A Library to Convert Curl to Python Requests File

Project description
KKBA

Intruoduction
A low-code tool that generates python crawler code based on curl or url
Requirement
Python >= 3.6
Install
pip install kkba
Usage
Copy the curl command or url from the browser, without pasting, execute the command directly: kkba [options]
kkba [options]
# After the command execution, the crawler directory will be generated in the current directory (including the crawler articles and readme files).
Example
# 1. Copy curl or url
# 2. Excute commands
kkba -F
# use proxy,support 蜻蜓、快代理、阿布云, For detailed usage, you can view the source code
from kkba.proxy import Proxy
p = Proxy(crawlerType='requests', proxyType='xxx', username='xxx', password='xxx')
proxies = p.get_proxy()
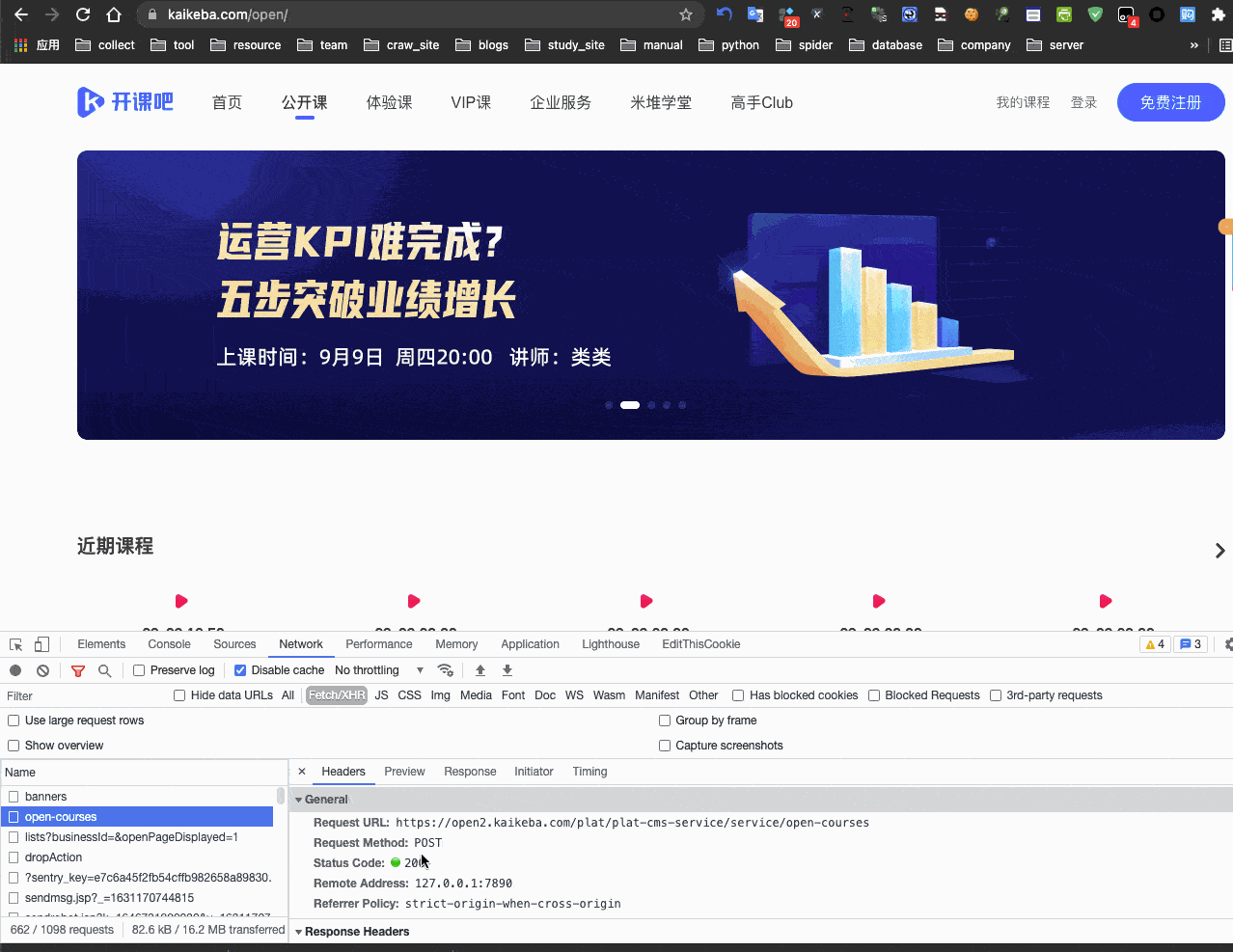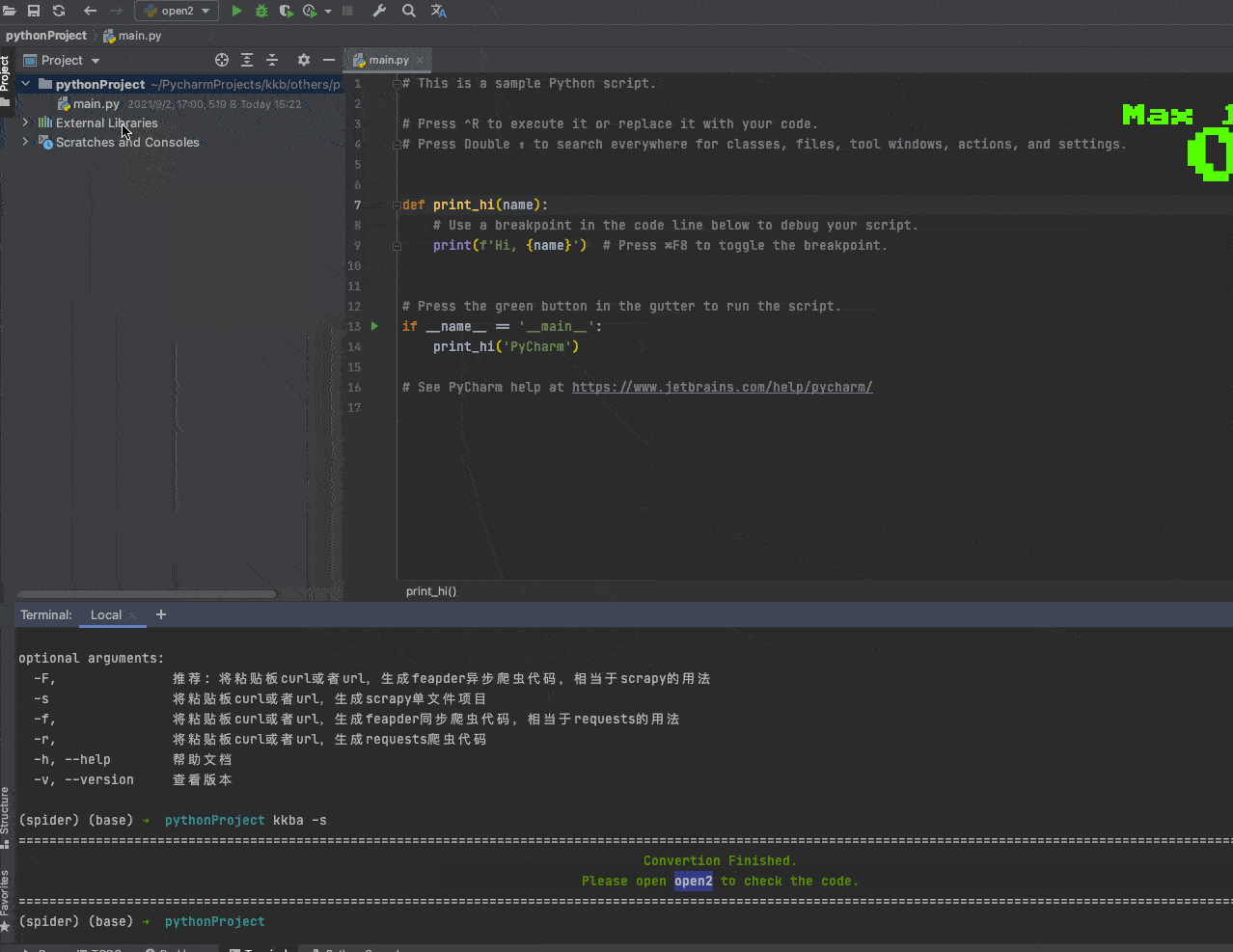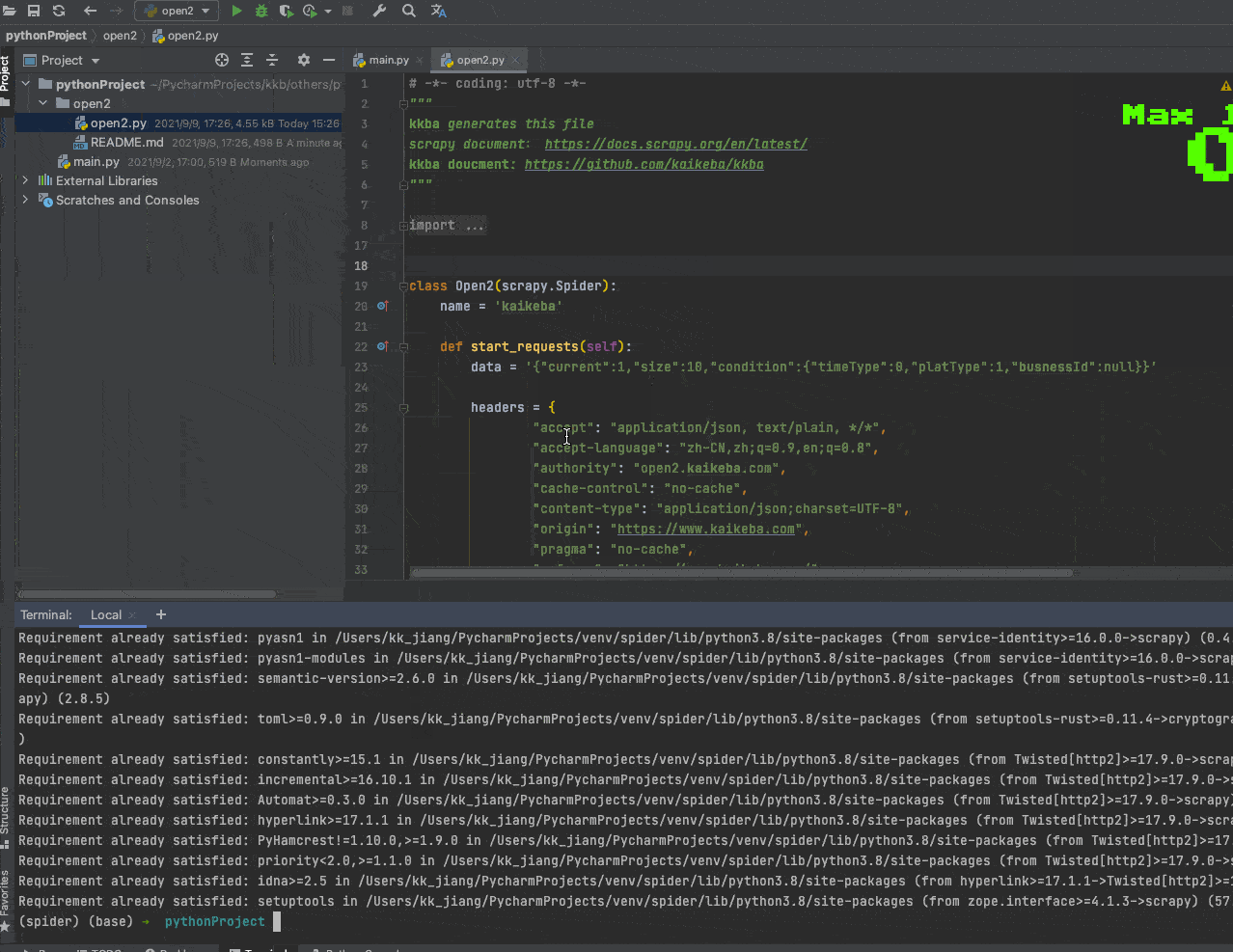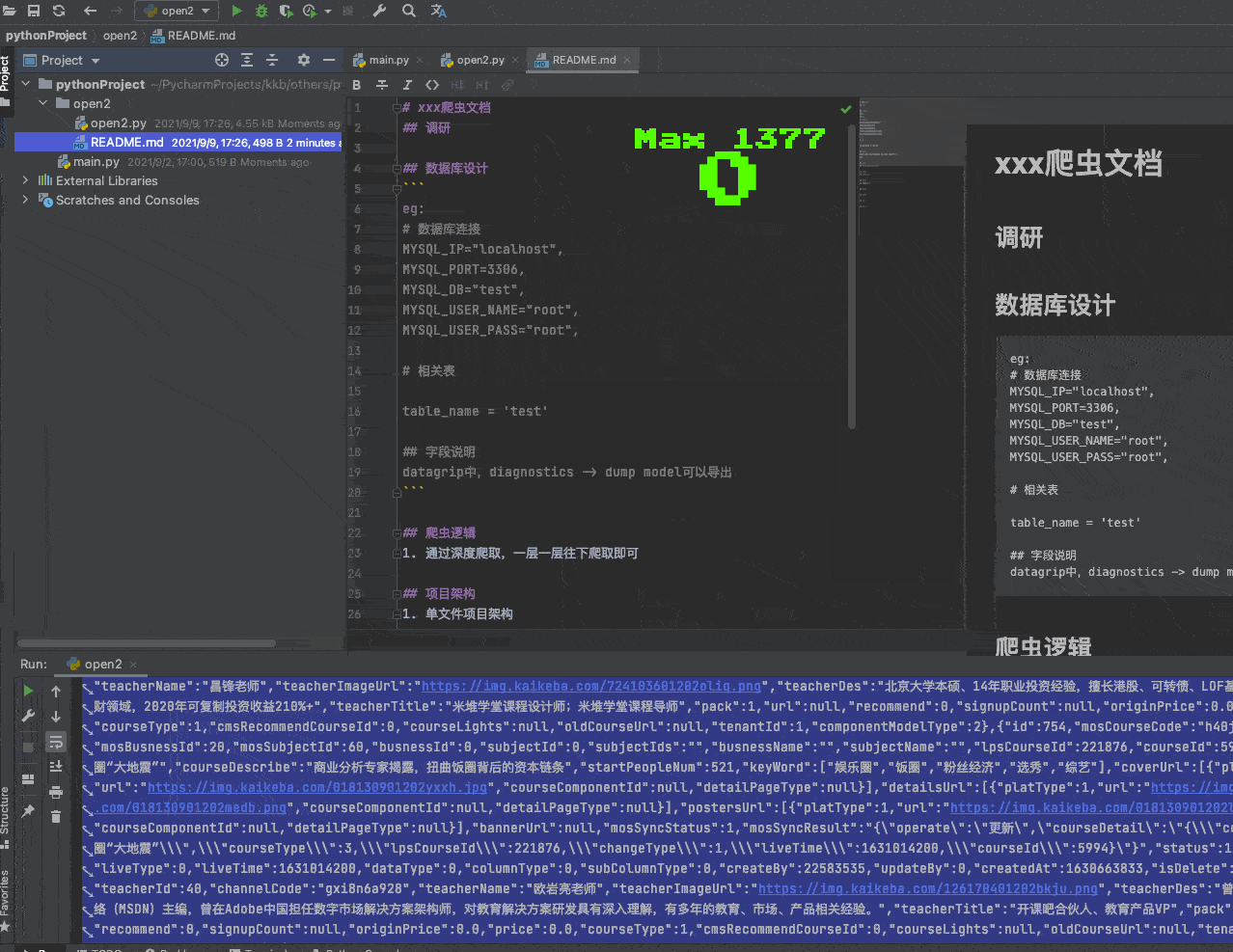
Help Document
kkba -h
爬虫生成器
usage: kkba [options]
optional arguments:
-F, 推荐: 将粘贴板curl或者url,生成feapder异步爬虫代码,相当于scrapy的用法
-s 将粘贴板curl或者url,生成scrapy单文件项目
-f, 将粘贴板curl或者url,生成feapder同步爬虫代码,相当于requests的用法
-r, 将粘贴板curl或者url,生成requests爬虫代码
-h, --help 帮助文档
-v, --version 查看版本
Genrates feapder spider code
# install fepader
pip install feapder
# generates feapder spiders code
kkba -F
Generates scrapy single file code
# install scrapy
pip install scrapy
# generates scrapy single spiders code
kkba -F
Thanks
curl2pyreqs 令狐 向娜
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
kkba-0.8.16.tar.gz
(15.8 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
kkba-0.8.16-py3-none-any.whl
(17.6 kB
view details)
File details
Details for the file kkba-0.8.16.tar.gz.
File metadata
- Download URL: kkba-0.8.16.tar.gz
- Upload date:
- Size: 15.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.6.1 pkginfo/1.7.1 requests/2.27.1 requests-toolbelt/0.9.1 tqdm/4.57.0 CPython/3.8.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1c7aeeaa17f2e5035612b6103b506a582e79e46cfaa8bee3b3597a23fb83a9dd
|
|
| MD5 |
2b16ca9056be3074eb2694c7abc9b9b8
|
|
| BLAKE2b-256 |
e9d7f4d31ca90af85e90102175c0a0589b0500a88c6b869c9f589932f7a9eb4f
|
File details
Details for the file kkba-0.8.16-py3-none-any.whl.
File metadata
- Download URL: kkba-0.8.16-py3-none-any.whl
- Upload date:
- Size: 17.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.6.1 pkginfo/1.7.1 requests/2.27.1 requests-toolbelt/0.9.1 tqdm/4.57.0 CPython/3.8.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
08ae72ea8dadd5c4f5becb6dd0aa82d8957f3939e89765f185ca8f4d66f2e674
|
|
| MD5 |
7c3cb540b18e7341d21e781d0fad0694
|
|
| BLAKE2b-256 |
f36dcfc423c36f64b3005d6688034648f5573f41eb725fb8f0f1341d98b28ce3
|







