Kesh Utils for Data science/EDA/Data preparation

Project description
Chart + Util = Chartil (Click to expand)
Chart + Util = Chartil
Data visualization: Simple, Single unified API for plotting and charting
During EDA/data preparation we use few common and fixed set of chart types to analyse the relation among various features. Few are simple charts like univariate and some are complex 3D or even multiple features>3.
This api is simple, single api to plot various type of relations which will hide all the technical/code details from Data Science task and approch. This overcomes the difficulties of maintaining several api or libraries and avoid repeated codes.
Using this approach we just need one api (Rest all decided by library)
from KUtils.eda import chartil
chartil.plot(dataframe, [list of columns]) or
chartil.plot(dataframe, [list of columns], {optional_settings})
Demo code:
Load UCI Dataset. Download From here
heart_disease_df = pd.read_csv('../input/uci/heart.csv')
Quick data preparation
column_to_convert_to_categorical = ['target', 'cp', 'fbs', 'exang', 'restecg', 'slope', 'ca', 'thal']
for col in column_to_convert_to_categorical:
heart_disease_df[col] = heart_disease_df[col].astype('category')
heart_disease_df['age_bin'] = pd.cut(heart_disease_df['age'], [0, 32, 40, 50, 60, 70, 100], labels=['<32', '33-40','41-50','51-60','61-70', '71+'])
heart_disease_df['sex'] = heart_disease_df['sex'].map({1:'Male', 0:'Female'})
heart_disease_df.info()
Heatmap
chartil.plot(heart_disease_df, heart_disease_df.columns) # Send all column names
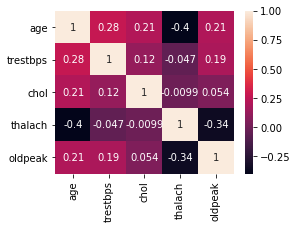
chartil.plot(heart_disease_df, heart_disease_df.columns, optional_settings={'include_categorical':True} )
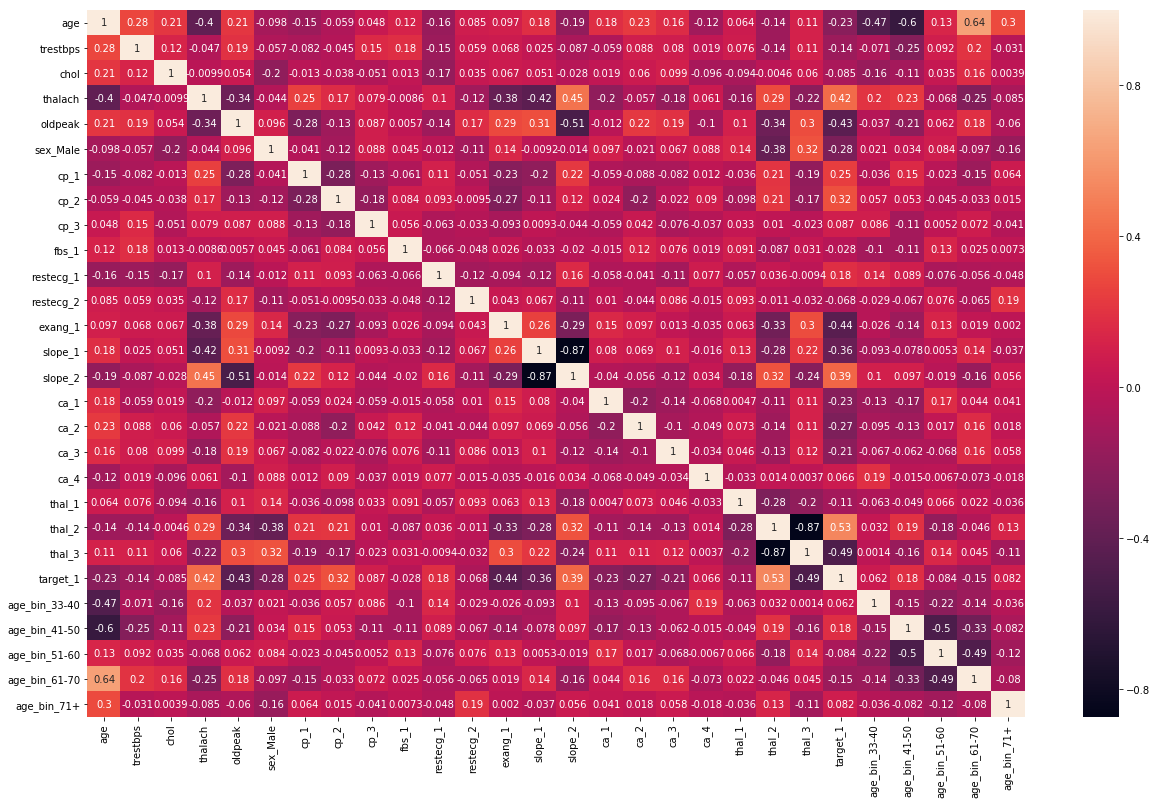
chartil.plot(heart_disease_df, heart_disease_df.columns, optional_settings={'include_categorical':True, 'sort_by_column':'trestbps'} )
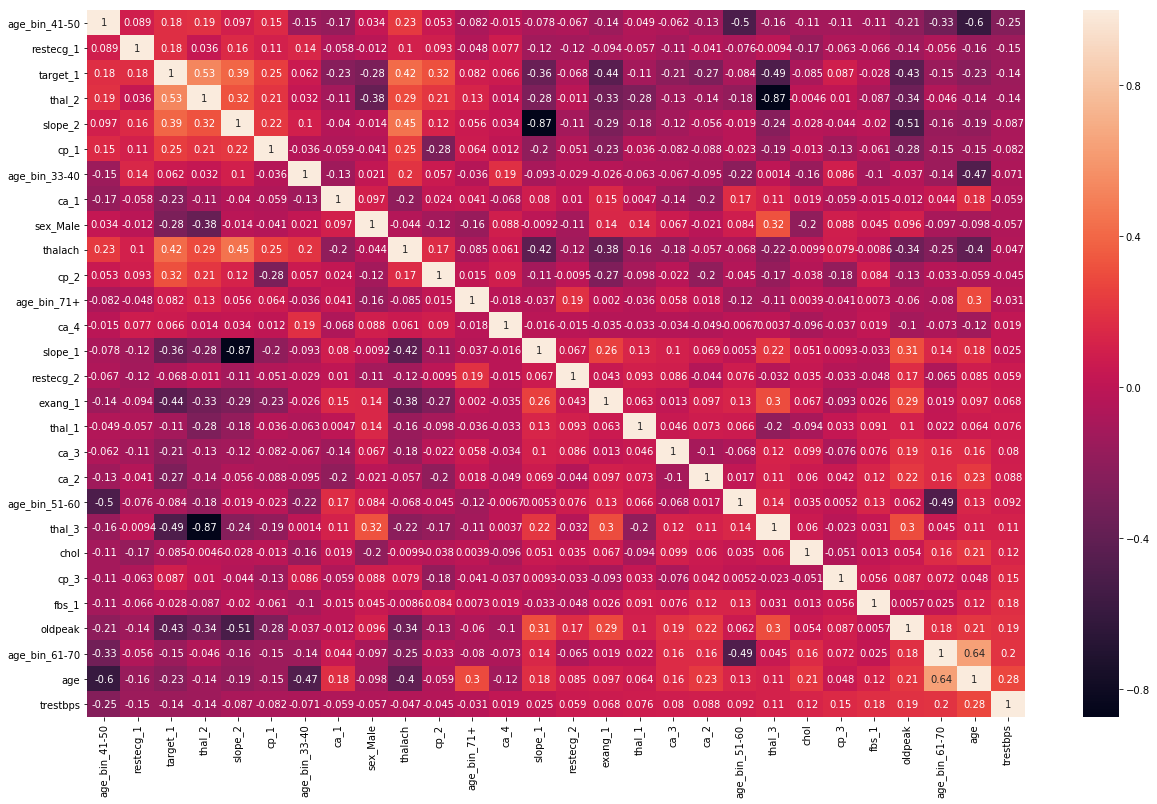
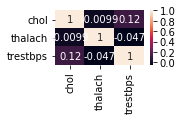
# Force to plot heatmap when you have fewer columns, otherwise tool will decide as different chart
chartil.plot(heart_disease_df, ['chol', 'thalach', 'trestbps'], chart_type='heatmap')
Uni-categorical
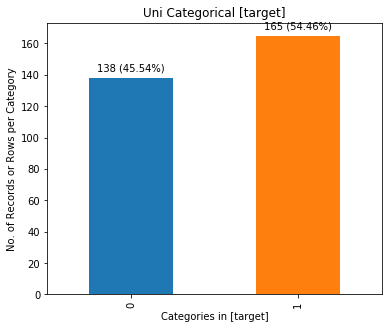
chartil.plot(heart_disease_df, ['target']) # Barchart as count plot
Uni-Continuous
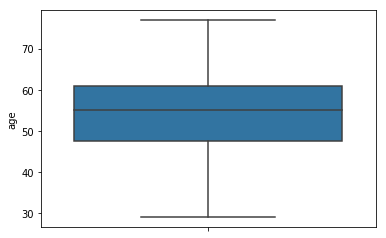
chartil.plot(heart_disease_df, ['age'])
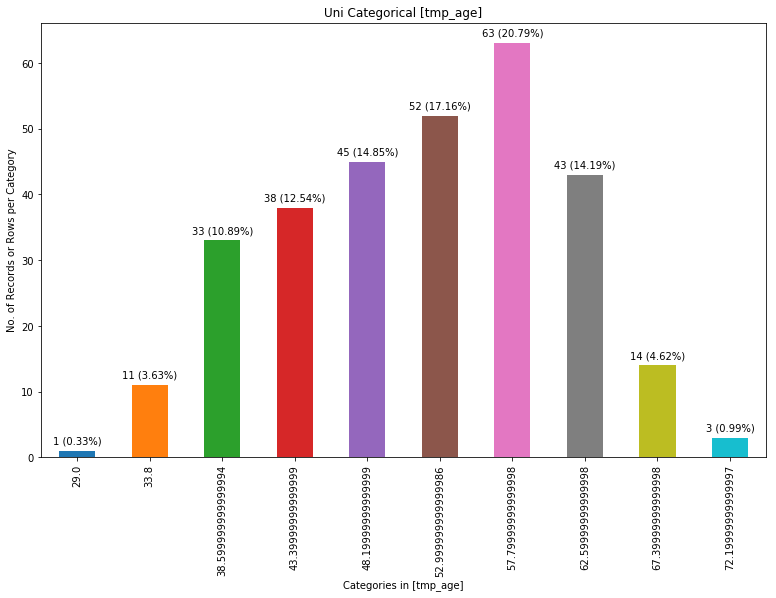
chartil.plot(heart_disease_df, ['age'], chart_type='barchart') # Force barchart on cntinuous by auto creating 10 equal bins
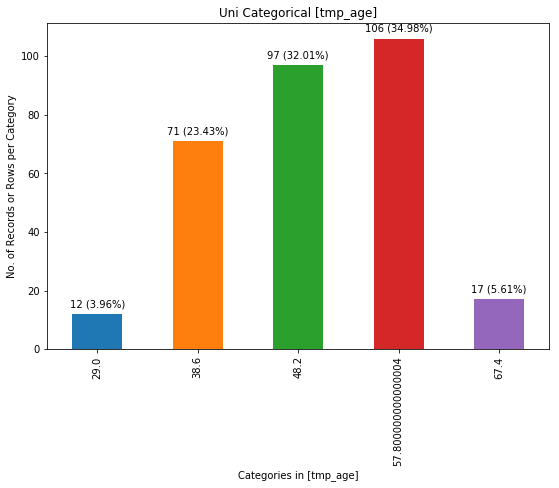
chartil.plot(heart_disease_df, ['age'], chart_type='barchart', optional_settings={'no_of_bins':5}) # Create custom number of bins
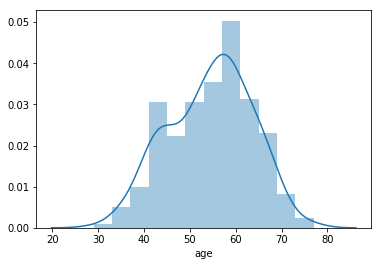
chartil.plot(heart_disease_df, ['age'], chart_type='distplot')
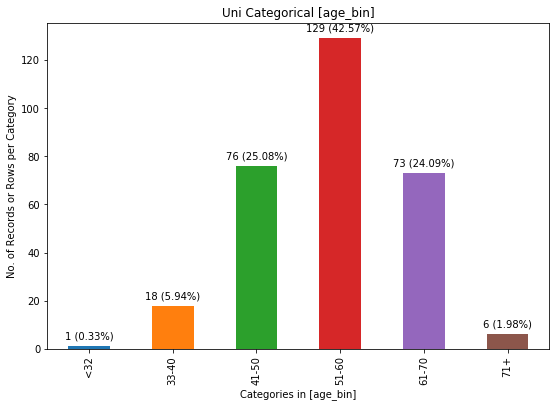
Uni-categorical with optional_settings
chartil.plot(heart_disease_df, ['age_bin']) # Barchart as count plot
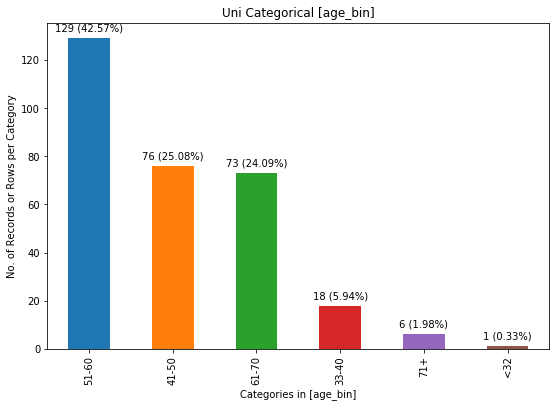
chartil.plot(heart_disease_df, ['age_bin'], optional_settings={'sort_by_value':True})
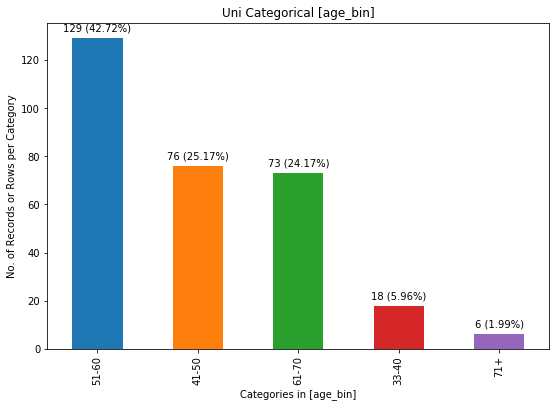
chartil.plot(heart_disease_df, ['age_bin'], optional_settings={'sort_by_value':True, 'limit_bars_count_to':5})
Bi Category vs Category (& Univariate Segmented)
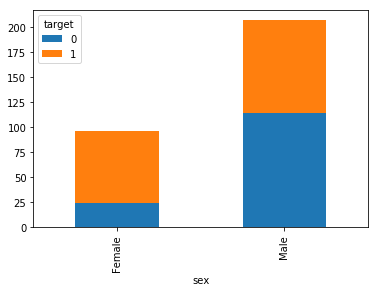
chartil.plot(heart_disease_df, ['sex', 'target'])
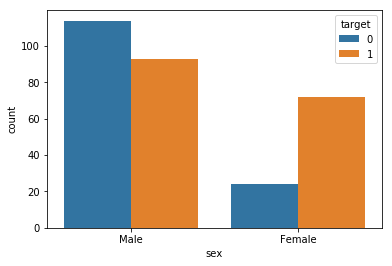
chartil.plot(heart_disease_df, ['sex', 'target'], chart_type='crosstab')
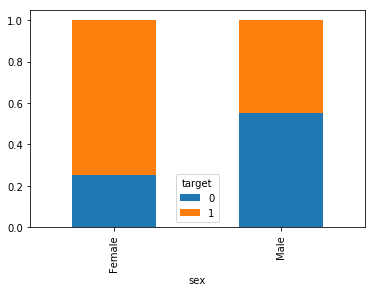
chartil.plot(heart_disease_df, ['sex', 'target'], chart_type='stacked_barchart')
Bi Continuous vs Continuous
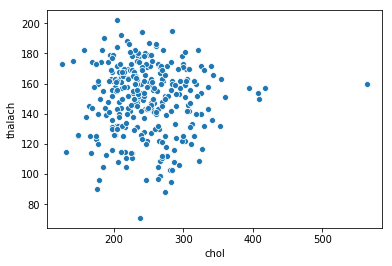
chartil.plot(heart_disease_df, ['chol', 'thalach']) # Scatter plot
Bi Continuous vs Category
chartil.plot(heart_disease_df, ['thalach', 'sex']) # Grouped box plot (Segmented univariate)
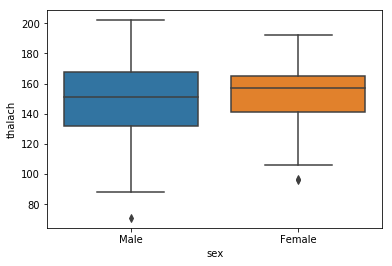
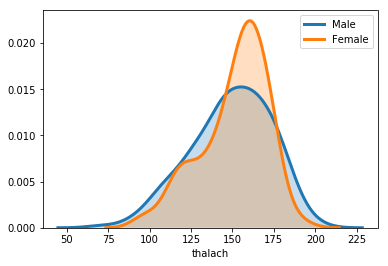
chartil.plot(heart_disease_df, ['thalach', 'sex'], chart_type='distplot') # Distplot
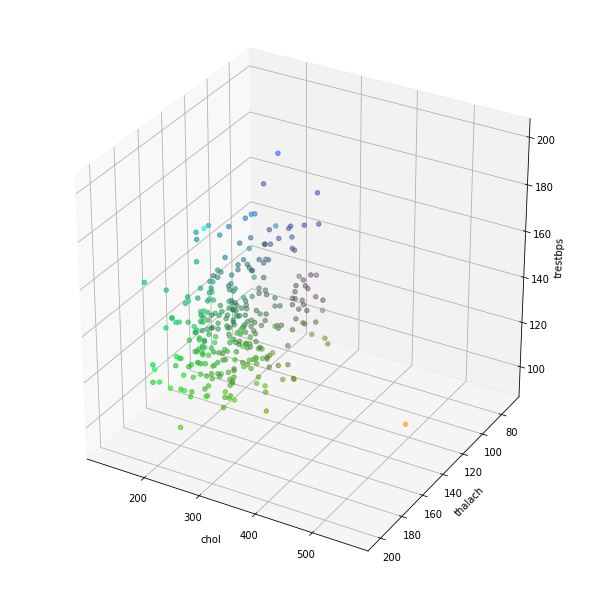
Multi 3 Continuous
chartil.plot(heart_disease_df, ['chol', 'thalach', 'trestbps']) # Colored 3D scatter plot
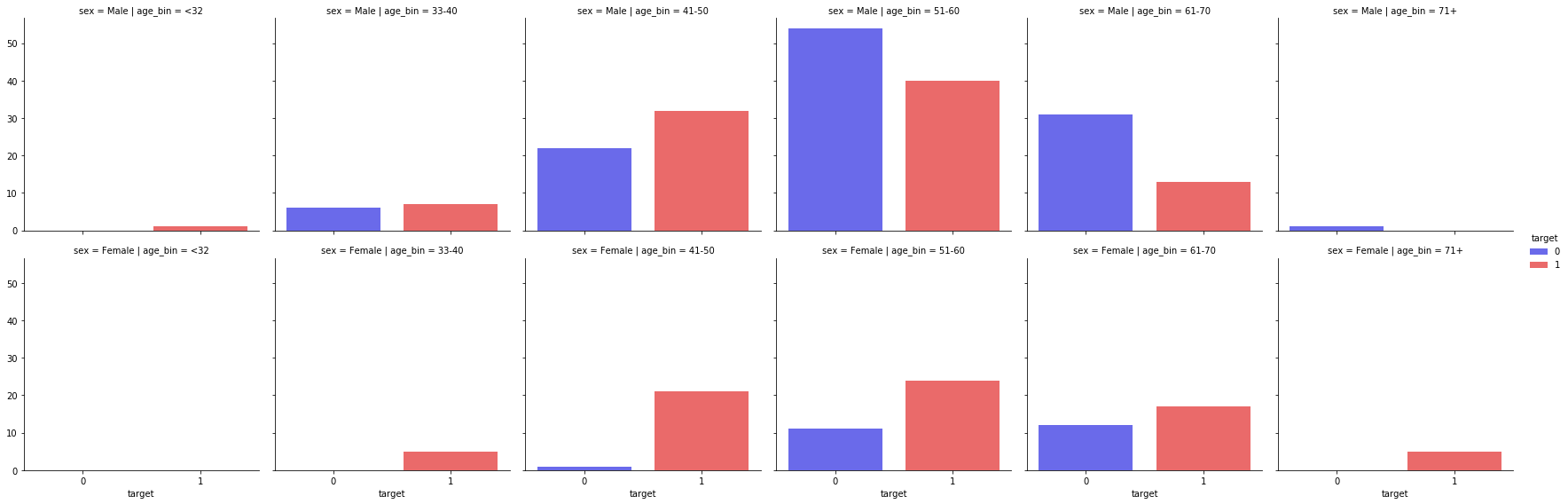
Multi 3 Categorical
chartil.plot(heart_disease_df, ['sex', 'age_bin', 'target']) # Paired barchart
Multi 2 Continuous, 1 Category
chartil.plot(heart_disease_df, ['chol', 'thalach', 'target']) # Scatter plot with colored groups
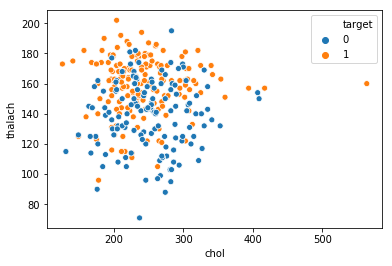
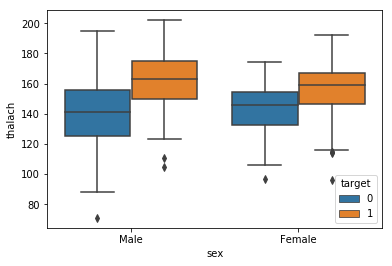
Multi 1 Continuous, 2 Category
chartil.plot(heart_disease_df, ['thalach', 'sex', 'target']) # Grouped boxplot
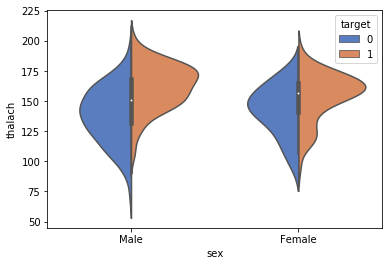
chartil.plot(heart_disease_df, ['thalach', 'sex', 'target'], chart_type='violinplot') # Grouped violin plot
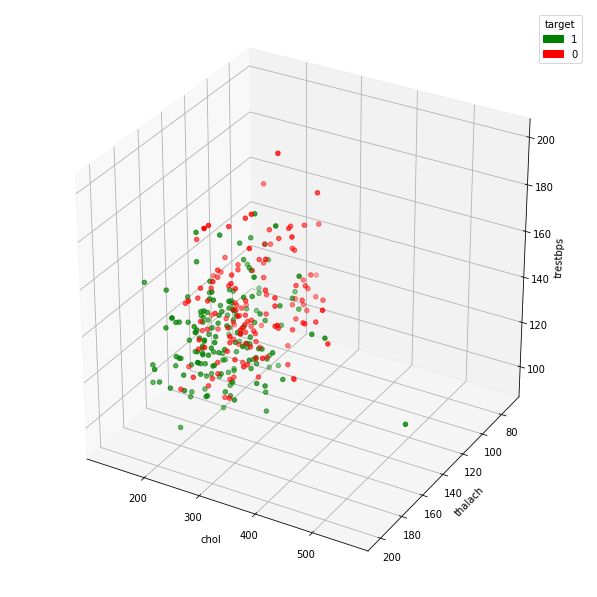
Multi 3 Continuous, 1 category
chartil.plot(heart_disease_df, ['chol', 'thalach', 'trestbps', 'target']) # Group Color highlighted 3D plot
Multi 3 category, 2 Continuous
chartil.plot(heart_disease_df, ['sex','cp','target','thalach','trestbps']) # Paired scatter plot
Full working demo available on kaggle here
Auto Linear Regression (Click to expand)
Auto Linear Regression
We have seen Auto ML like H2O which is a blackbox approach to generate models.
During our model building process, we try with brute force/TrialnError/several combinations to come up with best model. However trying these possibilities manually is a laborious process. In order to overcome or atleast have a base model automatically I developed this auto linear regression using backward feature elimination technique.
The library/package can be found here and source code here
How Auto LR works?
We throw the cleaned dataset to autolr.fit(<>) The method will
- Treat categorical variable if applicable(dummy creation/One hot encoding)
- First model - Run the RFE on dataset
- For remaining features elimination - it follows backward elimination - one feature at a time
- combination of vif and p-values of coefficients (Eliminate with higher vif and p-value combination
- vif only (or eliminate one with higher vif)
- p-values only (or eliminate one with higher p-value)
- Everytime when a feature is identified we build new model and repeat the process
- on every iteration if adjusted R2 affected significantly, we re-add/retain it and select next possible feature to eliminate.
- Repeat until program can't proceed further with above logic.
Auto Linear Regression Package/Function details
The method autolr.fit() has below parameters
- df, (The full dataframe)
- dependent_column, (Target column)
- p_value_cutoff = 0.01, (Threashold p-values of features to use while filtering features during backward elimination step, Default 0.01)
- vif_cutoff = 5, (Threashold co-relation of vif values of features to use while filtering features during backward elimination step, Default 5)
- acceptable_r2_change = 0.02, (Restrict degradtion of model efficiency by controlling loss of change in R2, Default 0.02)
- scale_numerical = False, (Flag to convert/scale numerical fetures using StandardScaler)
- include_target_column_from_scaling = True, (Flag to indiacte weather to include target column from scaling)
- dummies_creation_drop_column_preference='dropFirst', (Available options dropFirst, dropMax, dropMin - While creating dummies which clum drop to convert to one hot)
- train_split_size = 0.7, (Train/Test split ration to be used)
- max_features_to_select = 0, (Set the number of features to be qualified from RFE before entring auto backward elimination)
- random_state_to_use=100, (Self explanatory)
- include_data_in_return = False, (Include the data generated/used in Auto LR which might have gobne thru scaling, dummy creation etc.)
- verbose=False (Enable to print detailed debug messgaes)
Above method returns 'model_info' dictionary which will have all the details used while performing auto fit.
Full working demo available on kaggle here
Clustered Linear Regression (Click to expand)
Clustered Linear Regression
For a linear regression approach we try to fit a best model on entire dataset. However often we have seen within dataset based on a particular feature the dataset behaves totally different and single model is not the best solutions, instead have multiple model which applied on different subset or filtered data does better.
How to find the feature which splits the dataset into multiple sub dataset (and there after build and apply different models)
There is no easy solution, instead use trial and error or brute force to subset data on different feature and build multiple model. This clustred or grouped Linear Regression does the same. You send the entire dataset and specifiy list of columns to separate the dataset individually and return the kpi measures like rmse or r2 etc and then decide which way to go.
How "Clustered Linear Regression" works?
- First it lists possible combinations
- For each possible combinations split the data into subset
- For each subset execute the Auto Linear Regression. Check previous kaggle post on this.
- Return summary or consolidated kpi measures at group level.
The API clustlr.fit() has below parameters
- data_df (Full dataset)
- feature_group_list (List of column on which filter and group the data
- dependent_column (The target column)
- max_level = 2 (When it is 2 it uses two feature combination to filter)
- min_leaf_in_filtered_dataset=1000 (Condition the minimum datapoints in subgroup without which autolr will not be executed)
- no_of_bins_for_continuous_feature=10 (number of bins to be created when you use continuous varibale for grouping)
- verbose (Use True if you want detailed debug/log message)
Full working demo available on kaggle here
Auto Logistic Regression (Click to expand)
Auto Logistic Regression
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file kesh-utils-0.4.9.tar.gz.
File metadata
- Download URL: kesh-utils-0.4.9.tar.gz
- Upload date:
- Size: 33.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.29.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1f4cc294285a8d2d643d1037440beb54afdaecdbe3ad17d02eac07b6ce977d25
|
|
| MD5 |
035f52cfad4ba2f3fcddb95d73167640
|
|
| BLAKE2b-256 |
d149c98a0cd11386dddc8d0b7465e3e9aea45996f507be0f285b24a812484497
|
File details
Details for the file kesh_utils-0.4.9-py3-none-any.whl.
File metadata
- Download URL: kesh_utils-0.4.9-py3-none-any.whl
- Upload date:
- Size: 38.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.29.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
696fdf3a5f9547726a55e4ab885607adaf52674a804dd43c145d48e69c531cf3
|
|
| MD5 |
7c591c532ded80ab460a8153522e2688
|
|
| BLAKE2b-256 |
d6e021fa3380fe7f59c717ace502bb2bca6f9150a6a04469c975c94010216edb
|







