Run any Hugging Face GGUF model on your own GPU — TUI only. Type `inferhost` and you're done.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
inferhost
📖 Full documentation: https://amirrouh.github.io/inferhost/
Run any Hugging Face GGUF model on your own machine — TUI only. inferhost is a small Python framework that wraps llama.cpp and llama-swap behind a single LiteLLM gateway, exposing one OpenAI-compatible endpoint at http://<host>:9001/v1. llama-swap is now internal and binds loopback only.
Key features:
- Single endpoint, always on: LiteLLM is bundled (no extra required) and auto-starts on
:9001. - TurboQuant asymmetric KV cache compression: K=
q8_0, V=turbo3by default (the TurboQuant authors' recommended pairing — "V is free, K is everything"). ~3-4× total KV reduction via a customllama-serverbuilt from TheTom/llama-cpp-turboquant. - Pin = load now, with VRAM guard: Pressing
Pimmediately loads the model into VRAM. If it won't fit, inferhost warns you and asks you to unpin something else first. - Prebuilt binaries, nothing to compile: inferhost ships
llama-serveras prebuilt assets for Linux x86_64 CUDA, Linux x86_64 CPU, and macOS arm64 Metal.
uv tool install inferhost
inferhost
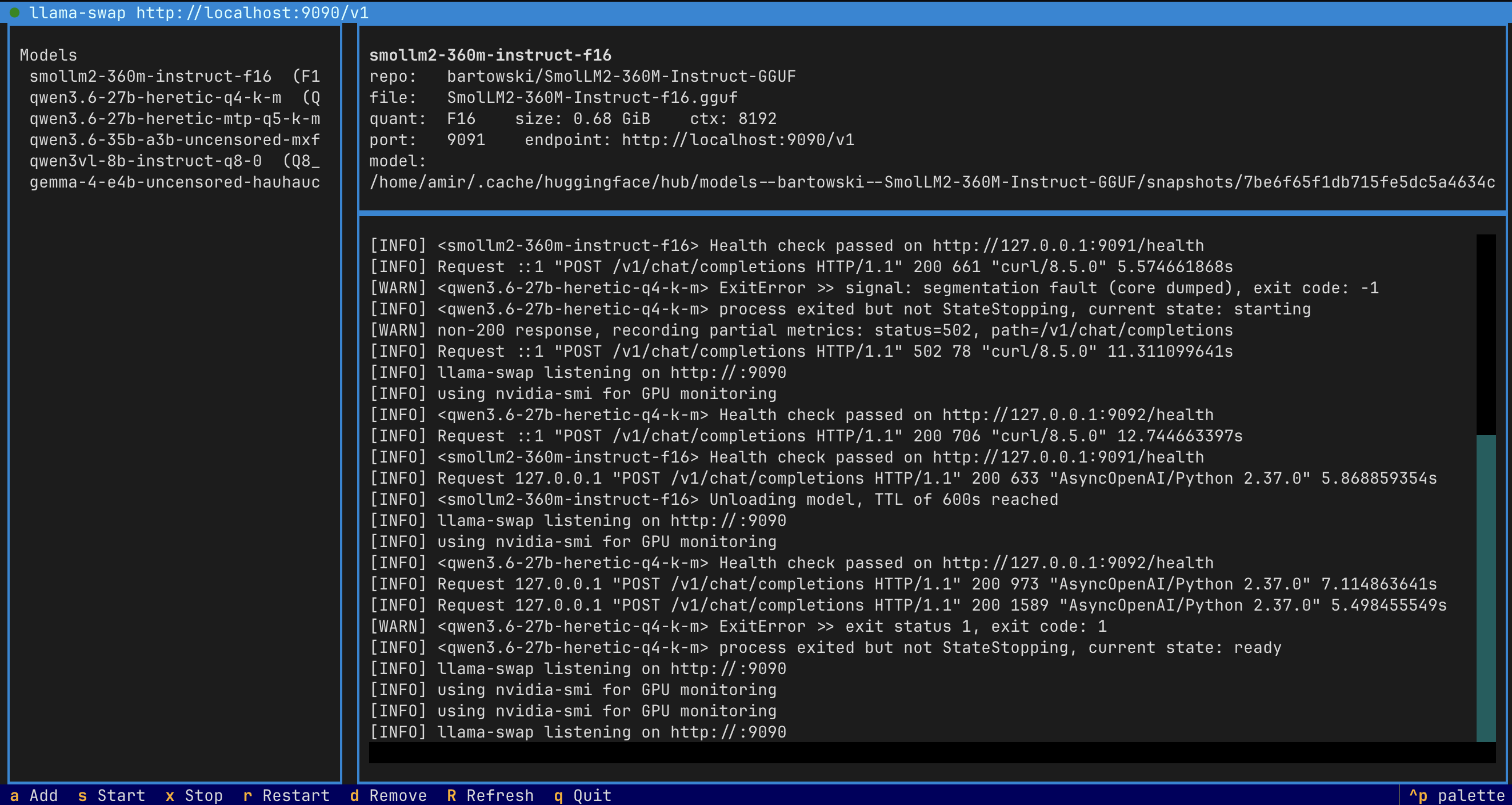
That's it. The first launch downloads the runtime binaries (llama-server + llama-swap) for you with a progress bar; then the dashboard opens and you can add, start, stop, and inspect models from the keyboard.
What it does
- One-key serving of any GGUF model published on Hugging Face.
- Automatic quantization selection based on available VRAM (
Q6 → Q5 → Q4 → IQ4fallback). - OpenAI-compatible API out of the box, including tool calling and vision
for any GGUF that ships an
mmproj-*.gguf(auto-downloaded alongside the main file). - Stacked speculative decoding for MTP-capable models — combines llama.cpp's
--spec-type draft-mtpwith--spec-type ngram-modso MTP handles novel tokens while ngram-mod dominates on repeated patterns (code, function names, etc.). - Multi-model support via llama-swap, which lazy-loads model backends on demand.
- Auto-detected hardware: NVIDIA CUDA, CPU, or Apple Silicon Metal (prebuilt assets);
for Vulkan/ROCm, point
INFERHOST_LLAMA_SERVER_PATHat your own binary. - Live download progress for both runtime binaries and Hugging Face model files.
- Full control from the TUI — change ports, edit context size and GPU layers, watch status of every daemon. No editor, no YAML, no extra commands.
- All defaults still overridable through environment variables or a
.envfile — the TUI just writes another.envfile at~/.config/inferhost/inferhost.envso your changes survive restarts.
Installation
Requirements: Python 3.11+, Linux or macOS. NVIDIA CUDA, Linux CPU, or Apple Silicon Metal are the supported prebuilt targets.
inferhost is a CLI app, not a library — install it globally with uv tool (or pipx), not into a project's dependencies.
# Recommended — global, isolated, on your PATH
uv tool install inferhost
# Alternatives
pipx install inferhost
pip install inferhost # only inside an existing venv
Note: In v0.4 and earlier, LiteLLM was an optional
[gateway]extra (inferhost[gateway]). From v0.5 it is bundled — a plainuv tool install inferhostis all you need. The[gateway]extra still exists as an empty alias for one release to avoid breaking existing install scripts.
⚠️ Don't use
uv add inferhost.uv addpins it as a project dependency, so you can only run it viauv run inferhostinside that one project directory. Useuv tool installsoinferhostis a normal command on your PATH.
Upgrade
uv tool upgrade inferhost # if installed with `uv tool`
pipx upgrade inferhost # if installed with pipx
pip install -U inferhost # if installed with pip
To pin a specific version:
uv tool install --force 'inferhost==0.5.0'
Uninstall
uv tool uninstall inferhost # if installed with `uv tool`
pipx uninstall inferhost # if installed with pipx
pip uninstall inferhost # if installed with pip
Inferhost stores runtime binaries, logs, and the model registry outside the Python install. To wipe everything (binaries, llama-server logs, model registry — but not downloaded GGUFs, which live in the Hugging Face cache):
rm -rf ~/.local/share/inferhost ~/.config/inferhost
To also drop downloaded models: rm -rf ~/.cache/huggingface/hub/models--*.
Usage
There is exactly one command:
inferhost
This opens the TUI. On first launch it downloads llama-server and llama-swap with a progress bar. Afterward you land on the dashboard.
Keys
| Key | Action |
|---|---|
a |
Add a Hugging Face model (downloads the GGUF + any mmproj-*.gguf for vision) |
n |
Rename the highlighted model's public alias (regenerates llama-swap + LiteLLM configs) |
c |
Configure the highlighted model: per-model context window (-c) |
P |
Toggle pin on the highlighted model — pins load the model into VRAM immediately; unpinning unloads it. inferhost checks VRAM first and warns if it won't fit. |
d / Delete |
Remove the highlighted model from the registry |
s |
Start llama-swap |
x |
Stop llama-swap |
r |
Restart llama-swap |
p |
Open the Settings panel (ports, context, GPU layers, flash attention) |
R |
Refresh |
q |
Quit |
The top of the dashboard shows two live status rows: a GPU bar (per-card
VRAM bar, used / total, utilization — via nvidia-smi, hidden on non-NVIDIA
boxes) and a status bar with the daemon dots, ports, the selected model's
active ctx, and which model llama-swap currently has resident in VRAM
(loaded: <name>). Both refresh every two seconds.
Adding a model
Press a, type a Hugging Face repo id (e.g. Qwen/Qwen2.5-7B-Instruct-GGUF), and press Enter. The TUI lists the available GGUF files, marks the recommended quant for your hardware, and shows a live progress bar while it downloads. The model is registered against llama-swap and ready to serve.
Pinning models (load into VRAM immediately)
Press P on a highlighted model to pin it. Pinning loads the model into VRAM right away — it does not wait for the next request. inferhost checks available VRAM before pinning; if the model won't fit, a modal appears asking you to unpin something else first. Press P again on a pinned model to unpin and unload it. The sidebar marks pinned models with a ★.
Renaming a model
The name shown in the model list is also the value clients send as the OpenAI
model field. Press n to change it. inferhost rewrites the llama-swap and
LiteLLM configs in one shot and, if llama-swap is running, restarts it so the new
alias is reachable immediately. No need to edit any YAML by hand.
Changing ports and other settings
Press p to open the Settings panel. You can edit swap_port, gateway_port,
default_ctx, gpu_layers, and flash_attention directly. Saving writes a
managed env file at ~/.config/inferhost/inferhost.env, so your changes persist
across restarts. Press r afterwards to restart llama-swap with the new values.
Endpoint
The single OpenAI-compatible endpoint is the LiteLLM gateway on port 9001:
curl http://localhost:9001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5-7b-instruct-q4-k-m",
"messages": [{"role": "user", "content": "Hello"}]
}'
Use the model name column from the dashboard as the model field.
Configuration
Every setting is overridable through environment variables or a .env file in the working directory. Copy .env.example for the full list.
| Variable | Default | Purpose |
|---|---|---|
INFERHOST_SWAP_PORT |
9090 |
llama-swap listen port (internal, loopback-only in v0.5+). |
INFERHOST_GATEWAY_PORT |
9001 |
LiteLLM gateway port — the user-facing OpenAI endpoint. |
INFERHOST_KV_QUANT_K |
q8_0 |
K cache type (-ctk). Keep at q8_0 or f16; turbo on K is discouraged. |
INFERHOST_KV_QUANT_V |
turbo3 |
V cache type (-ctv). Recommended: turbo4 (light) / turbo3 (default) / turbo2 (heavy). |
INFERHOST_LLAMA_SERVER_PATH |
(auto) | Path to a custom llama-server binary (Vulkan/ROCm/local builds). |
INFERHOST_DATA_DIR |
~/.local/share/inferhost |
Binaries, logs, and PID files. |
INFERHOST_CONFIG_DIR |
~/.config/inferhost |
Model registry and generated YAML. |
INFERHOST_HF_CACHE |
~/.cache/huggingface |
Hugging Face model cache. |
INFERHOST_GPU_LAYERS |
99 |
-ngl value passed to llama-server. |
INFERHOST_DEFAULT_CTX |
8192 |
Default context length for new models. |
INFERHOST_FLASH_ATTENTION |
on |
-fa flag for llama-server. |
INFERHOST_PARALLEL_SLOTS |
1 |
--parallel flag — concurrent request slots per llama-server instance. 1 = serial. |
INFERHOST_REASONING |
auto |
--reasoning flag — thinking mode for capable models. on, off, or auto. |
INFERHOST_REASONING_BUDGET |
-1 |
--reasoning-budget flag — token cap on thinking. -1 = unlimited, 0 = none. |
INFERHOST_LLAMACPP_BACKEND |
auto | Force a backend: vulkan, cuda, rocm, sycl, openvino, or cpu. |
INFERHOST_LLAMACPP_VERSION |
latest |
Pin a specific llama.cpp release tag. |
INFERHOST_LLAMASWAP_VERSION |
latest |
Pin a specific llama-swap release tag. |
INFERHOST_SPEC_DRAFT_N_MAX |
2 |
MTP draft tokens per step (only used on MTP-capable models). Set to 0 to disable the MTP lane. |
INFERHOST_SPEC_NGRAM_MOD_N_MATCH |
24 |
Minimum matching sequence length before ngram-mod drafts. |
INFERHOST_SPEC_NGRAM_MOD_N_MIN |
48 |
Minimum context window ngram-mod searches back through. |
INFERHOST_SPEC_NGRAM_MOD_N_MAX |
64 |
Max draft tokens ngram-mod proposes on a strong match. |
Architecture
Client inferhost
------ ---------
Your app --HTTP--> LiteLLM gateway llama-swap (loopback) llama-server
:9001 (public) ---> 127.0.0.1:9090 ---> (llama.cpp)
- llama.cpp runs the inference via a prebuilt TurboQuant-enabled
llama-server(Linux x86_64 CUDA, Linux x86_64 CPU, macOS arm64 Metal). - llama-swap sits in front of multiple llama-server instances and lazy-loads them on demand. It binds loopback (127.0.0.1) only.
- LiteLLM is the single user-facing gateway — always on, always bundled, serving
:9001.
Troubleshooting: If you try
curl http://<lan-ip>:9090/...and it fails, that is expected — llama-swap is loopback-only by design in v0.5+. Use the LiteLLM port:9001instead.
Development
The repo ships a run.sh wrapper for source-tree work:
git clone git@github.com:amirrouh/inferhost.git
cd inferhost
./run.sh install # creates venv, installs in editable mode
./run.sh start # launches the TUI (downloads binaries on first run)
./run.sh status # headless status print
./run.sh stop # stop daemons
./run.sh test # run pytest
Run ./run.sh help for the full list. End users do not need run.sh — they only ever type inferhost.
License
Apache 2.0
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file inferhost-0.5.0.tar.gz.
File metadata
- Download URL: inferhost-0.5.0.tar.gz
- Upload date:
- Size: 661.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
14b7247d3b863b00b5c4e0f03f5d972e48350ec3dae4d67862b60a91417092e0
|
|
| MD5 |
98767723c58dd0ac902e1b99806187ce
|
|
| BLAKE2b-256 |
636fa3581404961f27f4dcf9b5de6d634e78b92bfeb58b5ab84dc731022a4b3f
|
Provenance
The following attestation bundles were made for inferhost-0.5.0.tar.gz:
Publisher:
publish.yml on amirrouh/inferhost
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
inferhost-0.5.0.tar.gz -
Subject digest:
14b7247d3b863b00b5c4e0f03f5d972e48350ec3dae4d67862b60a91417092e0 - Sigstore transparency entry: 1615974260
- Sigstore integration time:
-
Permalink:
amirrouh/inferhost@b7aec3ee71f2a2e76d767a2f04d5ab9b3cb5ae37 -
Branch / Tag:
refs/tags/v0.5.0 - Owner: https://github.com/amirrouh
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b7aec3ee71f2a2e76d767a2f04d5ab9b3cb5ae37 -
Trigger Event:
push
-
Statement type:
File details
Details for the file inferhost-0.5.0-py3-none-any.whl.
File metadata
- Download URL: inferhost-0.5.0-py3-none-any.whl
- Upload date:
- Size: 57.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
29119983d0ec39b2ef50cbb4f76937f5656ffe83a47805629e9f13a02bd45654
|
|
| MD5 |
176a992bc7adb9e957fa8bf1bdf5bce0
|
|
| BLAKE2b-256 |
041626eb97498e248708923d9ae71cdf25425f3d3141f7b99f370f175b7b60cd
|
Provenance
The following attestation bundles were made for inferhost-0.5.0-py3-none-any.whl:
Publisher:
publish.yml on amirrouh/inferhost
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
inferhost-0.5.0-py3-none-any.whl -
Subject digest:
29119983d0ec39b2ef50cbb4f76937f5656ffe83a47805629e9f13a02bd45654 - Sigstore transparency entry: 1615974277
- Sigstore integration time:
-
Permalink:
amirrouh/inferhost@b7aec3ee71f2a2e76d767a2f04d5ab9b3cb5ae37 -
Branch / Tag:
refs/tags/v0.5.0 - Owner: https://github.com/amirrouh
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b7aec3ee71f2a2e76d767a2f04d5ab9b3cb5ae37 -
Trigger Event:
push
-
Statement type:







