Easier automatic validation and regression testing

Project description
Travis CI: 

Automated regression tests
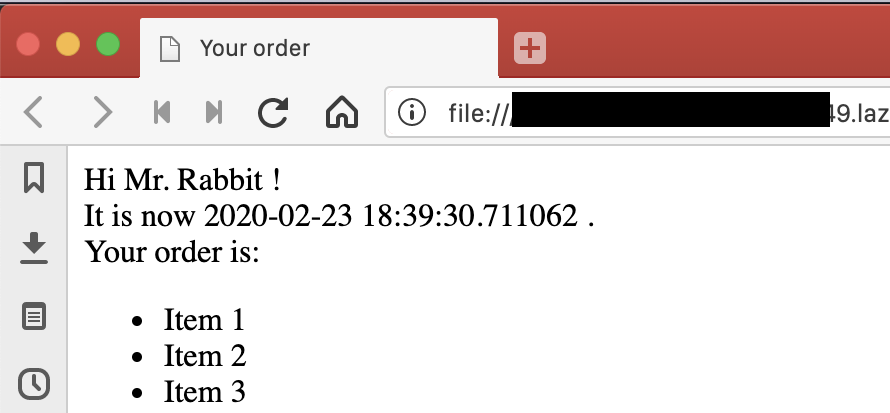
Let's take a simple web page that has some variable data.
Driving it is some simplistic markup, and a mocked up http unittest that varies some data like the time stamp and a hidden csrf token.
Goals
We want to do the following, with less than 10 lines of code:
- regression test that the page HTML is the same from run to run
- validate basic HTML behavior, like
title, 200status_codeand httpcontent_type - check that
namein the greeting corresponds to what's set on the unittest configuration - an additional feature is the presence of a csrf random token.
Obviously, both the csrf token and the time stamp need to be disregarded from run to run.
If anything else changes, we want to fail the test automatically. The tester can then examine what changed and determine whether to accept the new HTML as the new baseline. Cosmetic HTML changes are for designers to worry about, test code shouldn't have to change.
What a full test looks like, minus server/response mocking:
full test code, under class Test_Features
# generic lazy functionality
from lazy_regression_tests import (
LazyMixin,
ValidationDirective,
FilterDirective,
AutoExp,
RegexRemoveSaver,
)
# specific to HTTP/HTML validations
from lazy_regression_tests.http_validators import (
HTMLValidationMixin,
ResponseHTML,
HtmlFilterManager,
CSSRemoveFilter,
CSSValidator,
)
class LazyMixinBasic(LazyMixin):
""" base Mixin class for the lazy test framework """
lazy_filename = LazyMixin.get_basename(__name__, __file__, __module__)
cls_filters = dict(html=HtmlFilterManager())
# 👇 🥦🥦 filter changing contents
filter_variables = [
FilterDirective(
"timestamp", filter_=CSSRemoveFilter("span.timestamp", "timestamp", scalar=True)
),
FilterDirective("csrf", filter_=RegexRemoveSaver("csrf_token", "csrf_token")),
]
class Test_Features(Helper, HTMLValidationMixin, LazyMixinBasic, unittest.TestCase):
cls_filters = dict(html=filter_variables) # 👈 This is how we add the filters
name = "Mr. Rabbit" # picked up by `AutoExp` below
# 👇 setting up the validations 🥦🥦
cls_validators = [
ValidationDirective("title", exp="Your order"),
ValidationDirective("name", exp=AutoExp, validator=CSSValidator("#name")),
]
@mock.patch.dict(os.environ, di_mock_env)
def test_it(self):
try:
# this comes from `requests`, could be a Django testserver, your code...
http_response = get_fake_response_from_template(self)
# if we re-use filters and validations, yes, we use a lot less than
# 10 lines of code 👇 🍰🍰🍰🍰
# "adapt" standard http_response by tracking content_type, status_code, headers...
response = ResponseHTML(http_response)
# Check validation such as content_type and status code
self.check_expectations(response=response)
# Regression test - did we get the same contents as the last time?
tmp = self.assert_exp(response.content, "html")
except (Exception,) as e:
raise
THE DETAILS...
Let's start out by assuming we didn't have the filters configured yet, so data changes from run to run.
full test code, with more examples, under class Test_Features
Trigger a failure by running the test twice.
pytest -q test_doc::Test_Features::test_it
pytest -q test_doc::Test_Features::test_it
The first time works just fine - this test has never been run so the received data is taken as the expected data for this test.
The second run however triggers a test failure because the crsf token and timestamp don't match the first pass.
E ❌❌❌Regressions found:
✂️✂️✂️✂️✂️
E <script>
E - const csrf_token = 'VRzFbhbVZnzWZQlmr6xd';
E + const csrf_token = 'E0z05wqHH0I6msv7iouB';
✂️✂️✂️✂️✂️
E <br/>
E It is now
E <span class="timestamp">
E - 2020-02-23 19:04:52.777187
E ? ^^ --- ^^
E + 2020-02-23 19:17:52.106223
E ? ^^ ^^^^^
✂️✂️✂️✂️✂️
E ❌❌❌
Fix : filter out changing data
We want disregard the csrf token and the timestamp data when comparing runs. To do that, we add two filters to our processing of HTML data, one for the csrf and one for the time stamp.
filter_variables = [
FilterDirective(
"timestamp"
,filter_=CSSRemoveFilter("span.timestamp", "timestamp", scalar=True)
),
FilterDirective(
"csrf"
, filter_=RegexRemoveSaver("csrf_token", "csrf_token")),
]
Add the filters to the test class:
Note that our unittest inherits from LazyMixinBasic, which enables the whole lazy-test framework.
# ⚙️ This enables the lazy-test framework 👇
class Test_Features(Helper, HTMLValidationMixin, LazyMixinBasic, unittest.TestCase):
""" this is the test we are running here """
cls_filters = dict(html=filter_variables) # 👈 This is how we add the filters
name = "Mr. Rabbit"
line1 = "Item 1"
...
Write as little as possible:
The actual test code to use in each test method is very limited. Yes, you will need to declare those filters and validations, but they are designed to be shared across multiple test classes.
Most of the behavior is built-in, once you inherit from a base class. Filters, and validators which we will see later, are inherited from class to class via Python's standard MRO and some metaclass tweaking. No setUp/tearDown are needed, but you can use yours as usual.
The actual test class: Test_Features
We define Test_Features to be both a LazyMixin - which enables lazy-testing - and a TestCase. Helper isn't super important, it's just there to support the fake html requests.
# 👇⚙️This enables the lazy-test framework
class Test_Features(Helper, HTMLValidationMixin, LazyMixinBasic, unittest.TestCase):
""" this is the test we are running here """
cls_filters = dict(html=filter_variables) # 👈 This is how we add the filters
name = "Mr. Rabbit"
line1 = "Item 1"
line2 = "Item 2"
line3 = "Item 3"
# 👇 setting up the validations
cls_validators = [
ValidationDirective("title", exp="Your order"),
ValidationDirective("name", exp=AutoExp, validator=CSSValidator("#name")),
]
# the template used to generate the fake html
template = """
<title>Your order</title>
<script>
const csrf_token = '{{csrf}}';
</script>
<body>
Hi <span id="name">{{ name }}</span> !<br/>
It is now<span class="timestamp">{{ timestamp }}</span>.<br/>
Your order is:
<ul>
<li class="orderline">{{line1}}</li>
<li class="orderline">{{line2}}</li>
<li class="orderline">{{line3}}</li>
</ul>
</body>
"""
Run the test again
The test still fails - the csrf token and timestamps are gone, but only from the newly received data.
Things are slightly different. Before, we had 2 csrf tokens and two time stamps, one before (19:04), one after (19:23). Now it seems we only see the old ones, the new ones are being filtered out.
We need a way to accept the new data as the reference. There are two ways to do that.
E AssertionError:
E
E ❌❌❌Regressions found:
✂️✂️✂️✂️✂️
E <script>
E - const csrf_token = 'VRzFbhbVZnzWZQlmr6xd';
E </script>
✂️✂️✂️✂️✂️
E <br/>
E It is now
E - <span class="timestamp">
E - 2020-02-23 19:04:52.777187
E - </span>
E <ul>
✂️✂️✂️✂️✂️
Option #1 - reset expectations via baseline directive.
We need to tell the test to accept the new format as valid. Telling assert_exp that you want to treat new data as valid is what the directive=baseline mechanism is made for, which uses the environment variable $lzrt_directive.
Let's try it out:
lzrt_directive=baseline pytest -q test_doc::Test_Features::test_it
. [100%]
1 passed in 0.25s
What does lzrt_directive=baseline do? Whenever it is set, calling assert_exp overwrites the saved expectations file with the incoming, now filtered, data.
Option #2 - overwrite the expectations file
Instead of using baseline, you can also just copy the received/got formatted file over to the expected reference file. Or you can just delete the expectations file entirely.
The error message lists the paths:
❌❌❌Regressions found:
Expected contents are in file:
...tests/lazy/exp/Test_Features/test_doc.Test_Features.test_it.html
Received contents are in file:
.../lazy/got/Test_Features/test_doc.Test_Features.test_it.html
....
copy Received to Expected and the test will also pass next time.
Test-driven development:
Let's say we want to support styles on the order lines as in:
<li class="orderline">Item 1</li>
Just edit it manually in the expectations file.
Your order is:
<ul> 👇
<li class="orderline">
Item 1
...
and now the test fails until the application code has been updated:
❌❌❌Regressions found:
....
<ul>
- <li class="orderline">
+ <li>
Item 1
and succeeds afterwards:
pytest -q test_doc::Test_Features::test_it
. [100%]
1 passed in 0.29s
Validations
Validations are separate from the regression tests, but work with them. If you get an HTML 404 response instead of your expected JSON response, it is much more informative to be told that your response is in error status and of the wrong content type rather than looking at a big dump of mismatched expected JSON vs received HTML.
Let's fake out a bad response by setting it on the response.
response = ResponseHTML(http_response)
response.status_code = 404 👈 fake!
self.validationmgr.debug() 👈 and we will use this inspect the validations
We get the expected error:
E AssertionError:
E
E ❌❌❌❌❌❌❌
E
E Validation failure @ status_code [StatusCodeValidator[selector=status_code]]:
E
E False is not true : status_code exp:200<>404:got
E
E ❌❌❌❌❌❌❌
Where did this come from? class Test_Features's validations has 2 validations defined on it:
name
will use a CSS selector to find the matching element and the expection for it is AutoExp. AutoExp basically will cause the validator to look for a matching attribute in our unittest, i.e. name i.e. "Mr. Rabbit".
title
only has a hardcoded expectation and no apparent strategy to validate it.
# HTTP/HTML validation inheritance
# 👇
class Test_Features(Helper, HTMLValidationMixin, LazyMixinBasic, unittest.TestCase):
# 👇 setting up the validations
cls_validators = [
ValidationDirective("title", exp="Your order"),
ValidationDirective("name", exp=AutoExp, validator=CSSValidator("#name")),
]
Let's see what that debug function call has to say. Turns out there are a number of validations. What we are interested in is the class-level inheritance:
⚙️⚙️⚙️⚙️⚙️⚙️ lazy-tests configuration ⚙️⚙️⚙️⚙️⚙️⚙️
ValidationManager for test_it (__main__.Test_Features) validators:
status_code : active:True exp:200 StatusCodeValidator
content_type : active:True exp:html ContentTypeValidator
title : active:True exp:Your order TitleCSSValidator
name : active:True exp:Mr. Rabbit CSSValidator
⚙️class-level inheritance:
lazy_regression_tests.lazy3.http_validators.HTTPValidationMixin
lazy_regression_tests.lazy3.http_validators.HTMLValidationMixin
__main__.Test_Features
Validations default from class inheritance
To avoid side effects of sharing those validators and filters, the actual objects are always copied whenever they are inherited from another level. So you can for example reach into a CSSValidator and change its selector for 1 class.
Going from generic to specific (i.e. reverse MRO order):
First we set the content_type validation to be active, but leaving out the expectations.
class HTTPValidationMixin:
""" sets basic expectations
- http is expected to return a status_code, typically 200 (exp can be changed later)
- and has a content_type, which changes depending on end points
"""
cls_validators = [
ValidationDirective("status_code", exp=200, validator=StatusCodeValidator()),
ValidationDirective("content_type", active=True, validator=ContentTypeValidator()),
]
Next comes the HTML validations, which look for a title and also sets expections on the content_type:
title_validation = ValidationDirective("title", active=True, validator=TitleCSSValidator())
class HTMLValidationMixin(HTTPValidationMixin):
""" set `content_type` expectations
always want to validate `title`, by default
"""
cls_validators = [title_validation, ValidationDirective("content_type", exp="html")]
Writing your own validations
We haven't done that line item validation (they all need to start with "Item"). To do that we'll copy our class and add that validation.
Easy way - use built-in features:
Here we just add a CSS selector, with a regular expression as an expectation:
We expect our test to fail, because of the bad line3
cls_validators = [ #👇 #👇
ValidationDirective("item", exp=re.compile("^Item"), validator=CSSValidator("li.orderline")),
]
name = "Mr. Rabbit"
line1 = "Item 1"
line2 = "Item 2"
line3 = "Bad line 3" 👈❌ we're expecting a failure here
Sure enough:
❌❌❌❌❌❌❌
Validation failure @ item [CSSValidator[selector=li.orderline]]:
None is not true : item pattern:^Item:does not match:['Item 1', 'Item 2', 'Bad line 3']:got
❌❌❌❌❌❌❌
Or, write your own validation:
We can write our own validation function, which always receives:
testee: the unittest to assert againstgot:which is what the validator selection criteria has found- the validator itself
We inherit our failed Regex-based test, so we can re-use the CSS selector but just provide a custom validation function.
def check_lineitems(testee: "unittest.TestCase", got, validator: "Validator"):
"""
`got` will be a list of strings here
👉keeping this as stand alone function, rather a method of your TestCase
means it can be used anywhere. It still behaves just like a test method
"""
try:
for igot in got:
if not igot.endswith("3"):
testee.assertTrue(igot.startswith("Item"))
# pragma: no cover pylint: disable=unused-variable
except (Exception,) as e:
if cpdb():
pdb.set_trace()
raise
class Test_Features_CustomLineValidation(Test_Features_Regex):
""" This should pass, we are re-using the CSSValidation lookup for `item`"""
# 👇
cls_validators = [ValidationDirective("item", exp=check_lineitems)] # 👇
name = "Mr. Rabbit"
line1 = "Item 1"
line2 = "Item 2"
line3 = "Bad line 3"
The reason this validator sends a list of string:
Configured differently it could give you one or more DOM nodes to validate.
CSSValidator[selector=li.orderline] ''
cargo=None
scalar=False 👈
selector='li.orderline'
sourcename='response.selectable'
to_text=True 👈
For example, the title validator is preset differently because there's only one <title> tag.
TitleCSSValidator[selector=title] ''
scalar=True
selector='title'
sourcename='response.selectable'
Adjustments can be made within a test method
Here our validations would fail on the name and title, so we turn them off (which we could have done in the cls_validators as wel. We also turn off timestamp filtering.
class Test_Turning_ThingsOff(Test_Features):
""" we don't have a title or a greeting anymore
and we don't need to filter out the timestamp either
"""
template = """
<body>
It is now<span class="timestamp">fake, fixed, timestamp</span>.<br/>
</body>
"""
def setUp(self):
# 👇 turn these off to avoid validation errors
self.set_expectation("title", active=False)
self.set_expectation("name", active=False)
self.filters["html"].set_filter("timestamp", active=False) #👈 keep it
Wrapping things up
Access filtered-out data:
You may have noticed a little tmp variable by each assert_exp call.
tmp = self.assert_exp(response.content, "html")
That result object has a number of attributes and is available even if there is an AssertionError, via self.lazytemp. What we are most interested in is tmp.filtered which is a dictionary that holds lists of filtered values (but only if the filter was given a name).
class.Dummy ''
csrf_token=[" const csrf_token = 'M334JV6eNwJh9yFaFa89';"]
timestamp=?
Throttling validations:
Sometimes you want to turn off most of your validations in a test method without having to redefine things at the class level. Let's say I want to check a 404 in a complex URL - I may want to provide all the correct config for the test, using my base TestCase, but then just provide an incorrect ID for the data lookup.
In that case, most of my validations for the normal pages would fail, so I only to run a subset, maybe confirm status_code=404 and the content_type.
# fake a 404
response.content = "<div>404, to you, buddy!</div>"
response.status_code = 404
# This handles the 404, however, the title and name would error out
self.set_expectation("status_code", 404)
# 👇 turn off what you don't need
constants_keep_on_404 = ["status_code", "content_type"]
self.check_expectations(response=response, lazy_skip_except=constants_keep_on_404)
Not limited to HTML
JSON, YAML and SQL work too.
This was written to validate both HTML and embedded JSON within that HTML.
The JSON Filter has its own Validators and Filters, which operate on dictionaries. Aside from the serialization dump format, YAML works almost the same way.
The SQL manager takes any big SQL query string, applies some formatting to normalize it a bit and can be used to keep track of changes to these queries. It can be useful if you have an ORM-layer that you want to monitor for feature stability from version to version.
Other formats can be supported, provided there is a consistent way to store them in files and load them back up.
from lazy_regression_tests.lazy3.filters import JsonFilterManager,
class Test_JSON_Too(LazyMixinBasic, unittest.TestCase):
""" just connect it to the appropriate filter manager for
the extension type
"""
from lazy_regression_tests.lazy3.filters import JsonFilterManager
cls_filters = dict(json=JsonFilterManager())
extension = "json"
def test_it(self, data={}):
""" fetch data, run validations, regression test """
try:
data = dict(
var1="the_same",
var2="will_change",
)
tmp = self.assert_exp(data, self.extension)
data.update(var2="told you so")
tmp = self.assert_exp(data, self.extension)
except (Exception,) as e:
raise
class Test_YAML(Test_JSON_Too):
""" hey, most of the work was done by the JSON guys already
"""
from lazy_regression_tests.lazy3.yaml_validators import YAMLFilter
extension = "yaml"
cls_filters = dict(yaml=YAMLFilter())
As, expected with this test scenario, both error out:
JSON:
E {
E "var1": "the_same",
E - "var2": "will_change"
E + "var2": "told you so"
E }
E ❌❌❌
../lazy_regression_tests/lazy3/core.py:498: AssertionError
======================================== short test summary info =========================================
FAILED test_doc.py::Test_JSON_Too::test_it - AssertionError:
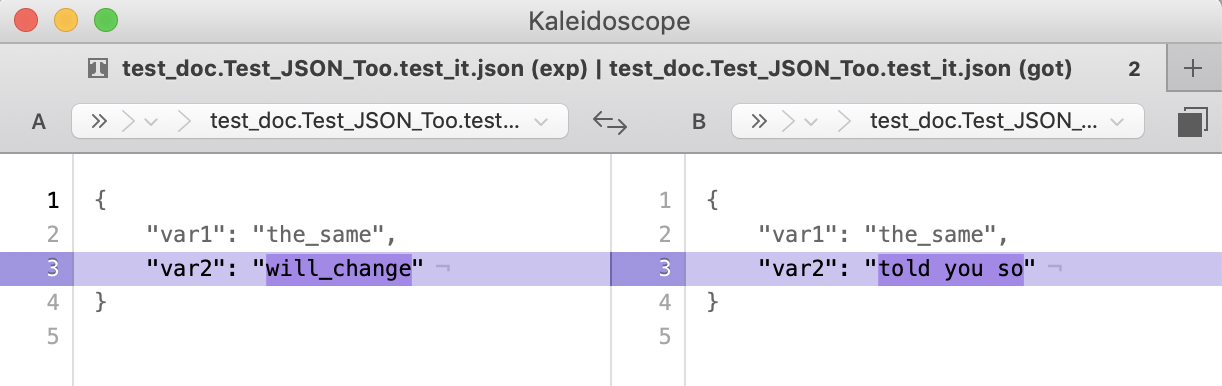
You can, of course, view differences in diff-type tools:
YAML:
E Original exception:
E 'var1: the_same\nvar2: will_change' != 'var1: the_same\nvar2: told you so'
E var1: the_same
E - var2: will_change+ var2: told you so
E ❌❌❌
../lazy_regression_tests/lazy3/core.py:498: AssertionError
======================================== short test summary info =========================================
FAILED test_doc.py::Test_YAML::test_it - AssertionError:
Filter JSON/YAML data:
class Test_JSON_Filter(Test_JSON_Too):
""" let's fix the above error by filtering out the changing key"""
cls_filters = dict(
json=FilterDirective(
"changing",
# DictFilter work by looking for matching keys in the target dictionary.
# and then call their value if it's a callable.
# value=None is the default behavior and just deletes the key in the target
# 👇
DictFilter(dict(var2=None), "changing"))
)
fixed:
(venv) jluc@exp$ pytest -q $v3oiut::Test_JSON_Filter
. [100%]
1 passed in 0.23s
You can even look at arbitrary object graphs
(As long as it is YAML-serializable)
class Subvar:
def __init__(self, value):
self.value = value
class SomethingToTest:
def __init__(self):
self.var1 = 11
self.var2 = 12
self.var4 = dict(FF="Fantastic")
class Test_YAML_Graphs(Test_YAML):
def test_going_down_the_rabbit_hole(self, data={}):
""" fetch data, run validations, regression test """
try:
from yaml import dump as ydump, load as yload
somethingtotest = SomethingToTest()
somethingtotest.var3 = Subvar("3")
yaml_ = ydump(somethingtotest)
#probably not a good idea with untrusted data
data = yload(yaml_)
self.assert_exp(data, self.extension)
somethingtotest.added_this = dict(somevar="somevalue")
somethingtotest.var3.value="3++"
yaml_ = ydump(somethingtotest)
data = yload(yaml_)
self.assert_exp(data, self.extension)
except (Exception,) as e:
raise
Yay! An error.
E + added_this:
E + somevar: somevalue
E var1: 11
E var2: 12
E var3: !!python/object:tests.test_doc.Subvar
E - value: '3'
E ? - ^
E + value: 3++
E ? ^^
E var4:
E FF: Fantastic
E ❌❌❌
../lazy_regression_tests/lazy3/core.py:498: AssertionError
======================================== short test summary info =========================================
FAILED test_doc.py::Test_YAML_Graphs::test_going_down_the_rabbit_hole - AssertionError:
1 failed in 0.33s
Full test code:
Each module needs to define a base mixin to add the lazy-test behavior. To support saving files according to the module name, this needs to be done once for each test module. The test method, test_it was added to this class here, but only because its pretty generic at this point.
class LazyMixinBasic(LazyMixin):
""" base Mixin class for the lazy test framework """
# 👇 ⚙️ tracks where expectation and received files are saved
lazy_filename = LazyMixin.get_basename(__name__, __file__, __module__)
extension = "html"
# 👇 ⚙️ Tells the framework what extensions/content to expect
cls_filters = dict(html=HtmlFilterManager())
#.... cut out the test_it() method... we've seen it befor...
class Test_Features(Helper, HTMLValidationMixin, LazyMixinBasic, unittest.TestCase):
""" this is the test we are running here """
cls_filters = dict(html=filter_variables) # 👈 This is how we add the filters
name = "Mr. Rabbit"
line1 = "Item 1"
line2 = "Item 2"
line3 = "Item 3"
# 👇 setting up the validations
cls_validators = [
ValidationDirective("title", exp="Your order"),
ValidationDirective("name", exp=AutoExp, validator=CSSValidator("#name")),
]
# the template used to generate the fake html
template = """
<title>Your order</title>
<script>
const csrf_token = '{{csrf}}';
</script>
<body>
Hi <span id="name">{{ name }}</span> !<br/>
It is now<span class="timestamp">{{ timestamp }}</span>.<br/>
Your order is:
<ul>
<li class="orderline">{{line1}}</li>
<li class="orderline">{{line2}}</li>
<li class="orderline">{{line3}}</li>
</ul>
</body>
"""
@unittest.skipUnless(False, "this is an intentional failure")
class Test_Features_Regex(Test_Features):
""" This should fail """
cls_validators = [ # 👇 #👇
ValidationDirective(
"item", exp=re.compile("^Item"), validator=CSSValidator("li.orderline")
)
]
name = "Mr. Rabbit"
line1 = "Item 1"
line2 = "Item 2"
line3 = "Bad line 3"
======= History
0.1.0 (2018-07-09)
- package created
0.2.0 (2019-08-14)
- First release on PyPI.
0.2.1 (2019-08-15)
- fixed the bad urls from lazy_regression_tests to lazy-regression-tests. Github link should work now
0.2.3 (2019-08-18)
- updated README.md
0.5.4 (2020-03-03)
- updated README.md
- reworked architecture around FilterDirectives and ValidationDirectives, with a metaclass to provide class inheritance
- better tests and test coverage


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file lazy_regression_tests-0.5.4.tar.gz.
File metadata
- Download URL: lazy_regression_tests-0.5.4.tar.gz
- Upload date:
- Size: 288.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.23.0 setuptools/40.6.2 requests-toolbelt/0.9.1 tqdm/4.43.0 CPython/3.6.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
54ef3be40d6da057fa0eb83eedad95d68cd96371139817bab8e283fd2e7f7b75
|
|
| MD5 |
423a0fccbf51e44a98b7640ac8754c6f
|
|
| BLAKE2b-256 |
3fc069bb082366d210fc86ba1f38fff8729e902ec18f396b9157af9d6d08f755
|







