Add your description here

Project description
🌿 Konoha: Simple wrapper of Japanese Tokenizers











Konoha is a Python library for providing easy-to-use integrated interface of various Japanese tokenizers,
which enables you to switch a tokenizer and boost your pre-processing.
Supported tokenizers






Also, konoha provides rule-based tokenizers (whitespace, character) and a rule-based sentence splitter.
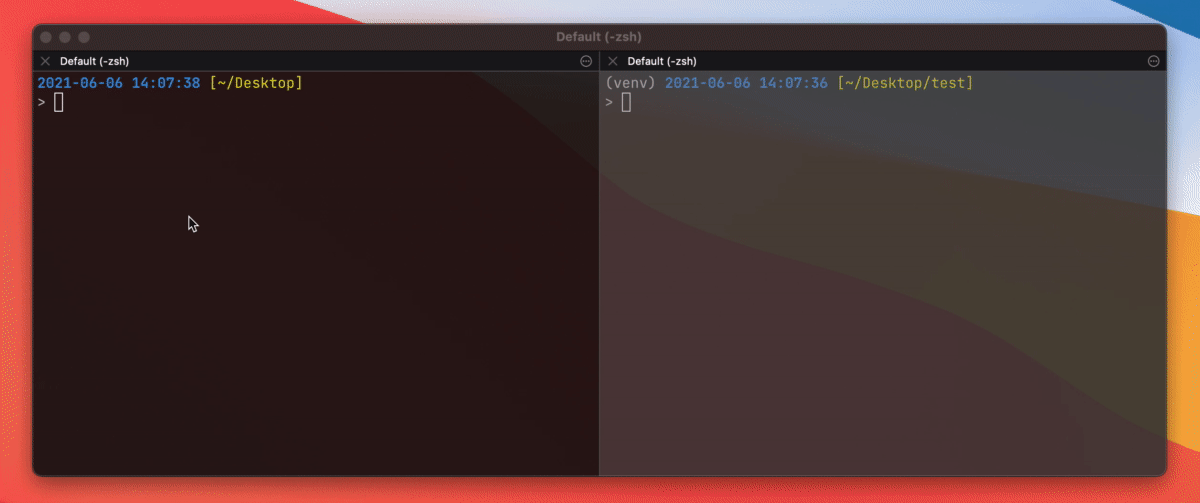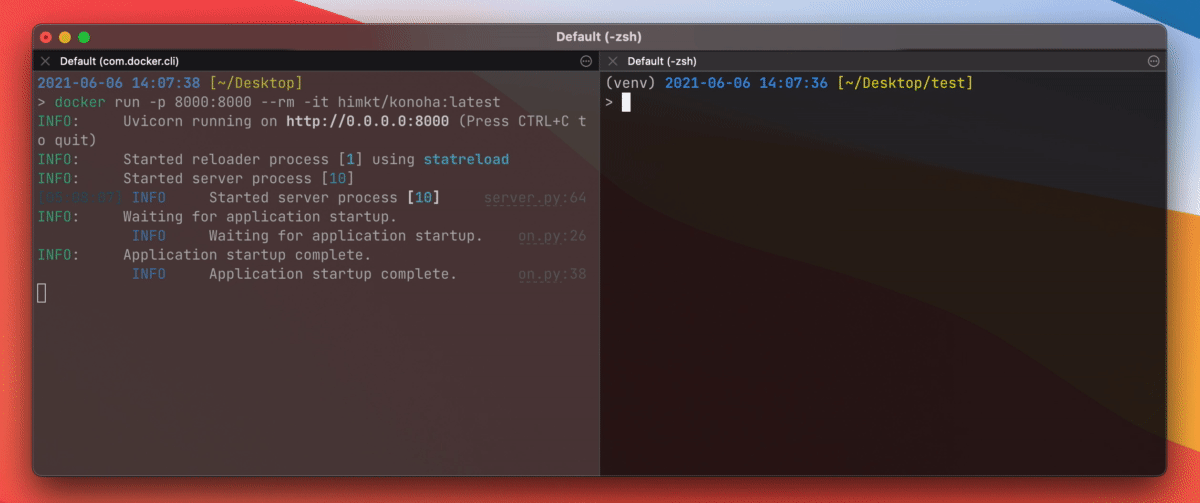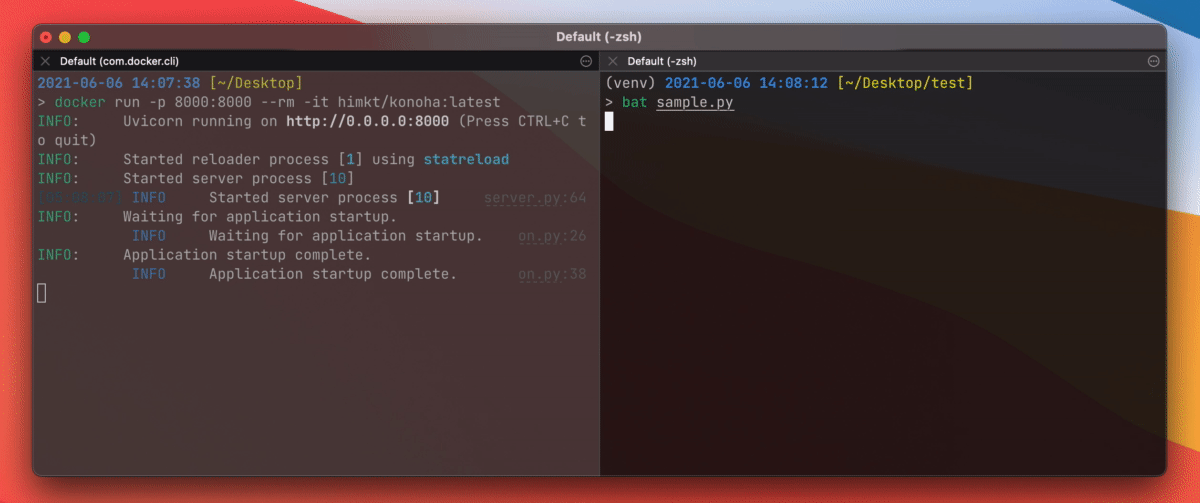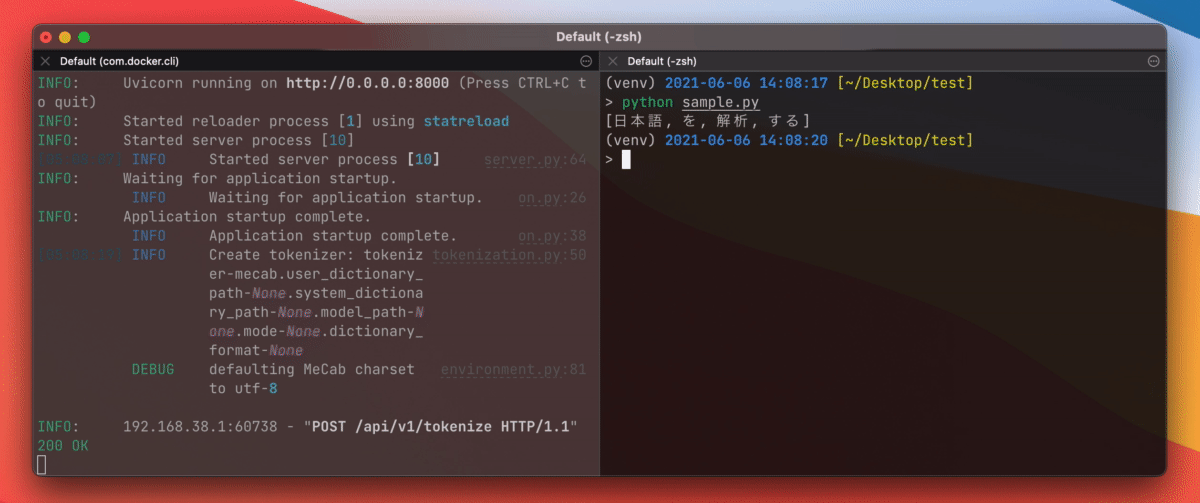
Quick Start with Docker
Simply run followings on your computer:
docker run --rm -p 8000:8000 -t himkt/konoha # from DockerHub
Or you can build image on your machine:
git clone https://github.com/himkt/konoha # download konoha
cd konoha && docker-compose up --build # build and launch container
Tokenization is done by posting a json object to localhost:8000/api/v1/tokenize.
You can also batch tokenize by passing texts: ["1つ目の入力", "2つ目の入力"] to localhost:8000/api/v1/batch_tokenize.
(API documentation is available on localhost:8000/redoc, you can check it using your web browser)
Send a request using curl on your terminal.
Note that a path to an endpoint is changed in v4.6.4.
Please check our release note (https://github.com/himkt/konoha/releases/tag/v4.6.4).
$ curl localhost:8000/api/v1/tokenize -X POST -H "Content-Type: application/json" \
-d '{"tokenizer": "mecab", "text": "これはペンです"}'
{
"tokens": [
[
{
"surface": "これ",
"part_of_speech": "名詞"
},
{
"surface": "は",
"part_of_speech": "助詞"
},
{
"surface": "ペン",
"part_of_speech": "名詞"
},
{
"surface": "です",
"part_of_speech": "助動詞"
}
]
]
}
Installation
I recommend you to install konoha by pip install 'konoha[all]'.
- Install konoha with a specific tokenizer:
pip install 'konoha[(tokenizer_name)]. - Install konoha with a specific tokenizer and remote file support:
pip install 'konoha[(tokenizer_name),remote]'
If you want to install konoha with a tokenizer, please install konoha with a specific tokenizer
(e.g. konoha[mecab], konoha[sudachi], ...etc) or install tokenizers individually.
Example
Word level tokenization
from konoha import WordTokenizer
sentence = '自然言語処理を勉強しています'
tokenizer = WordTokenizer('MeCab')
print(tokenizer.tokenize(sentence))
# => [自然, 言語, 処理, を, 勉強, し, て, い, ます]
tokenizer = WordTokenizer('Sentencepiece', model_path="data/model.spm")
print(tokenizer.tokenize(sentence))
# => [▁, 自然, 言語, 処理, を, 勉強, し, ています]
For more detail, please see the example/ directory.
Remote files
Konoha supports dictionary and model on cloud storage (currently supports Amazon S3).
It requires installing konoha with the remote option, see Installation.
# download user dictionary from S3
word_tokenizer = WordTokenizer("mecab", user_dictionary_path="s3://abc/xxx.dic")
print(word_tokenizer.tokenize(sentence))
# download system dictionary from S3
word_tokenizer = WordTokenizer("mecab", system_dictionary_path="s3://abc/yyy")
print(word_tokenizer.tokenize(sentence))
# download model file from S3
word_tokenizer = WordTokenizer("sentencepiece", model_path="s3://abc/zzz.model")
print(word_tokenizer.tokenize(sentence))
Sentence level tokenization
from konoha import SentenceTokenizer
sentence = "私は猫だ。名前なんてものはない。だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer()
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,「かわいい。それで十分だろう」。']
You can change symbols for a sentence splitter and bracket expression.
- sentence splitter
sentence = "私は猫だ。名前なんてものはない.だが,「かわいい。それで十分だろう」。"
tokenizer = SentenceTokenizer(period=".")
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。名前なんてものはない.', 'だが,「かわいい。それで十分だろう」。']
- bracket expression
sentence = "私は猫だ。名前なんてものはない。だが,『かわいい。それで十分だろう』。"
tokenizer = SentenceTokenizer(
patterns=SentenceTokenizer.PATTERNS + [re.compile(r"『.*?』")],
)
print(tokenizer.tokenize(sentence))
# => ['私は猫だ。', '名前なんてものはない。', 'だが,『かわいい。それで十分だろう』。']
Test
python -m pytest
Article
Acknowledgement
Sentencepiece model used in test is provided by @yoheikikuta. Thanks!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file konoha-5.6.0.tar.gz.
File metadata
- Download URL: konoha-5.6.0.tar.gz
- Upload date:
- Size: 11.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.6.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9bed8cfc5d760376438add5e03b216905058500e663d84860821391b8e530ae3
|
|
| MD5 |
df68a3692065ac96c585c7aeb8317df7
|
|
| BLAKE2b-256 |
4ec98e070d959e1e4b14eaf098af79818c455efdf05ca731c2212e93d9f33452
|
File details
Details for the file konoha-5.6.0-py3-none-any.whl.
File metadata
- Download URL: konoha-5.6.0-py3-none-any.whl
- Upload date:
- Size: 18.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.6.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2462fbdcef4ce91154bd73c000a0202e811d8becc8027df651c126323bd0a902
|
|
| MD5 |
8c64d95ffbe5a5214b298e57fd1fa0b8
|
|
| BLAKE2b-256 |
bfd08faeea8075f6fdee562130b06d78febbf8552c20dfe0a0928ed1fc002502
|







