Inflated Discrete Choice Models

Project description
IDCeMPy: Python Package for Inflated Discrete Choice Models
Nguyen K. Huynh, Sergio Bejar, Vineeta Yadav, Bumba Mukherjee





IDCeMPy is a Python package that provides functions to fit and assess the performance of the following distinct sets of “inflated” discrete choice models.
- Fit the Zero-Inflated Ordered Probit (ZIOP) model without and with correlated errors (ZIOPC model) to evaluate zero-inflated ordered choice outcomes that result from a dual data generating process (d.g.p.).
- Fit the Middle-Inflated Ordered Probit (MIOP) model without and with correlated errors (MIOPC) to account for the inflated middle-category in ordered choice measures related to a dual d.g.p.
- Fit Generalized Inflated Multinomial Logit (GIMNL) models account for the predominant and heterogeneous share of observations in the baseline or any lower category in unordered polytomous choice outcomes.
- Compute AIC and Log-likelihood statistics and the Vuong Test statistic to assess the performance of each inflated discrete choice model in the package.
IDCeMPy uses Newton numerical optimization methods to estimate the inflated discrete choice models listed above via Maximum Likelihood Estimation (MLE).
IDCeMPY is compatible with Python 3.7+
Why IDCeMPy?
An excessive (“inflated”) share of observations—stemming from two distinct d.g.p’s—fall into a single choice category in many ordered and unordered polytomous outcome variables. Standard Ordered Probit and Multinomial Logit models cannot account for such category inflation which leads to biased inferences. Examples include,
-
The inflated zero-category of "no smoking" in ordered measures of self-reported smoking behavior is generated from nonsmokers who never smoke cigarettes and those who smoked previously but temporarily stopped smoking because of high cigarette prices.
-
The inflated "indifference" middle-category in ordered measures of immigration attitudes includes respondents truly indifferent to immigration and those that choose indifference for social desirability reasons.
-
The inflated baseline or other lower outcome categories of unordered polytomous outcome measures of vote choice include nonvoters who temporarily abstain from voting and routine nonvoters who always abstain.
IDCeMPy includes the ZIOP(C) models for evaluating zero-inflated ordered choice outcomes that result from a dual d.g.p, the MIOP(C) models that address inflated middle-category ordered outcome measures arising from distinct d.g.p’s, and GIMNL models that account for inflated baseline or other categories for unordered polytomous outcomes.
Each inflated discrete choice model in this package addresses category inflation in one’s discrete outcome—unordered or unordered polytomous—of interest by jointly estimating a binary split-stage equation and an ordered or multinomial discrete choice outcome equation.
Functions in the IDCeMPy Package
| Function | Description |
|---|---|
opmod; iopmod; iopcmod |
Fits the ordered probit model, the Zero-Inflated (ZIOP) & Middle-Inflated ordered probit (MIOP) models without correlated errors, and the ZIOPC & MIOPC models that incorporate correlated errors. |
opresults; iopresults; iopcresults |
Presents covariate estimates, Variance-Covariance (VCV) matrix, and goodness-of-fit statistics (Log-Likelihood and AIC) of opmod, iopmod, iopcmod. |
iopfit; iopcfit |
Computes fitted probabilities from each estimated model's object. |
vuong_opiop; vuong_opiopc |
Calculates Vuong test statistic for comparing the OP model's performance to ZiOP(C) and MiOP(C) models. |
split_effects; ordered_effects |
Estimates marginal effects of covariates from the split and outcome-stage respectively. |
mnlmod; gimnlmod |
Fits MNL model and Generalized-Inflated MNL models. |
mnlresults; gimnlresults; vuong_gimnl |
Presents covariate estimates, VCV matrix, and goodness-of-fit statistics of mnlmod, gimnlmod. Vuong test statistic for comparing MNL to GIMNL models obtained from vuong_gimnl |
Dependencies
- scipy
- numpy
- pandas
Installation
From PyPi:
pip install idcempy
From GitHub
git clone https://github.com/hknd23/idcempy.git
cd idcempy
python setup.py install
On readthedocs you will find the installation guide, a complete overview of each feature included in IDCeMPy, and example scripts of all the models.
Using the Package
Example 1: Zero-inflated Ordered Probit Model with Correlated Errors (ZIOPC)
We illustrate how IDCeMPy can be used to estimate the OP and ZIOP(C) models for zero-inflated ordered outcome variables by using the CDC's 2018 National Youth Tobacco Dataset. The self-reported ordered tobacco consumption outcome variable in this data ranges from 0 for "no smoking" to 4 for "15 or more cigarettes". The zero "no smoking" category contains excessive observations that include permanent nonsmokers who never smoke (non-inflated cases) and transient nonsmokers (inflated cases) who temporarily stopped smoking because of high cigarette prices.
IDCeMPy allows users to fit the ordered probit (OP) and Zero-inflated Ordered Probit (ZIOP) model without and with correlated errors (ZIOPC). The application of the OP model (available from opmod) and ZIOP model without correlated errors (see iopmod) to the CDC's 2018 Tobacco Consumption data is provided in the package's documentation. We fit the Zero-Inflated Ordered Probit Model with correlated errors to this data below.
First, install pandas and matplotlib to import and visualize data (if the packages are not already installed):
pip install pandas
pip install matplotlib
pip install urllib
Then, import IDCeMPy, required packages, and dataset.
from idcempy import zmiopc
import pandas as pd
import matplotlib.pyplot as plot
import urllib
url = 'https://github.com/hknd23/idcempy/raw/main/data/tobacco_cons.csv'
data = pd.read_csv(url)
Users can define the lists with the names of the covariates to include in the ZIOPC model's split-stage (Z), the OP outcome-stage (X) as well as the zero-inflated ordered outcome variable (Y).
X = ['age', 'grade', 'gender_dum']
Y = ['cig_count']
Z = ['gender_dum']
The default value of the starting parameters is set to .01. Users can, however, define an array of starting parameters before estimating the ziopc model and add it as an argument in the iopcmod function.
The following line of code creates a ziopc regression object model.
ziopc_tob = zmiopc.iopcmod('ziopc', data, X, Y, Z, method='bfgs',
weights=1, offsetx=0, offsetz=0)
Users can estimate the ZIOP model without correlated errors by using zmiopc.iopmod and the parameter 'ziop'. Please note that the models with correlated errors estimated with zmiopc.iopcmod have substantially higher run-time than zmiopc.iopmod. The above model takes roughly 1 hour and 8 minutes (on Windows 10, Intel Core i7-2600, 16GB RAM).
The results from the ZIOPC model for this application are stored in a class (ZiopcModel) with the following attributes:
- coefs: Model coefficients and standard errors
- llik: Log-likelihood
- AIC: Akaike information criterion
- vcov: Variance-covariance matrix
We can generate the covariate estimates, standard errors, p value and t statistics in the ZIOPC case by typing:
print(ziopc_tob.coefs)
Coef SE tscore p 2.5% 97.5%
Probit Split-stage
-----------------------
intercept 9.538072 3.470689 2.748178 5.992748e-03 2.735521 16.340623
gender_dum -9.165963 3.420056 -2.680062 7.360844e-03 -15.869273 -2.462654
OP Outcome-stage
-----------------------
age -0.028606 0.008883 -3.220369 1.280255e-03 -0.046016 -0.011196
grade 0.177541 0.010165 17.465452 0.000000e+00 0.157617 0.197465
gender_dum 0.602136 0.053084 11.343020 0.000000e+00 0.498091 0.706182
cut1 1.696160 0.044726 37.923584 0.000000e+00 1.608497 1.783822
cut2 -0.758095 0.033462 -22.655678 0.000000e+00 -0.823679 -0.692510
cut3 -1.812077 0.060133 -30.134441 0.000000e+00 -1.929938 -1.694217
cut4 -0.705836 0.041432 -17.036110 0.000000e+00 -0.787043 -0.624630
rho -0.415770 0.074105 -5.610526 2.017123e-08 -0.561017 -0.270524
The Akaike Information Criterion (AIC) statistics for the ZIOPC model is given by,
print(ziopc_tob.AIC)
16061.716497590078
The AIC of the OP and ZIOP models reported in the documentation is 8837.44 and 10138.32, respectively.
split_effects creates a dataframe that provides values to illustrate via boxplots (with 95% Confidence Intervals) the marginal effect of the ZIOP(C) model's split-stage covariates on the first difference in the predicted probability that the zero-category observations are non-inflated. In the tobacco consumption example,split_effects provides and illustrates via boxplots (with 95% CIs) the first difference in the predicted probability of zero-category observations being permanent nonsmokers (non-inflated cases) when the dummy split-stage covariate 'gender_dum' changes from 0 (female) to 1 (male).
ziopcgender_split = zmiopc.split_effects(ziopc_tob, 1)
ziopcgender_split.plot.box(grid='False')
plot.show()
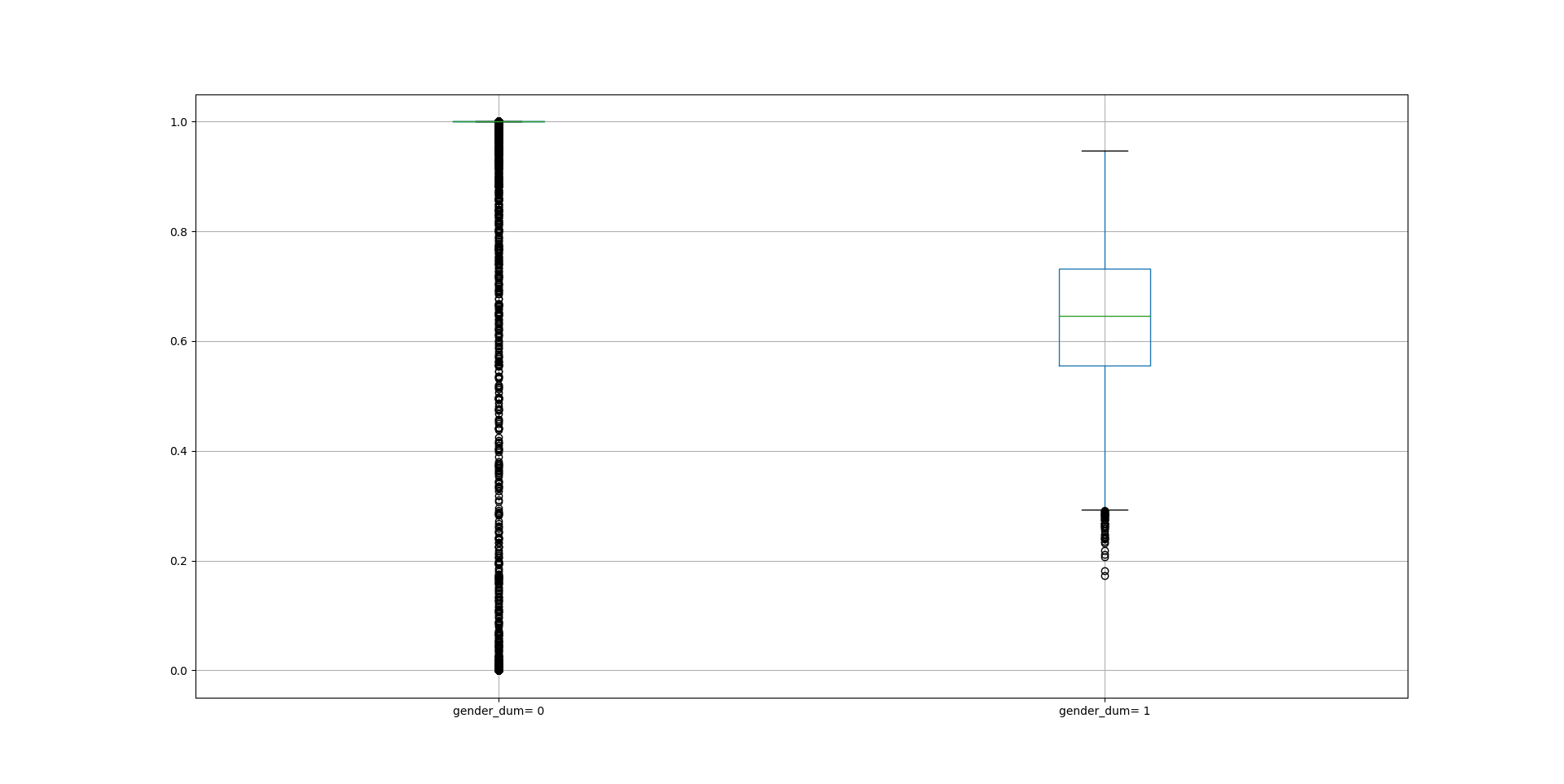
Fig. 1: Marginal Effect of Gender on Probability of Permanent Nonsmoker
ordered_effectscreates a dataframe that provides values to illustrate the marginal effect of the ZIOP(C) model's outcome-stage covariates on the first difference in the predicted probability of each ordered outcome category conditional on the zero-category observations being non-inflated. In the example below, ordered_effectsprovides and illustrate via boxplots (with 95% CIs) the first difference in the predicted probability (with 95% CIs) of each 0 to 4 ordered category of the tobacco consumption outcome when the dummy outcome-stage covariate 'gender_dum' changes from 0 to 1, conditional on zero-category observations being non-inflated.
ziopcgender_ordered = zmiopc.ordered_effects(ziopc_tob, 2)
ziopcgender_ordered.plot.box(grid='False')
plot.show()
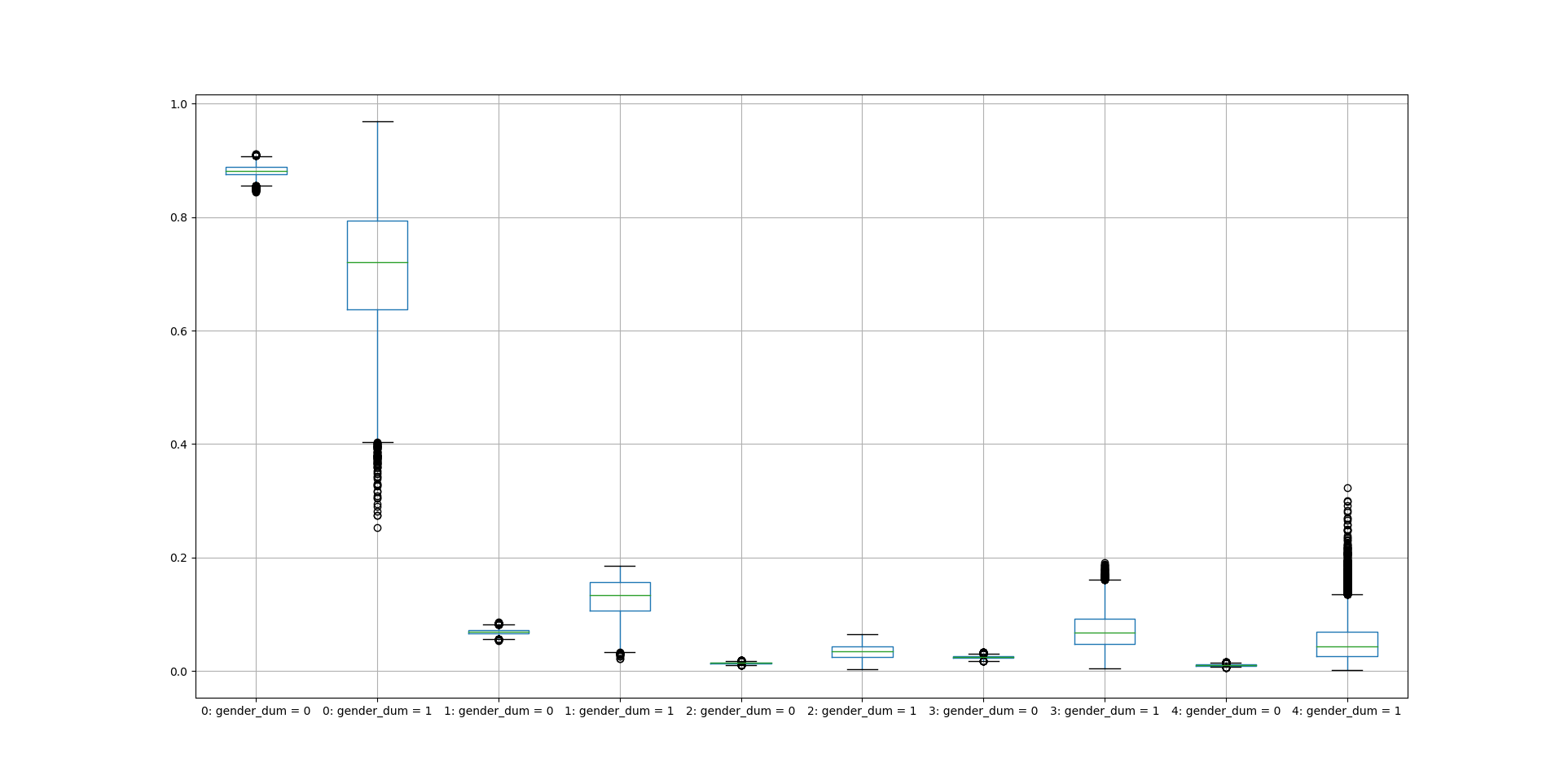
Fig. 2: Marginal Effect of Gender on Self-Reported Tobacco Consumption
Module zmiopc also provides the function vuong_opiopc that employs the Vuong test statistic to compare the performance of the standard OP model (also available through opmod) versus the ZIOPC model and also the OP versus ZIOP model. The Vuong statistics from comparing the OP and the ZIOPC model is given by,
op_tob = zmiopc.opmod(data, X, Y)
zmiopc.vuong_opiopc(op_tob, ziopc_tob)
6.576246015382724
The Vuong test statistic favors the OP over both the ZIOPC model and ZIOP model (see documentation).
Example 2: Middle-inflated Ordered Probit Models with Correlated Errors (MIOPC)
We next illustrate how IDCeMPy can be employed to fit the OP and MIOP(C) models for inflated middle-category ordered outcome variables. This is done by using Elgün and Tillman's (2007) survey-response data in which the ordered outcome measure of support for the European Union (EU) by Europeans is given by 1 for “a bad thing,” 2 for “neither good nor bad,” and 3 for “a good thing.” The middle (neither good nor bad) category in this ordered measure contains excessive observations that include informed respondents who opt for this category based on their knowledge about the EU and uninformed respondents who choose this category to save face.
IDCeMPy allows users to fit the OP and Middle-inflated Ordered Probit (MIOP) model without and with correlated errors (MIOPC). The application of the OP model from opmod and MIOP model without correlated errors from iopmod to the EU support data is provided in the package's documentation. Users can estimate the MIOP model without correlated errors by simply substituting 'miop' for 'miopc'.
We turn to fit the Middle-Inflated Ordered Probit Model with correlated errors (MIOPC) to the aforementioned data. To this end, first load the dataset.
url = 'https://github.com/hknd23/idcempy/raw/main/data/EUKnowledge.dta'
data = pd.read_stata(url)
Users can define the lists with names of the covariates they would like to include in the MIOPC model's split-stage (Z) and the second-stage (X) as well as the name of the ordered "middle-inflated" outcome variable (Y).
Y = ["EU_support_ET"]
X = ['Xenophobia', 'discuss_politics']
Z = ['discuss_politics', 'EU_Know_obj']
Run the model and print the results (this MiOPC specification takes roughly 31 minutes to finish):
miopc_EU = zmiopc.iopcmod('miopc', data, X, Y, Z)
print(miopc_EU.coefs)
Coef SE tscore p 2.5% 97.5%
Probit Split-stage
---------------------------
int -0.129 0.021 -6.188 0.000 -0.170 -0.088
discuss_politics 0.192 0.026 7.459 0.000 0.142 0.243
EU_Know_obj 0.194 0.027 7.154 0.000 0.141 0.248
OP Outcome-stage
---------------------------
Xenophobia -0.591 0.045 -13.136 0.000 -0.679 -0.502
discuss_politics -0.029 0.021 -1.398 0.162 -0.070 0.012
cut1 -1.370 0.044 -30.948 0.000 -1.456 -1.283
cut2 -0.322 0.103 -3.123 0.002 -0.524 -0.120
rho -0.707 0.106 -6.694 0.000 -0.914 -0.500
The AIC statistic for the MIOPC model is obtained from,
print(miopc_EU.AIC)
21669.96812802041
The AIC statistics for the MIOP model is 21729.39 and the OP model is 22100.90 (see documentation).
In this EU support example, the split_effects dataframe provides and illustrates via boxplots (with 95% CI) the first difference in the predicted probability of middle-category observations being informed respondents (non-inflated cases) when the split-stage covariate 'EU_know_obj' is increased by one standard deviation from its mean value (for continuous variables, the "=0" and "=1" box plots represents the mean and one standard deviation above mean value, respectively).
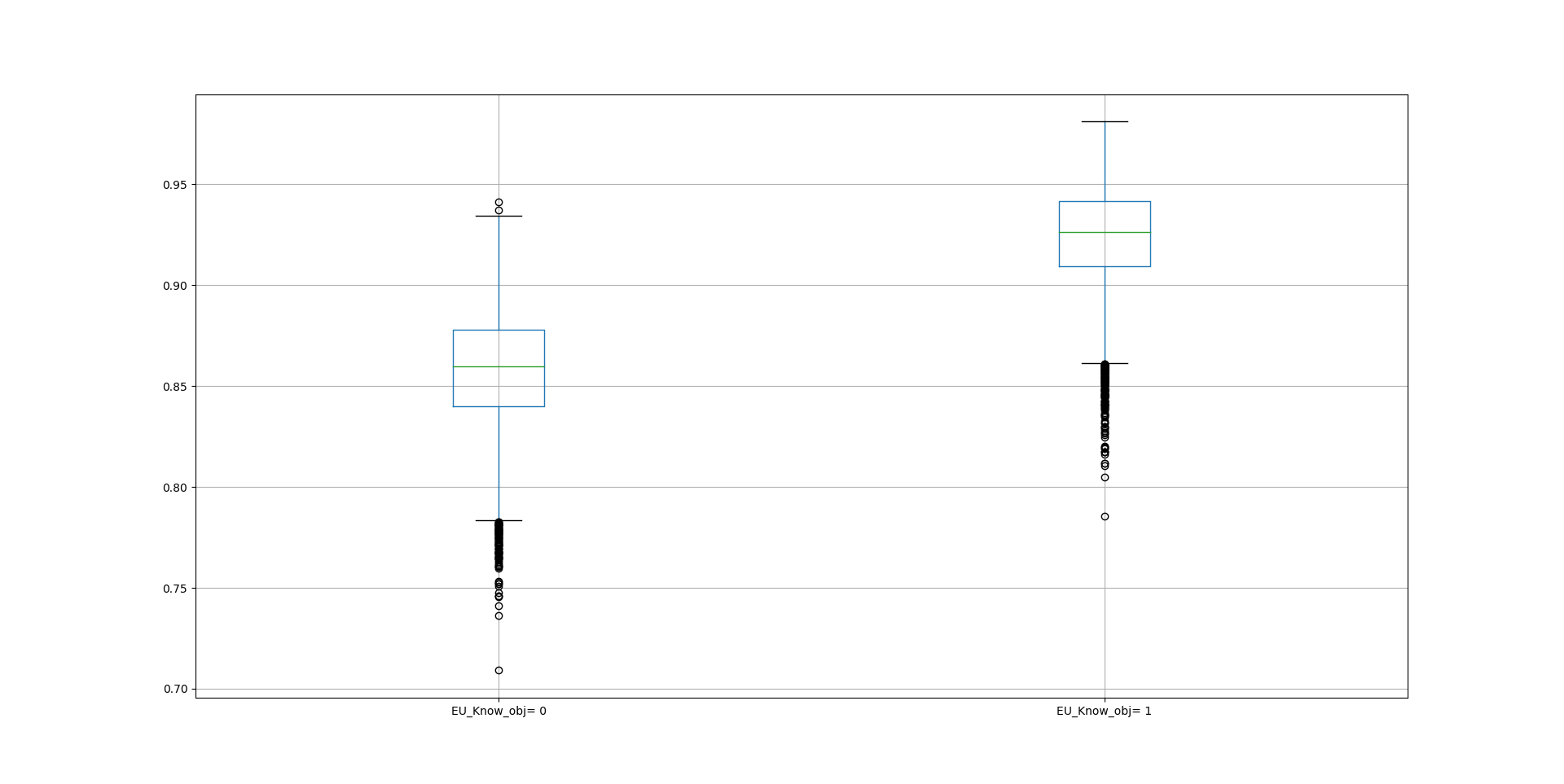
Fig. 3: Marginal Effect of EU Knowledge on Probability of Informed Respondents
ordered_effects() calculates and illustrates via boxplots (with 95% CI) the first difference in predicted probabilities of each ordered outcome category of "EU Support" when the outcome-stage Xenophobia covariate is increased by 1 standard deviation from its mean value, conditional on middle-category observations being informed respondents.
xeno = zmiopc.ordered_effects(miopc_EU, 2)
xeno.plot.box(grid='False')
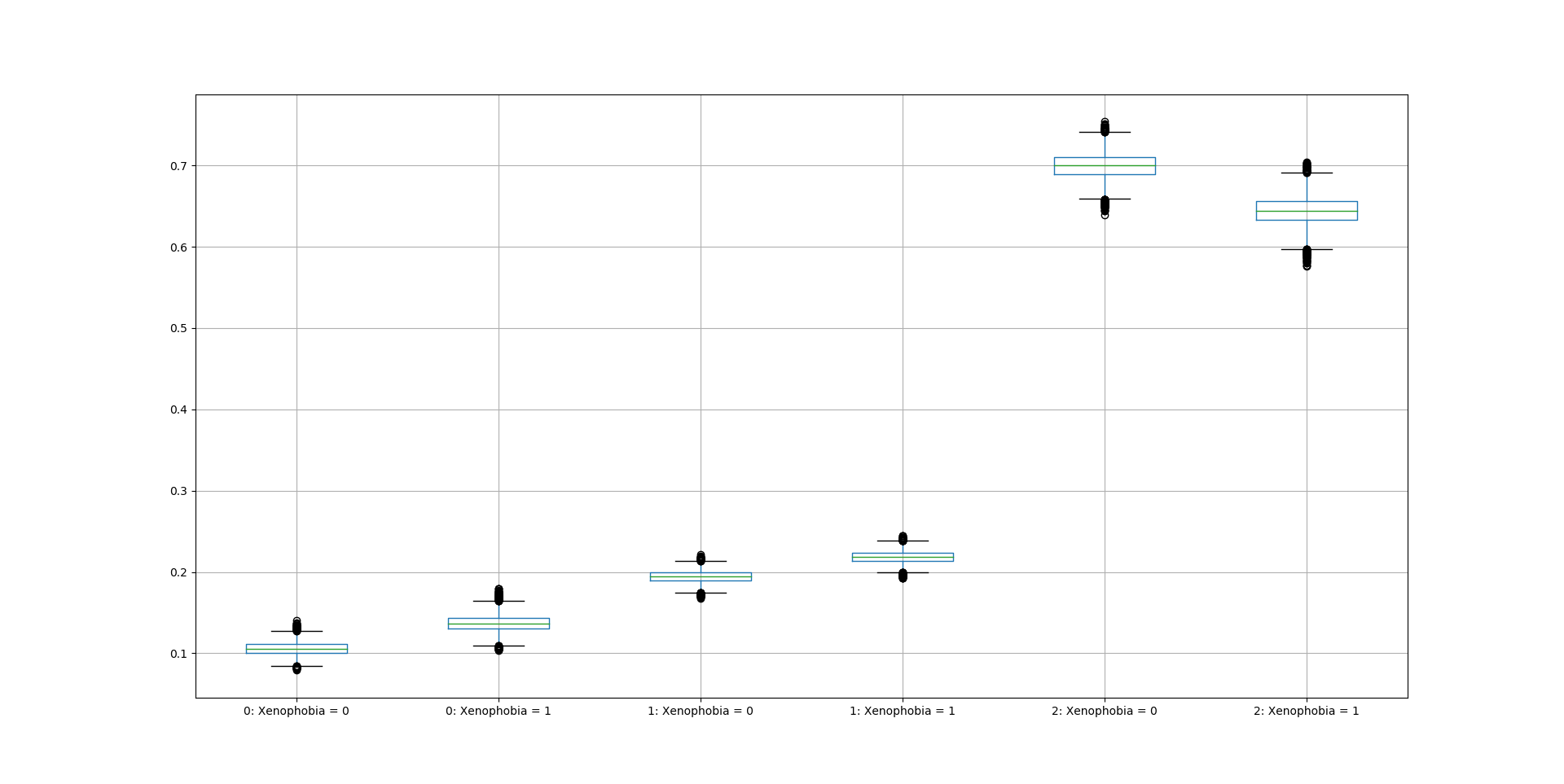
Fig. 4: Marginal Effect of Xenophobia on EU Support
Users can call the function vuong_opiopc to employ the Vuong test stastic to compare the OP model to the MIOPC model and also the OP to the MIOP model. The Vuong test statistics from comparing the OP to the MIOPC model is,
op_EU = zmiopc.opmod(DAT, X, Y)
zmiopc.vuong_opiopc(op_EU, miopc_EU)
-10.435718518003675
The Vuong test statistic thus favors the MIOPC over the OP model, and also the MIOP over the OP model (see documentation).
Example 3: Generalized Inflated Multinomial Logit Models (GIMNL)
IDCeMPy also includes functions to fit the GIMNL and standard MNL models. The Generalized Inflated Multinomial Logit Models account for the inflated and thus heterogeneous share of observations that can exist in the baseline or any other category of unordered polytomous outcome variables. To save space, we focus on just presenting the "Baseline" Inflated MNL (i.e., BIMNL) model that addresses excessive observations in the baseline category of unordered outcome measures. We fit this BIMNL model to the 2004 Presidential vote choice data from Campbell and Monson (2008). The 0,1,2 unordered-polytomous Presidential vote choice dependent variable in their data includes the following options: abstained (their MNL baseline category), Bush, or Kerry. The inflated baseline category incorporates excessive observations of abstained nonvoters who did not vote in the said elections due to temporary factors and routine nonvoters who never vote.
Users can fit the standard MNL model(available from mnlmod) to the Campbell and Monson (2008) data, which is described in the documentation. To illustrate how users can fit the BIMNL model to this data, however, we begin by importing the gimnl module.
from idcempy import gimnl
url= 'https://github.com/hknd23/idcempy/raw/main/data/replicationdata.dta'
data= pd.read_stata(url)
Define the unordered vote choice outcome variable in the BIMNL as Y, whose unordered categories are given by 0,1,2. Denote the covariates in this model's logit split-stage as Z and X for the MNL-outcome stage for each unordered category 1 and 2.
x = ['educ', 'party7', 'agegroup2']
z = ['educ', 'agegroup2']
y = ['vote_turn']
reference = [0, 1, 2]
inflatecat = "baseline"
The argument inflatecat can be used to specify any unordered category as the inflated category in their unordered-polytomous outcome measure. Further, from the argument reference, users can select which category of the unordered outcome variable is the baseline ("reference") category by placing it first. Since the baseline ("0") category in the Presidential vote choice outcome measure is inflated, the following code fits the BIMNL Model,
gimnl_2004vote = gimnl.gimnlmod(data, x, y, z, reference, inflatecat)
Print the estimates:
Coef SE tscore p 2.5% 97.5%
Logit Split-stage
----------------------
intercept -4.935 2.777 -1.777 0.076 -10.379 0.508
educ 1.886 0.293 6.441 0.000 1.312 2.460
agegroup2 1.295 0.768 1.685 0.092 -0.211 2.800
MNL Outcome Category 1
---------------------
intercept -4.180 1.636 -2.556 0.011 -7.387 -0.974
educ 0.334 0.185 1.803 0.071 -0.029 0.697
party7 0.454 0.057 7.994 0.000 0.343 0.566
agegroup2 0.954 0.248 3.842 0.000 0.467 1.441
MNL Outcome Category 2
----------------------
intercept 0.900 1.564 0.576 0.565 -2.166 3.966
educ 0.157 0.203 0.772 0.440 -0.241 0.554
party7 -0.577 0.058 -9.928 0.000 -0.691 -0.463
agegroup2 0.916 0.235 3.905 0.000 0.456 1.376
The AIC statistic for the BIMNL model is given by,
print(gimnl_2004vote.AIC)
1656.8324085039708
The AIC for the standard MNL model (see documentation) is 1657.19. The Vuong statistic for comparing the MNL to the BIMNL model in this case is,
mnl_2004vote = gimnl.mnlmod(data, x, y, reference)
gimnl.vuong_gimnl(mnl_2004vote, gimnl_2004vote)
-1.2835338187781173
Users can employ the argument inflatecat to specify any unordered category as the inflated category (dictated by the distribution) in their unordered-polytomous outcome measure. If a higher category (say 1 or 2) is inflated in the 0,1,2 unordered-polytomous outcome measure, then users can specify reference and inflatecat as follows,
gimnl.gimnlmod(data, x, y, z, reference, inflatecat = "second")
gimnl.gimnlmod(data, x, y, z, reference, inflatecat = "third")
Contributions
The authors welcome and encourage new contributors to help test IDCeMPy and add new functionality. Issues can be raised by any users for questions and bug reports. For further details, see Guidelines for Contributors.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file idcempy-0.1.1.tar.gz.
File metadata
- Download URL: idcempy-0.1.1.tar.gz
- Upload date:
- Size: 40.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.0.1 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.54.1 CPython/3.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5a18d310ebea9730c9c411f9957ad533fb58f394a7f4217b3cacb26b759ebc33
|
|
| MD5 |
a5b19f204470ef31a6ed016f5e3202ab
|
|
| BLAKE2b-256 |
9a4cc59e283e8b023d5d12327d962035f61bb00edef95c5b5ae713418cd66bf4
|
File details
Details for the file idcempy-0.1.1-py3-none-any.whl.
File metadata
- Download URL: idcempy-0.1.1-py3-none-any.whl
- Upload date:
- Size: 36.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.0.1 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.54.1 CPython/3.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
772e931f2f2c90cc586d2defa9da8afe11ddfe5f62d409e5f73e8a1e9e1e17cd
|
|
| MD5 |
becd467e9ded97d2a29c6e4c2fa7b8a9
|
|
| BLAKE2b-256 |
5215ecd627ebc25cd32a0405eef4c4a17e1dbb906c787884e6accb7c37125b0d
|







