Using neural networks to extract sufficient statistics from data by maximising the Fisher information


Project description
Optimising a neural network to maximise the Fisher information provides us with a function able to massively compress data without losing information about parameters of interest. This function can then be used for likelihood-free inference.
The module here provides both the routines for fitting a neural network by maximising the Fisher information as well as a few methods for performing likelihood-free inference and approximate Bayesian computation.
Specifically, the neural network takes some data, 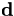
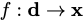
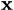
To train the neural network a batch of simulations 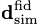
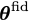
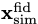
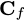
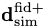
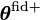
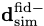
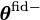
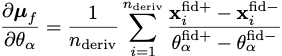
If the derivative of the simulations with respect to the parameters can be calculated analytically (or via autograd, etc.) then that can be used directly using the chain rule since the derivative of the network outputs with respect to the network input can be calculated easily
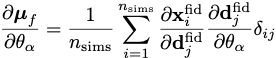
We then use 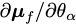
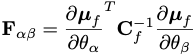
Since any linear rescaling of the summaries is also a summary, when maximising the Fisher information we set their scale using
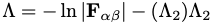
where
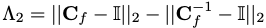
is a regularisation term whose strength is dictated by
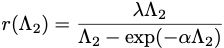
with 
When using this code please cite
Tom Charnock, Guilhem Lavaux and Benjamin D. Wandelt
Automatic physical inference with information maximizing neural networks.
Physical Review D. 97 083004 (2018)
doi:10.1103/PhysRevD.97.083004
arXiv:1802.03537
The code in the paper can be downloaded as v1 or v1.1 of the code kept on zenodo:
The code can be installed using:
pip install imnn-tf
or:
git clone https://bitbucket.org/tomcharnock/imnn-tf.git cd imnn-tf python3 setup.py install
Modules
Available are modules for fitting the IMNN in IMNN and for doing likelihood-free inference in LFI. Examples of how to use these modules are available in the examples directory.
IMNN
The basic call for the IMNN is
imnn = IMNN.IMNN(
n_s, n_d, n_params, n_summaries, θ_fid, δθ, input_shape,
fiducial, derivative, validation_fiducial, validation_derivative,
{model}, {optimiser}, {save}, {load}, {weights}, {directory},
{filename}, {at_once}, {map_fn}, {check_shape}, {verbose},
{dtype}, {itype})where
n_s - number of simulations to calculate covariance of fiducial simulations
n_d - number of simulations to calculate mean of the derivative simulations
n_params - number of parameters in the model
n_summaries - number of summaries to compress the data to
θ_fid - fiducial parameter values
δθ - parameter differences for numerical derivative
input_shape - shape of a single simulation
fiducial - a numpy array of fiducial simulations, generative function of individual fiducial simulations, or list of TFRecord filenames
derivative - a numpy array of derivative simulations, generative function of individual derivative simulations, or list of TFRecord filenames
validation_fiducial - a numpy array of fiducial simulations, generative function of individual fiducial simulations, or list of TFRecord filenames
validation_derivative - a numpy array of derivative simulations, generative function of individual derivative simulations, or list of TFRecord filenames
model - a keras-like model (optional if loading)
optimiser - a keras-like optimiser (optional if loading)
save - boolean describing whether to save or not (need directory and filename if save=True)
load - boolean describing whether to load model or not (need directory, `filename and optionally weights if load=True)
weights - string with name of file of saved weights
directory - string with directory to load or save model
filename - string with filename to load or save model
at_once - number of simulations to process with model at once (should be n_s if memory is large enough)
map_fn - function to preprocess data (None if no preprocessing)
check_shape - boolean describing whether to check shape of simulation on initialisation
verbose - boolean to turn on and off descriptive write out
dtype - TensorFlow float type (default tf.float32)
itype - TensorFlow int type (default tf.int32)
Fit
imnn.fit(
{n_iterations}, {λ}, {ϵ}, {reset}, {patience}, {min_iterations},
{checkpoint}, {tqdm_notebook}, {weight_file})where
n_iterations - number of iterations to run the fitting for (can be None when using patience)
λ - strength of the regularisation
ϵ - distance of covariance (and inverse covariance) from the identity
reset - boolean describing whether to reset weights and start training from scratch
patience - number of iterations of decreasing Fisher information of the validation set before stopping
min_iterations - number of iterations before early stopping turns on
checkpoint - number of iterations between model saving (default turned off)
tqdm_notebook - True if using a Jupyter notebook and False otherwise #TODO - make automatic (might already be implemented)
weight_file - string with filename to save model weights to
Once trained, statistics are saved in a history dictionary attribute imnn.history
"det_F" - determinant of the Fisher information of the training set
"det_C" - determinant of the covariance matrix of the training set
"det_Cinv" - determinant of the inverse covariance matrix of the training set
"dμ_dθ" - derivative of the mean of the training set summaries
"reg" - value of the regularisation
"r" - value of the dynamic strength of the regularisation
"val_det_F" - determinant of the Fisher information of the validation set
"val_det_C" - determinant of the covariance matrix of the validation set
"val_det_Cinv" - determinant of the inverse covariance matrix of the validation set
"val_dμ_dθ" - derivative of the mean of the validation set summaries
Plot
imnn.plot(
{regulariser}, {known_det_fisher}, {figsize})where
regulariser - boolean describing whether to plot the regularisation history
known_det_fisher - value of the determinant of the target Fisher information if already known
figsize - tuple with the size of the figure if not default
Estimate parameters
Gaussian estimates of the parameter values can be obtained from the network by running
imnn.get_estimate(input_data)where `input_data is data input to the network (shape None + input_shape). Note that if you want to make estimates without initialising the IMNN (once trained), the model can be loaded, along with the saved data during fit. For an IMNN saved with directory="model" and filename=model then an estimator can be made using
estimator_parameters = np.load("model/model/estimator.npz")
Finv = estimator_parameters["Finv"]
θ_fid = estimator_parameters["θ_fid"]
dμ_dθ = estimator_parameters["dμ_dθ"]
Cinv = estimator_parameters["Cinv"]
μ = estimator_parameters["μ"]
@tf.function:
def estimator(data):
return tf.add(
θ_fid,
tf.einsum(
"ij,jk,kl,ml->mi",
Finv,
dμ_dθ,
Cinv,
model(data) - μ))or
def estimator(data):
return θ_fid + np.einsum(
"ij,jk,kl,ml->mi",
Finv,
dμ_dθ,
Cinv,
model(data) - μ)Training and validation data format
The data must have the correct shape. For a single simulation with shape input_shape then a fiducial data array must have a shape of
fiducial.shape = (n_s,) + input_shapeThe derivatives need to have a shape of
derivative.shape = (n_d, 2, n_params) + input_shapewhere derivative[:, 0, ...] is the lower part of the numerical derivative and derivative[:, 1, ...] is the upper part of the numerical derivative and derivative[:, :, i, ...] labels the i th parameter.
If the data won’t fit in memory then we can load data via a generative function
def fiducial_loader(seed):
yield fiducial[seed], seed
def derivative_loader(seed, derivative, parameter):
yield derivative[seed, derivative, parameter] (seed, derivative, parameter)The function yields a single simulation at for each call labelled with the seed index (seed in range 0 to n_s) for the fiducial loader. The derivative loader yields a single simulation at a given seed, given upper or lower derivative and given parameter index (seed in range 0 to n_d, derivative in range 0 to 1, and parameter in range 0 to n_params). In the above functions, fiducial and derivative are some way of grabbing the data - it could be reading from file or from memory, etc. This has quite a bit of overhead and so it would be preferred to save the data as a TFRecord format. Instructions on how to do this for ingestion by the IMNN is available in the examples/TFRecords.ipynb and examples/IMNN - TFRecords.ipynb tutorials.
Network model and optimiser
The IMNN is based on keras-like network and optimisers, so an example could be
model = tf.keras.Sequential(
[tf.keras.Input(shape=input_shape),
tf.keras.layers.Dense(128),
LeakyReLU(0.01),
tf.keras.layers.Dense(128),
LeakyReLU(0.01),
tf.keras.layers.Dense(n_summaries),
])
opt = tf.keras.optimizers.Adam()Make sure to choose this network sensibly so that it best pulls the information from the data.
LFI
The LFI module provides a Gaussian approximation to the posterior, a simple approximation Bayesian computation (ABC) implementation and a population Monte Carlo (PMC). These work with any estimator and not just with the IMNN.
Gaussian approximation of the posterior
The Gaussian approximation takes the inverse Fisher information as the variance of a Gaussian posterior (as implied by the Cramer-Rao bound) whose mean is at the estimate value.
GA = LFI.GaussianApproximation(
target_data, prior, Fisher, get_estimate, {labels})where
target_data - as many pieces of data to be inferred (target_data.shape = (None,) + input_shape)
prior - the prior distribution which can be sampled from and whose probability can be evaluated with an event_shape of at least [1] (suggested to use a TensorFlow Probability distribution)
Fisher - Fisher information matrix (imnn.F or otherwise for non-IMNN)
get_estimate - function providing estimate of the n_params model parameters from the data (imnn.get_estimate or otherwise for non-IMNN)
labels - list of strings for labelling plots
Plot Fisher information
The inverse Fisher information can plotted using
GA.plot_Fisher({figsize})Gaussian approximation to the likelihood and posterior
The Gaussian approximation to the likelihood (prob) and the posterior (and their logarithms) can be obtained using
GA.log_prob({grid}, {gridsize})
GA.prob({grid}, {gridsize})
GA.log_posterior({grid}, {gridsize})
GA.posterior({grid}, {gridsize})where
grid - a set of parameters or an array of parameter or a meshgrid of parameter to evaluate the likelihood or posterior at (if None gridsize takes over)
gridsize - a tuple of length n_params with the size of the meshgrid to make #TODO might crash if GA.prior.low=-np.inf for any parameter or GA.prior.high=np.inf for any parameter. This defaults to 20 for every parameter if grid=None and gridsize is not provided
Plotting posterior
The posterior can be plotted using
GA.plot({grid}, {gridsize}, **kwargs)where **kwargs are a variety of matplotlib arguments.
Approximate Bayesian computation (ABC)
The ABC draws parameter values from the prior and makes simulations at these points. These simulations are then summarised and then the distance between these estimates and the estimate of the target data can be calculated. Estimates within some small ϵ-ball around the target estimate are approximately samples from the posterior. Note that the larger the value of ϵ, the worse the approximation to the posterior.
Note that a simulator of the data is needed. The simulator must be a function
def simulator(parameters, seed, simulator_args):
return simulationwhere seed is a random number generator and simulator_args is a dict of arguments. The seed and simulator_args are only for setting up the simulator - the function used in the ABC (and PMC) call must only take an array of parameters and return an array of simulations made at those parameter values. The function can call external codes, submit jobs on a cluster, etc. as long as the simulations are returned in the same order as the passed parameter array.
The ABC can be initialised using
ABC = LFI.ApproximateBayesianComputation(
target_data, prior, Fisher, get_estimate, simulator, {labels})where
target_data - as many pieces of data to be inferred (target_data.shape = (None,) + input_shape)
prior - the prior distribution which can be sampled from and whose probability can be evaluated with an event_shape of at least [1] (suggested to use a TensorFlow Probability distribution)
Fisher - Fisher information matrix (imnn.F or otherwise for non-IMNN)
get_estimate - function providing estimate of the n_params model parameters from the data (imnn.get_estimate or otherwise for non-IMNN)
simulator - function taking array of parameter values and returning simulations made at those values
labels - list of strings for labelling plots
Obtaining samples
The ABC can be run using
ABC(draws, {at_once}, {save_sims})or
ABC.ABC(draws, {at_once}, {save_sims}, {PMC}, {update})where
draws - the number of simulations to make (or parameter values to make the simulations if PMC=True)
at_once - boolean describing whether to process (and make) all simulations at once or not
save_sims - string with the filename to save the sims (as a .npy) if provided
PMC - boolean describing whether draws is a number of simulations or draws is an array of parameter values to make simulations at
update - boolean describing whether to update the ABC attributes onces the ABC is run or not
Once this is run the parameters, estimates, differences from the estimate and the target and the distance from the target are found as
ABC.parameters
ABC.estimates
ABC.differences
ABC.distances
Acception and rejection of samples
ABC only runs the simulations and calculates the estimate distances but doesn’t do the accept and reject step within the ϵ-ball. This is done using
ABC.accept_reject(ϵ)where
ϵ` - a float describing the radius of the ϵ-ball
Once this is run more attributes are filled
ABC.num_accepted - number of accepted samples
ABC.num_rejected - number of rejected samples
ABC.num_draws - total number of samples done
ABC.accepted_parameters
ABC.accepted_differences
ABC.accepted_estimates
ABC.accepted_distances
ABC.rejected_parameters
ABC.rejected_differences
ABC.rejected_estimates
ABC.rejected_distances
Automatic rejection sampler
To get a certain number of draws within a chosen ϵ-ball one can run
ABC.get_min_accepted(
ϵ, accepted, {min_draws}, {at_once}, {save_sims}, {tqdm_notebook})where
ϵ - a float describing the radius of the ϵ-ball
accepted - the number of samples to be accepted within the ϵ-ball
min_draws - how many simulations to do at a time iteratively until enough simulations are accepted
at_once - boolean describing whether to process (and make) all simulations at once or not
save_sims - string with the filename to save the sims (as a .npy) if provided
tqdm_notebook - True if using a Jupyter notebook and False otherwise #TODO - make automatic (might already be implemented)
Histogrammed posterior
The posterior is approximated by histogramming the accepted samples from the ABC (and acception/rejection) and can be calculated using
ABC.posterior(
{bins}, {ranges}, {ϵ}, {draws}, {accepted},
{at_once}, {save_sims}, {tqdm_notebook})where
bins - number of bins in the histogram defining the posterior
ranges - minimum and maximum values for each parameter in the histogram
Optionally any of the parameters for ABC.ABC(...), ABC.accept_reject(...), and/or ABC.get_min_accepted(...) can be passed to ABC.posterior(...) to run the ABC when calling posterior rather than calling the sampling step first.
Plot plosterior
The posterior can be plotted using
ABC.plot(
{smoothing}, {bins}, {ranges}, {ϵ}, {draws}, {accepted},
{at_once}, {save_sims}, {tqdm_notebook}, **kwargs)where
smoothing - the pixel range of a Gaussian smoothing of the histogram for plotting (smoothing causes inflation of the posterior)
Optionally any of the parameters for ABC.ABC(...), ABC.accept_reject(...), and/or ABC.get_min_accepted(...) can be passed to ABC.plot(...) to run the ABC when making the plot rather than calling the sampling step first. matplotlib parameters can also be passed for the plotting routine.
Plot samples
The samples can also be plotted using
ABC.scatter_plot(
{axes}, {rejected}, {ϵ}, {draws}, {accepted},
{at_once}, {save_sims}, {tqdm_notebook}, **kwargs)where
axes - either "parameter_estimate", "parameter_parameter", or "estimate_estimate" for plotting the estimates against the parameters, or the parameters against the parameters or the estimates against the estimates (the last two are good for diagnostics such as the completeness of the sampling from the prior and the shape and correlation of the estimation function)
rejected - a number between 0 and 1 describing the fraction of the rejected samples to plot (there are often orders of magnitude more samples rejected and so it makes sense to plot fewer, if they are to be plotted at all)
Optionally any of the parameters for ABC.ABC(...), ABC.accept_reject(...), and/or ABC.get_min_accepted(...) can be passed to ABC.scatter_plot(...) to run the ABC when making the plot rather than calling the sampling step first. matplotlib parameters can also be passed for the plotting routine.
Running with saved simulations
If simulations have already been run and we want to perform a simple ABC on them then we can set the simulator to return the saved simulations, saved_simulations -> (?) + input_shape, and pass the corresponding saved parameters, saved_parameters -> (?, n_params)`, used to make the simulation.
simulator = lambda _ : saved_simulations
ABC = LFI.ApproximateBayesianComputation(
target_data, prior, Fisher, get_estimate, simulator, {labels})
ABC(draws=saved_parameters, predrawn=True, save_sims=None, {at_once})
ABC.accept_reject(ϵ)Population Monte Carlo (PMC)
Whilst we can obtain approximate posteriors using ABC, the rejection rate is very high because we sample always from the prior. Population Monte Carlo (PMC) uses statistics of the population of samples to propose new parameter values, so each new simulation is more likely to be accepted. This prevents us needing to define an ϵ parameter to define the acceptance distance. Instead we start with a population from the prior and iteratively move samples inwards. Once it becomes difficult to move the population any more, i.e. the number of attempts to accept a parameter becomes very large, then the distribution is seen to be a stable approximation to the posterior.
The whole module works very similarly to ABC with a few changes in arguments.
PMC = LFI.PopulationMonteCarlo(
target_data, prior, Fisher, get_estimate, simulator, {labels})where
target_data - as many pieces of data to be inferred (target_data.shape = (None,) + input_shape)
prior - the prior distribution which can be sampled from and whose probability can be evaluated with an event_shape of at least [1] (suggested to use a TensorFlow Probability distribution)
Fisher - Fisher information matrix (imnn.F or otherwise for non-IMNN)
get_estimate - function providing estimate of the n_params model parameters from the data (imnn.get_estimate or otherwise for non-IMNN)
simulator - function taking array of parameter values and returning simulations made at those values
labels - list of strings for labelling plots
Obtaining accepted samples
The PMC can be run by calling
PMC(draws, initial_draws, criterion, {percentile},
{at_once}, {save_sims}, {tqdm_notebook})or
PMC.PMC(
draws, initial_draws, criterion, {percentile},
{at_once}, {save_sims}, {tqdm_notebook})where
draws - number of samples from the posterior
initial_draws - number of samples from the prior to start the PMC (must be equal to or greater than the number of draws from the posterior
criterion - the stopping condition, the fraction of times samples are accepted in any one iteration of the PMC (when this is small then many samples are not accepted into the population, suggesting a stationary distribution)
percentile - the percentage of points which are considered the in the main sample (making this small moves more samples at once, but with reduced statistics from the population, default set to 75%, it takes longer to run (but may be cheaper in number of simulations) if set to a high value or None)
at_once - boolean describing whether to process (and make) all simulations at once or not
save_sims - string with the filename to save the sims (as a .npy) if provided
tqdm_notebook - True if using a Jupyter notebook and False otherwise #TODO - make automatic (might already be implemented)
Histogrammed posterior
The posterior is approximated by histogramming the accepted samples from the PMC and can be calculated using
PMC.posterior(
{bins}, {ranges}, {draws}, {initial_draws}, {criterion}, {percentile},
{at_once}, {save_sims}, {tqdm_notebook})where
bins - number of bins in the histogram defining the posterior
ranges - minimum and maximum values for each parameter in the histogram
Optionally any of the parameters for PMC.PMC(...) can be passed to PMC.posterior(...)` to run the PMC when calling posterior rather than calling the sampling step first.
Plot posterior
The posterior can be plotted using
PMC.plot(
{smoothing}, {bins}, {ranges}, {draws}, {initial_draws}, {criterion},
{percentile}, {at_once}, {save_sims}, {tqdm_notebook}, **kwargs)where
smoothing - the pixel range of a Gaussian smoothing of the histogram for plotting (smoothing causes inflation of the posterior)
Optionally any of the parameters for PMC.PMC(...) can be passed to PMC.plot(...) to run the PMC when making the plot rather than calling the sampling step first. matplotlib parameters can also be passed for the plotting routine.
Plot samples
The samples can also be plotted using
PMC.scatter_plot(
{axes}, {draws}, {initial_draws}, {criterion}, {percentile},
{at_once}, {save_sims}, {tqdm_notebook}, **kwargs)where
axes - either "parameter_estimate", "parameter_parameter", or "estimate_estimate" for plotting the estimates against the parameters, or the parameters against the parameters or the estimates against the estimates (the last two are good for diagnostics such as the completeness of the sampling from the prior and the shape and correlation of the estimation function)
Optionally any of the parameters for PMC.PMC(...) can be passed to PMC.scatter_plot(...) to run the PMC when making the plot rather than calling the sampling step first. matplotlib parameters can also be passed for the plotting routine.
TODO
The module is under constant development, and progress can be checked in the dev branch. Current additions to the IMNN include
Put back summary support - Previous versions of the IMNN had the ability to pass arbitrary summaries along with network summaries. This is useful because it can be a suggestion of how much information is gained over other summarising functions (such as the two point statistics, etc.) - Need to accept array, generative function and TFRecords with summaries and split covariance between summaries and network outputs for regularisation
JAX implementation of all routines - This is under private development currently
Docstrings written for LFI
Write unit tests
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file imnn-tf-0.2.0.tar.gz.
File metadata
- Download URL: imnn-tf-0.2.0.tar.gz
- Upload date:
- Size: 3.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.0.0 pkginfo/1.7.0 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.7.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ff2eee441ff2b10c20f1a00431c7b4a2c9ac6984a6420e501ef3c1e9bde62da0
|
|
| MD5 |
020acdf01145644783f0c65ee108299a
|
|
| BLAKE2b-256 |
98c9ee76cedaaebe59ce1aeabc5e08e6491679c92ab0530247a403bdef3842c4
|
File details
Details for the file imnn_tf-0.2.0-py3-none-any.whl.
File metadata
- Download URL: imnn_tf-0.2.0-py3-none-any.whl
- Upload date:
- Size: 34.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/4.0.0 pkginfo/1.7.0 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.48.2 CPython/3.7.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c7469a02b3b3a3a239e988c3a20140671a22eacd98d343113b2da15153ea309a
|
|
| MD5 |
3fc1cc6da7e403ffd85129c5993fe178
|
|
| BLAKE2b-256 |
8d1b60886e2e5cb5bac8cb068302fb70d6967d8a5153ee383b1ef8568d13c7d7
|







