Core library powering a GUI providing an audio interface to GPT3.

Project description

Jabberwocky
Video demo: https://user-images.githubusercontent.com/40480855/132139847-0d0014b9-022e-4684-80bf-d46031ca4763.mp4
This was not really designed to be used as a standalone library - it was mostly used as a convenient way to structure and import code in other parts of the project. Some components may be reusable for other projects combining GPT-3 with audio, however.
Project Description
This is the core library powering a GUI that provides an audio interface to GPT-3. My main goal was to provide a convenient way to interact with various experts or public figures: imagine discussing physics with Einstein or hip hop with Kanye (or hip hop with Einstein? 🤔). I often find writing and speaking to be wildly different experiences and I imagined the same would be true when interacting with GPT-3. This turned out to be partially true - the default Mac text-to-speech functionality I'm using here is certainly not as lifelike as I'd like. Perhaps more powerful audio generation methods will pop up in a future release...
We also provide Task Mode containing built-in prompts for a number of sample tasks:
- Summarization
- Explain like I'm 5
- Translation
- How To (step by step instructions for performing everyday tasks)
- Writing Style Analysis
- Explain machine learning concepts in simple language
- Generate ML paper abstracts
- MMA Fight Analysis and Prediction
Getting Started
- Clone the repo.
git clone https://github.com/hdmamin/jabberwocky.git
- Install the necessary packages. I recommend using a virtual environment of some kind (virtualenv, conda, etc). If you're not using Mac OS, you could try installing portaudio with whatever package manager you're using, but app behavior on other systems is unknown.
brew install portaudio
pip install -r requirements.txt
python -m nltk.downloader punkt
If you have make installed you can simply use the command:
make install
- Add your openai API key somewhere the program can access it. There are two ways to do this:
echo your_openai_api_key > ~/.openai
or
export OPENAI_API_KEY=your_openai_api_key
(Make sure to use your actual key, not the literal text your_openai_api_key.)
- Run the app.
python gui/main.py
Or with make:
make run
Usage
Conversation Mode
In conversation mode, you can chat with a number of pre-defined personas or add new ones. New personas can be autogenerated or defined manually.
See data/conversation_personas for examples of autogenerated prompts. You can likely achieve better results using custom prompts though.
Conversation mode only supports spoken input, though you can edit flawed transcriptions manually. Querying GPT-3 with nonsensical or ungrammatical text will negatively affect response quality.
Task Mode
In task mode, you can ask GPT-3 to perform a number pre-defined tasks. Written and spoken input are both supported. By default, GPT-3's response is both typed out and read aloud.
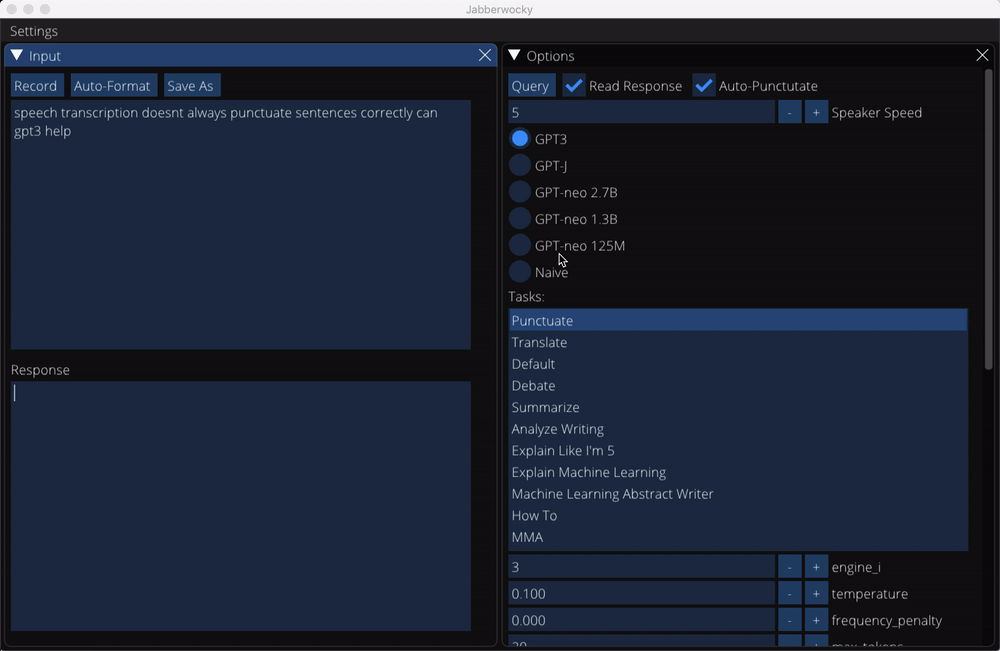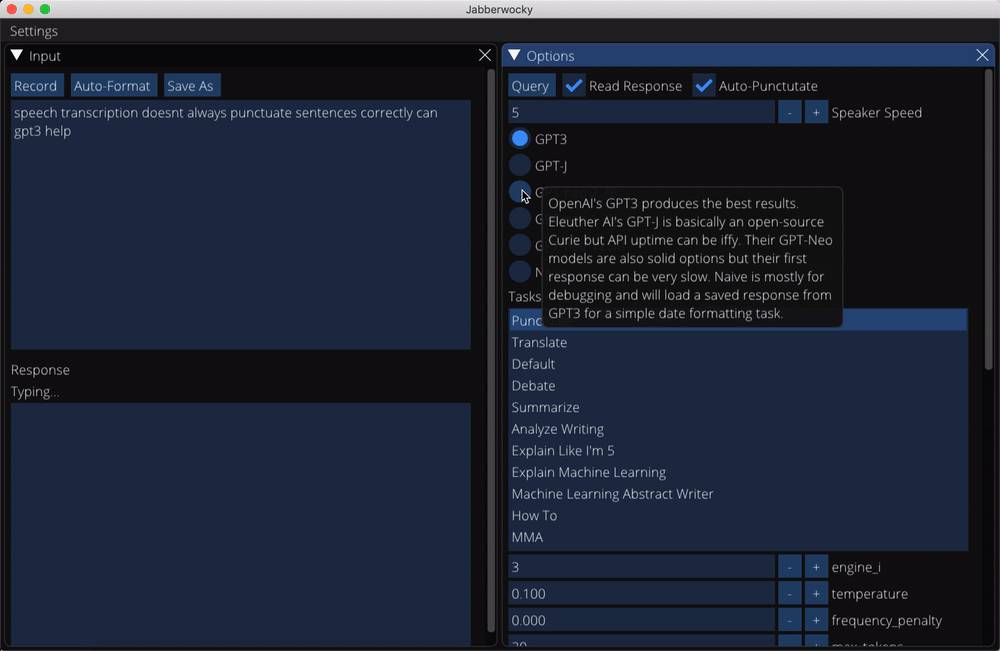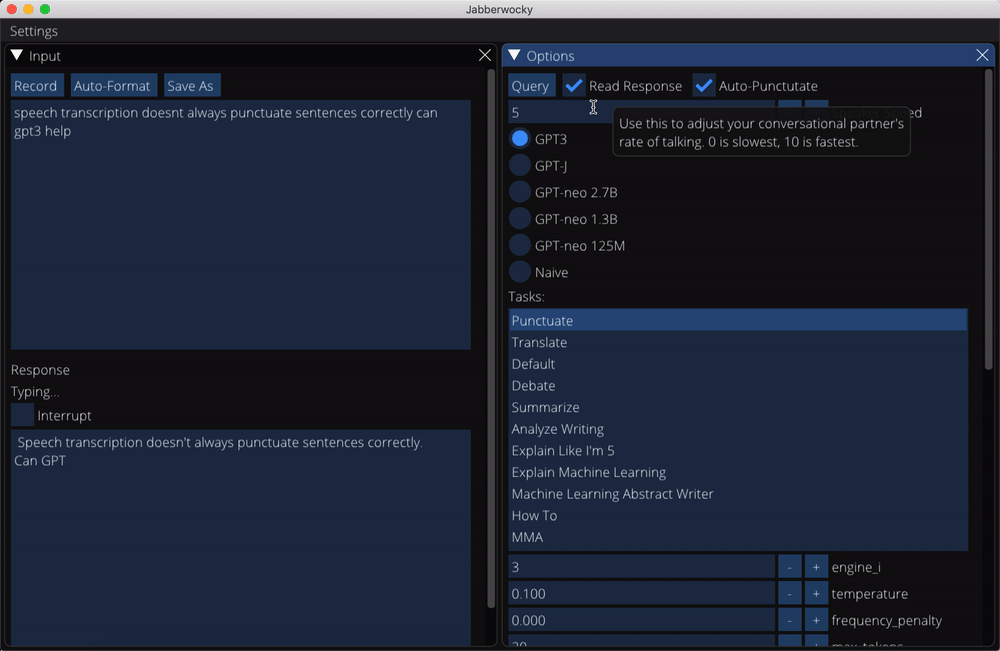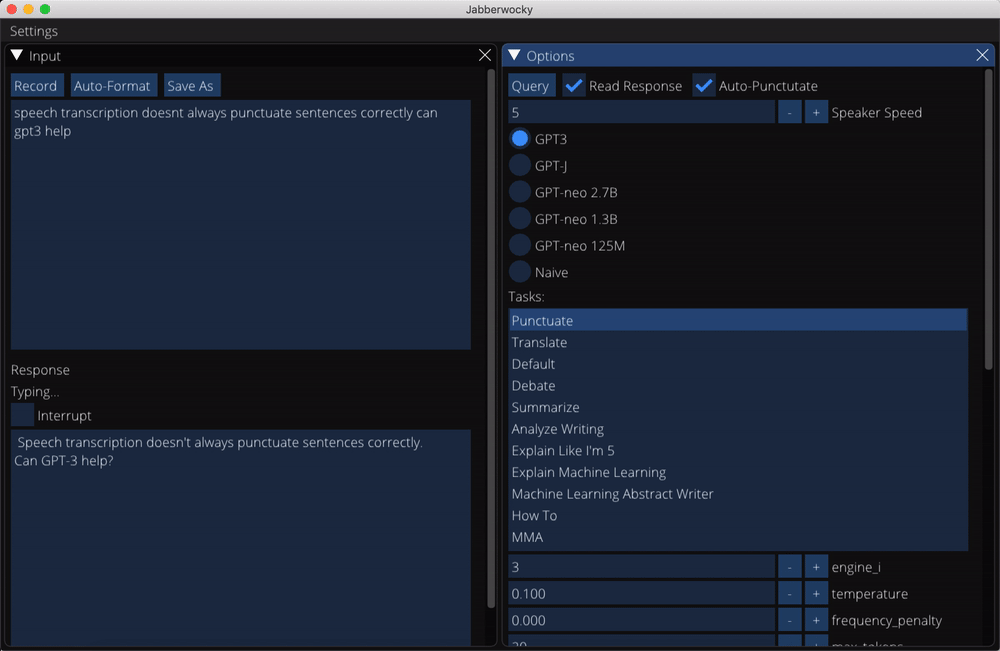
Transcripts of responses from a small subset of non-conversation tasks can be found in the data/completions directory. You can also save your own completions while using the app.
Usage Notes
The first time you speak, the speech transcription back end will take a few seconds to calibrate to the level of ambient noise in your environment. You will know it's ready for transcription when you see a "Listening..." message appear below the Record button. Calibration only occurs once to save time.
Hotkeys
CTRL + SHIFT: Start recording audio (same as pressing the "Record" button).
CTRL + a: Get GPT-3's response to whatever input you've recorded (same as pressing the "Get Response" button).
Project Members
- Harrison Mamin
Repo Structure
jabberwocky/
├── data # Raw and processed data. Some files are excluded from github but the ones needed to run the app are there.
├── notes # Miscellaneous notes from the development process stored as raw text files.
├── notebooks # Jupyter notebooks for experimentation and exploratory analysis.
├── reports # Markdown reports (performance reports, blog posts, etc.)
├── gui # GUI scripts. The main script should be run from the project root directory.
└── lib # Python package. Code can be imported in analysis notebooks, py scripts, etc.
Start of auto-generated file data.
Last updated: 2022-07-24 14:12:52
| File | Summary | Line Count | Last Modified | Size |
|---|---|---|---|---|
| __init__.py | _ | 1 | 2022-07-23 20:30:48 | 22.00 b |
| cli.py | At the moment, the only useful part of this is the `update_prompt_readme` command which updates the readme in data/prompts to make it easier to review what prompts are currently available. The chat functionality was a brief experiment with an old version of Jabberwocky and no longer reflects the current API. I'm keeping it around for future reference since I'm still interested in combining prompt_toolkit with jabberwocky and it may be useful to see my old thoughts on implementation (or at the very least, serve as a sort of API reference about the prompt_toolkit features I care about). |
108 | 2022-06-25 11:08:06 | 3.71 kb |
| config.py | Define constants used throughout the project. | 72 | 2022-07-07 20:05:07 | 2.49 kb |
| core.py | Core functionality that ties together multiple APIs. | 612 | 2022-04-22 21:46:52 | 24.36 kb |
| external_data.py | Functionality to fetch and work with YouTube transcripts and Wikipedia data. | 426 | 2022-07-14 20:35:09 | 15.56 kb |
| openai_utils.py | Utility functions for interacting with the gpt3 api. A note on query functions: There are a number of different services (both paid and free) that provide access to GPT-like models. GPTBackend.query() provides a convenient interface to them by calling different query functions under the hood. These query functions are all defined in this module and have names starting with 'query_gpt'. There are a number of steps to defining a new query function: 1. Use the `mark` decorator to set "batch_support" to either True or False. True means you can pass in a list of prompts, False means the prompt must be a single string. GPTBackend will support batching either way, but it needs to know whether each query function supports this natively in order to determine how to do this. 2. The first parameter should be 'prompt' with no default. The other parameters should have defaults, but keep in mind many of these will be ignored when called by GPTBackend.query - the latter has its own defaults which are passed in as kwargs. Speaking of which... 3. It must accept kwargs. 4. If it supports multiple completions, include a parameter "n" with a default value of 1 in the signature. GPTBackend.query will support it either way, but again it needs to know how to achieve this. 5. If multiple engines are available through this backend, update jabberwocky.config.C.backend_engines, using the other examples as guidance. In addition, in this scenario we recommend retrieving the engine name explicitly as query_gpt_huggingface does: ```engine = GPTBackend.engine(engine, backend='huggingface')``` rather than simply calling ```GPTBackend.engine(engine)```. 6. We recommend popping off kwargs that you actually do want to use and then providing a warning so the user can see the remaining unused kwargs if there are any. 7. The fuction should either return a (str, dict-like) tuple or (list[str], list[dict-like]). Use the latter if batch_support is True and multiple completions per prompt are supported (i.e. n is in its parameters). Technically I suppose there could be a backend that supported 1 but not the other, but I haven't seen it yet so I'll figure that case out if/when needed. 8. When done, update some or all of the following GPTBackend class attributes. - name2base - name2func - skip_trunc Use the comments and examples in the class as guidance. |
3090 | 2022-07-19 19:43:49 | 130.72 kb |
| speech.py | Module to help us interact with mac's speech command. This lets the GUI read responses out loud. |
117 | 2021-08-20 21:05:11 | 4.16 kb |
| streaming.py | Functionality to support streaming gpt responses, both from backends that natively support it like openai and those that don't. This handles things like updating prompt_index in each streamed response dict so we can more easily tell which prompt a token belongs to, truncating before stop words for backends that don't (only openai supports this natively), and updating finish_reason when we find stop words. Note: if adding a streaming function for a new backend, make sure to register it so it ends up in BACKEND2STREAMER (see _stream_openai_generator for an example). Each function must accept a first param which is the result of calling GPT.query(prompt, stream=True) while using the desired backend. It must also accept **kwargs. Be careful when changing param names - they must match the stream_response() call in jabberwocky.openai_utils.GPTBackend._query(). |
575 | 2022-05-09 20:53:51 | 23.75 kb |
| utils.py | General purpose utilities. | 699 | 2022-07-19 18:57:35 | 23.36 kb |
End of auto-generated file data. Do not add anything below this.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file jabberwocky-2.5.0.tar.gz.
File metadata
- Download URL: jabberwocky-2.5.0.tar.gz
- Upload date:
- Size: 79.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.26.0 setuptools/60.10.0 requests-toolbelt/0.9.1 tqdm/4.64.0 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d6308ad0c455712c6032504e968798a1782f746a4ed21bf42519b5712a205d6a
|
|
| MD5 |
9b5b400a94ca4d6ad005ecd078d1adcd
|
|
| BLAKE2b-256 |
00a00cd6f4851094b6f6452fefefc49ed30ccfc89fd1def85922263ea03ef660
|







