InstaNovo enables diffusion-powered de novo peptide sequencing in large scale proteomics experiments
Project description

De novo peptide sequencing with InstaNovo




The official code repository for InstaNovo. This repo contains the code for training and inference of InstaNovo and InstaNovo+. InstaNovo is a transformer neural network with the ability to translate fragment ion peaks into the sequence of amino acids that make up the studied peptide(s). InstaNovo+, inspired by human intuition, is a multinomial diffusion model that further improves performance by iterative refinement of predicted sequences.
Publication in Nature Machine Intelligence: InstaNovo enables diffusion-powered de novo peptide sequencing in large-scale proteomics experiments
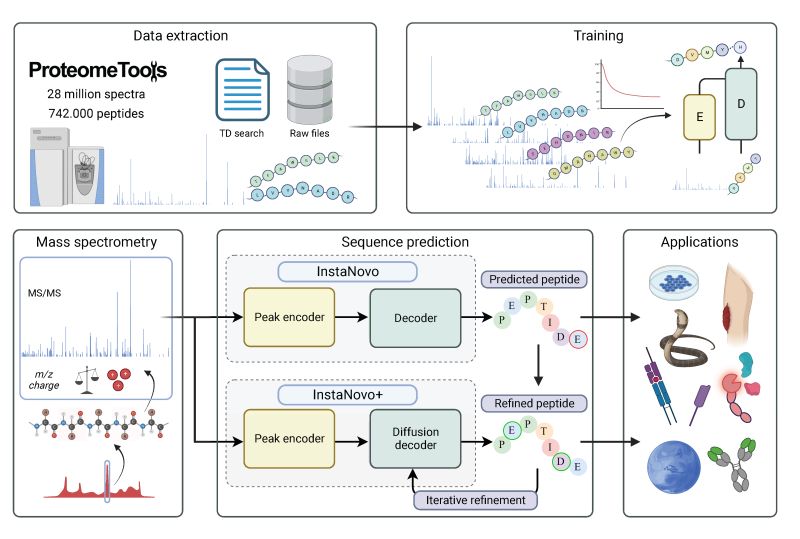
The full documentation is available at https://instadeepai.github.io/InstaNovo/ and consists of the following sections.
- Tutorials
- How to install InstaNovo, make your first prediction and evaluate InstaNovo's performance.
- An end-to-end starter notebook that you can run in Google Colab .
- How-to guides:
- How to perform predictions with InstaNovo with iterative refinement of InstaNovo+, or how to use each model separately.
- Guide for preparing your own data for use with InstaNovo and InstaNovo+.
- Details how to train your own InstaNovo and InstaNovo+ models.
- Reference:
- Overview of the
instanovocommand-line interface. - List of the supported post translational modifications.
- Description of the columns in the prediction output CSV
- Code reference API
- Overview of the
- Explanation:
- Explains our performance metrics and benchmarking results
- A detailed explanation of the
SpectrumDataFrameclass and its features.
- Blog:
- For Developers:
- How to set up a development environment.
- How to run the tests and lint the code.
- View the test coverage and test report.
- How to Cite:
- Bibtex references for our peer-reviewed publication on InstaNovo and InstaNovo+ and our preprints on InstaNovo-P, InstaNexus and Winnow.
- License:
- Code is licensed under the Apache License, Version 2.0
- The model checkpoints are licensed under Creative Commons Non-Commercial (CC BY-NC-SA 4.0)
Developed by:
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file instanovo-1.2.2.tar.gz.
File metadata
- Download URL: instanovo-1.2.2.tar.gz
- Upload date:
- Size: 133.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
65b42a46e4d61ddb8a77d3e433e815019696dc839cf45de8afd0c95ae3c0f598
|
|
| MD5 |
1e3e7bcf7ecf953e8a1e1e54cb251d2e
|
|
| BLAKE2b-256 |
3d5b53228054f35a70c4baeda8a7dff4e41dec02759d2eaafaf4b27423cf4fc3
|
File details
Details for the file instanovo-1.2.2-py3-none-any.whl.
File metadata
- Download URL: instanovo-1.2.2-py3-none-any.whl
- Upload date:
- Size: 164.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e951a05da7481cce281f1891ed03ad8cbb38e779bf9896adbcb11454f3ed2ec1
|
|
| MD5 |
0966082e504817aa8cf0790fd3e51e9d
|
|
| BLAKE2b-256 |
bb424c4005d5550c6ad728e65dc1ae3f8f42b7301f9e827345de2b7154d1f093
|







