A wrapper around numpy that does lazy evaluations to optimize for chained matrix multiplication

Project description


lazynumpy
a lazy evaluated wrapper around numpy
What is gained?
- Chained matrix multiplication will be minimized by keeping the values of the other arrays in memory and solving the associative problem that minimizes the number of computations.
- only keeps one copy of each matrix [Memory optimization in progress]
- Allow partial matrix returns withou calculating the entire matrix [In Progress]
If you have three matrices with dimensions as below there are two ways to do the matrix multiplication to find the answer:
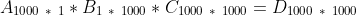
Either:
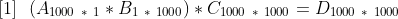
or
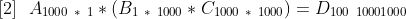
[1] will take 1000 * 1 * 1000 operations to calculate A * B plus 1000 * 1000 * 1000 operations to calculate (A * B) * C. The total sum to calculate A * B * C is equal to 1000^3 + 1000^2.
[2] will take 1 * 1000 * 1000 operations to calculate B * C plus 1000 * 1 * 1000 operations to calculate A * (B * C). The total sum to calculate A * B * C is equal to 1000^2 + 1000^2 which means the optimal multiplication order will be ~500 faster.
If you run the simple example you should see a significant speed up. On my computer there is a 50x speedup with only three matrix calculations.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lazynumpy-0.0.1.tar.gz.
File metadata
- Download URL: lazynumpy-0.0.1.tar.gz
- Upload date:
- Size: 5.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.6.3 requests-toolbelt/0.8.0 tqdm/4.29.1 CPython/3.7.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
02b44607b7070bb02e769962a818bbeed7c2be1b1ca333227d8a90f2c90c9f01
|
|
| MD5 |
a9e6556176f035128ab0ad2891817698
|
|
| BLAKE2b-256 |
d6fcdc9cfc701faa2b080da06ba62c2fddff00e6041928de86c15fa5cb8e128d
|
File details
Details for the file lazynumpy-0.0.1-py3-none-any.whl.
File metadata
- Download URL: lazynumpy-0.0.1-py3-none-any.whl
- Upload date:
- Size: 8.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.6.3 requests-toolbelt/0.8.0 tqdm/4.29.1 CPython/3.7.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
be3bc493a48ed1e580f60ffaf1579da58f3fd27934952b80bfc053e9c6758458
|
|
| MD5 |
a96d43eb047bea30b9cfd5795e4416e0
|
|
| BLAKE2b-256 |
f55871b57c8d75bd4a95d882fe4e64e1d69d16aa34bd77c763e88ecd40718ae3
|







