Framework for automatic classification and segmentation of hyperspectral images.




Project description




Hyperspectral Tissue Classification
This package is a framework for automated tissue classification and segmentation on medical hyperspectral imaging (HSI) data. It contains:
- The implementation of deep learning models to solve supervised classification and segmentation problems for a variety of different input spatial granularities (pixels, superpixels, patches and entire images, cf. figure below) and modalities (RGB data, raw and processed HSI data) from our paper “Robust deep learning-based semantic organ segmentation in hyperspectral images”. It is based on PyTorch and PyTorch Lightning.
- The implementation of deep learning models for automated sepsis diagnosis and mortality prediciton, as described in our paper "AI-powered skin spectral imaging enables instant sepsis diagnosis and outcome prediction in critically ill patients". The models are based on skin HSI data at various spatial granularities (median spectra, patches) and across different modalities (RGB images, raw and processed HSI data). We further provide a multimodal approach that combines HSI data with clinical features such as demographics and blood gas analysis parameters.
- Corresponding pretrained models.
- A pipeline to efficiently load and process HSI data, to aggregate deep learning results and to validate and visualize findings.
- Presentation of several solutions to speed up the data loading process (see Pytorch Conference 2023 poster details below).

This framework is designed to work on HSI data from the Tivita cameras but you can adapt it to different HSI datasets as well. Potential applications include:
- Use our data loading and processing pipeline to easily access image and meta data for any work utilizing Tivita datasets.
- This repository is tightly coupled to work with the public HeiPorSPECTRAL and xeno-spectral datasets. If you already downloaded the data, you only need to perform the setup steps and then you can directly use the
htcframework to work on the data (cf. our tutorials). - Train your own networks and benefit from a pipeline offering e.g. efficient data loading, correct hierarchical aggregation of results and a set of helpful visualizations.
- Use our pretrained models to initialize the weights for your own training.
- Use our pretrained models to generate predictions for your own data.
If you use the htc framework, please consider citing the corresponding papers. You can also cite this repository directly via:
Cite via BibTeX
@software{sellner_htc_2023,
author = {Sellner, Jan and Seidlitz, Silvia},
publisher = {Zenodo},
url = {https://github.com/IMSY-DKFZ/htc},
date = {2026-03-22},
doi = {10.5281/zenodo.6577614},
title = {Hyperspectral Tissue Classification},
version = {v0.1.0},
}
Setup
Package Installation
This package can be installed via pip:
pip install imsy-htc
This installs all the required dependencies defined in requirements.txt. The requirements include the default PyTorch version for your system. In case you have special requirements on the PyTorch version (e.g. CUDA version), you need to manually install and build the imsy-htc package (see below).
The installation uses the latest versions of the dependencies to not break your existing environment. However, it can happen that a future update of a dependency breaks the installation or introduces incompatibilities. Unfortunately, we cannot guarantee that we will always make a new release which fixes the dependency problems. For this case, we provide a Docker image (see below) where you can work with the last working set of dependencies. This hopefully retains the functionality of this package even in the (far) future.
⚠️ This framework was developed and tested using the Ubuntu 24.04+ Linux distribution. Despite we do provide wheels for Windows and macOS as well, they are not tested.
⚠️ Network training and inference was conducted using an RTX 4090 GPU with 24 GiB of memory. It should also work with GPUs which have less memory but you may have to adjust some settings (e.g. the batch size).
PyTorch Compatibility and Custom Pytorch Versions
Our wheels are bound to the PyTorch ABI used during building of the wheel. This usually matches to most recent PyTorch version so if you keep both packages (imsy-htc and torch) up-to-date, everything should work. In the following table, we list the PyTorch versions which are compatible with the respective imsy-htc version.
imsy-htc |
torch |
|---|---|
| 0.0.9 | 1.13 |
| 0.0.10 | 1.13 |
| 0.0.11 | 2.0 |
| 0.0.12 | 2.0 |
| 0.0.13 | 2.1 |
| 0.0.14 | 2.1 |
| 0.0.15 | 2.2 |
| 0.0.15 | 2.3 |
| 0.0.16 | 2.4 |
| 0.0.17 | 2.5 |
| 0.0.18 | 2.5 |
| 0.0.19 | 2.6 |
| 0.0.20 | 2.6 |
| 0.0.21 | 2.7 |
| 0.0.22 | 2.8 |
| 0.0.23 | 2.9 |
| 0.1.0 | 2.10 |
However, we do not make explicit version constraints in the dependencies of the imsy-htc package because a future version of PyTorch may still work and we don't want to break the installation if it is not necessary.
If something does not work due to a version mismatch or if you have a custom torch version, you usually get an error like
ImportError: /usr/local/lib/python3.12/site-packages/htc/_cpp.cpython-312-x86_64-linux-gnu.so: undefined symbol: _ZNK3c105Error4whatEv
which indicates a link error between our binary and your PyTorch version. In this case, you need to build the imsy-htc package yourself. You can either install the developer version (see below) or you can use the provided source distribution to build imsy-htc while installing:
# Install the PyTorch version which you want
pip install torch
# Install and build our htc package against your previously installed torch package
pip install --no-build-isolation --no-binary "torch,htc" imsy-htc
⚠️ Building the
imsy-htcpackage manually requires that an up-to-date C++ compiler is available on your system, e.g.,g++ --versionshould work on Linux.
Optional Dependencies (imsy-htc[extra])
Some requirements are considered optional (e.g. if they are only needed by certain scripts) and you will get an error message if they are needed but unavailable. You can install them via
pip install --extra-index-url https://read_package:CnzBrgDfKMWS4cxf-r31@git.dkfz.de/api/v4/projects/15/packages/pypi/simple imsy-htc[extra]
or by adding the following lines to your requirements.txt
--extra-index-url https://read_package:CnzBrgDfKMWS4cxf-r31@git.dkfz.de/api/v4/projects/15/packages/pypi/simple
imsy-htc[extra]
This installs the optional dependencies defined in requirements-extra.txt, including for example our Python wrapper for the challengeR toolkit.
Docker
We also provide a Docker setup. As a prerequisite:
-
Clone this repository
-
Install Docker and the NVIDIA Container Toolkit
-
Run arbitrary commands inside the container via the provided
run_docker.pyscript:# Start an interactive python shell inside the container python run_docker.py --image-name ghcr.io/imsy-dkfz/imsy-htc ipython # Start any Python script inside the container python run_docker.py --image-name ghcr.io/imsy-dkfz/imsy-htc python tutorials/website_HeiPorSPECTRAL_example.py # Run any htc command inside the container python run_docker.py --image-name ghcr.io/imsy-dkfz/imsy-htc htc info # Do anything you want inside the container python run_docker.py --image-name ghcr.io/imsy-dkfz/imsy-htc bash
The example makes use of our prebuilt Docker image from the GitHub registry. There are also images for specific versions available. If you want to build the Docker image yourself, you can omit the
--image-nameargument.
All datasets you provided via an environment variable that starts with PATH_Tivita will be accessible in your container (you can also check the generated dependencies/docker-compose*.override.yml files for details). Per default, the Docker container is meant for small testing and not for development. This is reflected by the fact that all results are stored inside the container and hence will also be deleted after exiting the container. If you want to keep your results, let the environment variable PATH_HTC_DOCKER_RESULTS point to the directory where you want to store the results.
Developer Installation
If you want to make changes to the package code (which is highly welcome 😉), we recommend to install the htc package in editable mode in a separate conda environment:
# Set up the conda environment
conda create --yes --name htc python=3.14
conda activate htc
# Install the htc package and its requirements
pip install -r dependencies/requirements-dev.txt
pip install --no-build-isolation -e .
Before committing any files, please run the static code checks locally:
git add .
pre-commit run --all-files
Environment Variables
This framework can be configured via environment variables. Most importantly, we need to know where your data is located (e.g. PATH_Tivita_HeiPorSPECTRAL) and where results should be stored (e.g. PATH_HTC_RESULTS). For a full list of possible environment variables, please have a look at the documentation of the Settings class.
💡 If you set an environment variable for a dataset path, it is important that the variable name matches the folder name (e.g. the variable name
PATH_Tivita_HeiPorSPECTRALmatches the dataset pathmy/path/HeiPorSPECTRALwith its folder nameHeiPorSPECTRAL, whereas the variable namePATH_Tivita_some_other_namedoes not match). Furthermore, the dataset path needs to point to a directory which contains adataand anintermediatessubfolder.
There are several options to set the environment variables. For example:
-
You can specify a variable as part of your bash startup script
~/.bashrcor before running each command:PATH_HTC_RESULTS="~/htc/results" htc training --model image --config "models/image/configs/default"
However, this might get cumbersome or might not give you the flexibility you need.
-
Recommended if you cloned this repository (in contrast to simply installing it via pip): You can create a
.envfile in the repository root and add your variables, for example:export PATH_Tivita_HeiPorSPECTRAL=/mnt/nvme_4tb/HeiPorSPECTRAL export PATH_HTC_RESULTS=~/htc/results # You can also add your own datasets via (the environment variable name must start with PATH_Tivita) # export PATH_Tivita_my_dataset=~/htc/Tivita_my_dataset:shortcut=my_shortcut # You can then access it via settings.data_dirs.my_shortcut
-
Recommended if you installed the package via pip: You can create user settings for this application. The location is OS-specific. For Linux the location might be at
~/.config/htc/variables.env. Please runhtc infoupon package installation to retrieve the exact location on your system. The content of the file is of the same format as of the.envabove.
After setting your environment variables, it is recommended to run htc info to check that your variables are correctly registered in the framework.
Tutorials
A series of tutorials can help you get started on the htc framework by guiding you through different usage scenarios.
💡 The tutorials make use of our public HSI dataset HeiPorSPECTRAL. If you want to directly run them, please download the dataset first and make it accessible via the environment variable
PATH_Tivita_HeiPorSPECTRALas described above.
- As a start, we recommend to take a look at this general notebook which showcases the basic functionalities of the
htcframework. Namely, it demonstrates the usage of theDataPathclass which is the entry point to load and process HSI data. For example, you will learn how to read HSI cubes, segmentation masks and meta data. Among others, you can use this information to calculate the median spectrum of an organ. - You want to perform some spectral analysis? Then we have a notebook on loading and working with median spectra for you.
- If you want to use our framework with your own dataset, it might be necessary to write a custom
DataPathclass so that you can load and process your images and annotations. We collected some tips on how this can be achieved. - You have some HSI data at hand and want to use one of our pretrained models to generate predictions? Then our prediction notebook has got you covered.
- You want to use our pretrained models to initialize the weights for your own training? See the section about pretrained models below for details.
- You want to use our framework to train a network? The network training notebook will show you how to achieve this on the example of a heart and lung segmentation network.
- If you are interested in our technical validation (e.g. because you want to compare your colorchecker images with ours) and need to create a mask to detect the different colorchecker fields, you might find our automatic colorchecker mask creation pipeline useful.
- If you are coming from our xeno-learning publication and want to know more about the handling of the data, then we have you covered with an extra tutorial on the xeno-spectral dataset.
We do not have a separate documentation website for our framework yet. However, most of the functions and classes are documented, so feel free to explore the source code or use your favorite IDE to display the documentation. If something does not become clear from the documentation, feel free to open an issue!
Pretrained Models
This framework gives you access to a variety of pretrained segmentation and classification models. The models will be automatically downloaded, provided you specify the model type (e.g. image) and the run folder (e.g. 2022-02-03_22-58-44_generated_default_model_comparison). It can then be used for example to create predictions on some data or as a baseline for your own training (see example below).
The following table lists all the models you can get for surgical scene segmentation:
The following table lists all the models you can get for sepsis diagnosis and mortality prediction:
| model type | modality | class | run folder |
|---|---|---|---|
| median_pixel | hsi | ModelPixel |
2025-03-07_13-00-00_survival-inclusion_palm_median_nested-*-4_seed-*-2 |
| median_pixel | hsi | ModelPixel |
2025-03-07_13-00-00_survival-inclusion_finger_median_nested-*-4_seed-*-2 |
| median_pixel | hsi | ModelPixel |
2025-03-07_13-00-00_sepsis-inclusion_palm_median_nested-*-4_seed-*-2 |
| median_pixel | hsi | ModelPixel |
2025-03-07_13-00-00_sepsis-inclusion_finger_median_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_palm_stacked_image_nested-*-4_seed-*-2 |
| image | param | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_palm_image_tpi_nested-*-4_seed-*-2 |
| image | rgb | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_palm_image_rgb_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_palm_image_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_palm_image-meta_demographic+vital+BGA+diagnosis+ventilation+catecholamines_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_palm_image-meta_demographic+vital+BGA+diagnosis+ventilation+catecholamines+lab_nested-*-4_seed-*-2 |
| image | param | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_finger_image_tpi_nested-*-4_seed-*-2 |
| image | rgb | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_finger_image_rgb_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_survival-inclusion_finger_image_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_palm_stacked_image_nested-*-4_seed-*-2 |
| image | param | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_palm_image_tpi_nested-*-4_seed-*-2 |
| image | rgb | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_palm_image_rgb_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_palm_image_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_palm_image-meta_demographic+vital+BGA+diagnosis+ventilation+catecholamines_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_palm_image-meta_demographic+vital+BGA+diagnosis+ventilation+catecholamines+lab_nested-*-4_seed-*-2 |
| image | param | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_finger_image_tpi_nested-*-4_seed-*-2 |
| image | rgb | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_finger_image_rgb_nested-*-4_seed-*-2 |
| image | hsi | ModelSuperpixelClassification |
2025-03-07_13-00-00_sepsis-inclusion_finger_image_nested-*-4_seed-*-2 |
💡 The modality
paramrefers to stacked tissue parameter images (named TPI in our papers). For the model typepatch, pretrained models are available for the patch sizes 64 x 64 and 32 x 32 pixels in the case of surgical scene segmentation models. For sepsis diagnosis and mortality prediction models, a patch size of 224 x 224 is utilized. The modality and patch size is not specified when loading a model as it is already characterized by specifying a certain run folder.
💡 A wildcard
*in the run folder name refers to a collection of models (e.g. from nested cross validation). You can use the name as noted in the table to retrieve all models from this collection as list of models or explicitly set the index to only retrieve one specific model from the collection. If you keep the wildcard for creating predictions (see below), all models will be loaded and the final prediction is an ensemble of the output from all individual networks (e.g. 15 networks with 3 outer and 5 inner folds).
💡 In the sepsis diagnosis and mortality prediction models, the term
palm_stackedin the run folder name indicates models trained on combined palm and finger data. In these models, palm and finger patches were concatenated along the spectral dimension.
After successful installation of the htc package, you can use any of the pretrained models listed in the table. There are several ways to use them but the general principle is that models are always specified via their model and run_folder.
Option 1: Use the models in your own training pipeline
Every model class listed in the table has a static method pretrained_model() which you can use to create a model instance and initialize it with the pretrained weights. The model object will be an instance of torch.nn.Module. The function has examples for all the different model types but as a teaser consider the following example which loads the pretrained image HSI network:
import torch
from htc import ModelImage, Normalization
run_folder = "2022-02-03_22-58-44_generated_default_model_comparison" # HSI model
model = ModelImage.pretrained_model(model="image", run_folder=run_folder, n_channels=100, n_classes=19)
input_data = torch.randn(1, 100, 480, 640) # NCHW
input_data = Normalization(channel_dim=1)(input_data) # Model expects L1 normalized input
model(input_data).shape
# torch.Size([1, 19, 480, 640])
💡 Please note that when initializing the weights as in this example, the segmentation head is initialized randomly. Meaningful predictions on your own data can thus not be expected out of the box, but you will have to train the model on your data first.
Option 2: Use the models to create predictions for your data
The models can be used to predict segmentation masks for your data. The segmentation models automatically sample from your input image according to the selected model spatial granularity (e.g. by creating patches) and the output is always a segmentation mask for an entire image. The set of output classes is determined by the training configuration, e.g. 18 organ classes + background for our semantic models. There are two alternatives for creating predictions:
- The
CreatingPredictionsnotebook shows how to create predictions for all images in a folder (via thehtc inferencecommand) and how to map the network output to meaningful label names. - If you want to compute predictions directly within your code for custom tensors, batches or paths, you can use the
SinglePredictorclass.
Option 3: Use the models to train a network with the htc package
If you are using the htc framework to train your networks, you only need to define the model in your configuration:
{
"model": {
"pretrained_model": {
"model": "image",
"run_folder": "2022-02-03_22-58-44_generated_default_model_comparison"
}
}
}
This is very similar to option 1 but may be more convenient if you already train with the htc framework.
💡 We have a JSON Schema file which describes the structure of our config files including descriptions of the attributes.
Prediction Tables
The above options will only make predictions for your data without evaluating those predictions. If you want to compare the predictions against some reference annotations and compute some metric values (e.g., DSC), then there are two possibilities:
- Use the
htc tables --input-dir YOUR_INPUT_DIR --output-dir YOUR_OUTPUT_DIR --test --metrics DSC --model image --run-folder 2023-02-08_14-48-02_organ_transplantation_0.8command to create predictions for a set of paths (cf.htc tables --helpfor more information on the arguments). This will save a validation or test table on disk. - Similar to the
SinglePredictorclass from before, there is also aSinglePredictionTableclass to compute a metrics table for your data within your own code (the validation or test table will be returned instead of saved to disk). This is useful if you only want to compute metrics for a custom set of paths.
In any case, it is required that reference segmentations are available for every image so that the output of the network can be compared against something.
CLI
There is a common command line interface for many scripts in this repository. More precisely, every script which is prefixed with run_NAME.py can also be run via htc NAME from any directory. For more details, just type htc.
Papers
This repository contains code to reproduce our publications listed below:
📝 AI-powered skin spectral imaging enables instant sepsis diagnosis and outcome prediction in critically ill patients
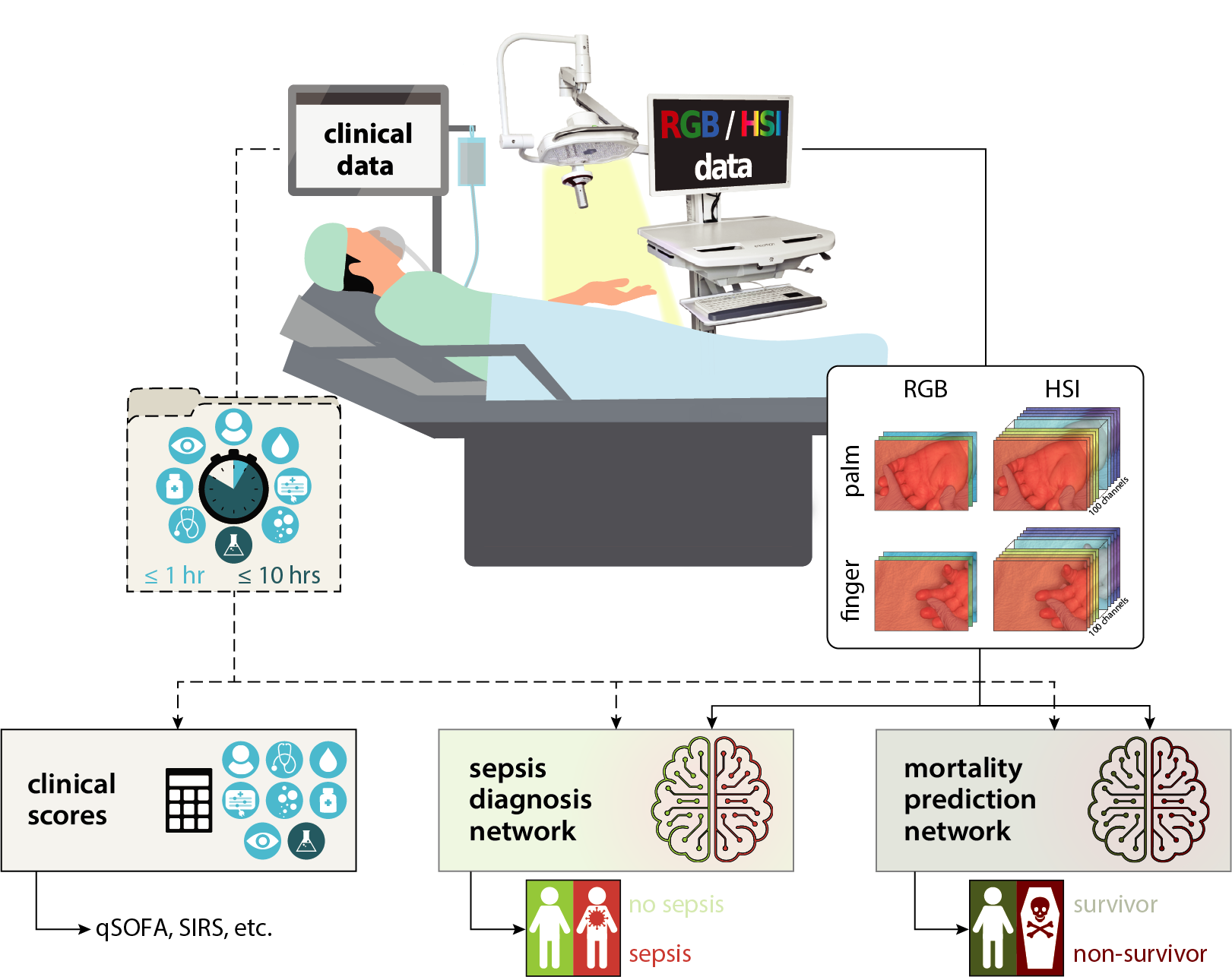
This paper presents a deep learning framework for automated sepsis diagnosis and mortality prediciton in intensive care patients. We show that models based on skin HSI data achieve high accuracy, which can be further enhanced through multimodal fusion with minimal clinical data. Our approach outperforms widely used clinical scores and biomarkers while enabling non-invasive, rapid, and mobile predictions. All trained networks are available as pretrained models. We utilized a nested cross-validation scheme with 5 outer and 5 inner folds, as well as 3 different random seed settings, so each training configuration is composed of 15 run folders on disk. However, you can still refer to them via the run_folder argument by using a wildcard (e.g., 2025-03-07_13-00-00_sepsis-inclusion_palm_image_nested-*-4_seed-*-2) to get the corresponding networks. You can find all notebooks which generate the paper figures in paper/ScienceAdvances2025 accompanied by reproducibility instructions. The code for all experiments is located in the htc_projects/sepsis_icu folder.
📂 The dataset for this paper is not publicly available.
Cite via BibTeX
@article{seidlitz_sepsis_2025,
author = {Seidlitz, Silvia and Hölzl, Katharina and von Garrel, Ayca and Sellner, Jan and Katzenschlager, Stephan and Hölle, Tobias and Fischer, Dania and von der Forst, Maik and Schmitt, Felix C. F. and Studier-Fischer, Alexander and Weigand, Markus A. and Maier-Hein, Lena and Dietrich, Maximilian},
date = {2025},
doi = {10.1126/sciadv.adw1968},
eprint = {https://www.science.org/doi/pdf/10.1126/sciadv.adw1968},
journaltitle = {Science Advances},
number = {29},
pages = {eadw1968},
title = {AI-powered skin spectral imaging enables instant sepsis diagnosis and outcome prediction in critically ill patients},
volume = {11},
}
📝 Xeno-learning: knowledge transfer across species in deep learning-based spectral image analysis
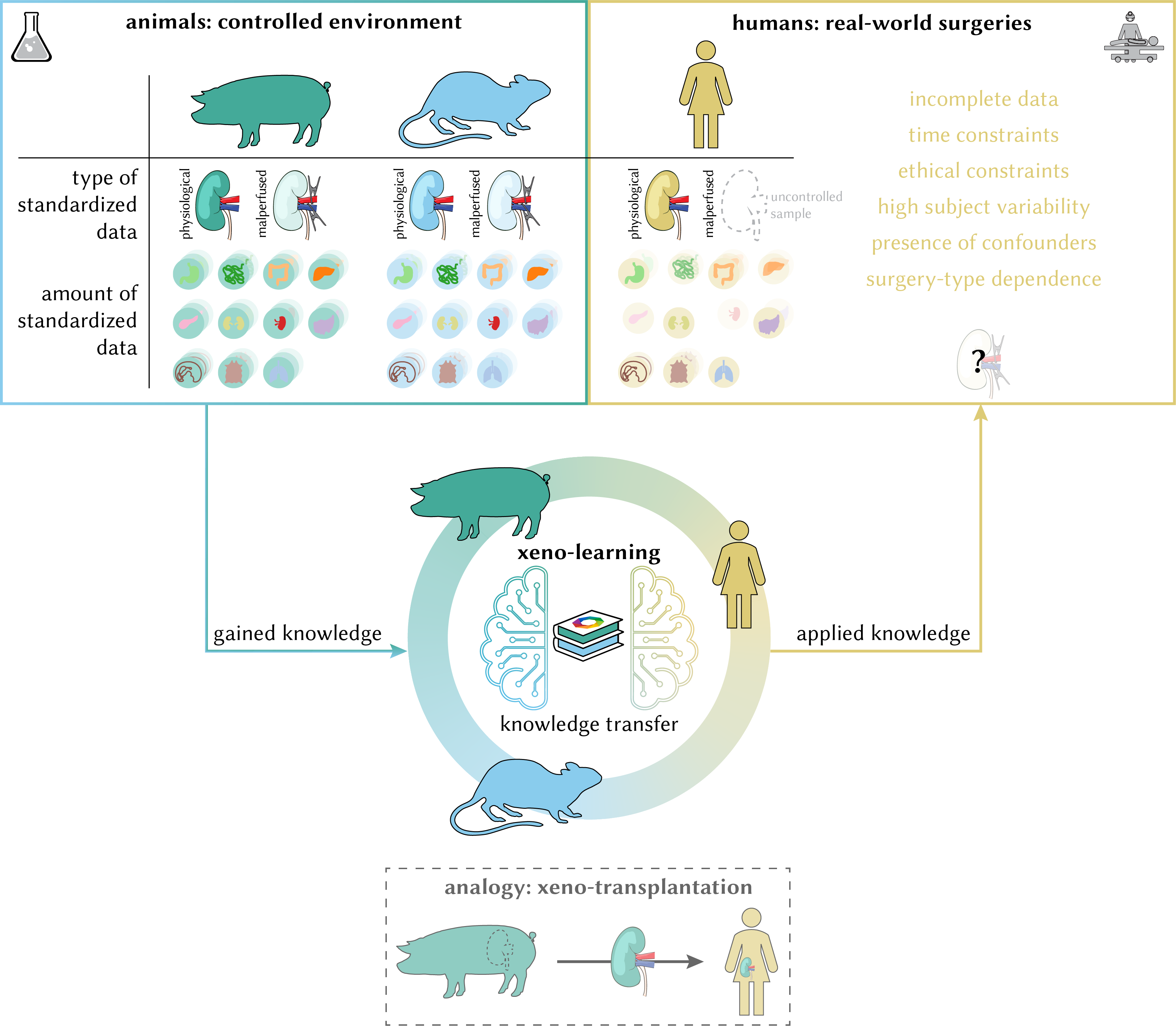
This paper introduces a cross-species knowledge transfer paradigm termed xeno-learning to make use of what has been learned in one species in other species. Specifically, we showcase how human segmentation performance on malperfused tissues can be improved by leveraging perfusion knowledge obtained from animal data via a physiology-based data augmentation method. All trained networks are available as pretrained models (baseline networks and networks which included the new data augmentation method during training). Compared to previous papers, we switched to a nested cross-validation scheme with 3 outer folds so each training configuration is composed of 3 run folders on disk. However, you can still refer to them via the run_folder argument by using a wildcard (e.g., 2025-06-07_20-24-33_baseline_human_nested-*-2 to get the baseline networks 0, 1 and 2 trained on human data). You can find all notebooks which generate the paper figures in paper/NatureBME2026 accompanied by reproducibility instructions. The code for all experiments is located in the htc_projects/species folder.
📂 The animal data for this dataset is publicly available. The human data is not publicly available.
Cite via BibTeX
@article{sellner_species_2026,
author = {Sellner, Jan and Studier-Fischer, Alexander and Qasim, Ahmad Bin and Seidlitz, Silvia and Schreck, Nicholas and Tizabi, Minu and Wiesenfarth, Manuel and Kopp-Schneider, Annette and Heinecke, Janne and Brandt, Jule and Knoedler, Samuel and Max Haney, Caelan and Salg, Gabriel and Özdemir, Berkin and Dietrich, Maximilian and Michel, Maurice Stephan and Nickel, Felix and Kowalewski, Karl-Friedrich and Maier-Hein, Lena},
url = {https://spectralverse-heidelberg.org},
date = {2026-01-26},
doi = {10.1038/s41551-025-01585-4},
issn = {2157-846X},
journaltitle = {Nature Biomedical Engineering},
title = {Xeno-learning: knowledge transfer across species in deep learning-based spectral image analysis},
}
📝 Semantic segmentation of surgical hyperspectral images under geometric domain shifts
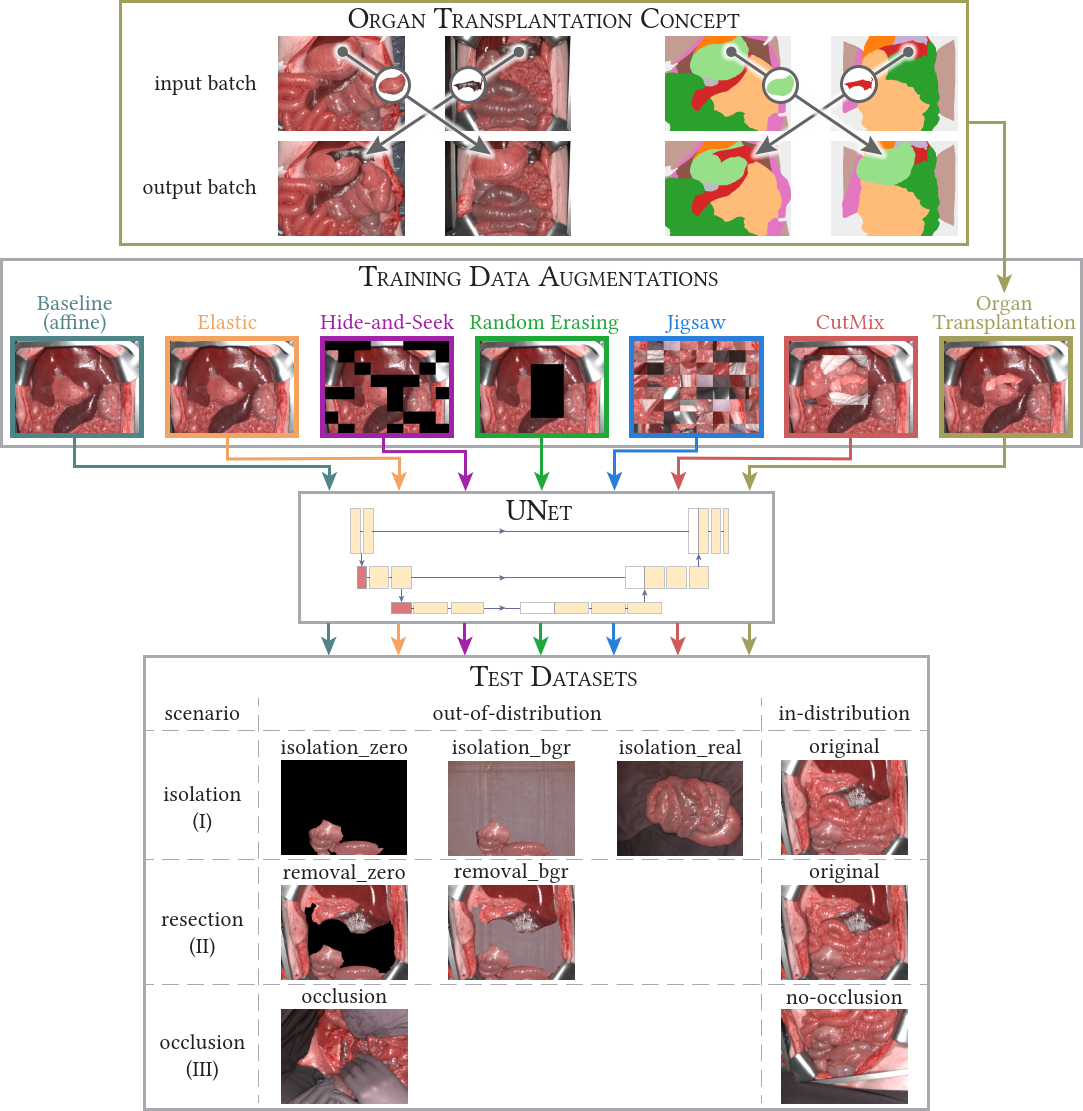
This MICCAI2023 paper is the direct successor of our MIA2022 paper. We analyzed how well our networks perform under geometrical domain shifts which commonly occur in real-world open surgeries (e.g. situs occlusions). The effect is drastic (drop of Dice similarity coefficient by 45 %) but the good news is that performance on par with in-distribution data can be achieved with our simple, model-independent solution (augmentation method). You can find all the code in htc_projects/context and paper figures as well as reproducibility instructions in paper/MICCAI2023. Pretrained models are available for our organ transplantation networks with HSI and RGB modalities.
💡 If you are only interested in our data augmentation method, you can also head over to Kornia where this augmentation is implemented for generic use cases (including 2D and 3D data). You will find it under the name
RandomTransplantation.
📂 The dataset for this paper is publicly available.
Cite via BibTeX
@inproceedings{sellner_context_2023,
author = {Sellner, Jan and Seidlitz, Silvia and Studier-Fischer, Alexander and Motta, Alessandro and Özdemir, Berkin and Müller-Stich, Beat Peter and Nickel, Felix and Maier-Hein, Lena},
editor = {Greenspan, Hayit and Madabhushi, Anant and Mousavi, Parvin and Salcudean, Septimiu and Duncan, James and Syeda-Mahmood, Tanveer and Taylor, Russell},
location = {Cham},
publisher = {Springer Nature Switzerland},
booktitle = {Medical Image Computing and Computer Assisted Intervention -- MICCAI 2023},
date = {2023},
doi = {10.1007/978-3-031-43996-4_59},
isbn = {978-3-031-43996-4},
pages = {618--627},
title = {Semantic Segmentation of Surgical Hyperspectral Images Under Geometric Domain Shifts},
}
📝 Robust deep learning-based semantic organ segmentation in hyperspectral images
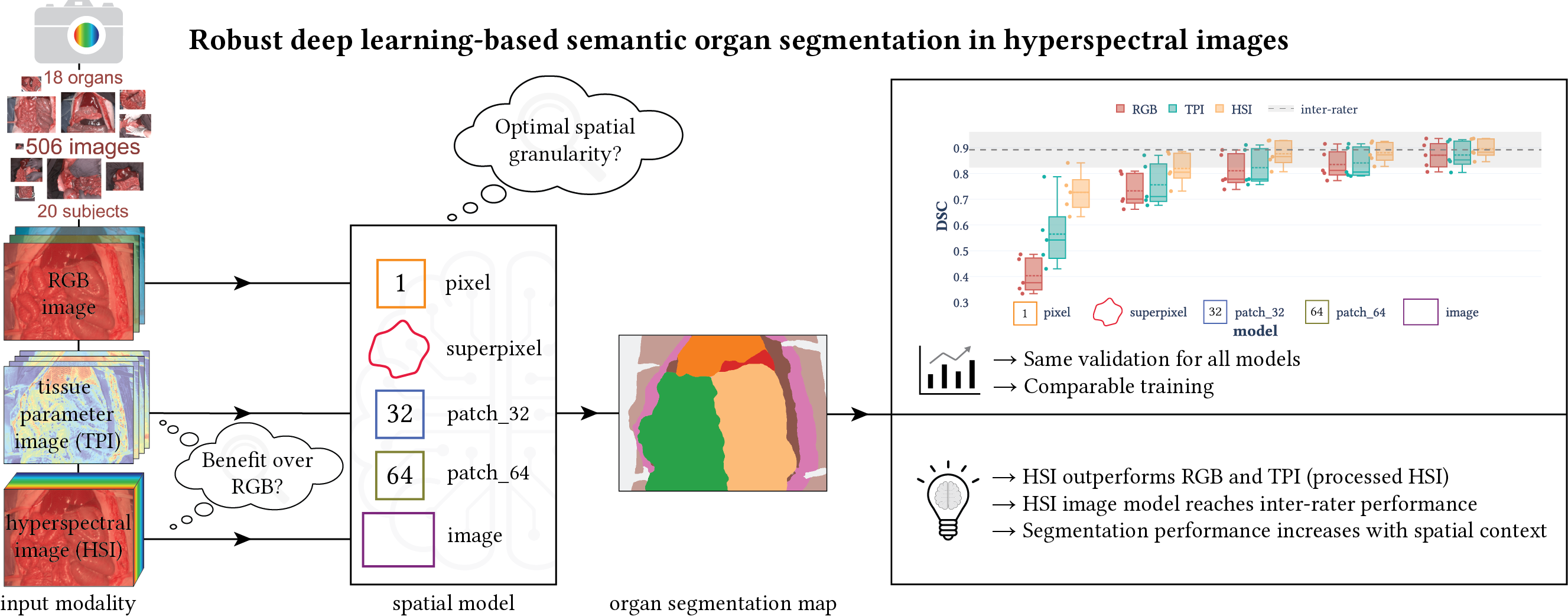
In this paper, we tackled fully automatic organ segmentation and compared deep learning models on different spatial granularities (e.g. patch vs. image) and modalities (e.g. HSI vs. RGB). Furthermore, we studied the required amount of training data and the generalization capabilities of our models across subjects. The pretrained networks are related to this paper. You can find the notebooks to generate the paper figures in paper/MIA2022 (the folder also includes a reproducibility document) and the models in htc/models. For each model, there are three configuration files, namely default, default_rgb and default_parameters, which correspond to the HSI, RGB and TPI modality, respectively. You can also download the NSD thresholds which we used for the NSD metric (cf. Fig. 12).
📂 The dataset for this paper is publicly available.
Cite via BibTeX
@article{seidlitz_seg_2022,
author = {Seidlitz, Silvia and Sellner, Jan and Odenthal, Jan and Özdemir, Berkin and Studier-Fischer, Alexander and Knödler, Samuel and Ayala, Leonardo and Adler, Tim J. and Kenngott, Hannes G. and Tizabi, Minu and Wagner, Martin and Nickel, Felix and Müller-Stich, Beat P. and Maier-Hein, Lena},
date = {2022-08},
doi = {10.1016/j.media.2022.102488},
issn = {1361-8415},
journaltitle = {Medical Image Analysis},
keywords = {Hyperspectral imaging,Surgical data science,Deep learning,Open surgery,Organ segmentation,Semantic scene segmentation},
pages = {102488},
title = {Robust deep learning-based semantic organ segmentation in hyperspectral images},
volume = {80},
}
📝 Dealing with I/O bottlenecks in high-throughput model training
The poster was presented at the PyTorch Conference 2023 and presents several solutions to improve data loading for faster network training. This originated from our MICCAI2023 paper, where we load huge amount of data while using a relatively small network resulting in GPU idle times when the GPU has to wait for the CPU to deliver new data. This requested the need for fast data loading strategies so that the CPU delivers data in-time for the GPU. The solutions include (1) efficient data storage via Blosc compression, (2) appropriate precision settings, (3) GPU instead of CPU augmentations using the Kornia library and (4) a fixed shared pinned memory buffer for efficient data transfer to the GPU. For the last part, you will find the relevant code to create the buffer in this repository as part of the SharedMemoryDatasetMixin class (_add_tensor_shared() method).
You can find the code to generate the results figures of the poster in paper/PyTorchConf2023 including reproducibility instructions. The experiment code can be found in the project folder htc_projects/benchmarking.
📂 The dataset for this poster is publicly available.
Cite via BibTeX
@misc{sellner_benchmarking_2023,
author = {Sellner, Jan and Seidlitz, Silvia and Maier-Hein, Lena},
url = {https://e130-hyperspectal-tissue-classification.s3.dkfz.de/figures/PyTorchConference_Poster.pdf},
date = {2023-10-16},
howpublished = {Poster presented at the PyTorch Conference 2023, San Francisco, United States of America},
title = {Dealing with I/O bottlenecks in high-throughput model training},
}
📝 HeiPorSPECTRAL - the Heidelberg Porcine HyperSPECTRAL Imaging Dataset of 20 Physiological Organs
This paper introduces the HeiPorSPECTRAL dataset containing 5756 hyperspectral images from 11 subjects. We are using these images in our tutorials. You can find the visualization notebook for the paper figures in paper/NatureData2023 (the folder also includes a reproducibility document) and the remaining code in htc_projects/atlas_open.
If you want to learn more about the HeiPorSPECTRAL dataset (e.g. the underlying data structure) or you stumbled upon a file and want to know how to read it, you might find this notebook with low-level details helpful.
📂 The dataset for this paper is publicly available.
Cite via BibTeX
@article{studierfischer_open_2023,
author = {Studier-Fischer, Alexander and Seidlitz, Silvia and Sellner, Jan and Bressan, Marc and Özdemir, Berkin and Ayala, Leonardo and Odenthal, Jan and Knoedler, Samuel and Kowalewski, Karl-Friedrich and Haney, Caelan Max and Salg, Gabriel and Dietrich, Maximilian and Kenngott, Hannes and Gockel, Ines and Hackert, Thilo and Müller-Stich, Beat Peter and Maier-Hein, Lena and Nickel, Felix},
url = {https://spectralverse-heidelberg.org/HeiPorSPECTRAL},
date = {2023-06-24},
doi = {10.1038/s41597-023-02315-8},
issn = {2052-4463},
journaltitle = {Scientific Data},
number = {1},
pages = {414},
title = {HeiPorSPECTRAL - the Heidelberg Porcine HyperSPECTRAL Imaging Dataset of 20 Physiological Organs},
volume = {10},
}
📝 Spectral organ fingerprints for machine learning-based intraoperative tissue classification with hyperspectral imaging in a porcine model
In this paper, we trained a classification model based on median spectra from HSI data. You can find the model code in htc_projects/atlas and the confusion matrix figure of the paper in paper/NatureReports2022 (including a reproducibility document).
📂 The dataset for this paper is not fully publicly available, but a subset of the data is available through the public HeiPorSPECTRAL dataset.
Cite via BibTeX
@article{studierfischer_atlas_2022,
author = {Studier-Fischer, Alexander and Seidlitz, Silvia and Sellner, Jan and Özdemir, Berkin and Wiesenfarth, Manuel and Ayala, Leonardo and Odenthal, Jan and Knödler, Samuel and Kowalewski, Karl Friedrich and Haney, Caelan Max and Camplisson, Isabella and Dietrich, Maximilian and Schmidt, Karsten and Salg, Gabriel Alexander and Kenngott, Hannes Götz and Adler, Tim Julian and Schreck, Nicholas and Kopp-Schneider, Annette and Maier-Hein, Klaus and Maier-Hein, Lena and Müller-Stich, Beat Peter and Nickel, Felix},
date = {2022-06-30},
doi = {10.1038/s41598-022-15040-w},
issn = {2045-2322},
journaltitle = {Scientific Reports},
number = {1},
pages = {11028},
title = {Spectral organ fingerprints for machine learning-based intraoperative tissue classification with hyperspectral imaging in a porcine model},
volume = {12},
}
📝 Künstliche Intelligenz und hyperspektrale Bildgebung zur bildgestützten Assistenz in der minimal-invasiven Chirurgie
This paper presents several applications of intraoperative HSI, including our organ segmentation and classification work. You can find the code generating our figure for this paper at paper/Chirurg2022.
📂 The sample image used here is contained in the dataset from our paper “Robust deep learning-based semantic organ segmentation in hyperspectral images” and hence not publicly available.
Cite via BibTeX
@article{chalopin_chirurgie_2022,
author = {Chalopin, Claire and Nickel, Felix and Pfahl, Annekatrin and Köhler, Hannes and Maktabi, Marianne and Thieme, René and Sucher, Robert and Jansen-Winkeln, Boris and Studier-Fischer, Alexander and Seidlitz, Silvia and Maier-Hein, Lena and Neumuth, Thomas and Melzer, Andreas and Müller-Stich, Beat Peter and Gockel, Ines},
date = {2022-10-01},
doi = {10.1007/s00104-022-01677-w},
issn = {2731-698X},
journaltitle = {Die Chirurgie},
number = {10},
pages = {940--947},
title = {Künstliche Intelligenz und hyperspektrale Bildgebung zur bildgestützten Assistenz in der minimal-invasiven Chirurgie},
volume = {93},
}
Funding
This project has received funding from the European Research Council (ERC) under the European Unions Horizon 2020 research and innovation programme (NEURAL SPICING, grant agreement No. 101002198) and was supported by the German Cancer Research Center (DKFZ) and the Helmholtz Association under the joint research school HIDSS4Health (Helmholtz Information and Data Science School for Health). It further received funding from the Surgical Oncology Program of the National Center for Tumor Diseases (NCT) Heidelberg.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file imsy_htc-0.1.0.tar.gz.
File metadata
- Download URL: imsy_htc-0.1.0.tar.gz
- Upload date:
- Size: 2.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c20e8f87c6387fb0c45ce5aaa959ed688283207b1b3df21a35ba8256224def0b
|
|
| MD5 |
7d30993d2c8d300795cb3e9b5500c335
|
|
| BLAKE2b-256 |
033520dc716be37a1e2796e3904828160ca67eddf7543ad287f30c510eb6a370
|
File details
Details for the file imsy_htc-0.1.0-cp314-cp314-win_amd64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp314-cp314-win_amd64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.14, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7437a78eb4d0c4ac56366b91253984337da24a1b625cff955b0ed58a26389452
|
|
| MD5 |
f990d685cf8c47ffd36bd079353c20fe
|
|
| BLAKE2b-256 |
01e091a1dddc5a58893fa0cf8a0cfef2e7ecc78fe79603e3423c8038b6ea6149
|
File details
Details for the file imsy_htc-0.1.0-cp314-cp314-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp314-cp314-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 15.8 MB
- Tags: CPython 3.14, manylinux: glibc 2.24+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
38a42b419d3ff051d7bd19bd4baf6fb2f45a17e5188953a154e8032b1bd80788
|
|
| MD5 |
69ec2dc7dc1cbaedd762176e6534514f
|
|
| BLAKE2b-256 |
1901909a65711e1cf876d0cb0ac4a50deb9a7a96210e3d3f380e3b0468b2b2a1
|
File details
Details for the file imsy_htc-0.1.0-cp314-cp314-macosx_11_0_arm64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp314-cp314-macosx_11_0_arm64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.14, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bf6c3e936430112a89eb440152d178f5e5b1902e5be3343e0b2356d2929f1de5
|
|
| MD5 |
740e8dca5b274bcf30e8353adc2aef1a
|
|
| BLAKE2b-256 |
1db083dc5fcb5b501d48ca9cdaa6e50ac4a949a3a4386813815896591de40193
|
File details
Details for the file imsy_htc-0.1.0-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d55020ba06f1b1df3798e13a3bf4d7480f60da7c98c8bce29fee7dc1f6b24d18
|
|
| MD5 |
b1234a5b0c546a6d049e74244c0b3f38
|
|
| BLAKE2b-256 |
2b2d6b840894b29bf65772164418e16dc5f3d6542c0c83626abd95f3c5bfaa91
|
File details
Details for the file imsy_htc-0.1.0-cp313-cp313-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp313-cp313-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 15.8 MB
- Tags: CPython 3.13, manylinux: glibc 2.24+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9e26f9b7020b70373f6ca8242474195e75d35d1a53f096532c8628226ac45be9
|
|
| MD5 |
0ebc53d3bd1ebc45d22d24da62b618cb
|
|
| BLAKE2b-256 |
903bf2007447dd2099fb867f212b6106a74f9d7263a8b672d1546da3358058c1
|
File details
Details for the file imsy_htc-0.1.0-cp313-cp313-macosx_11_0_arm64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp313-cp313-macosx_11_0_arm64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.13, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4041de62109dbc37afde6999e6c7a552c0c3ca4be63d35ded757db8e934d2020
|
|
| MD5 |
a44737ca5ca8ddfae1cf6a5faccad25b
|
|
| BLAKE2b-256 |
142ad7b5d035d16556bc3827af4b8d47b1d10dc2411634859d5322634ef5d62c
|
File details
Details for the file imsy_htc-0.1.0-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8e364887fba0951d88cb59fe01aede4fdd15971abbe57345fa9e1223df93fef2
|
|
| MD5 |
37247ec1cc6a73d131e1dc68c6923380
|
|
| BLAKE2b-256 |
1ddef61f080b27a72a2d06a23a07ffa2a04af90714d45d48b7f763f2fcbbec58
|
File details
Details for the file imsy_htc-0.1.0-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 15.8 MB
- Tags: CPython 3.12, manylinux: glibc 2.24+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a79052b21b4a7144e1258ceeec2b734318eaa870b1157ec1f540f2c0a32663cb
|
|
| MD5 |
57e56c314de16ea91a5d502c325460a6
|
|
| BLAKE2b-256 |
027389201b3b656b3c8b4df377105022e34ecfc061e0489011d87e05b2aedb08
|
File details
Details for the file imsy_htc-0.1.0-cp312-cp312-macosx_11_0_arm64.whl.
File metadata
- Download URL: imsy_htc-0.1.0-cp312-cp312-macosx_11_0_arm64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.12, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b094b0acac2705ac6950ed9b03a6c453789e1bf7c7a1723bdfa583a00e930823
|
|
| MD5 |
8c6b6ffd868be33db0489e84818404e9
|
|
| BLAKE2b-256 |
02f631fce4802005349d8e0a163d320ab6272915c3b5d47e31b865328c69f424
|







