Client library to download and publish environments, agents on the huggingbutt.com hub

Project description
HuggingButt
Client library to download and publish reinforcement learning environments/agents on the huggingbutt.com hub
Installation
The base dependency mlagents-envs has been update to version 1.0.0. However, this version may rise an error Issue 5996(on Windows 10). So I specified mlagents-envs==0.30.0, NumPy==1.21.2 in this project. I did not found this issue on MacOS.
Create a new python environment using anaconda/miniconda. Only Python 3.9!!
conda create -n hb python==3.9.18
activate the new python environment.
conda activate hb
install huggingbutt from pypi
pip install huggingbutt==0.0.5
or from source code
git clone -b v0.0.5 https://github.com/huggingbutt/huggingbutt.git
cd huggingbutt
python -m pip install .
If there is no error message printed during the installation, congratulations, you have successfully installed this package. Next, you need to apply an access token from the official website https://huggingbutt.com.
Register an account and login, just do as shown in the image below.
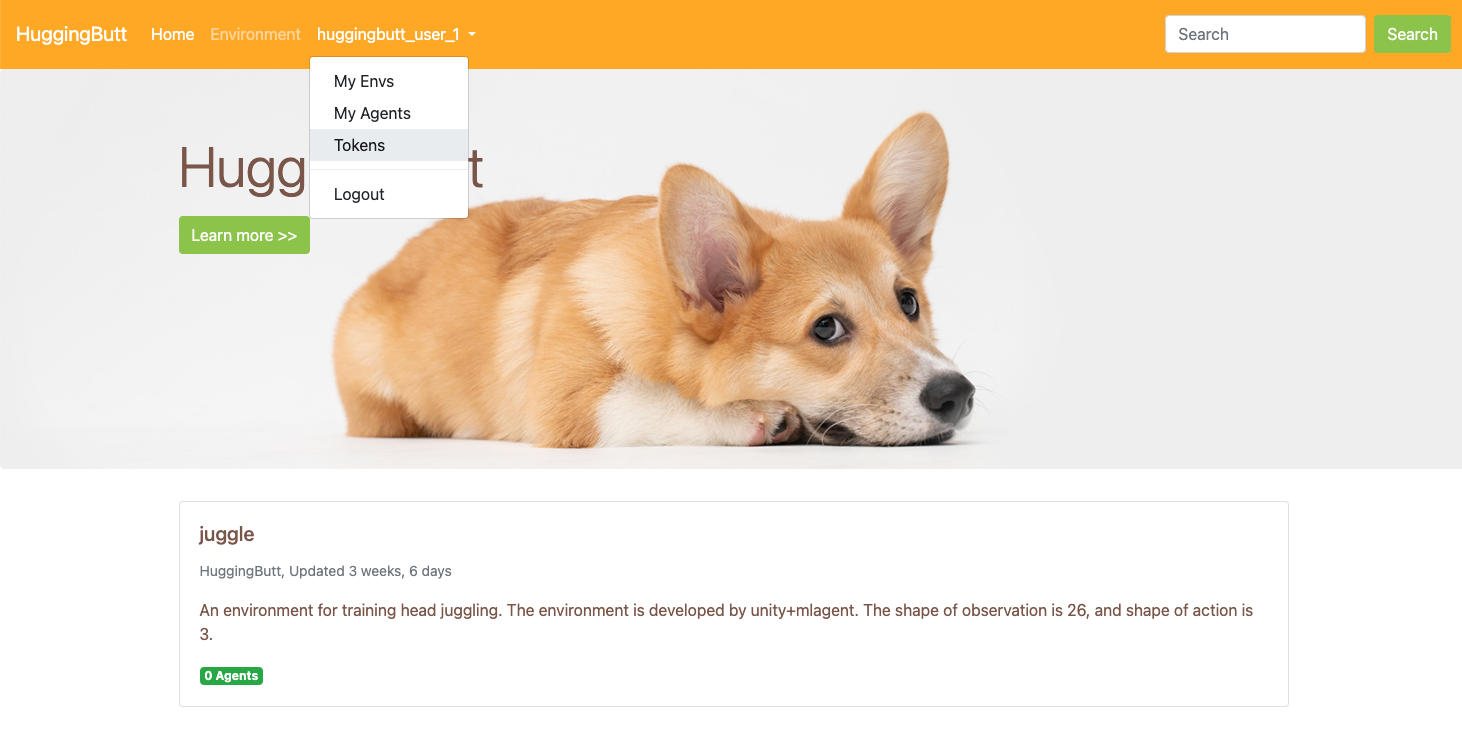
Click new token button generate a new token. This access token is mainly used to restrict the download times of each user, as the server cost is relatively high.
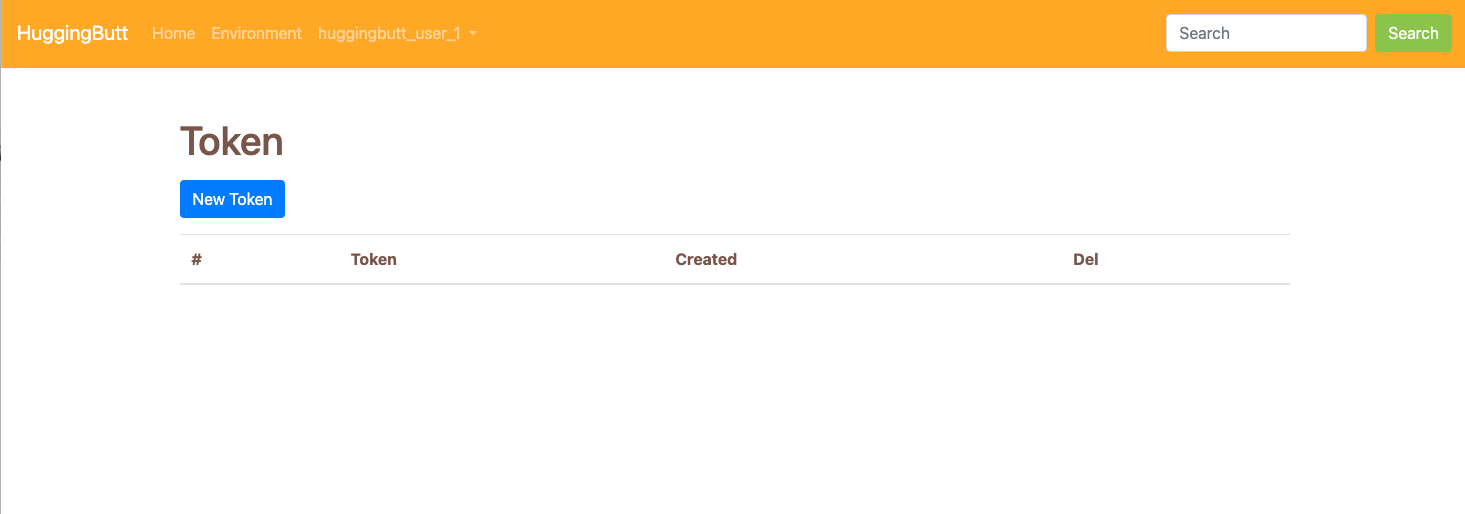
Congratulations, you now have an access token!
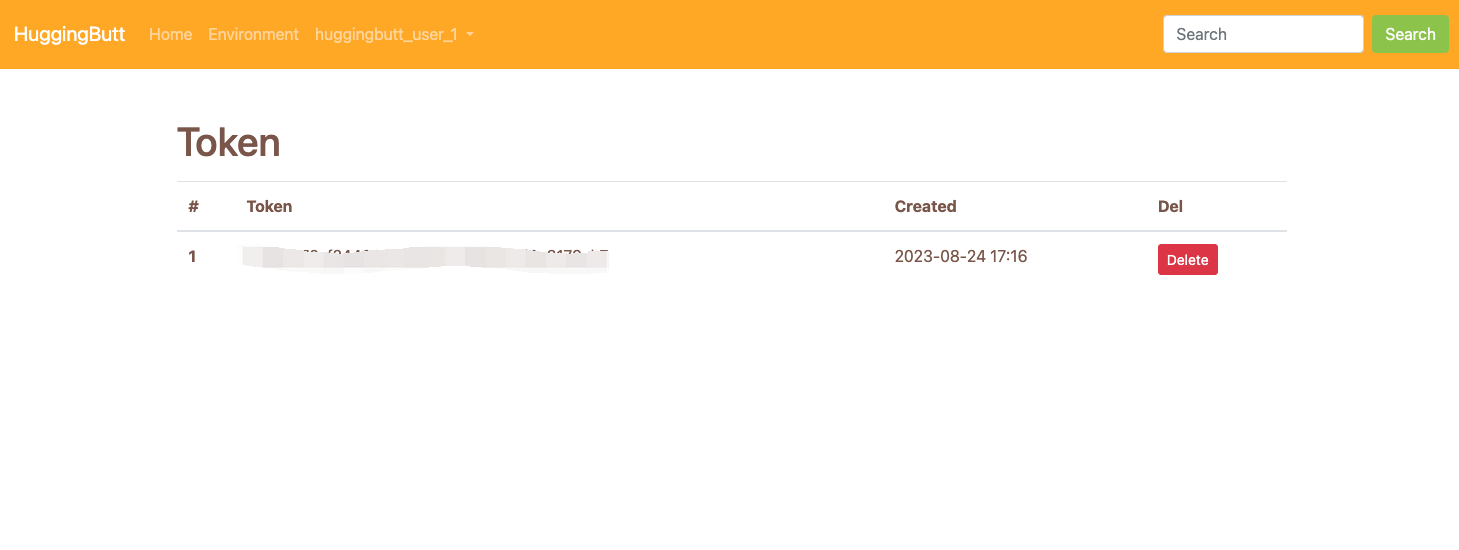
Just put the generated token in the task code and you're gooooood to go.
Here is a simple training code:
from huggingbutt import Env, Agent, set_access_token
if __name__ == '__main__':
set_access_token('YOUR_TOKEN')
env = Env.get("huggingbutt/juggle", 'mac', startup_args=['--time_scale', '10'])
agent = Agent(
env=env,
algorithm='PPO',
policy='MlpPolicy',
batch_size=64
)
agent.learn(total_timesteps=10000)
agent.save()
env.close()
Inference:
from huggingbutt import Env, Agent, set_access_token
if __name__ == '__main__':
set_access_token('YOUR_TOKEN')
env = Env.get("huggingbutt/juggle", 'mac', startup_args=['--time_scale', '1'])
agent = Agent.get(15, env)
obs = env.reset()
for i in range(100):
act, _status_ = agent.predict(obs)
obs, reward, done, info = env.step(act)
if done:
obs = env.reset()
env.close()
todo
- Support more types learning environment, such as native game wrapped by python, pygame, class gym...
- Develop a framework, user can customize the observation, action and reward of the environment developed under this framework. I hope this makes it easier for everyone to iterate the environment's agent.
- There are still many ideas, I will add them later when I think about them...
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file huggingbutt-0.0.5.tar.gz.
File metadata
- Download URL: huggingbutt-0.0.5.tar.gz
- Upload date:
- Size: 16.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58ecb382c81005b40a04f11b6a4f8eb12f0137a2afccf31f3788fe3c13d731be
|
|
| MD5 |
5b41092224059a6ce8015e8ee407e4bc
|
|
| BLAKE2b-256 |
2be31ec3c36440bc5fdb9f42ef42761d73a33b46c4946b63e6188372bf9212f9
|
File details
Details for the file huggingbutt-0.0.5-py3-none-any.whl.
File metadata
- Download URL: huggingbutt-0.0.5-py3-none-any.whl
- Upload date:
- Size: 17.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8980d0d79417dc9ff24d26de7e9173813cc38451e6d4a943b6a051107470720f
|
|
| MD5 |
20eb6214761fa8c9f7a2c523eaa89a45
|
|
| BLAKE2b-256 |
a9520a2e52f1e6723a46ed5650543edfb4a7a4588b4338191ead02b1d1f9d464
|







