Fast random access to bzip2 files

Project description
indexed_bzip2













This module provides an IndexedBzip2File class, which can be used to seek inside bzip2 files without having to decompress them first.
Alternatively, you can use this simply as a parallelized bzip2 decoder as a replacement for Python's builtin bz2 module in order to fully utilize all your cores.
On a 12-core processor, this can lead to a speedup of 6 over Python's bz2 module, see this example.
Note that without parallelization, indexed_bzip2 is unfortunately slower than Python's bz2 module.
Therefore, it is not recommended when neither seeking nor parallelization is used!
The internals are based on an improved version of the bzip2 decoder bzcat from toybox, which was refactored and extended to be able to export and import bzip2 block offsets, seek to block offsets, and to add support for threaded parallel decoding of blocks.
Seeking inside a block is only emulated, so IndexedBzip2File will only speed up seeking when there are more than one block, which should almost always be the cause for archives larger than 1 MB.
Since version 1.2.0, parallel decoding of blocks is supported!
However, per default, the older serial implementation is used.
To use the parallel implementation you need to specify a parallelization argument other than 1 to IndexedBzip2File, see e.g. this example.
Table of Contents
Performance comparison with bz2 module
Results for an AMD Ryzen 3900X 12-core (24 virtual cores) processor and with bz2FilePath='CTU-13-Dataset.tar.bz2', which is a 2GB bz2 compressed archive.
| Module | Runtime / s | Bandwidth / (MB/s) | Speedup |
|---|---|---|---|
| bz2 | 386 | 5.2 | 1 |
| indexed_bzip2 with parallelization = 0 | 60 | 33.2 | 6.4 |
| indexed_bzip2 with parallelization = 1 | 472 | 4.2 | 0.8 |
| indexed_bzip2 with parallelization = 2 | 265 | 7.6 | 1.5 |
| indexed_bzip2 with parallelization = 6 | 99 | 20.2 | 3.9 |
| indexed_bzip2 with parallelization = 12 | 64 | 31.4 | 6.1 |
| indexed_bzip2 with parallelization = 24 | 63 | 31.8 | 6.1 |
| indexed_bzip2 with parallelization = 32 | 63 | 31.7 | 6.1 |
The speedup of indexed_bzip2 over the bz2 module with parallelization = 0 is 6.
When using only one core, indexed_bzip2 is unfortunately slower by (559-392)/392 = 42%.
These are simple timing tests for reading all the contents of a bzip2 file sequentially.
import bz2
import os
import time
fileSize = os.stat(bz2FilePath).st_size
with bz2.open(bz2FilePath) as file:
t0 = time.time()
while file.read(512*1024):
pass
bz2Duration = time.time() - t0
print(f"Decoded file in {bz2Duration:.0f}s, bandwidth: {fileSize / bz2Duration / 1e6:.1f} MB/s")
The usage of indexed_bzip2 is slightly different:
import indexed_bzip2
import time
# parallelization = 0 means that it is automatically using all available cores.
for parallelization in [0, 1, 2, 6, 12, 24, 32]:
with indexed_bzip2.IndexedBzip2File(bz2FilePath, parallelization = parallelization) as file:
t0 = time.time()
# Unfortunately, the chunk size is very performance critical! It might depend on the cache size.
while file.read(512*1024):
pass
ibz2Duration = time.time() - t0
print(f"Decoded file in {ibz2Duration:.0f}s"
f", bandwidth: {fileSize / ibz2Duration / 1e6:.1f} MB/s"
f", speedup: {bz2Duration/ibz2Duration:.1f}")
Installation
You can simply install it from PyPI:
python3 -m pip install --upgrade pip # Recommended for newer manylinux wheels
python3 -m pip install indexed_bzip2
To install with conda:
conda install -c conda-forge indexed_bzip2
The latest unreleased development version can be tested out with:
python3 -m pip install --force-reinstall 'git+https://github.com/mxmlnkn/indexed_bzip2.git@master#egginfo=indexed_bzip2&subdirectory=python/indexed_bzip2'
And to build locally, you can use build and install the wheel:
cd python/indexed_bzip2
rm -rf dist
python3 -m build .
python3 -m pip install --force-reinstall --user dist/*.whl
Usage
Python Library
Simple open, seek, read, and close
from indexed_bzip2 import IndexedBzip2File
file = IndexedBzip2File( "example.bz2", parallelization = os.cpu_count() )
# You can now use it like a normal file
file.seek( 123 )
data = file.read( 100 )
file.close()
The first call to seek will ensure that the block offset list is complete and therefore might create them first. Because of this the first call to seek might take a while.
Use with context manager
import os
import indexed_bzip2 as ibz2
with ibz2.open( "example.bz2", parallelization = os.cpu_count() ) as file:
file.seek( 123 )
data = file.read( 100 )
Storing and loading the block offset map
The creation of the list of bzip2 blocks can take a while because it has to decode the bzip2 file completely. To avoid this setup when opening a bzip2 file, the block offset list can be exported and imported.
import indexed_bzip2 as ibz2
import pickle
# Calculate and save bzip2 block offsets
file = ibz2.open( "example.bz2", parallelization = os.cpu_count() )
block_offsets = file.block_offsets() # can take a while
# block_offsets is a simple dictionary where the keys are the bzip2 block offsets in bits(!)
# and the values are the corresponding offsets in the decoded data in bytes. E.g.:
# block_offsets = {32: 0, 14920: 4796}
with open( "offsets.dat", 'wb' ) as offsets_file:
pickle.dump( block_offsets, offsets_file )
file.close()
# Load bzip2 block offsets for fast seeking
with open( "offsets.dat", 'rb' ) as offsets_file:
block_offsets = pickle.load( offsets_file )
file2 = ibz2.open( "example.bz2", parallelization = os.cpu_count() )
file2.set_block_offsets( block_offsets ) # should be fast
file2.seek( 123 )
data = file2.read( 100 )
file2.close()
Open a pure Python file-like object for indexed reading
import io
import os
import indexed_bzip2 as ibz2
with open( "example.bz2", 'rb' ) as file:
in_memory_file = io.BytesIO( file.read() )
with ibz2.open( in_memory_file, parallelization = os.cpu_count() ) as file:
file.seek( 123 )
data = file.read( 100 )
Via Ratarmount
Because indexed_bzip2 is used by default as a backend in ratarmount, you can use ratarmount to mount single bzip2 files easily.
Furthermore, since ratarmount 0.11.0, parallelization is the default and does not have to be specified explicitly with -P.
base64 /dev/urandom | head -c $(( 512 * 1024 * 1024 )) | bzip2 > sample.bz2
# Serial decoding: 23 s
time bzip2 -c -d sample.bz2 | wc -c
python3 -m pip install --user ratarmount
ratarmount sample.bz2 mounted
# Parallel decoding: 2 s
time cat mounted/sample | wc -c
# Random seeking to the middle of the file and reading 1 MiB: 0.132 s
time dd if=mounted/sample bs=$(( 1024 * 1024 )) \
iflag=skip_bytes,count_bytes skip=$(( 256 * 1024 * 1024 )) count=$(( 1024 * 1024 )) | wc -c
Command Line Tool
A rudimentary command line tool exists but is not yet shipped with the Python module and instead has to be built from source.
git clone https://github.com/mxmlnkn/indexed_bzip2.git
cd indexed_bzip2
mkdir build
cd build
cmake ..
cmake --build . -- ibzip2
The finished ibzip2 binary is created in the tools subfolder.
To install it, it can be copied, e.g., to /usr/local/bin or anywhere else as long as it is available in your PATH variable.
The command line options are similar to those of the existing bzip2 tool.
src/tools/ibzip2 --help
# Parallel decoding: 1.7 s
time src/tools/ibzip2 -d -c -P 0 sample.bz2 | wc -c
# Serial decoding: 22 s
time bzip2 -d -c sample.bz2 | wc -c
C++ library
Because it is written in C++, it can of course also be used as a C++ library.
In order to make heavy use of templates and to simplify compiling with Python setuptools, it is completely header-only so that integration it into another project should be easy.
The license is also permissive enough for most use cases.
I currently did not yet test integrating it into other projects other than simply manually copying the source in core and indexed_bzip2.
If you have suggestions and wishes like support with CMake or Conan, please open an issue.
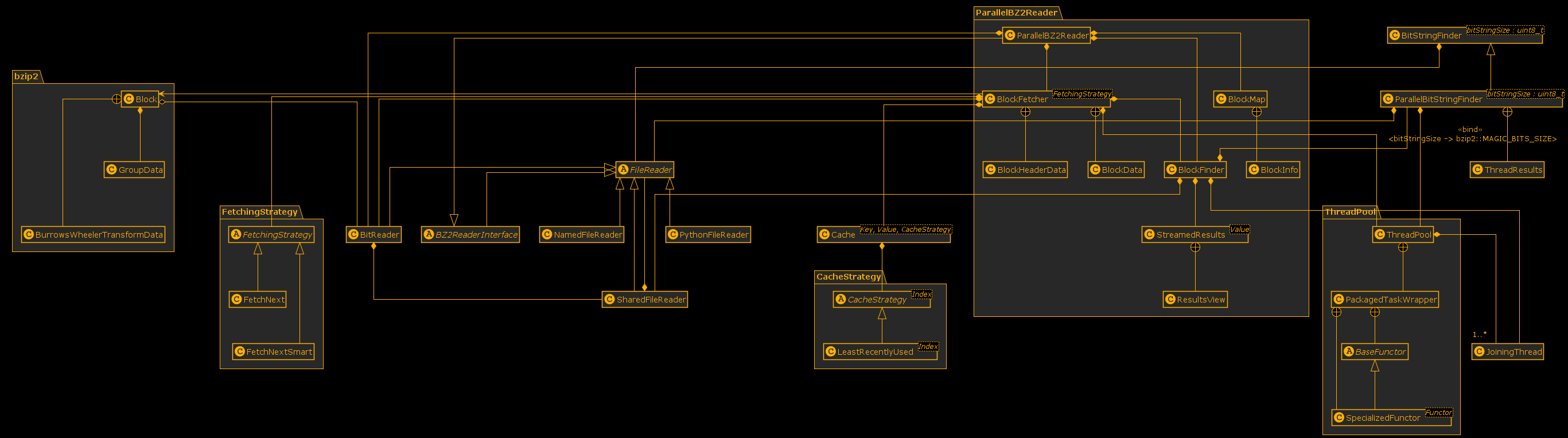
Internal Architecture
The parallelization of the bzip2 decoder and adding support to read from Python file-like objects required a lot of work to design an architecture which works and can be reasoned about.
An earlier architecture was discarded because it became to monolithic.
That discarded one was able to even work with piped non-seekable input, with which the current parallel architecture does not work with yet.
The serial BZ2Reader still exists but is not shown in the class diagram because it is deprecated and will be removed some time in the future after the ParallelBZ2Reader has proven itself.
Click here or the image to get a larger image and here to see an SVG version.
Tracing the Decoder
Performance profiling and tracing is done with Score-P for instrumentation and Vampir for visualization. This is one way, you could install Score-P with most of the functionalities on Ubuntu 22.04.
sudo apt-get install libopenmpi-dev openmpi-bin gcc-11-plugin-dev llvm-dev libclang-dev libunwind-dev \
libopen-trace-format-dev otf-trace libpapi-dev
# Install Score-P (to /opt/scorep)
SCOREP_VERSION=8.0
wget "https://perftools.pages.jsc.fz-juelich.de/cicd/scorep/tags/scorep-${SCOREP_VERSION}/scorep-${SCOREP_VERSION}.tar.gz"
tar -xf "scorep-${SCOREP_VERSION}.tar.gz"
cd "scorep-${SCOREP_VERSION}"
./configure --with-mpi=openmpi --enable-shared --without-llvm --without-shmem --without-cubelib --prefix="/opt/scorep-${SCOREP_VERSION}"
make -j $( nproc )
make install
# Add /opt/scorep to your path variables on shell start
cat <<EOF >> ~/.bashrc
if test -d /opt/scorep; then
export SCOREP_ROOT=/opt/scorep
export PATH=$SCOREP_ROOT/bin:$PATH
export LD_LIBRARY_PATH=$SCOREP_ROOT/lib:$LD_LIBRARY_PATH
fi
EOF
echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid
# Check whether it works
scorep --version
scorep-info config-summary
# Actually do the tracing
cd tools
bash trace.sh
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file indexed_bzip2-1.7.0.tar.gz.
File metadata
- Download URL: indexed_bzip2-1.7.0.tar.gz
- Upload date:
- Size: 254.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3fcdf8edf5d846c17d7200c024d447581a0723b55746d6fdcc610856ac33d42b
|
|
| MD5 |
78030dbc865f244c2e641544c7c4f9b6
|
|
| BLAKE2b-256 |
3acd2b9b5b0ecc9a646e33ba6bfcd53af055c3ee04955b539d0ab9c41202b0bc
|
File details
Details for the file indexed_bzip2-1.7.0-pp311-pypy311_pp73-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp311-pypy311_pp73-win_amd64.whl
- Upload date:
- Size: 254.1 kB
- Tags: PyPy, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
40171c2ffe0cdcd923f7c22c3f4711f14a3defb573f99e46228365b0779964cd
|
|
| MD5 |
af5f95fabaa1fdf91a7d7af231c113af
|
|
| BLAKE2b-256 |
5e910853b415ed807611ef28c340f0a782a125348c741fb97c2f1ded45520166
|
File details
Details for the file indexed_bzip2-1.7.0-pp311-pypy311_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp311-pypy311_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 467.2 kB
- Tags: PyPy, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
895fe8f5e043d588f9c319cc4ad71e944c84f419f13d4c7f4ac46f1305ffead5
|
|
| MD5 |
8ea342ee9599fb1b8f8f9f873efc611c
|
|
| BLAKE2b-256 |
30d482a6e6cb34c01898a4e8b30669d27879c3526d3998c44bc318cb5317972a
|
File details
Details for the file indexed_bzip2-1.7.0-pp311-pypy311_pp73-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp311-pypy311_pp73-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 586.2 kB
- Tags: PyPy, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58ff167c97392e7ba8ffe7d0d781483cdaa1c996161d25aa3b985fd7de907ac6
|
|
| MD5 |
121eecf4ef31a06481c818c84cf9117b
|
|
| BLAKE2b-256 |
8b3d572ed4cd7128f474ac56565a842a60f8246d521fff4f1220bf4bfeaef41e
|
File details
Details for the file indexed_bzip2-1.7.0-pp311-pypy311_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp311-pypy311_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 521.4 kB
- Tags: PyPy, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5a5509d6dcacc0517cb15ad3dd738cf60c8d7da3d55a15b7d75e826a4fd6ba1c
|
|
| MD5 |
4371d6f21b7f1c9a915163fb914fd71c
|
|
| BLAKE2b-256 |
82c3ece04df7075045fc0cf14341f629ab65ed632d8283785a0bd67a19e2ee5d
|
File details
Details for the file indexed_bzip2-1.7.0-pp311-pypy311_pp73-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp311-pypy311_pp73-macosx_11_0_arm64.whl
- Upload date:
- Size: 263.5 kB
- Tags: PyPy, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
64688c69c790c325fc3017cd2eebfe6e9289d86cf05ea4e5a0dddb42434dc26f
|
|
| MD5 |
e606b7b16936421d8d06d751ce471b1a
|
|
| BLAKE2b-256 |
6291b7d5161d2b334e24484ed9b9f91262376e90205d3766e2c63ad61f60b79a
|
File details
Details for the file indexed_bzip2-1.7.0-pp311-pypy311_pp73-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp311-pypy311_pp73-macosx_10_15_x86_64.whl
- Upload date:
- Size: 291.6 kB
- Tags: PyPy, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dbe7632ceb5a28e0c38825ab165d70b3eed1f71e94b1e92337f926ccbed479bf
|
|
| MD5 |
f02929e1cf859b6c50d41740497a9f5c
|
|
| BLAKE2b-256 |
40363b268124c7fdb3ee57a53ba0552877a3e1f3189894d3e6df085eddb1f06b
|
File details
Details for the file indexed_bzip2-1.7.0-pp310-pypy310_pp73-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp310-pypy310_pp73-win_amd64.whl
- Upload date:
- Size: 253.9 kB
- Tags: PyPy, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8e240413a83b14d4148af9818c694b5a3cd9106053b338b53abd4b97386fcc39
|
|
| MD5 |
1ab10e43a53bd856741dfb9a7c517ed3
|
|
| BLAKE2b-256 |
73d5d5427921e986bb58d1964898334904be681da4dc463598694bf687c87b08
|
File details
Details for the file indexed_bzip2-1.7.0-pp310-pypy310_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp310-pypy310_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 467.3 kB
- Tags: PyPy, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e15235c3ca1e1739b2c9224eca6f007935894bc59754d64f6a9f542e4563b301
|
|
| MD5 |
25ff2b1adf4743fec51dbc1fb1d3ebfb
|
|
| BLAKE2b-256 |
78334c791a65362eb777d38e5da0ddd1892db02dfec44ef6474ec147664ce0a7
|
File details
Details for the file indexed_bzip2-1.7.0-pp310-pypy310_pp73-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp310-pypy310_pp73-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 586.1 kB
- Tags: PyPy, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ce86d5c55026bdf724a351c4a96c56a965aab9517783b22b63ed70bbfb777daf
|
|
| MD5 |
146e63b5a5b754120224887a268c7c56
|
|
| BLAKE2b-256 |
873ef4798cf9ee64028b9c36f6cc3c6ca8ab03f056eae29c3105de69decb32f1
|
File details
Details for the file indexed_bzip2-1.7.0-pp310-pypy310_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp310-pypy310_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 521.3 kB
- Tags: PyPy, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9ad1807e35aab164d8badd5984480a98b1d5634dd636cbc6d9d7ee6e290a0930
|
|
| MD5 |
987143fa4795824c38dd0ab9b2cbfdad
|
|
| BLAKE2b-256 |
2cb4bf2954e7d24acff93264567694c5663a6bdd5ec6dadf1925c240f5e2a476
|
File details
Details for the file indexed_bzip2-1.7.0-pp310-pypy310_pp73-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp310-pypy310_pp73-macosx_11_0_arm64.whl
- Upload date:
- Size: 263.0 kB
- Tags: PyPy, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
43842c84d18e051e47a319a99f12988eaba82cba6d91055af8f245e155cfdd28
|
|
| MD5 |
a6290374bd54f8b1cfdfc7b6067f40d9
|
|
| BLAKE2b-256 |
21032b61177bda4a719918ad39ea9b53826e364e1c123025d806542959b9d618
|
File details
Details for the file indexed_bzip2-1.7.0-pp310-pypy310_pp73-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp310-pypy310_pp73-macosx_10_15_x86_64.whl
- Upload date:
- Size: 290.8 kB
- Tags: PyPy, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bb363e302431603c2714534dc13733257dafe8c08c24d4640119697fa7360406
|
|
| MD5 |
1a2704ab85fb5541240b98302d8a44a0
|
|
| BLAKE2b-256 |
3dac1230c49022fd893ca3651d7360a40599ab8b064d18231e925179a53d18ee
|
File details
Details for the file indexed_bzip2-1.7.0-pp39-pypy39_pp73-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp39-pypy39_pp73-win_amd64.whl
- Upload date:
- Size: 254.0 kB
- Tags: PyPy, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7df41d0043c9f3cd3dd41a079c529868af8c7878bb4b81406b66fbb41bd7ceb9
|
|
| MD5 |
36075bb811058d0f14becc34c910f0be
|
|
| BLAKE2b-256 |
c8f452ab7f1142aa4cd45232a46f961cb17d2764c176a43f9079309e454aa702
|
File details
Details for the file indexed_bzip2-1.7.0-pp39-pypy39_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp39-pypy39_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 467.2 kB
- Tags: PyPy, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b50d2e4a5ac32ebc52a833fae76e387a771653a23d666f951e5f984c9768883d
|
|
| MD5 |
826851c9838f15c94b9ee5681843051c
|
|
| BLAKE2b-256 |
0f13c1940c0961ea2be7edb104bd9e005b26d5a0dae4df5e56acac95575d33e7
|
File details
Details for the file indexed_bzip2-1.7.0-pp39-pypy39_pp73-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp39-pypy39_pp73-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 586.0 kB
- Tags: PyPy, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
639cc1d81fa289938e78c837d7b77e67c9eb0962d899a91cc4b371d440a38278
|
|
| MD5 |
de06d648d6c49693798f1e34a34c0f9d
|
|
| BLAKE2b-256 |
807a0f74e23465a645898a6bf7ca7f29449fc252a7d4e01c347a3b55d1502f8f
|
File details
Details for the file indexed_bzip2-1.7.0-pp39-pypy39_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp39-pypy39_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 521.1 kB
- Tags: PyPy, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
116a17f08d9bc021ddce8ddf7d7b5c862ee41e4892b28e9d693537427334262e
|
|
| MD5 |
8aa7ac4dd8712c52115589b110ffe150
|
|
| BLAKE2b-256 |
9b5b16ba55ac9da0f158e3654e8b42d3d022d4b134d78dc95d6b318da75cf008
|
File details
Details for the file indexed_bzip2-1.7.0-pp39-pypy39_pp73-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp39-pypy39_pp73-macosx_11_0_arm64.whl
- Upload date:
- Size: 262.8 kB
- Tags: PyPy, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0a13c25fa6ec7bd3507a0192a8d9de1a625cd0f324a3f751118aa091ef19b02c
|
|
| MD5 |
c8f91c6dd645753d125f76499f167075
|
|
| BLAKE2b-256 |
14359b74c25a399369e0cb7cbd3e18a0a3788cc70585722ac06bd6aa671d1928
|
File details
Details for the file indexed_bzip2-1.7.0-pp39-pypy39_pp73-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp39-pypy39_pp73-macosx_10_15_x86_64.whl
- Upload date:
- Size: 290.7 kB
- Tags: PyPy, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
55520659f6a3c534eb596f5b7a0a52e7088754f2d12f34df2566df8cabbf153d
|
|
| MD5 |
c49542f99f5f871a0566c29de6854df1
|
|
| BLAKE2b-256 |
7b385ab826db5e42e60bed80ae1d037a5637b1908c3cd67f6c1a1c3beea54efe
|
File details
Details for the file indexed_bzip2-1.7.0-pp38-pypy38_pp73-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp38-pypy38_pp73-win_amd64.whl
- Upload date:
- Size: 253.1 kB
- Tags: PyPy, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
524eb359619bb23c8de932f8c896366008146b6074d1d8f60e527b900e9b4e1d
|
|
| MD5 |
159f433d54c0f357c5549fa89bcd5dcc
|
|
| BLAKE2b-256 |
15636002b59b09d2f43c7fb3a35bf1b63e45492bd3bccdcbd8375c8818e15165
|
File details
Details for the file indexed_bzip2-1.7.0-pp38-pypy38_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp38-pypy38_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 466.3 kB
- Tags: PyPy, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9d1129e17e4847d3cf2935a2c7bf136c93bfc2b541883d75d45f055bc4000e93
|
|
| MD5 |
8a947d1efc6a37d056fa602869d53f50
|
|
| BLAKE2b-256 |
a7b7c1c300038ccf6c0b04e05541fbfc7053953132397ecb3e43fee9b38192e2
|
File details
Details for the file indexed_bzip2-1.7.0-pp38-pypy38_pp73-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp38-pypy38_pp73-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 585.1 kB
- Tags: PyPy, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
812042eab47297e50393928b82174a100200cecf12d9efd24e623ccf366aa0b5
|
|
| MD5 |
f129a352a9ee5d2f3ded1617a6966faa
|
|
| BLAKE2b-256 |
c1ea203ad7ef151d36642f5db829aff4342c6f47a6270c30a90db90a15697f1e
|
File details
Details for the file indexed_bzip2-1.7.0-pp38-pypy38_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp38-pypy38_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 520.4 kB
- Tags: PyPy, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
03baafdce5c7322aeae0e3aaa71efa468cc9182a6ef8552adaa27944c0466b39
|
|
| MD5 |
85dd6396f2cd7d29cc05831a172f3923
|
|
| BLAKE2b-256 |
6b7d1f699c21fedc35bcc80a4dcc673a60c7595741c3a25d7c9e44ed396defdd
|
File details
Details for the file indexed_bzip2-1.7.0-pp38-pypy38_pp73-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp38-pypy38_pp73-macosx_11_0_arm64.whl
- Upload date:
- Size: 262.5 kB
- Tags: PyPy, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
16f4038e280d606d33b8eb17f4f0e670d8d3484d487ce77298436f23c4db1b26
|
|
| MD5 |
b11d28701c97dc5189c115d044282184
|
|
| BLAKE2b-256 |
434f008c731c551a0c0a1160e41fe83113b3bbd48a6b4d03f3df7b92f446100b
|
File details
Details for the file indexed_bzip2-1.7.0-pp38-pypy38_pp73-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp38-pypy38_pp73-macosx_10_15_x86_64.whl
- Upload date:
- Size: 290.6 kB
- Tags: PyPy, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
98d61c2444581f25f616be2a6965f034e984abf0ca0165887be77c36e4a487d8
|
|
| MD5 |
8abf114e199e81a638ba19d0c40b0fd8
|
|
| BLAKE2b-256 |
de9d3f58292bc439921a251bfaa29f3bc5b3793bc62ec818321c946db045eb3f
|
File details
Details for the file indexed_bzip2-1.7.0-pp37-pypy37_pp73-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp37-pypy37_pp73-win_amd64.whl
- Upload date:
- Size: 253.0 kB
- Tags: PyPy, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e99a88cae02715b0d36a8102aae675954692d2ea08cd345d75967cdc67d66874
|
|
| MD5 |
f87fd3b7b7931b45017cfed0339cb0f7
|
|
| BLAKE2b-256 |
d534422321ecd91cdaf30c3f36efcd13600f58bd20214b8c8668e6682098b846
|
File details
Details for the file indexed_bzip2-1.7.0-pp37-pypy37_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp37-pypy37_pp73-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 467.1 kB
- Tags: PyPy, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ddfbe3feba689a0c9f795a0e350a1ad4956d3d945996fe44d91557810669bf9d
|
|
| MD5 |
ee803929bcb90c8ded9809ecfceb37f4
|
|
| BLAKE2b-256 |
5d4f705ab9ba7cf7c3a700c6040303f32d114184e936ecb2f2e5622fd8d17380
|
File details
Details for the file indexed_bzip2-1.7.0-pp37-pypy37_pp73-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp37-pypy37_pp73-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 587.6 kB
- Tags: PyPy, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d51246b8071dc88bfccace8e994cde89dc2b2996fa17f9de21e750249a7e94d7
|
|
| MD5 |
de56f3e101b78c61449ef2d841afa99f
|
|
| BLAKE2b-256 |
dd6eef59086840d906a85711d7f59a703b41c030be2ab45d5f64b20c000036c6
|
File details
Details for the file indexed_bzip2-1.7.0-pp37-pypy37_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp37-pypy37_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 521.8 kB
- Tags: PyPy, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2bf6a1d11cb1309bc65a7bf6af4c32e57db20717f0e870e1a92a88f55911783c
|
|
| MD5 |
062a25965168e8d630402e939f5da275
|
|
| BLAKE2b-256 |
60ce8de7db10073dafd9cdb2a34db1e99e648290fe753ef7af6dbd09f20ce89c
|
File details
Details for the file indexed_bzip2-1.7.0-pp37-pypy37_pp73-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-pp37-pypy37_pp73-macosx_10_15_x86_64.whl
- Upload date:
- Size: 290.6 kB
- Tags: PyPy, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
96776f376dec6b0c98e39181ebc186351ed5d4e33a7bd2f20b2640adaa21d0ee
|
|
| MD5 |
fa8dded48ba26318417399f1448fba89
|
|
| BLAKE2b-256 |
4dbc69d0aca251bbd7e63d904442a46bd93fce79a0bd207b477424166d18403e
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 258.7 kB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
592069433af0bef929fd0565b85e685689acece95a1c9a64f24fd825c761d87c
|
|
| MD5 |
24868a43c0981a5dd30c429bb21c276e
|
|
| BLAKE2b-256 |
bc36c1c80927778559f7714e9e8a8849b68d78913281bc65d616f8871ba1de2a
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.5 MB
- Tags: CPython 3.13, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b7f9041ed7055e6bcaa6b2fb5927fe84a54187d1f9b4aac7838088f2918440ce
|
|
| MD5 |
51da645e02222d2fbb6fd6f418af69be
|
|
| BLAKE2b-256 |
fa606a087b5fb3462ba78c6c8991ecf764c110b8ab88ac9405258bf1c7ed727f
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.13, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
64cd97bf752f90066d62b6503ae3c1843244b6c71b598b0a1e59110b339e232f
|
|
| MD5 |
11d614937011810d4b3063d10f11319f
|
|
| BLAKE2b-256 |
d785bec622276a073ffa1827a44df20a534136d17995036284e692d2654d34d0
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.13, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
158c8a027b259534fc0c942418c2b7c1cc5c9ea18f93c88d084ff6a87c7cbbcc
|
|
| MD5 |
dff96eacb40ae93fa06824bbf3b3c64a
|
|
| BLAKE2b-256 |
7ac3244218affde4ecc2ddf63f46e788bb7cdb8000ce273697a10c9ae5f12bc5
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.13, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
606b21e753df29222377ad0df3490a80a5b38d4183f97a221ca3eb5abd845f49
|
|
| MD5 |
e9aca78dc4e79b40ee5978967b7959c4
|
|
| BLAKE2b-256 |
713dab1c025bd7e00e1b8efacaaa7500e0d1f9aeb0f1b0b8ab619951071771d2
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.13, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6eeba3d359c813ec6441735c70ef11e606ba4c0e94a832293c9b7e4de5f5e3a4
|
|
| MD5 |
e713d2e867ad22f084a9e3df60a67ffb
|
|
| BLAKE2b-256 |
1e47b7fa9fd6a4e75c380cf78e2135a340cbd16215a42a349b20fa324cb95736
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.13, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ae12142a2a90db922263eb5e0c35f1a4fc6f9e27380c16d7d8b91aca41eaeda3
|
|
| MD5 |
cd40de47566615f73ea132c876ce037b
|
|
| BLAKE2b-256 |
a4df39f7c336084cc65e90857a7690485730246dcbf1e04b068da4f4f84baeac
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-macosx_11_0_arm64.whl
- Upload date:
- Size: 284.9 kB
- Tags: CPython 3.13, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6735ed87bc2bd2a97ceb4706809012989333e4515a915dfc719d3b4cc7901ce0
|
|
| MD5 |
313b102ae9e80db56e6a9d27bfbe83a1
|
|
| BLAKE2b-256 |
0005392f75850de4bc0760902014f4476b3e5aa0c9f92c26fa676af325e066e1
|
File details
Details for the file indexed_bzip2-1.7.0-cp313-cp313-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp313-cp313-macosx_10_15_x86_64.whl
- Upload date:
- Size: 308.6 kB
- Tags: CPython 3.13, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ed32e940e09c54d82fbb12ffd764e467e34f6729396510a37efb2959fa9321f7
|
|
| MD5 |
ddb142fcedffa2a2f4cb91f26071d785
|
|
| BLAKE2b-256 |
1e59054d340e9cd1918baea345c80c227d0bce53c3f900f8f81878a18200294e
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 259.0 kB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
10ad685402183cb603862977857bb72c44ee3190515cc29fdea9fad449939057
|
|
| MD5 |
2301ee1734827375f57f10b630cd4e26
|
|
| BLAKE2b-256 |
bb4130e24612e686847a2bf552670c2fe52f05d192307ad412756bcc2f5e2067
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.5 MB
- Tags: CPython 3.12, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2cb41f771a62e8bc037878153839e056219c6b9c4e94d5776b271bc31cf0f4a3
|
|
| MD5 |
2c18e3dda32d2d7c397199325b427687
|
|
| BLAKE2b-256 |
60437bcc3babc2c1c17ecc568bbc12df6f05ba88ef40aca31502738b405dcc06
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.12, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6243bcf9c49543bbf7914564b371aadebc6b6e76144bccfe799e3e9083828b02
|
|
| MD5 |
373d3a6e62b344b32858f818daf037a9
|
|
| BLAKE2b-256 |
e7b972f6f48682a8643e9c8c5f3449ca6afe6f4df7f92fac9c1c1a3f3f7b06d7
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.12, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
80cafbac79ee52a0fbc4ef51fde384ec8d18b82595692d40e799a54b70720f89
|
|
| MD5 |
c9bf84728e29be10d871c42d130adf60
|
|
| BLAKE2b-256 |
9fa0b9a72987fe6c267ae3e13848212e0aa86f99768bca839b56ef60cda0b251
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.12, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
741dfc6beda9ffd35969585ffb0f6d7f5507033bae9d327e591bc4079a0f3492
|
|
| MD5 |
ac28bd8b1ef9aa5d663f0a474258742e
|
|
| BLAKE2b-256 |
b077974285b9a4867fc04369ccbe463aa7497e47e95a007f9712be17dad6df58
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.12, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6a5a40d7f88836b5162df8bc4dcec5d309a1e511a090683c9a00794a842259c2
|
|
| MD5 |
1219378877354bab92d1ce34d4ae285b
|
|
| BLAKE2b-256 |
97b97cf79c04d883a997480003e6dcefeaaa1f78ea194b2abdb288470d8ae88b
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.12, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cf08be3e60e84a42e3f60a941020516c3b42ab129f573da642043183c30e2803
|
|
| MD5 |
7635fb9e22b31141687b4ca2ec0b6782
|
|
| BLAKE2b-256 |
0a512a61ec85fee25295010006b20ce855ae8d74fb9b0ec87d29119c10cb44ab
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-macosx_11_0_arm64.whl
- Upload date:
- Size: 285.9 kB
- Tags: CPython 3.12, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
77bd1567386c18a1cdc5e07e1bef8635731418e37ac75fb2c222d3316abd195e
|
|
| MD5 |
2dc9890f3bb5e6a3d892f685d5e58e7e
|
|
| BLAKE2b-256 |
19cc1a85c1883c2129f84441089aa8a0f36dcacdb2c19e6b3741f7a09ed69297
|
File details
Details for the file indexed_bzip2-1.7.0-cp312-cp312-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp312-cp312-macosx_10_15_x86_64.whl
- Upload date:
- Size: 309.6 kB
- Tags: CPython 3.12, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
33e906aa52a7d58c05b974dc21dac010415d6eb6bc5319db47cc975d37454a1e
|
|
| MD5 |
a8c3592f904b1b8a23374478deb8c228
|
|
| BLAKE2b-256 |
8912460771e117c9fe760244f1726be5850df1b0612a3059d033b5a9acf194b9
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 259.0 kB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
00cc5556b269c4a5b42e22b61bfc1d598803503bc45fdd3917077b177e0f44f2
|
|
| MD5 |
e11d6c088745a9181572628c306c6b28
|
|
| BLAKE2b-256 |
c33975e961e048878bc36f076a061e4c308a4512b8eafbfc09c3b978fbcafe44
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.5 MB
- Tags: CPython 3.11, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b2165a7406411fbc0b145048e23f29b90702121b0e9a8391e6bbd981b1b5ecf8
|
|
| MD5 |
53af6e7ee471dfd929068b40c0c04aab
|
|
| BLAKE2b-256 |
eb855ca45e8bdc82eda0177c0d6cb492d4cecb82754bea3fbf4dc34318ae382d
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.11, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d5d6a85746996040272fc92987908d6361be9c40eb4ba42c1c9ebfdecea0e15b
|
|
| MD5 |
e6e5a8b69a11cb5f0069780f36fef44b
|
|
| BLAKE2b-256 |
2314ee5a64ea34bd6167bf5109186c987f5a80e93f361a7f032cba8210b0eacf
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.11, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
50068eeb5afd4faed58f37c67322f9f9211aa0f3ce50c64fa92d39afc4b10f02
|
|
| MD5 |
cdf5f318563c39337ddc53ee2cbee9ba
|
|
| BLAKE2b-256 |
d66062b3485e4e5e0803c7220166e9536db596c7ed6288dc5270aeecb2f38e94
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.11, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c8a3bb364a70a8f58d99c04d57c3b6ed025727c372f9be30fec3d576e408ded4
|
|
| MD5 |
763f7bcd4342a4fe6b06ba386afe9c59
|
|
| BLAKE2b-256 |
48173e3cfc7e3c107bdcf00137bbfaa4cb420898d6ad0c605c2e05b791c23772
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.11, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
70c0b096ca5e8d4e7fd041489b60d03c600b71d23d10078f9004b3341b7bedf5
|
|
| MD5 |
c5310d1c3df755a5a706d8fe19620f9e
|
|
| BLAKE2b-256 |
bbf9d386846d3c9e0a76986bd9c83ced621d47be7b921b35edc0d1fbd51bfeb2
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.11, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
45265b6764b8047d31cb2e68825865090485871d8ac00b4231cfe217c6961176
|
|
| MD5 |
190621e39d5f76ffad2c02c6ccf21d3d
|
|
| BLAKE2b-256 |
7a1a357eab996d05629ed8aae520b4217af069fddc8137191787ed806b9112a5
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-macosx_11_0_arm64.whl
- Upload date:
- Size: 285.9 kB
- Tags: CPython 3.11, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b0143af198ba682261a6c971fcf8450df13d731c05e80f61e7c135038b20c425
|
|
| MD5 |
ab15c9da1e8e022eaeeccb59c178401c
|
|
| BLAKE2b-256 |
832ccd6c79462bbfb0b4aa5bb1390c2b016cac0866c67274250c99b89d071584
|
File details
Details for the file indexed_bzip2-1.7.0-cp311-cp311-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp311-cp311-macosx_10_15_x86_64.whl
- Upload date:
- Size: 309.1 kB
- Tags: CPython 3.11, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0bfeb913a05fa3c85be3b9e7b11c3ba6b8cd884b2e3df80875f28b9d5a538936
|
|
| MD5 |
af8a53f6fdcb879585e77b7b415979fd
|
|
| BLAKE2b-256 |
b5d995a5ec566002b0a2cae49a84c5eec33b7399c1db805f4b2c0622fb892ded
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 258.7 kB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e823516b403130b6bde42c000bd65a82a2231879b0127a22b2d331b1fea1bd92
|
|
| MD5 |
d4aaf2d37c4cb1f0871d15530c0e13f6
|
|
| BLAKE2b-256 |
9cacdfb3e5082f60273f636e1fe67c1eeaef2a4517e29f1b568ae412da8ea31a
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.10, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
323342b198cc071afb7d839c450cb4b61875cb6b8aceed76f1e49c12cbe85318
|
|
| MD5 |
45f6cb98f3747532ff3a5661ef77a939
|
|
| BLAKE2b-256 |
942a10bfa5da0623013b86aa6ae993592776facdb6bbebee746af14eafb1f5e1
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.10, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ab74580fb45db10fe0cf8610ddeaab002b0682198bf127a69944eb40e95321ce
|
|
| MD5 |
2879ae332d5928f549380413259903d4
|
|
| BLAKE2b-256 |
4a0d117d514a0b6a634dd71fa16feaa62bf9938da24634640097607f6b003952
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.10, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
275e774f27616bd78e32614b768e2a99d6ed21de33355489840a6722e45d86b8
|
|
| MD5 |
53404d1d9bbb85f7e003e9f5bc2e96ae
|
|
| BLAKE2b-256 |
23ab4ab1a0e2847167d6e55bf843d222d233f8f554a00f7dd69965dd64fa4cc9
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.10, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
836afd60440442e0030fd29f5adbab617dc9be32cb78f35774aa38ad24fe092c
|
|
| MD5 |
87f51fa32fb7d686e099585f6fc29fcd
|
|
| BLAKE2b-256 |
921207ef395ea92d0b2e9fc1f4f4b4eb1854731194bc36379796f6c0a3099923
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.10, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
415bd77cdb6fcb1dad3953945dc8a4c5d0d131ae453cf3baa4acf57fd1e49d86
|
|
| MD5 |
a5e0f536dc13fe122884736f20d5637b
|
|
| BLAKE2b-256 |
960132f65b693f7d1ab5c58dc7e15e6fb19852e1ce140e07081dd74effddaaa1
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.10, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9d8250a09474e0d209965cf16b5bb0a16a86f1176b2315a88ab345d7b6b11aed
|
|
| MD5 |
f934ba08c6b44cfec2031394a4e77b36
|
|
| BLAKE2b-256 |
e200049e6ceb6e46ccc91983e8d13abfcb61735164d0ebd121f6df6e158be613
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-macosx_11_0_arm64.whl
- Upload date:
- Size: 285.3 kB
- Tags: CPython 3.10, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1d15e150402a096c58e9d62f2d22e3c76365868629a9599c4dfc448db2c5bcd5
|
|
| MD5 |
f60482b56188b19256f9e4031e67ef23
|
|
| BLAKE2b-256 |
9ada6445792ac66a494a1f1cee428280f5035dbd03845afe2f92c3c1cde9bb1d
|
File details
Details for the file indexed_bzip2-1.7.0-cp310-cp310-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp310-cp310-macosx_10_15_x86_64.whl
- Upload date:
- Size: 307.9 kB
- Tags: CPython 3.10, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
39a7f9708072597f5dcfb11e93982b5b29c36bd3349b73f8a81062881c6e7f5f
|
|
| MD5 |
2b5c3bbdbe5b0590a61ac5b93960498b
|
|
| BLAKE2b-256 |
8921ce8b5a7e5a1363eb7ac4a339bd1f6da2d5ecebd30ceea1438d8910aae0b8
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-win_amd64.whl
- Upload date:
- Size: 258.8 kB
- Tags: CPython 3.9, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0a6816a515d28900e92023ce351c68d9af36984fd798e5dcf05b0435715aa313
|
|
| MD5 |
79c8ee649ab80f89c716b4a0ab599b34
|
|
| BLAKE2b-256 |
84cf15504f3f7ff69608550c8457f7e51680e43bee160acc44f8b40f1a157b41
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.9, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cf7045694ea3ac1fa7f24e87f689f462b800e456eac0e683a6e79824db234ba0
|
|
| MD5 |
e7c4b61f036f2b315aa87c562aafb31d
|
|
| BLAKE2b-256 |
7b20c7439691bf243bfbb56bc895999c68e517caed9022e9929b0afbf67f25b6
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.9, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7c98294f0fdaa246ec7e6f85f23f875737a97f1e3459d4879bc0bbeb1b731dfa
|
|
| MD5 |
7803c9ffd9dadc24ed01e4e45f577027
|
|
| BLAKE2b-256 |
7123b0fd0ae18970f39cac6c4d2edbe5880321c30a6567718d49b5804d3d6045
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.9, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f2fe32ad4f20135a7072371b05e563582dffa98ee7082258fe1dbf9de6f1b996
|
|
| MD5 |
b0df3d43164f563f6c5920a0c6abc857
|
|
| BLAKE2b-256 |
5b3d87384af6903ffa5444bbd296f2abd7827b404ab9cecce3533a241318f2da
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.9, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
309a9abf5bbab6cfabe6b5a3aab39e3cc97b3acf5461d2e6e6215f4423446708
|
|
| MD5 |
3070f7c810c23858bdb6b2f16ed02a4f
|
|
| BLAKE2b-256 |
d1bc1b58a8a24bdf928ebc90acdeb3b65e8d78a49b2d7eadfa6c306df7635bf8
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.9, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
37e7d7a864b409cebaf6fed644dd1511cf3e22b80f9dff3297c7f6e235ed6cdb
|
|
| MD5 |
61b72cd16a89b7c489b0de3461625e48
|
|
| BLAKE2b-256 |
89233c01a64361d51cfcff502dfe6713626cf5c54df209621dc4ac3722c91c30
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.9, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c4145d9a09ae6c6332b78a2586e76780153f44d15c2bc4688cf95be5a726160
|
|
| MD5 |
81182c4964703a80d011e710d705cbb7
|
|
| BLAKE2b-256 |
6d81c004b13f222e0ad90c2ea97cdf6e07be9f09884949a45c7504b89aff2d33
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-macosx_11_0_arm64.whl
- Upload date:
- Size: 285.7 kB
- Tags: CPython 3.9, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2e92b5fd371d0d717c51b332c0fafabbc19ff33b0fb32c719bcfbf91987c2c6f
|
|
| MD5 |
893fafec09fab2f796a6be54b6f34309
|
|
| BLAKE2b-256 |
2acd07026e598b0fd1e9ee4ed60c2023571907a24a1d234ac55770ee7e362ab4
|
File details
Details for the file indexed_bzip2-1.7.0-cp39-cp39-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp39-cp39-macosx_10_15_x86_64.whl
- Upload date:
- Size: 308.2 kB
- Tags: CPython 3.9, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d68de685dcb98975df5dbf404a9bd506f4d4b96db58904e3232bc1acccb9a73e
|
|
| MD5 |
d99cdc5340754605ea48702c4cc91a98
|
|
| BLAKE2b-256 |
37fcbee397b9864e8c47253865b450fada22c627332ac24499d47994bdb80f2d
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-win_amd64.whl
- Upload date:
- Size: 258.9 kB
- Tags: CPython 3.8, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a1bb2f18e7f5f6a80afe290e3e0592e6f9a9705dc263e73e63de896b91e7b9f4
|
|
| MD5 |
f4ff88dc0fcf54783adb4f75c0ae1a20
|
|
| BLAKE2b-256 |
18fe28bb8190e6a89864f713a60004a0d9688a86fb94d06033840e7b8c836a98
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.8, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
aae642e4dd972c187f67e4c2b6edddcff43819fa9eb9c74ed14dc88d814aeef1
|
|
| MD5 |
7d14c1ea2e0130652e23ac5326dd106f
|
|
| BLAKE2b-256 |
17a708c80a6bc91c3e3c43b240b6f59fea501a08575d4b344af174bb5e25f480
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.8, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0fa19a49bf609c17ac150005617b4f253d2e824683ec330c85d52bbf9e1392bc
|
|
| MD5 |
ebff79725fe56405dce74e8cc09aec22
|
|
| BLAKE2b-256 |
04efdf4c31cb0f96a1d39b93da4503a5b6f043b7aa6539b279d987b9d51f0fa2
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.8, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
683aec45f7166e9560571ea85526cd8e0deefd2a495b5f6f7a876c55768a922c
|
|
| MD5 |
9eb5b6e7e8a4bcc3d37e7bca976fe47b
|
|
| BLAKE2b-256 |
15e562774090f07ab671fe0195c21f092cc5643f7f419963b20795fdcb9b593c
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.8, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0dc8456d04853d790d0451050865216ee19e93e93278e5b7f5c83ad4ef40507e
|
|
| MD5 |
0c8aac4a4d6184f1be0693170dc6f35f
|
|
| BLAKE2b-256 |
aad7274c54c0f4fad824ca878d8479df781ca3ee47e6aeacd27646d2099c0a71
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.8, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
260ec7b587bf41cb6a2912837167f0b9420377c46dfe9e06b0497dc68f854bec
|
|
| MD5 |
eb1103ca62f0ee88ae299d82dc406346
|
|
| BLAKE2b-256 |
23b903bd959b9390077138d14ec4b8645e4d451c2078d2bc261178625ab7cb56
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.8, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6940d36f2fc30710ee1020c61c6f875997b2ea49cc43e1d47134b597a98572ea
|
|
| MD5 |
3ff0e86fc13f76687c91865680dca3c4
|
|
| BLAKE2b-256 |
7c5b38226c0bd21e6a00be3defe15c20bbcd9a303aed695bdfa407bc8d444497
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-macosx_11_0_arm64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-macosx_11_0_arm64.whl
- Upload date:
- Size: 286.0 kB
- Tags: CPython 3.8, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
934211dd1494eac13a3125da52162a85282c69b924d2ebfb34a665cbb52639e6
|
|
| MD5 |
40c5d6663fc79a63ac547b7a07d36984
|
|
| BLAKE2b-256 |
89b4a96f63dda5e696da75577255a2cda7da6ba62ad1dce5b4e843d8a4b98540
|
File details
Details for the file indexed_bzip2-1.7.0-cp38-cp38-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp38-cp38-macosx_10_15_x86_64.whl
- Upload date:
- Size: 308.7 kB
- Tags: CPython 3.8, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ffd9bc3891942cf57e7fe4e90cef4466103ca11c8c2859642061902dbb0a3496
|
|
| MD5 |
90de0a5d1b6815d04f98a45b70c9f76d
|
|
| BLAKE2b-256 |
c1a698ef6d5968bd34a7251e27bc8e3e4417472438579c489ea5c03c90cc7669
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-win_amd64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-win_amd64.whl
- Upload date:
- Size: 258.5 kB
- Tags: CPython 3.7m, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
94a5c7f266d3b2db6b2c160c932b298445a70cee2ff88310ea016ef8df94c92f
|
|
| MD5 |
14900771c61d05ee6bb0d7be2b64250f
|
|
| BLAKE2b-256 |
a2905f7e82cdb6f3d59a954aaea17e1b1586c3f5dcd9fe89cea8adde8d26ec56
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.7m, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b01efa13ba4d1dc6f053f8ac80d59387a7b2cbffffbb1a0f0f90c34c5e85bafe
|
|
| MD5 |
e69ef4c5652da2f0fecf68a1ad550e06
|
|
| BLAKE2b-256 |
dd58da08bd7d988013c8bee2d02f1294c4961f54205f17f669133cd5bef369b5
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-musllinux_1_2_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-musllinux_1_2_i686.whl
- Upload date:
- Size: 4.6 MB
- Tags: CPython 3.7m, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
01cbfe4cf3d76a23dcd0d581fa7e5e16cbb0e8faafdf5594f36274771558b2a8
|
|
| MD5 |
15ec4247315722db847d47ec97a53b5e
|
|
| BLAKE2b-256 |
0005fe8d93b4507b006ecb167096371f57601857f5a5cd012671467e8961f14c
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 4.3 MB
- Tags: CPython 3.7m, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7b794481ace0c50ec9cd687a3eb56874e6869fde85307b5b7cec339bb5810fdc
|
|
| MD5 |
a300af098898aafadeaeaff7a5297a80
|
|
| BLAKE2b-256 |
c0350d4dd05a60a6f658f1211dce3a3779275c97ea415cbbf812068f3883f25e
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 3.6 MB
- Tags: CPython 3.7m, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ecd72267bf87a8e7e9e6b769e37c76f8c65a5f1d5c1e96b01ae64979bfbe2253
|
|
| MD5 |
13584c84541c4fc0c0a73dd5d03e3bc9
|
|
| BLAKE2b-256 |
a6adf038eff7c841e26d6b3b064615beecbb54c021bda3e28198c6ab918128ee
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.7m, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7f9b54a1a66e8444733858582b424fb89f85af8a1143a2207484435884b9f4fd
|
|
| MD5 |
640d79774bd828ebb3406fd4a799469f
|
|
| BLAKE2b-256 |
e2404c299efac80dee2c506ac9a5327432c36b636161904c0928a2c902c8bb4e
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 3.7 MB
- Tags: CPython 3.7m, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
91c92e4b40124ed52c86b012eb1d4e4b40b154b7aad8641d72b2494b90e72457
|
|
| MD5 |
4ca5530800b4fb77bac4af2df185e2ea
|
|
| BLAKE2b-256 |
3f20681bf33ff8c562731f87cfc58074f41a2b324a60b8dc8d548594bd15f929
|
File details
Details for the file indexed_bzip2-1.7.0-cp37-cp37m-macosx_10_15_x86_64.whl.
File metadata
- Download URL: indexed_bzip2-1.7.0-cp37-cp37m-macosx_10_15_x86_64.whl
- Upload date:
- Size: 309.1 kB
- Tags: CPython 3.7m, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e640927adccefb18b33596b4b24e5e5c5a10d54d66d14824e5d15a700cc1dca8
|
|
| MD5 |
946d4e47f7f217e53ca0fc2168935ddd
|
|
| BLAKE2b-256 |
2273d8b8c3b5c5c105d6019dcfc745b937402a3309805d31c9a179754d0d9eb0
|








{kind=link}