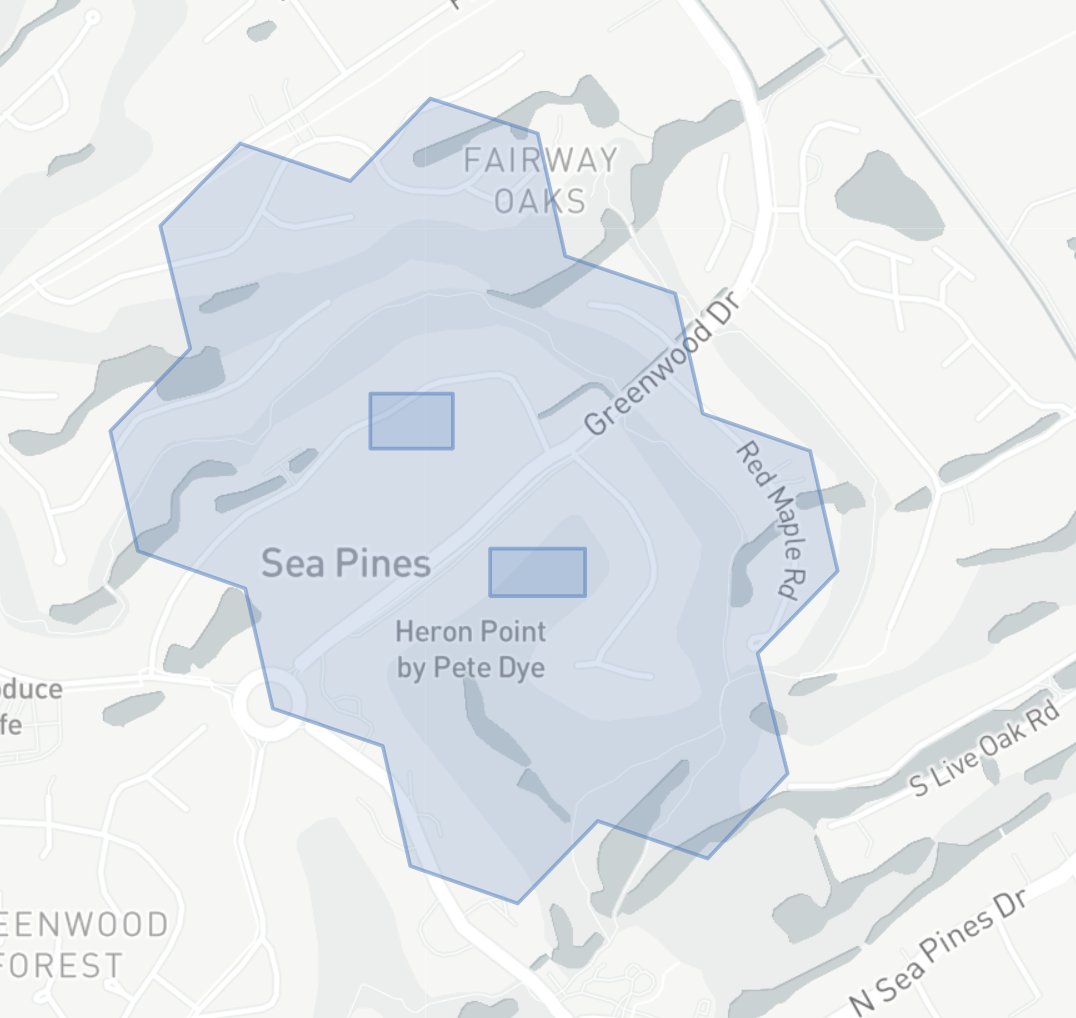
Spatial Joins
Once we have an indexed version of our geometries, we can easily join on the string column in H3 to get a set of pair candidates:
>>> from pyspark.sql import SparkSession, functions as F
>>> from h3_pyspark.indexing import index_shape
>>> spark = SparkSession.builder.getOrCreate()
>>>
>>> left = spark.createDataFrame([{
'left_id': 'left_point',
'left_geometry': '{ "type": "Point", "coordinates": [ -80.79527020454407, 32.132884966083935 ] }',
}])
>>> right = spark.createDataFrame([{
'right_id': 'right_polygon',
'right_geometry': '{ "type": "Polygon", "coordinates": [ [ [ -80.80022692680359, 32.12864200501338 ], [ -80.79224467277527, 32.12864200501338 ], [ -80.79224467277527, 32.13378441213715 ], [ -80.80022692680359, 32.13378441213715 ], [ -80.80022692680359, 32.12864200501338 ] ] ] }',
}])
>>>
>>> left = left.withColumn('h3_9', index_shape('left_geometry', F.lit(9)))
>>> right = right.withColumn('h3_9', index_shape('right_geometry', F.lit(9)))
>>>
>>> left = left.withColumn('h3_9', F.explode('h3_9'))
>>> right = right.withColumn('h3_9', F.explode('h3_9'))
>>>
>>> joined = left.join(right, on='h3_9', how='inner')
>>> joined.show()
+---------------+--------------------+----------+--------------------+-------------+
| h3_9| left_geometry| left_id| right_geometry| right_id|
+---------------+--------------------+----------+--------------------+-------------+
|8944d55100fffff|{ "type": "Point"...|left_point|{ "type": "Polygo...|right_polygon|
+---------------+--------------------+----------+--------------------+-------------+
You can combine this technique with a Buffer to do a Distance Join.
⚠️ Warning ⚠️: The outputs of an H3 join are approximate – all resulting geometry pairs should be considered intersection candidates rather than definitely intersecting. Pairing a join here with a subsequent
distancecalculation (distance = 0= intersecting) orintersectscan make this calculation exact. Shapely is a popular library with a well-documenteddistancefunction which can be easily wrapped in a UDF:
from pyspark.sql import functions as F, types as T
from shapely import geometry
import json
@F.udf(T.DoubleType())
def distance(geometry1, geometry2):
geometry1 = json.loads(geometry1)
geometry1 = geometry.shape(geometry1)
geometry2 = json.loads(geometry2)
geometry2 = geometry.shape(geometry2)
return geometry1.distance(geometry2)
After a spatial join (detailed above), you can filter to only directly intersecting geometries:
>>> joined = joined.withColumn('distance', distance(F.col('left_geometry'), F.col('right_geometry')))
>>> joined = joined.filter(F.col('distance') == 0)
>>> joined.show()
+---------------+--------------------+----------+--------------------+-------------+--------+
| h3_9| left_geometry| left_id| right_geometry| right_id|distance|
+---------------+--------------------+----------+--------------------+-------------+--------+
|8944d55100fffff|{ "type": "Point"...|left_point|{ "type": "Polygo...|right_polygon| 0.0|
+---------------+--------------------+----------+--------------------+-------------+--------+
Publishing New Versions
-
Bump version in
setup.cfg -
Publish to
PyPigit clean -fdx python3 -m build python3 -m twine upload --repository pypi dist/* -
Create a new tag & release w/ version
x.x.xand nameh3-pyspark-x.x.xin GitHub -
Publish to
conda-forge:- Bump version & new tag's
sha256hash inmeta.ymlin@conda-forge/h3-pyspark-feedstockopenssl sha256 /path/to/h3-pyspark-x.x.x.tar.gz
- Bump version & new tag's
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file h3-pyspark-1.2.6.tar.gz.
File metadata
- Download URL: h3-pyspark-1.2.6.tar.gz
- Upload date:
- Size: 14.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.10.0 pkginfo/1.8.2 requests/2.27.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
27c6e9513b37cc18be4de5a7b9ebc8216372250ee59f26522f1ab0719f5395fe
|
|
| MD5 |
9ac92283e58eae0cd9471ca090ae57fd
|
|
| BLAKE2b-256 |
288ab85bb9a5bbe2468a9abf95baa2e3bd16754e770714caa9266b5183d13edb
|
File details
Details for the file h3_pyspark-1.2.6-py3-none-any.whl.
File metadata
- Download URL: h3_pyspark-1.2.6-py3-none-any.whl
- Upload date:
- Size: 13.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.10.0 pkginfo/1.8.2 requests/2.27.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e247713f7006260b2da6039b0a05bb3e109ec24aa482218f08d71011baf4e00d
|
|
| MD5 |
7c4c423a0dc09c974b0a24b5e4b0b73b
|
|
| BLAKE2b-256 |
a75df9f0679583112cb0e656769dc4c0fbf5d4144aa606e4d23acea1b53c0ff7
|







