RDBMS access via IPython


Project description
Introduces a %sql (or %%sql) magic.
Connect to a database, using SQLAlchemy connect strings, then issue SQL commands within IPython or IPython Notebook.
Examples
In [1]: %load_ext sql
In [2]: %%sql postgresql://will:longliveliz@localhost/shakes
...: select * from character
...: where abbrev = 'ALICE'
...:
Out[2]: [(u'Alice', u'Alice', u'ALICE', u'a lady attending on Princess Katherine', 22)]
In [3]: result = _
In [4]: print(result)
charid charname abbrev description speechcount
=================================================================================
Alice Alice ALICE a lady attending on Princess Katherine 22
In [4]: result.keys
Out[5]: [u'charid', u'charname', u'abbrev', u'description', u'speechcount']
In [6]: result[0][0]
Out[6]: u'Alice'
In [7]: result[0].description
Out[7]: u'a lady attending on Princess Katherine'After the first connection, connect info can be omitted:
In [8]: %sql select count(*) from work Out[8]: [(43L,)]
Connections to multiple databases can be maintained. You can refer to an existing connection by username@database
In [9]: %%sql will@shakes
...: select charname, speechcount from character
...: where speechcount = (select max(speechcount)
...: from character);
...:
Out[9]: [(u'Poet', 733)]
In [10]: print(_)
charname speechcount
======================
Poet 733If no connect string is supplied, %sql will provide a list of existing connections; however, if no connections have yet been made and the environment variable DATABASE_URL is available, that will be used.
For secure access, you may dynamically access your credentials (e.g. from your system environment or getpass.getpass) to avoid storing your password in the notebook itself. Use the $ before any variable to access it in your %sql command.
In [11]: user = os.getenv('SOME_USER')
....: password = os.getenv('SOME_PASSWORD')
....: connection_string = "postgresql://{user}:{password}@localhost/some_database".format(user=user, password=password)
....: %sql $connection_string
Out[11]: u'Connected: some_user@some_database'You may use multiple SQL statements inside a single cell, but you will only see any query results from the last of them, so this really only makes sense for statements with no output
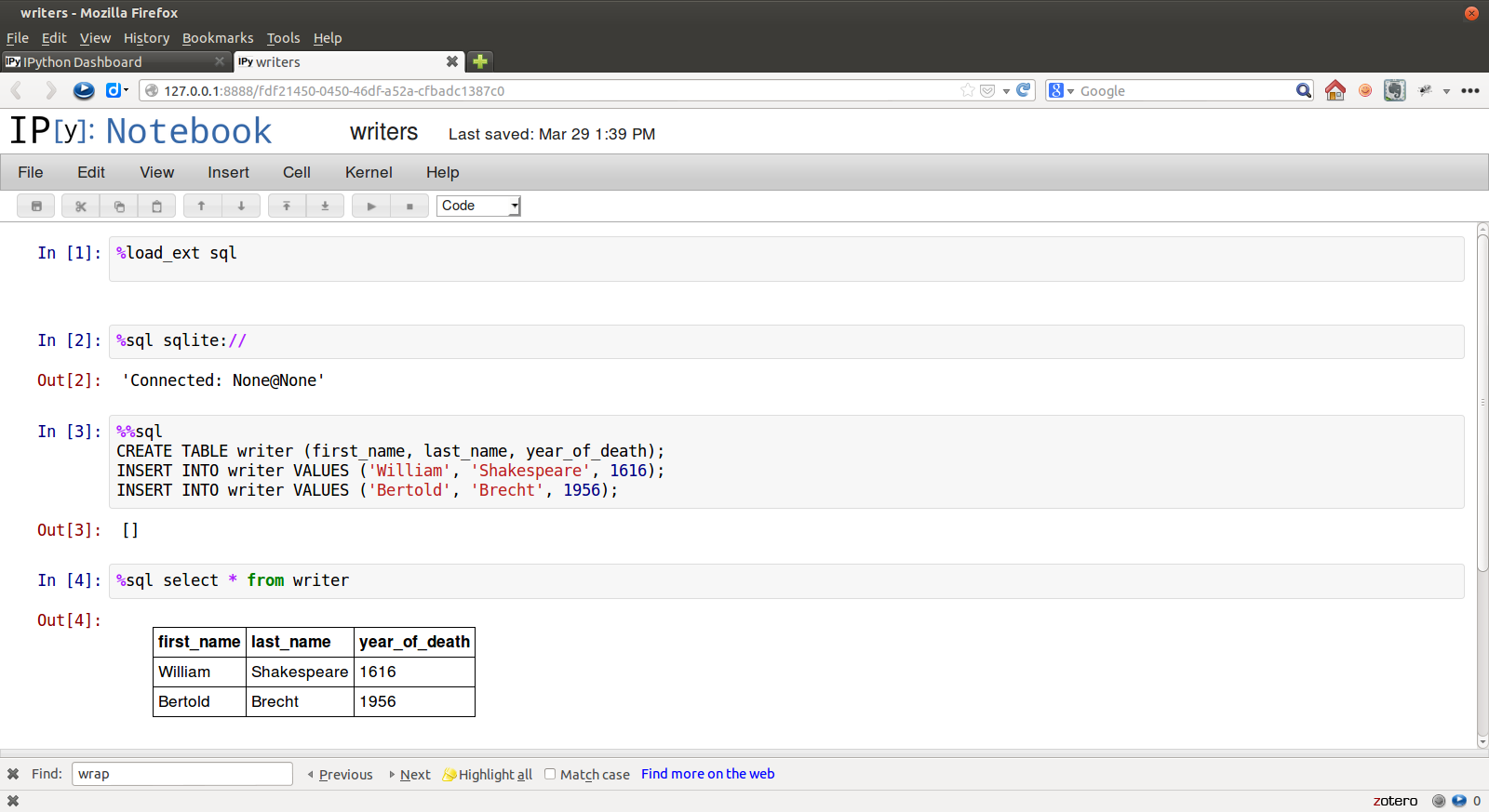
In [11]: %%sql sqlite://
....: CREATE TABLE writer (first_name, last_name, year_of_death);
....: INSERT INTO writer VALUES ('William', 'Shakespeare', 1616);
....: INSERT INTO writer VALUES ('Bertold', 'Brecht', 1956);
....:
Out[11]: []Bind variables (bind parameters) can be used in the “named” (:x) style. The variable names used should be defined in the local namespace
In [12]: name = 'Countess'
In [13]: %sql select description from character where charname = :name
Out[13]: [(u'mother to Bertram',)]As a convenience, dict-style access for result sets is supported, with the leftmost column serving as key, for unique values.
In [14]: result = %sql select * from work
43 rows affected.
In [15]: result['richard2']
Out[15]: (u'richard2', u'Richard II', u'History of Richard II', 1595, u'h', None, u'Moby', 22411, 628)Results can also be retrieved as an iterator of dictionaries (result.dicts()) or a single dictionary with a tuple of scalar values per key (result.dict())
Assignment
Ordinary IPython assignment works for single-line %sql queries:
In [16]: works = %sql SELECT title, year FROM work
43 rows affected.The << operator captures query results in a local variable, and can be used in multi-line %%sql:
In [17]: %%sql works << SELECT title, year
...: FROM work
...:
43 rows affected.
Returning data to local variable worksConnecting
Connection strings are SQLAlchemy standard.
Some example connection strings:
mysql+pymysql://scott:tiger@localhost/foo oracle://scott:tiger@127.0.0.1:1521/sidname sqlite:// sqlite:///foo.db mssql+pyodbc://username:password@host/database?driver=SQL+Server+Native+Client+11.0
Note that mysql and mysql+pymysql connections (and perhaps others) don’t read your client character set information from .my.cnf. You need to specify it in the connection string:
mysql+pymysql://scott:tiger@localhost/foo?charset=utf8
Note that impala connecion with impyla for HiveServer2 requires to disable autocommit:
%config SqlMagic.autocommit=False %sql impala://hserverhost:port/default?kerberos_service_name=hive&auth_mechanism=GSSAPI
Configuration
Query results are loaded as lists, so very large result sets may use up your system’s memory and/or hang your browser. There is no autolimit by default. However, autolimit (if set) limits the size of the result set (usually with a LIMIT clause in the SQL). displaylimit is similar, but the entire result set is still pulled into memory (for later analysis); only the screen display is truncated.
In [2]: %config SqlMagic
SqlMagic options
--------------
SqlMagic.autocommit=<Bool>
Current: True
Set autocommit mode
SqlMagic.autolimit=<Int>
Current: 0
Automatically limit the size of the returned result sets
SqlMagic.autopandas=<Bool>
Current: False
Return Pandas DataFrames instead of regular result sets
SqlMagic.displaylimit=<Int>
Current: 0
Automatically limit the number of rows displayed (full result set is still
stored)
SqlMagic.feedback=<Bool>
Current: True
Print number of rows affected by DML
SqlMagic.short_errors=<Bool>
Current: True
Don't display the full traceback on SQL Programming Error
SqlMagic.style=<Unicode>
Current: 'DEFAULT'
Set the table printing style to any of prettytable's defined styles
(currently DEFAULT, MSWORD_FRIENDLY, PLAIN_COLUMNS, RANDOM)
In[3]: %config SqlMagic.feedback = FalsePlease note: if you have autopandas set to true, the displaylimit option will not apply. You can set the pandas display limit by using the pandas max_rows option as described in the pandas documentation.
Pandas
If you have installed pandas, you can use a result set’s .DataFrame() method
In [3]: result = %sql SELECT * FROM character WHERE speechcount > 25
In [4]: dataframe = result.DataFrame()The bogus non-standard pseudo-SQL command PERSIST will create a table name in the database from the named DataFrame.
In [5]: %sql PERSIST dataframe
In [6]: %sql SELECT * FROM dataframe;Graphing
If you have installed matplotlib, you can use a result set’s .plot(), .pie(), and .bar() methods for quick plotting
In[5]: result = %sql SELECT title, totalwords FROM work WHERE genretype = 'c'
In[6]: %matplotlib inline
In[7]: result.pie()
Dumping
Result sets come with a .csv(filename=None) method. This generates comma-separated text either as a return value (if filename is not specified) or in a file of the given name.
In[8]: result = %sql SELECT title, totalwords FROM work WHERE genretype = 'c'
In[9]: result.csv(filename='work.csv')PostgreSQL features
psql-style “backslash” meta-commands commands (\d, \dt, etc.) are provided by PGSpecial. Example:
In[9]: %sql \dInstalling
Install the lastest release with:
pip install ipython-sql
or download from https://github.com/catherinedevlin/ipython-sql and:
cd ipython-sql sudo python setup.py install
Development
Credits
Matthias Bussonnier for help with configuration
Olivier Le Thanh Duong for %config fixes and improvements
Mike Wilson for bind variable code
Thomas Kluyver and Steve Holden for debugging help
Berton Earnshaw for DSN connection syntax
Andrés Celis for SQL Server bugfix
Michael Erasmus for DataFrame truth bugfix
Noam Finkelstein for README clarification
Xiaochuan Yu for << operator, syntax colorization
Amjith Ramanujam for PGSpecial and incorporating it here
News
0.1
Release date: 21-Mar-2013
Initial release
0.1.1
Release date: 29-Mar-2013
Release to PyPI
Results returned as lists
print(_) to get table form in text console
set autolimit and text wrap in configuration
0.1.2
Release date: 29-Mar-2013
Python 3 compatibility
use prettyprint package
allow multiple SQL per cell
0.2.0
Release date: 30-May-2013
Accept bind variables (Thanks Mike Wilson!)
0.2.1
Release date: 15-June-2013
Recognize socket connection strings
Bugfix - issue 4 (remember existing connections by case)
0.2.2
Release date: 30-July-2013
Converted from an IPython Plugin to an Extension for 1.0 compatibility
0.2.2.1
Release date: 01-Aug-2013
Deleted Plugin import left behind in 0.2.2
0.2.3
Release date: 20-Sep-2013
Contributions from Olivier Le Thanh Duong:
SQL errors reported without internal IPython error stack
Proper handling of configuration
Added .DataFrame(), .pie(), .plot(), and .bar() methods to result sets
0.3.0
Release date: 13-Oct-2013
displaylimit config parameter
reports number of rows affected by each query
test suite working again
dict-style access for result sets by primary key
0.3.1
Reporting of number of rows affected configurable with feedback
Local variables usable as SQL bind variables
0.3.2
.csv(filename=None) method added to result sets
0.3.3
Python 3 compatibility restored
DSN access supported (thanks Berton Earnshaw)
0.3.4
PERSIST pseudo-SQL command added
0.3.5
Indentations visible in HTML cells
COMMIT each SQL statement immediately - prevent locks
0.3.6
Fixed issue #30, commit failures for sqlite (thanks stonebig, jandot)
0.3.7
New column_local_vars config option submitted by darikg
Avoid contaminating user namespace from locals (thanks alope107)
0.3.7.1
Avoid “connection busy” error for SQL Server (thanks Andrés Celis)
0.3.8
Stop warnings for deprecated use of IPython 3 traitlets in IPython 4 (thanks graphaelli; also stonebig, aebrahim, mccahill)
README update for keeping connection info private, from eshilts
0.3.9
Fix truth value of DataFrame error (thanks michael-erasmus)
<< operator (thanks xiaochuanyu)
added README example (thanks tanhuil)
bugfix in executing column_local_vars (thanks tebeka)
pgspecial installation optional (thanks jstoebel and arjoe)
conceal passwords in connection strings (thanks jstoebel)
0.3.9
Restored Python 2 compatibility (thanks tokenmathguy)
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file hops-ipython-sql-0.3.9.tar.gz.
File metadata
- Download URL: hops-ipython-sql-0.3.9.tar.gz
- Upload date:
- Size: 18.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.6.3 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.7.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
71dfdce95f202e0432e5aaba7cdafca50ee301b419bfd7d701183660d962131c
|
|
| MD5 |
5dbdd58aaa76abf40f3a09b362f9a020
|
|
| BLAKE2b-256 |
e46eaa0304fbaf32d2297bc416a0f72eb17a959b261e3bf396d8de956c9e861a
|







