A scikit-learn compatible hyperbox-based machine learning library in Python

Project description







hyperbox-brain is a Python open source toolbox implementing hyperbox-based machine learning algorithms built on top of scikit-learn and is distributed under the GPL-3 license.
The project was started in 2018 by Prof. Bogdan Gabrys and Dr. Thanh Tung Khuat at the Complex Adaptive Systems Lab - The University of Technology Sydney. This project is a core module aiming to the formulation of explainable life-long learning systems in near future.
Resources
Installation
Dependencies
Hyperbox-brain requires:
Python (>= 3.6)
Scikit-learn (>= 0.24.0)
NumPy (>= 1.14.6)
SciPy (>= 1.1.0)
joblib (>= 0.11)
threadpoolctl (>= 2.0.0)
Pandas (>= 0.25.0)
Hyperbox-brain plotting capabilities (i.e., functions start with show_ or draw_) require Matplotlib (>= 2.2.3) and Plotly (>= 4.10.0). For running the examples Matplotlib >= 2.2.3 and Plotly >= 4.10.0 are required. A few examples require pandas >= 0.25.0.
conda installation
You need a working conda installation. Get the correct miniconda for your system from here.
To install hyperbox-brain, you need to use the conda-forge channel:
conda install -c conda-forge hyperbox-brainWe recommend to use a conda virtual environment.
pip installation
If you already have a working installation of numpy, scipy, pandas, matplotlib, and scikit-learn, the easiest way to install hyperbox-brain is using pip:
pip install -U hyperbox-brainAgain, we recommend to use a virtual environment for this.
From source
If you would like to use the most recent additions to hyperbox-brain or help development, you should install hyperbox-brain from source.
Using conda
To install hyperbox-brain from source using conda, proceed as follows:
git clone https://github.com/UTS-CASLab/hyperbox-brain.git
cd hyperbox-brain
conda env create
source activate hyperbox-brain
pip install .Using pip
For pip, follow these instructions instead:
git clone https://github.com/UTS-CASLab/hyperbox-brain.git
cd hyperbox-brain
# create and activate a virtual environment
pip install -r requirements.txt
# install hyperbox-brain version for your system (see below)
pip install .Testing
After installation, you can launch the test suite from outside the source directory (you will need to have pytest >= 5.0.1 installed):
pytest hbbrainFeatures
Types of input variables
The hyperbox-brain library separates learning models for continuous variables only and mixed-attribute data.
Incremental learning
Incremental (online) learning models are created incrementally and are updated continuously. They are appropriate for big data applications where real-time response is an important requirement. These learning models generate a new hyperbox or expand an existing hyperbox to cover each incoming input pattern.
Agglomerative learning
Agglomerative (batch) learning models are trained using all training data available at the training time. They use the aggregation of existing hyperboxes to form new larger sized hyperboxes based on the similarity measures among hyperboxes.
Ensemble learning
Ensemble models in the hyperbox-brain toolbox build a set of hyperbox-based learners from a subset of training samples or a subset of both training samples and features. Training subsets of base learners can be formed by stratified random subsampling, resampling, or class-balanced random subsampling. The final predicted results of an ensemble model are an aggregation of predictions from all base learners based on a majority voting mechanism. An intersting characteristic of hyperbox-based models is resulting hyperboxes from all base learners or decision trees can be merged to formulate a single model. This contributes to increasing the explainability of the estimator while still taking advantage of strong points of ensemble models.
Multigranularity learning
Multi-granularity learning algorithms can construct classifiers from multiresolution hierarchical granular representations using hyperbox fuzzy sets. This algorithm forms a series of granular inferences hierarchically through many levels of abstraction. An attractive characteristic of these classifiers is that they can maintain a high accuracy in comparison to other fuzzy min-max models at a low degree of granularity based on reusing the knowledge learned from lower levels of abstraction.
Learning from both labelled and unlabelled data
One of the exciting features of learning algorithms for the general fuzzy min-max neural network is the capability of creating classification boundaries among known classes and clustering data and representing them as hyperboxes in the case that labels are not available. Unlabelled hyperboxes is then possible to be labelled on the basis of the evidence of next incoming input samples. As a result, the GFMMNN models have the ability to learn from the mixed labelled and unlabelled datasets in a native way.
Ability to directly process missing data
Learning algorithms for the general fuzzy min-max neural network supported by the library may classify inputs with missing data directly without the need for replacing or imputing missing values as in other classifiers.
Continual learning of new classes in an incremental manner
Incremental learning algorithms of hyperbox-based models in the hyperbox-brain library can grow and accommodate new classes of data without retraining the whole classifier. Incremental learning algorithms themselves can generate new hyperboxes to represent clusters of new data with potentially new class labels both in the middle of normal training procedure and in the operating time where training has been finished. This property is a key feature for smart life-long learning systems.
Data editing and pruning approaches
By combining the repeated cross-validation methods provided by scikit-learn and hyperbox-based learning algorithms, evidence from training multiple models can be deployed for identifying which data points from the original training set or the hyperboxes from the generated multiple models should be retained and those that should be edited out or pruned before further processing.
Scikit-learn compatible estimators
The estimators in hyperbox-brain is compatible with the well-known scikit-learn toolbox. Therefore, it is possible to use hyperbox-based estimators in scikit-learn pipelines, scikit-learn hyperparameter optimizers (e.g., grid search and random search), and scikit-learn model validation (e.g., cross-validation scores). In addition, the hyperbox-brain toolbox can be used within hyperparameter optimisation libraries built on top of scikit-learn such as hyperopt.
Explainability of predicted results
The hyperbox-brain library can provide the explanation of predicted results via visualisation. This toolbox provides the visualisation of existing hyperboxes and the decision boundaries of a trained hyperbox-based model if input features are two-dimensional features:
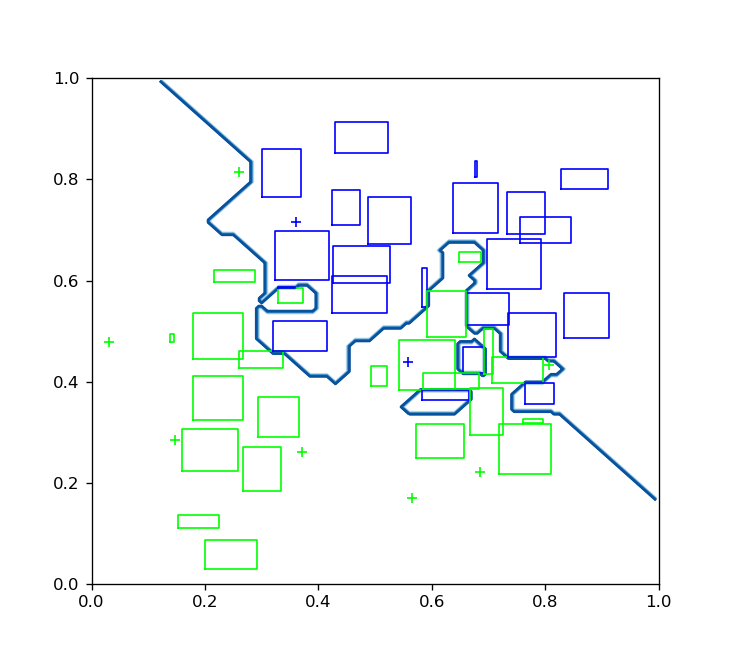
For two-dimensional data, the toolbox also provides the reason behind the class prediction for each input sample by showing representative hyperboxes for each class which join the prediction process of the trained model for an given input pattern:
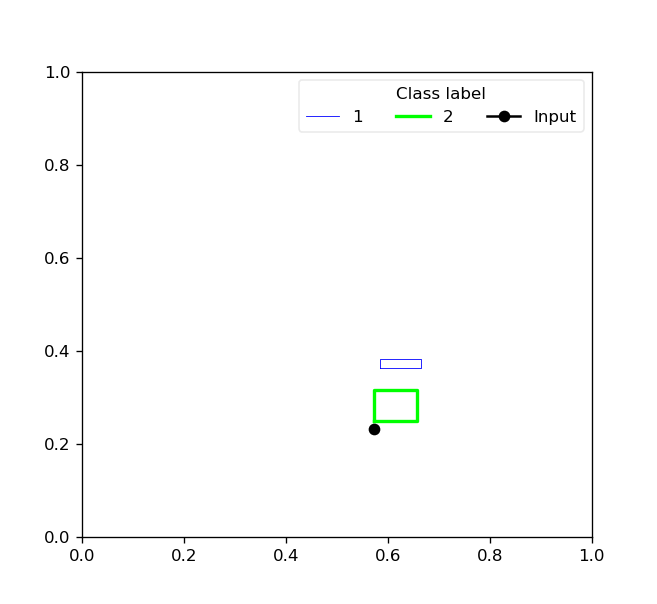
For input patterns with two or more dimensions, the hyperbox-brain toolbox uses a parallel coordinates graph to display representative hyperboxes for each class which join the prediction process of the trained model for an given input pattern:
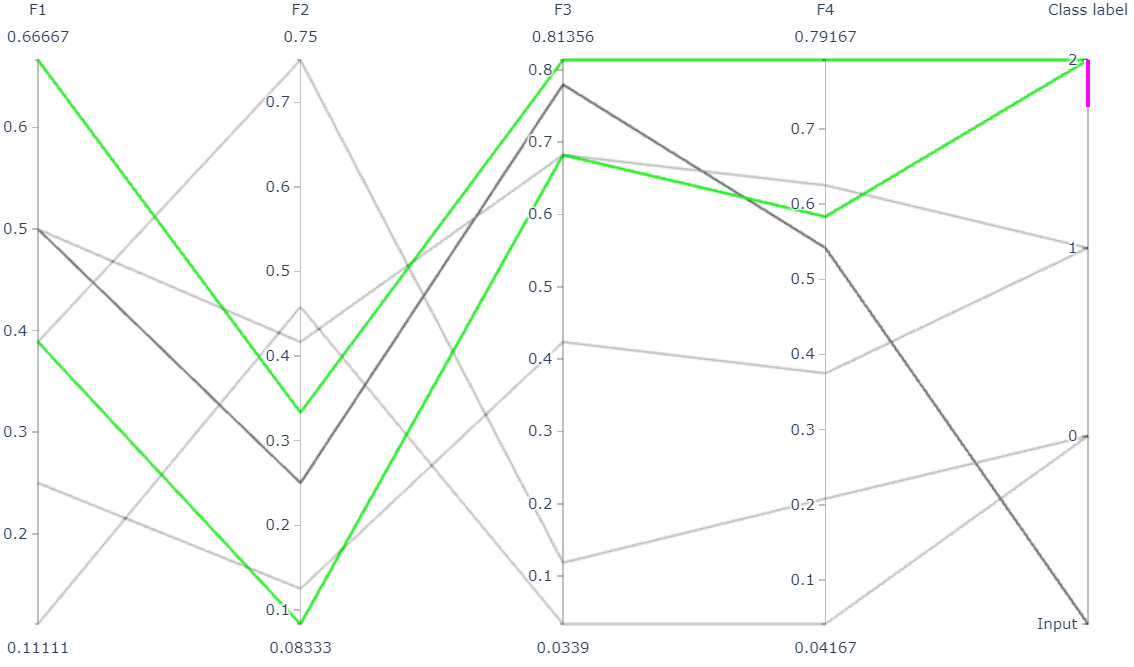
Easy to use
Hyperbox-brain is designed for users with any experience level. Learning models are easy to create, setup, and run. Existing methods are easy to modify and extend.
Jupyter notebooks
The learning models in the hyperbox-brain toolbox can be easily retrieved in notebooks in the Jupyter or JupyterLab environments.
In order to display plots from hyperbox-brain within a Jupyter Notebook we need to define the proper mathplotlib backend to use. This can be performed by including the following magic command at the beginning of the Notebook:
%matplotlib notebookJupyterLab is the next-generation user interface for Jupyter, and it may display interactive plots with some caveats. If you use JupyterLab then the current solution is to use the jupyter-matplotlib extension:
%matplotlib widgetExamples regarding how to use the classes and functions in the hyperbox-brain toolbox have been written under the form of Jupyter notebooks.
Available models
The following table summarises the supported hyperbox-based learning algorithms in this toolbox.
Model |
Feature type |
Model type |
Learning type |
Implementation |
Example |
References |
|---|---|---|---|---|---|---|
EIOL-GFMM |
Mixed |
Single |
Instance-incremental |
|||
Freq-Cat-Onln-GFMM |
Mixed |
Single |
Batch-incremental |
|||
OneHot-Onln-GFMM |
Mixed |
Single |
Batch-incremental |
|||
Onln-GFMM |
Continuous |
Single |
Instance-incremental |
|||
IOL-GFMM |
Continuous |
Single |
Instance-incremental |
|||
FMNN |
Continuous |
Single |
Instance-incremental |
|||
EFMNN |
Continuous |
Single |
Instance-incremental |
|||
KNEFMNN |
Continuous |
Single |
Instance-incremental |
|||
RFMNN |
Continuous |
Single |
Instance-incremental |
|||
AGGLO-SM |
Continuous |
Single |
Batch |
|||
AGGLO-2 |
Continuous |
Single |
Batch |
|||
MRHGRC |
Continuous |
Granularity |
Multi-Granular learning |
|||
Decision-level Bagging of hyperbox-based learners |
Continuous |
Combination |
Ensemble |
|||
Decision-level Bagging of hyperbox-based learners with hyper-parameter optimisation |
Continuous |
Combination |
Ensemble |
|||
Model-level Bagging of hyperbox-based learners |
Continuous |
Combination |
Ensemble |
|||
Model-level Bagging of hyperbox-based learners with hyper-parameter optimisation |
Continuous |
Combination |
Ensemble |
|||
Random hyperboxes |
Continuous |
Combination |
Ensemble |
|||
Random hyperboxes with hyper-parameter optimisation for base learners |
Continuous |
Combination |
Ensemble |
Examples
To see more elaborate examples, look here.
Simply use an estimator by initialising, fitting and predicting:
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from hbbrain.numerical_data.incremental_learner.onln_gfmm import OnlineGFMM
# Load dataset
X, y = load_iris(return_X_y=True)
# Normalise features into the range of [0, 1] because hyperbox-based models only work in a unit range
scaler = MinMaxScaler()
scaler.fit(X)
X = scaler.transform(X)
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Training a model
clf = OnlineGFMM(theta=0.1).fit(X_train, y_train)
# Make prediction
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f'Accuracy = {acc * 100: .2f}%')Using hyperbox-based estimators in a sklearn Pipeline:
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from hbbrain.numerical_data.incremental_learner.onln_gfmm import OnlineGFMM
# Load dataset
X, y = load_iris(return_X_y=True)
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create a GFMM model
onln_gfmm_clf = OnlineGFMM(theta=0.1)
# Create a pipeline
pipe = Pipeline([
('scaler', MinMaxScaler()),
('onln_gfmm', onln_gfmm_clf)
])
# Training
pipe.fit(X_train, y_train)
# Make prediction
acc = pipe.score(X_test, y_test)
print(f'Testing accuracy = {acc * 100: .2f}%')Using hyperbox-based models with random search:
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import train_test_split
from hbbrain.numerical_data.ensemble_learner.random_hyperboxes import RandomHyperboxesClassifier
from hbbrain.numerical_data.incremental_learner.onln_gfmm import OnlineGFMM
# Load dataset
X, y = load_breast_cancer(return_X_y=True)
# Normalise features into the range of [0, 1] because hyperbox-based models only work in a unit range
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialise search ranges for hyper-parameters
parameters = {'n_estimators': [20, 30, 50, 100, 200, 500],
'max_samples': [0.2, 0.3, 0.4, 0.5, 0.6],
'max_features' : [0.2, 0.3, 0.4, 0.5, 0.6],
'class_balanced' : [True, False],
'feature_balanced' : [True, False],
'n_jobs' : [4],
'random_state' : [0],
'base_estimator__theta' : np.arange(0.05, 0.61, 0.05),
'base_estimator__gamma' : [0.5, 1, 2, 4, 8, 16]}
# Init base learner. This example uses the original online learning algorithm to train a GFMM classifier
base_estimator = OnlineGFMM()
# Using random search with only 40 random combinations of parameters
random_hyperboxes_clf = RandomHyperboxesClassifier(base_estimator=base_estimator)
clf_rd_search = RandomizedSearchCV(random_hyperboxes_clf, parameters, n_iter=40, cv=5, random_state=0)
# Fit model
clf_rd_search.fit(X_train, y_train)
# Print out best scores and hyper-parameters
print("Best average score = ", clf_rd_search.best_score_)
print("Best params: ", clf_rd_search.best_params_)
# Using the best model to make prediction
best_gfmm_rd_search = clf_rd_search.best_estimator_
y_pred_rd_search = best_gfmm_rd_search.predict(X_test)
acc_rd_search = accuracy_score(y_test, y_pred_rd_search)
print(f'Accuracy (random-search) = {acc_rd_search * 100: .2f}%')Citation
If you use hyperbox-brain in a scientific publication, we would appreciate citations to the following paper:
@article{khga23,
title={hyperbox-brain: A Python toolbox for hyperbox-based machine learning algorithms},
author={Khuat, Thanh Tung and Gabrys, Bogdan},
journal={SoftwareX},
volume={23},
pages={101425},
year={2023},
url={https://doi.org/10.1016/j.softx.2023.101425},
publisher={Elsevier}
}
Contributing
Feel free to contribute in any way you like, we’re always open to new ideas and approaches.
There are some ways for users to get involved:
Issue tracker: this place is meant to report bugs, request for minor features, or small improvements. Issues should be short-lived and solved as fast as possible.
Discussions: in this place, you can ask for new features, submit your questions and get help, propose new ideas, or even show the community what you are achieving with hyperbox-brain! If you have a new algorithm or want to port a new functionality to hyperbox-brain, this is the place to discuss.
Contributing guide: in this place, you can learn more about making a contribution to the hyperbox-brain toolbox.
License
Hyperbox-brain is free and open-source software licensed under the GNU General Public License v3.0.
References


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file hyperbox_brain-0.1.6-py3-none-any.whl.
File metadata
- Download URL: hyperbox_brain-0.1.6-py3-none-any.whl
- Upload date:
- Size: 250.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
73c94a30f64730039f378d8c6e9be7970d1e609332d5d1d14e6bb2080d31bd50
|
|
| MD5 |
55308f4f7e3d3db5fc888b0370844bd8
|
|
| BLAKE2b-256 |
f9900facb65eb4d44c88fcb054522c9ffde783ca9a58b967da3814314480559f
|







