Logically-Constrained Reinforcement Learning

Project description



LCRL
Logically-Constrained Reinforcement Learning (LCRL) is a model-free reinforcement learning framework to synthesise policies for unknown, continuous-state-action Markov Decision Processes (MDPs) under a given Linear Temporal Logic (LTL) property. LCRL automatically shapes a synchronous reward function on-the-fly. This enables any off-the-shelf RL algorithm to synthesise policies that yield traces which probabilistically satisfy the LTL property. LCRL produces policies that are certified to satisfy the given LTL property with maximum probability.
Publications
LCRL Tool Paper:
- Hasanbeig, H., Kroening, D., Abate, A., "LCRL: Certified Policy Synthesis via Logically-Constrained Reinforcement Learning", QEST, 2022. [PDF]
LCRL Foundations:
- Mitta, R., Hasanbeig, H., Wang, J., Kroening, D., Kantaros, Y., Abate, A., "Safeguarded Progress in Reinforcement Learning: Safe Bayesian Exploration for Control Policy Synthesis", AAAI Special Track on Safe, Robust and Responsible AI, 2024. [PDF]
- Hasanbeig, H. , Abate, A. and Kroening, D., "Cautious Reinforcement Learning with Logical Constraints", International Conference on Autonomous Agents and Multi-agent Systems, 2020. [PDF]
- Hasanbeig, H. , Kroening, D. and Abate, A., "Deep Reinforcement Learning with Temporal Logics", International Conference on Formal Modeling and Analysis of Timed Systems, 2020. [PDF]
- Hasanbeig, H. , Kroening, D. and Abate, A., "Towards Verifiable and Safe Model-Free Reinforcement Learning", Workshop on Artificial Intelligence and Formal Verification, Logics, Automata and Synthesis (OVERLAY), 2020. [PDF]
- Hasanbeig, H. , Kantaros, Y., Abate, A., Kroening, D., Pappas, G. J., and Lee, I., "Reinforcement Learning for Temporal Logic Control Synthesis with Probabilistic Satisfaction Guarantees", IEEE Conference on Decision and Control, 2019. [PDF]
- Hasanbeig, H. , Abate, A. and Kroening, D., "Logically-Constrained Neural Fitted Q-Iteration", International Conference on Autonomous Agents and Multi-agent Systems, 2019. [PDF]
- Lim Zun Yuan, Hasanbeig, H. , Abate, A. and Kroening, D., "Modular Deep Reinforcement Learning with Temporal Logic Specifications", CoRR abs/1909.11591, 2019. [PDF]
- Hasanbeig, H. , Abate, A. and Kroening, D., "Certified Reinforcement Learning with Logic Guidance", CoRR abs/1902.00778, 2019. [PDF]
- Hasanbeig, H. , Abate, A. and Kroening, D., "Logically-Constrained Reinforcement Learning", CoRR abs/1801.08099, 2018. [PDF]
Installation
You can install LCRL using
pip3 install lcrl
Alternatively, you can clone this repository and install the dependencies:
git clone https://github.com/grockious/lcrl.git
cd lcrl
pip3 install .
or
pip3 install git+https://github.com/grockious/lcrl.git
Usage
Training an RL agent under an LTL property
Sample training commands can be found under the ./scripts directory. LCRL consists of three main classes MDP, the LDBA automaton and the core training algorithm. Inside LCRL, the MDP state and the LDBA state are automatically synchronised, resulting in an on-the-fly product MDP structure.
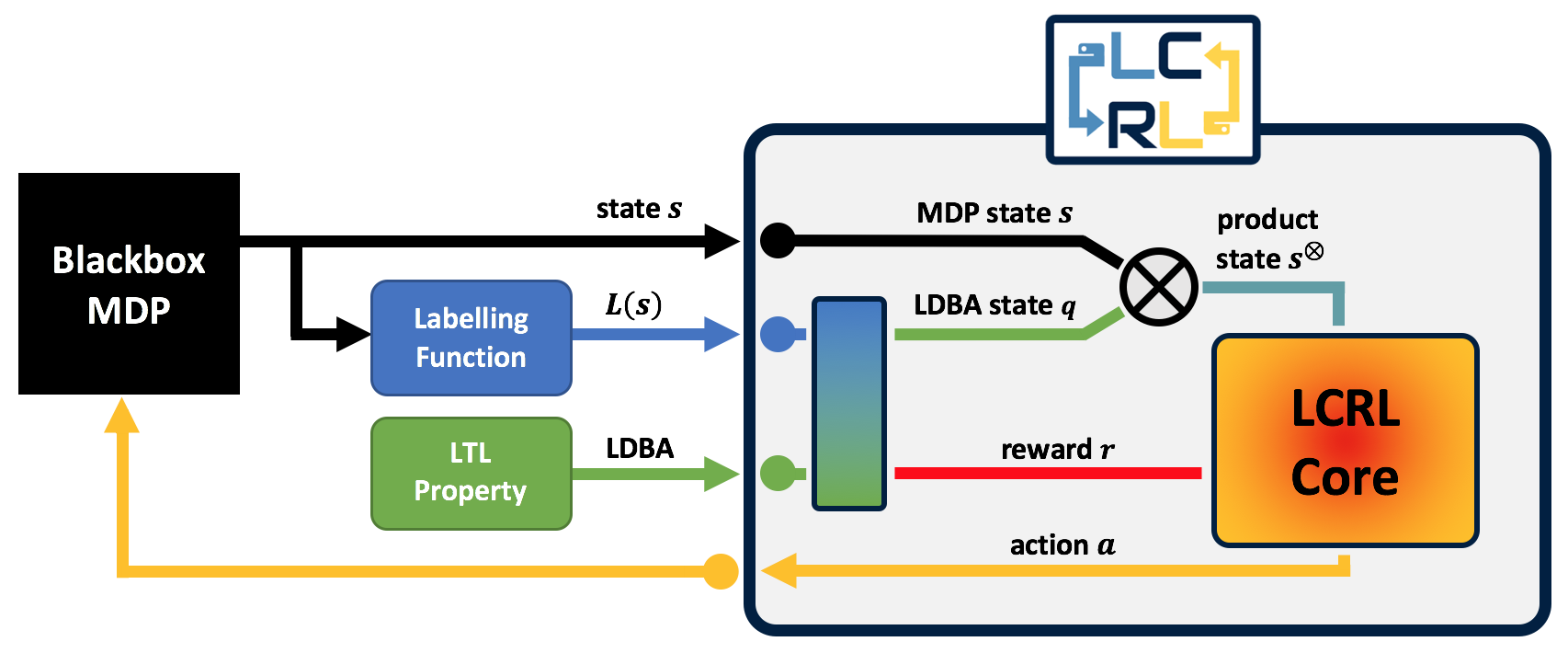
Over the product MDP, LCRL shapes a reward function based on the LDBA object. An optimal stationary Markov policy synthesised by LCRL on the product
MDP is guaranteed to induce a finite-memory policy on the original MDP that maximises the probability of satisfying the given LTL property.
The package includes a number of pre-built MDP and LDBA class objects. A set of instances of the MDP and LDBA classes
are available in lcrl.environments and lcrl.automata, respectively. As an example, to train an agent for minecraft-t1 (Table 2 in the tool paper) run:
python3
>>> # import LCRL code trainer module
>>> from lcrl.train import train
>>> # import the pre-built LDBA for minecraft-t1
>>> from lcrl.automata.minecraft_1 import minecraft_1
>>> # import the pre-built MDP for minecraft-t1
>>> from lcrl.environments.minecraft import minecraft
>>>
>>> LDBA = minecraft_1
>>> MDP = minecraft
>>>
>>> # train the agent
>>> task = train(MDP, LDBA,
algorithm='ql',
episode_num=500,
iteration_num_max=4000,
discount_factor=0.95,
learning_rate=0.9
)
Applying LCRL to a custom black-box MDP and a custom LTL property
- MDP:
LCRL can be connected to a black-box MDP object that is fully unknown to
the tool. This includes the size of the state space as LCRL automatically keeps track of the visited states. Following the OpenAI's convention, the MDP object, call it MDP, should at
least have the following methods:
MDP.reset()
to reset the MDP state,
MDP.step(action)
to change the state of the MDP upon executing action,
MDP.state_label(state)
to output the label of state.
- LTL:
The LTL property has to be converted to an LDBA, which is a finite-state machine.
An excellent tool for this is OWL, which you can try online.
The synthesised LDBA can be used as an object of the class lcrl.automata.ldba.
The constructed LDBA, call it LDBA, is expected to offer the following methods:
LDBA.reset()
to reset the automaton state and its accepting frontier function,
LDBA.step(label)
to change the state of the automaton upon reading label,
LDBA.accepting_frontier_function(state)
to update the accepting frontier set. This method is already included in the class lcrl.automata.ldba, thus for a custom LDBA object you only need to instance this class and specify the reset() and step(label) methods.
Reference
Please cite our tool paper and this repository if you use LCRL in your publications:
@inproceedings{lcrl_tool_paper,
title={{LCRL}: Certified Policy Synthesis via Logically-Constrained Reinforcement Learning},
author={Hasanbeig, Hosein and Kroening, Daniel and Abate, Alessandro},
booktitle={International Conference on Quantitative Evaluation of SysTems},
year={2022},
organization={Springer}
}
@misc{lcrl_repo,
title={Logically-Constrained Reinforcement Learning Code Repository},
author={Hasanbeig, Hosein and Kroening, Daniel and Abate, Alessandro},
year={2022}
}
License
This project is licensed under the terms of the MIT License


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lcrl-0.0.9.2.tar.gz.
File metadata
- Download URL: lcrl-0.0.9.2.tar.gz
- Upload date:
- Size: 301.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
51837eb380c465806bbb70d0a4444e3a662e72c8155136f4c5afd3a59d57c211
|
|
| MD5 |
cf433d5d2dcdef017a008c8d31230310
|
|
| BLAKE2b-256 |
ae110c8a79b0b7d5768f3cb3cef7cc2a834793ebdc0ae700987990bc46868d10
|
File details
Details for the file lcrl-0.0.9.2-py3-none-any.whl.
File metadata
- Download URL: lcrl-0.0.9.2-py3-none-any.whl
- Upload date:
- Size: 57.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c66fbcc35029e08d37542b2d37055fc2b21843956519f67655e3fa5803c034ed
|
|
| MD5 |
419968bed03ddb4e4d482ba0f583abe2
|
|
| BLAKE2b-256 |
5d82c495d18e6f5a339b00be506a19486cecc815ca1ea591adfa9a7375038490
|







