Interactive EDA visualizations in your jupyter notebook

Project description
intedact: Interactive EDA


Interactive EDA for pandas DataFrames directly in your Jupyter notebook. intedact makes common, standardized EDA visual summaries available in an interactive manner with one function call. Using ipywidgets, you can quickly cycle through different variables or combinations of variables and produce useful visual summaries when exploring the dataset. Each summary will have additional plot parameters you can tweak to adjust the visualizations to work for your dataset.
Full documentation at intedact.readthedocs.io
Getting Started
Installation
Install via pip:
pip install intedact
Download the following nltk resources for the ngram text summaries.
import nltk
nltk.download('punkt')
nltk.download('stopwords')
Univariate EDA
Univariate EDA refers to the process of visualizing and summarizing a single variable.
For interactive univariate EDA simply import the univariate_eda_interact function in a jupyter notebook and pass in a pandas dataframe:
from intedact import univariate_eda_interact
univarate_eda_interact(
data, notes_file="optional_file_to_save_notes_to.json"
)
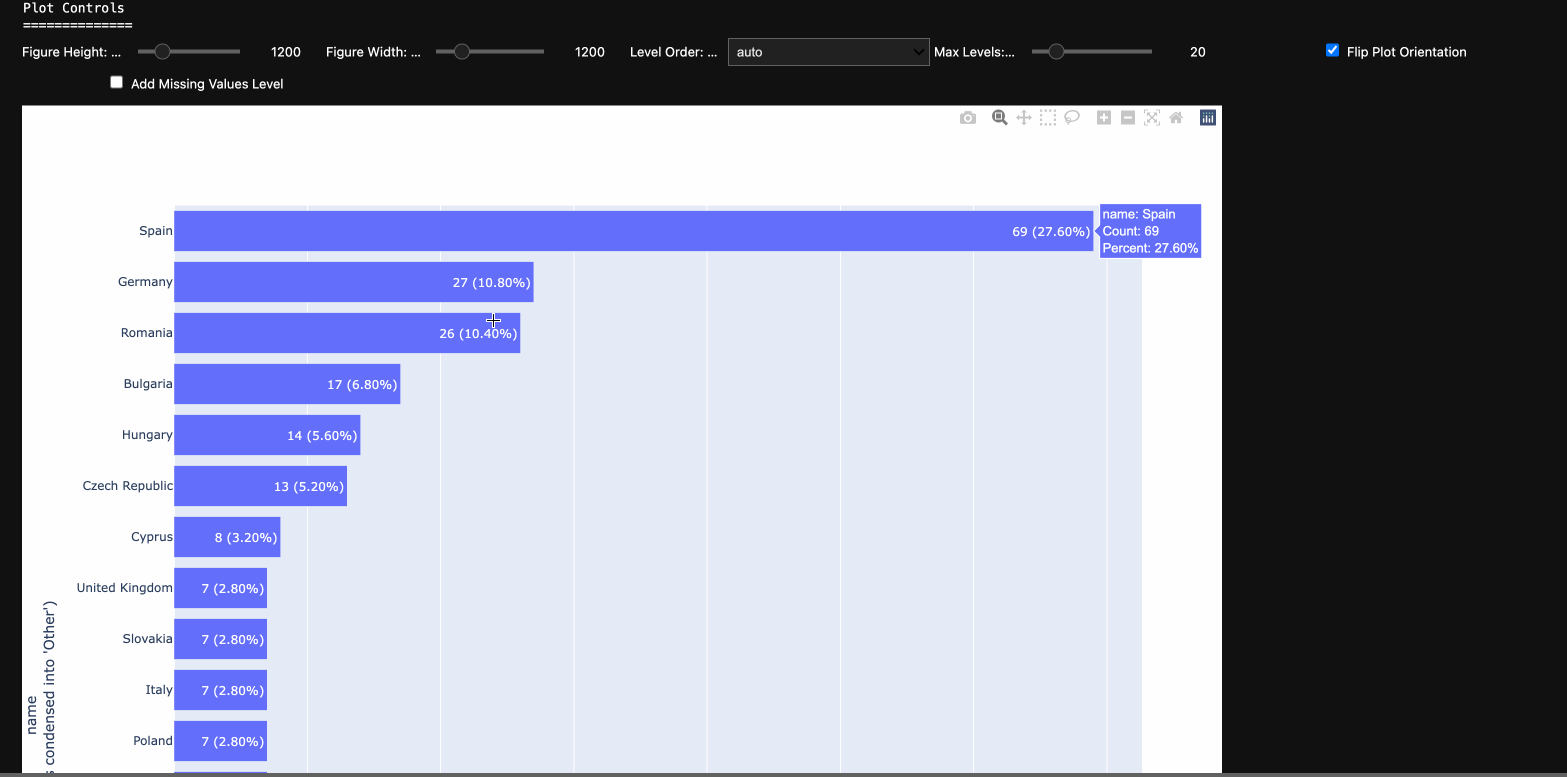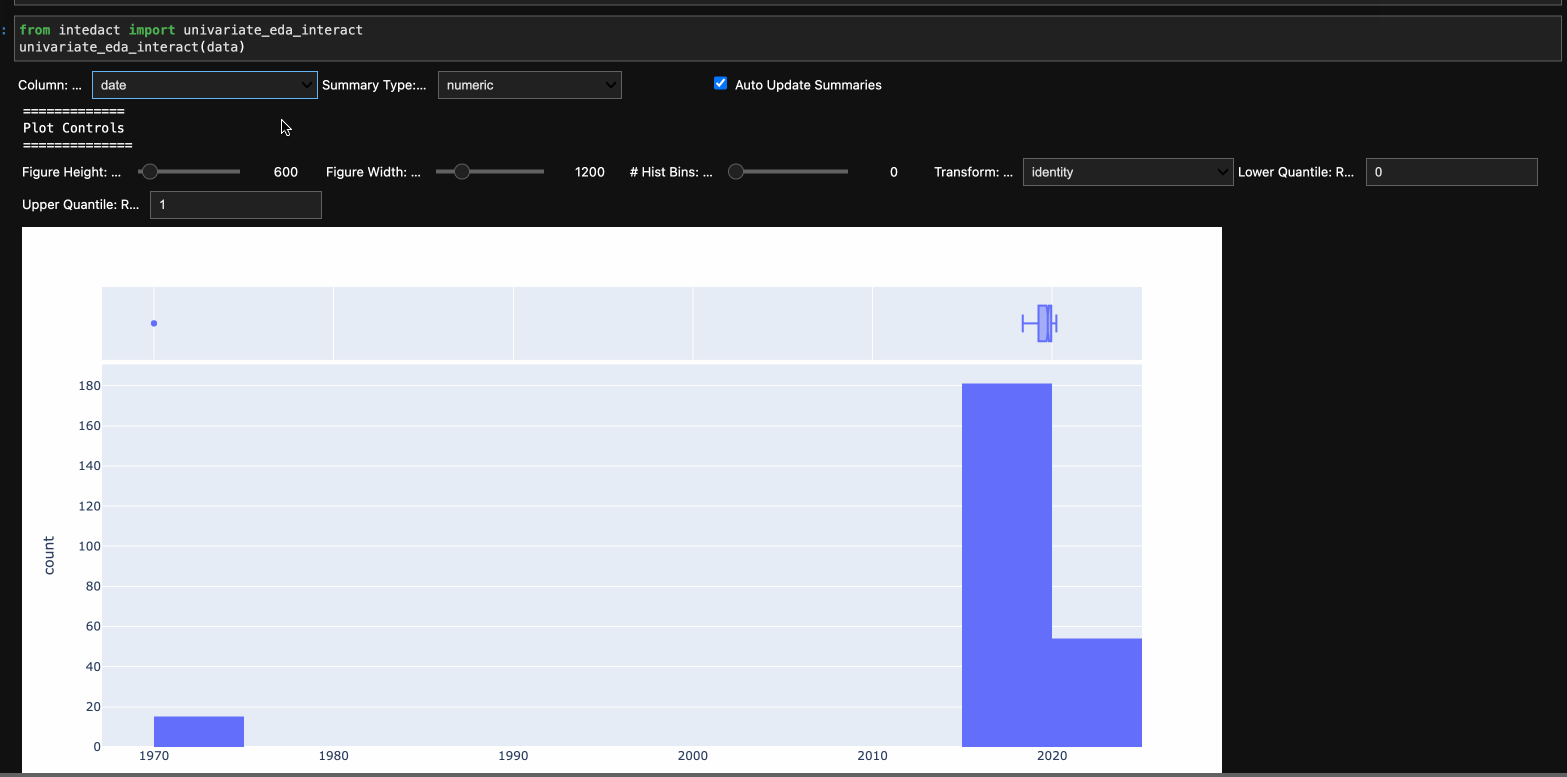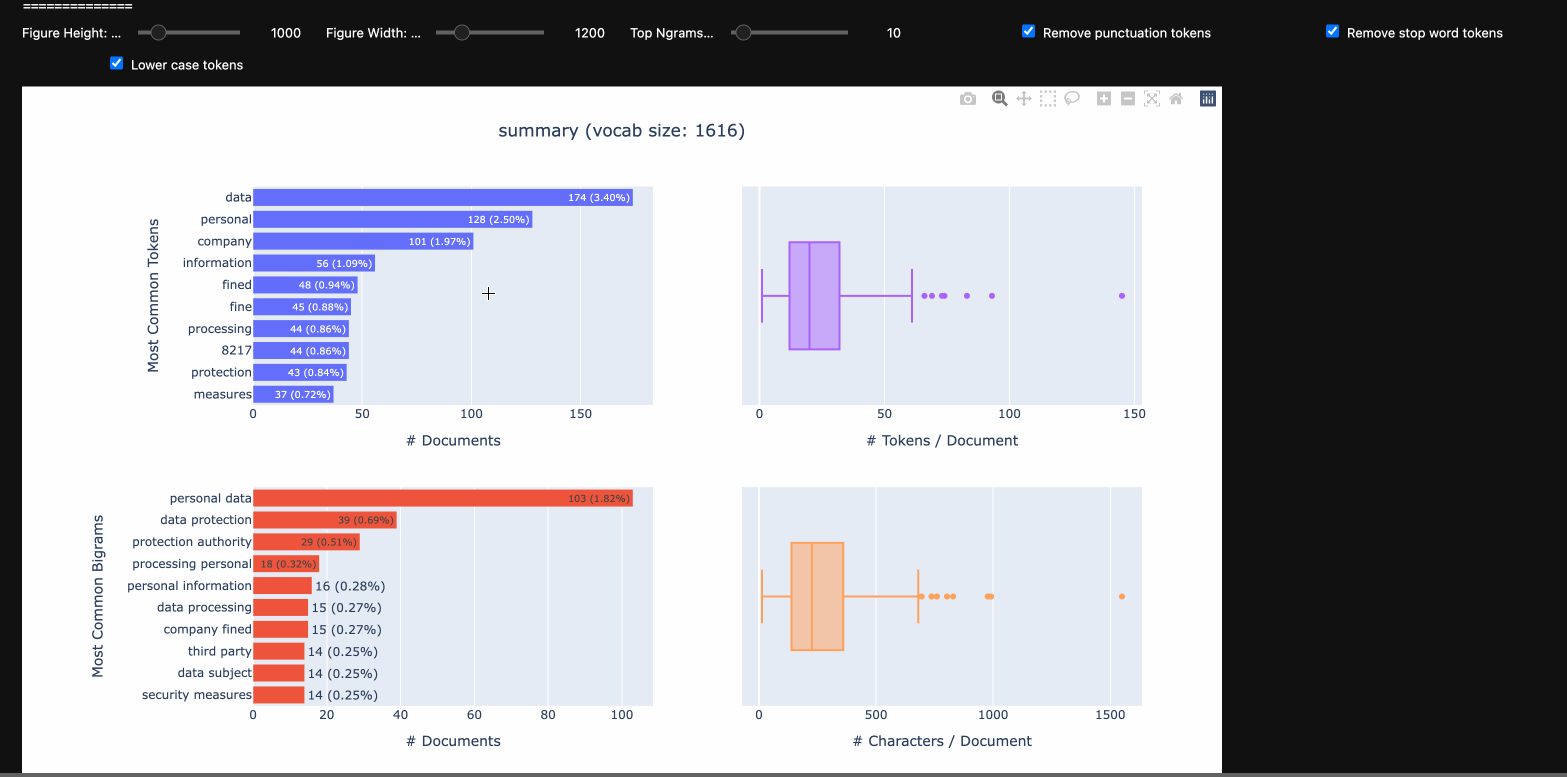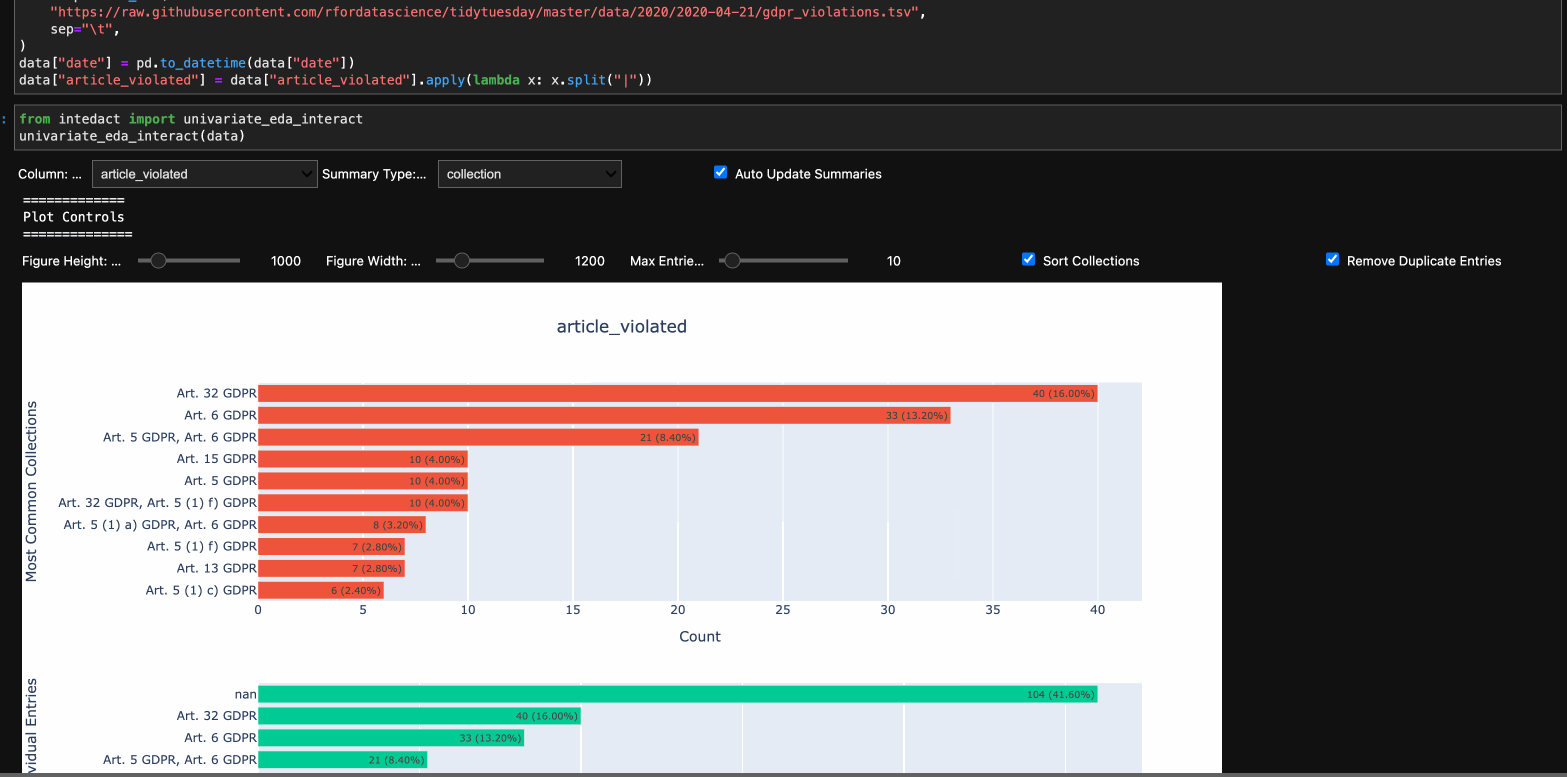
At the top level, one selects the column and the summary type for that column to display. To explore the full dataset, just toggle through each of the column names. Current supported summary types:
- categorical: Summarize a categorical or low cardinality numerical column
- numeric: Summarize a high cardinality numerical column
- datetime: Summarize a datetime column
- text: Summarize a free form text column
- collection: Summarize a column with collections of values (i.e. lists, tuples, sets, etc.)
- url: Summarize a column containing urls
For each column, one can then adjust parameters for the given summary type to fit your particular dataset. These summaries try to automatically set good default parameters, but sometimes you need to make adjustments to get the full picture.
See the documentation for examples of how to statically call the individual univariate summary functions.
Bivariate EDA
Bivariate EDA refers to the process of visualizing and summarizing a pair of variables.
Like with univariate EDA, simply import the bivariate_eda_interact function in a jupyter notebook and pass in a dataframe:
from intedact import bivariate_eda_interact
bivarate_eda_interact(
data, notes_file="optional_file_to_save_notes_to.json"
)
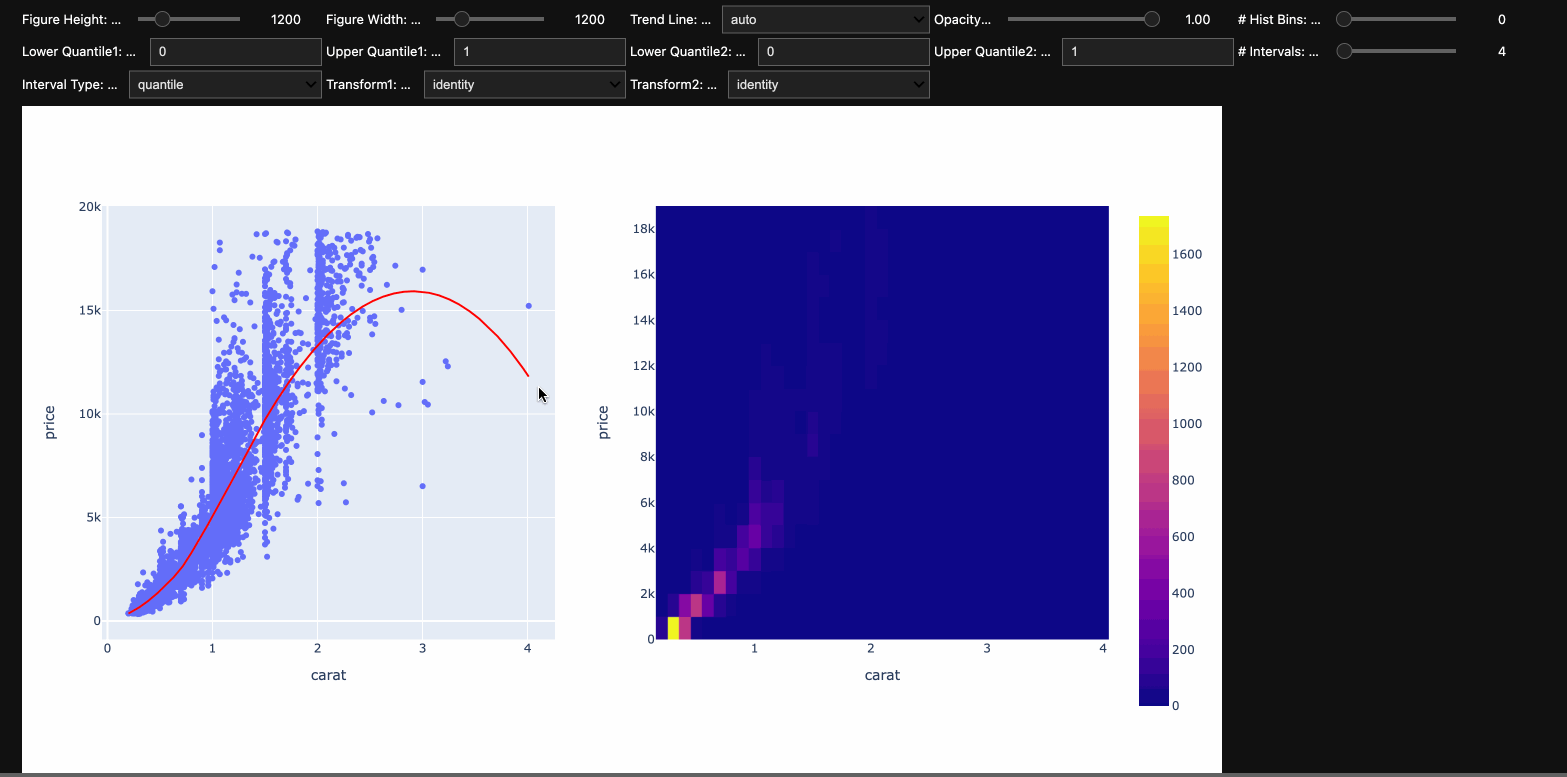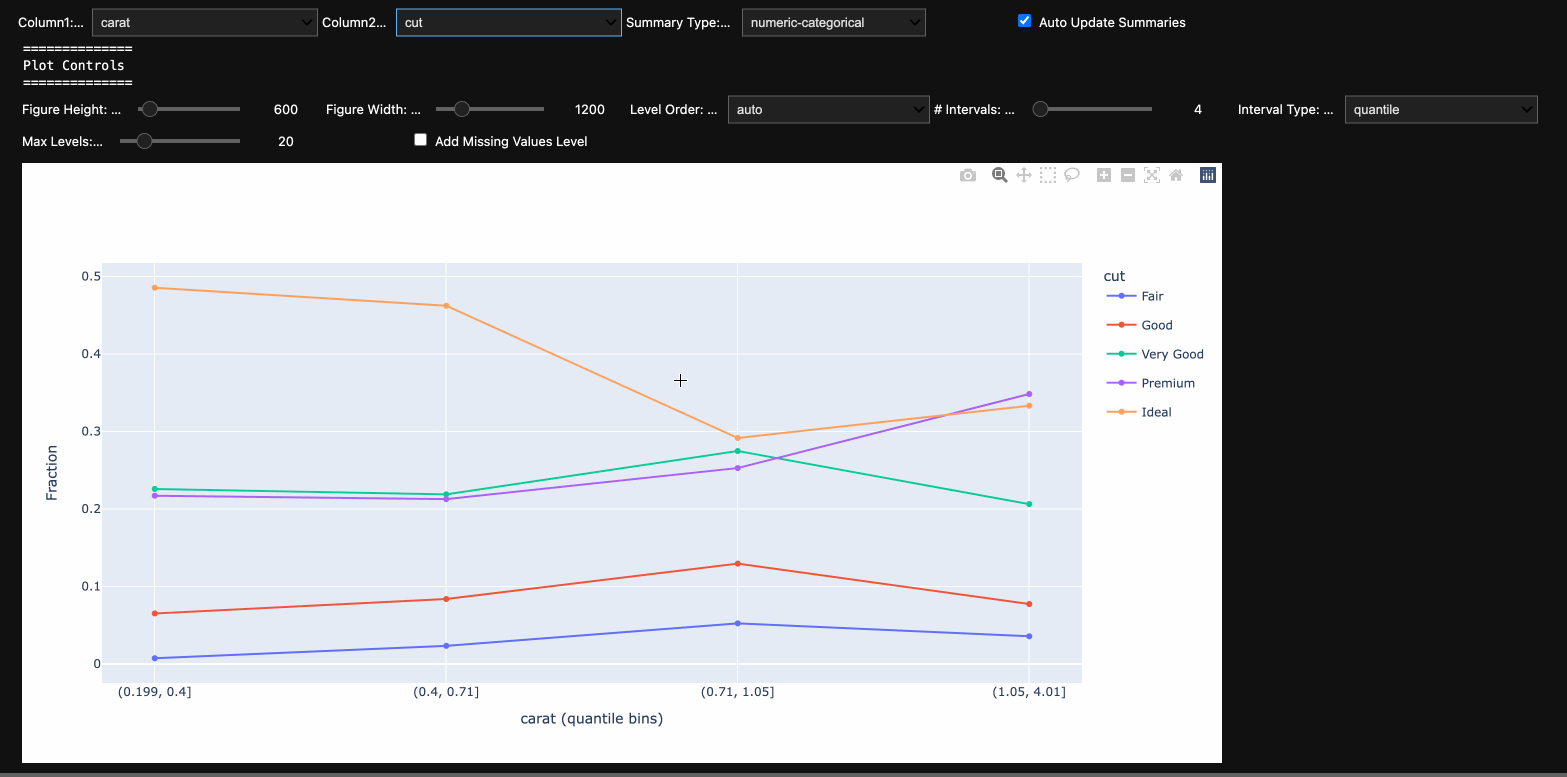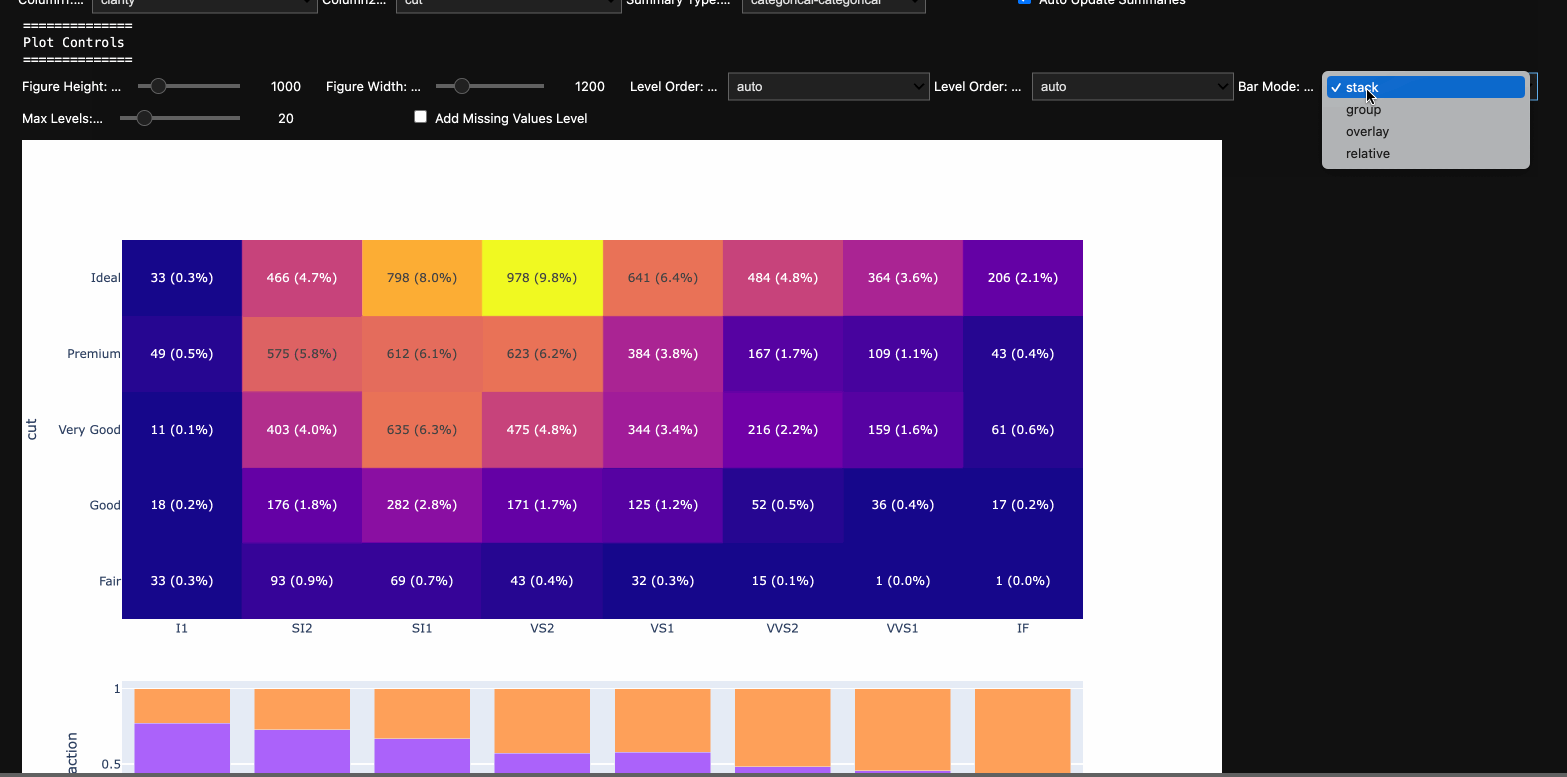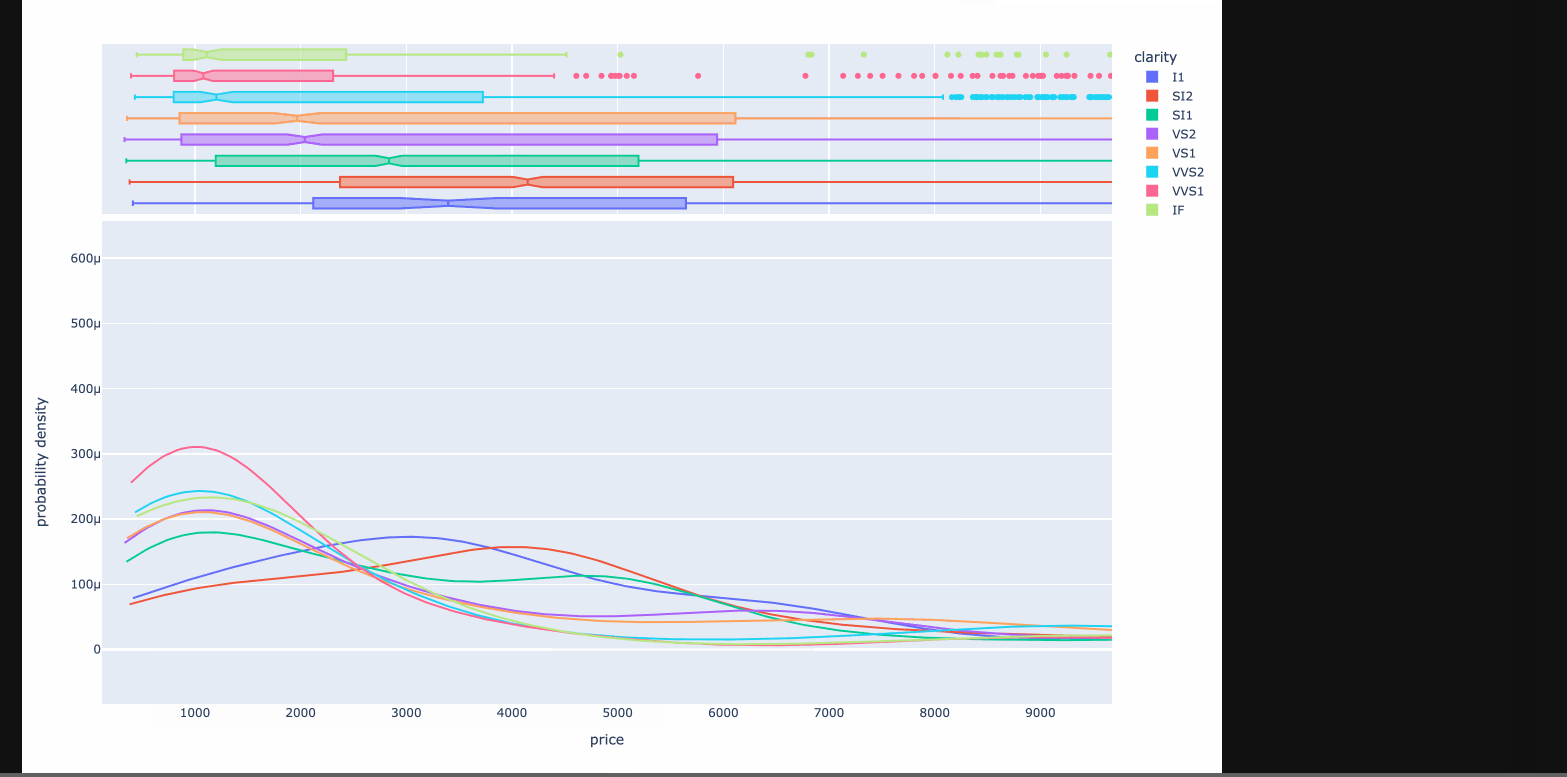
At the top level, one selects a pair of columns to display (one as the independent and the second as the dependent). Current supported summary types:
- categorical-categorical: Summarize a pair of categorical columns
- numeric-categorical: Summarize an independent numeric variable against a dependent categorical variable
- categorical-numeric: Summarize an independent categorical variable against a dependent numeric variable
- numeric-numeric: Summarize a pair of numeric columns
Design Philosophy
The motivation for intedact comes from the following observations:
- There is a standard set of visualizations that should be always applied to different individual and combinations of variables depending on their type when performing EDA. For example, it is always good to visualize the distribution of a numerical variable using a histogram. intedact's goal is to save you from having to constantly copy-paste this code across columns, projects, etc.
- These visualizations often need some degree of adjustment to get the information you need. For example, really skewed variables with outliers might need some outlier filtering and/or a log transform to actually be able to visualize the histogram properly. intedact's goal is to give you additional control over the visualization with interactive widgets that you can repeatedly adjust until you get the visualization you need.
Given the above, intedact tries to produce visualizations that give you the visual understanding you are seeking for 95% of cases when you pass in the defaults. For the other 5%, we give you additional parameters you can tweak via the widgets so you can still get the insights you need without having to leave the interface.
intedact is not a single click EDA summary generation tool. Many of those exist and we recommend pairing them with intedact (pandas-profiling is a great one for example). Where these fall short, is they don't focus on the visualizations and give you the power to adjust them to your dataset when the defaults don't suffice. Use intedact when you want to dig deeper and really visually understand a variable or the relationship between variable(s).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file intedact-0.1.0.tar.gz.
File metadata
- Download URL: intedact-0.1.0.tar.gz
- Upload date:
- Size: 22.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0e4673ec901662dcf77898934d8d2c67a41a282a03cf7b33b26b5a9ebec9cf63
|
|
| MD5 |
48e8104c7e4c08b02bdc16a657a2d2d8
|
|
| BLAKE2b-256 |
44cc9016e44708e9c147bf76d0d4e93dcbb4111da4eeaf3c1c41cd78b5942709
|
File details
Details for the file intedact-0.1.0-py3-none-any.whl.
File metadata
- Download URL: intedact-0.1.0-py3-none-any.whl
- Upload date:
- Size: 25.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bbf21333c8c223e9286202021ae6ab96e96ff07ee0d94289ab554fb609550841
|
|
| MD5 |
3df7ef432086dc6c7dc58c268f2ab2d5
|
|
| BLAKE2b-256 |
a13d726175ec618bebab339394bd405d9ef71e6100070253c77290e1444cd132
|







