A set of python modules for anomaly detection

Project description











kenchi
This is a scikit-learn compatible library for anomaly detection.
Dependencies
- Required dependencies
numpy>=1.13.3 (BSD 3-Clause License)
scikit-learn>=0.20.0 (BSD 3-Clause License)
scipy>=0.19.1 (BSD 3-Clause License)
- Optional dependencies
matplotlib>=2.1.2 (PSF-based License)
networkx>=2.2 (BSD 3-Clause License)
Installation
You can install via pip
pip install kenchi
or conda.
conda install -c y_ohr_n kenchi
Algorithms
Examples
import matplotlib.pyplot as plt
import numpy as np
from kenchi.datasets import load_pima
from kenchi.outlier_detection import *
from kenchi.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
np.random.seed(0)
scaler = StandardScaler()
detectors = [
FastABOD(novelty=True, n_jobs=-1), OCSVM(),
MiniBatchKMeans(), LOF(novelty=True, n_jobs=-1),
KNN(novelty=True, n_jobs=-1), IForest(n_jobs=-1),
PCA(), KDE()
]
# Load the Pima Indians diabetes dataset.
X, y = load_pima(return_X_y=True)
X_train, X_test, _, y_test = train_test_split(X, y)
# Get the current Axes instance
ax = plt.gca()
for det in detectors:
# Fit the model according to the given training data
pipeline = make_pipeline(scaler, det).fit(X_train)
# Plot the Receiver Operating Characteristic (ROC) curve
pipeline.plot_roc_curve(X_test, y_test, ax=ax)
# Display the figure
plt.show()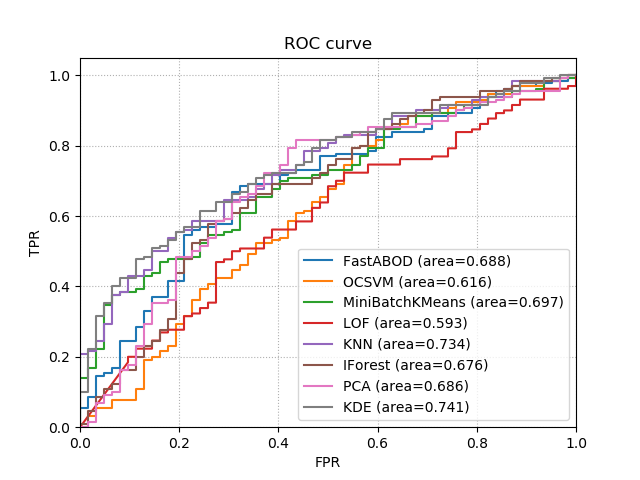
References
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
No source distribution files available for this release.See tutorial on generating distribution archives.
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
kenchi-0.10.0-py3-none-any.whl
(384.9 kB
view details)
File details
Details for the file kenchi-0.10.0-py3-none-any.whl.
File metadata
- Download URL: kenchi-0.10.0-py3-none-any.whl
- Upload date:
- Size: 384.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.18.4 setuptools/39.1.0 requests-toolbelt/0.8.0 tqdm/4.26.0 CPython/3.6.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1bab6781e9987bfb64c1ed50991c70cd289af9932f9bcc079455f0c62e8a6aa7
|
|
| MD5 |
2166cfea6b7d871e1e995194d64c43b6
|
|
| BLAKE2b-256 |
da00f791c807f778521ee8206994a5fa9b6d4e683f032afc1be1b6a44d4745f7
|







