🔥LIT: The Learning Interpretability Tool






Project description
🔥 Learning Interpretability Tool (LIT)
The Learning Interpretability Tool (🔥LIT, formerly known as the Language Interpretability Tool) is a visual, interactive ML model-understanding tool that supports text, image, and tabular data. It can be run as a standalone server, or inside of notebook environments such as Colab, Jupyter, and Google Cloud Vertex AI notebooks.
LIT is built to answer questions such as:
- What kind of examples does my model perform poorly on?
- Why did my model make this prediction? Can this prediction be attributed to adversarial behavior, or to undesirable priors in the training set?
- Does my model behave consistently if I change things like textual style, verb tense, or pronoun gender?
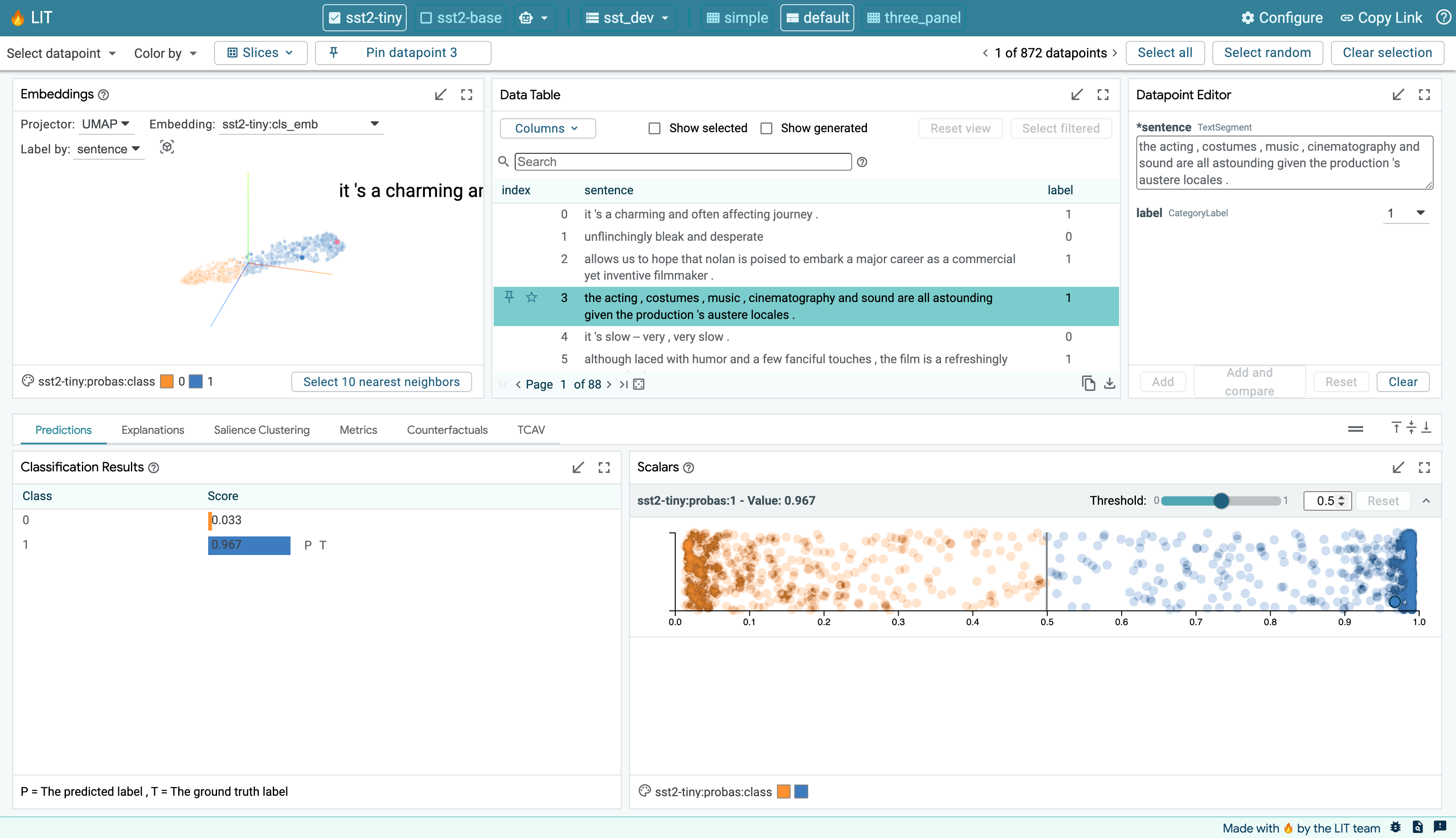
LIT supports a variety of debugging workflows through a browser-based UI. Features include:
- Local explanations via salience maps and rich visualization of model predictions.
- Aggregate analysis including custom metrics, slicing and binning, and visualization of embedding spaces.
- Counterfactual generation via manual edits or generator plug-ins to dynamically create and evaluate new examples.
- Side-by-side mode to compare two or more models, or one model on a pair of examples.
- Highly extensible to new model types, including classification, regression, span labeling, seq2seq, and language modeling. Supports multi-head models and multiple input features out of the box.
- Framework-agnostic and compatible with TensorFlow, PyTorch, and more.
LIT has a website with live demos, tutorials, a setup guide and more.
Stay up to date on LIT by joining the lit-announcements mailing list.
For a broader overview, check out our paper and the user guide.
Documentation
Download and Installation
LIT can be installed via pip or built from source. Building from source is
necessary if you want to make code changes.
Install from PyPI with pip
pip install lit-nlp
The default pip installation will install all required packages to use the LIT
Python API, built-in interpretability components, and web application. To
install dependencies for the provided demos or test suite, install LIT with the
appropriate optional dependencies.
# To install dependencies for the discriminative AI examples (GLUE, Penguin)
pip install 'lit-nlp[examples-discriminative-ai]'
# To install dependencies for the generative AI examples (Prompt Debugging)
pip install 'lit-nlp[examples-generative-ai]'
# To install dependencies for all examples plus the test suite
pip install 'lit-nlp[test]'
Install from source
Clone the repo:
git clone https://github.com/PAIR-code/lit.git
cd lit
Note: be sure you are running Python 3.9+. If you have a different version on
your system, use the conda instructions below to set up a Python 3.9
environment.
Set up a Python environment with venv (or your preferred environment manager).
Note that these instructions assume you will be making code changes to LIT and
includes the full requirements for all examples and the test suite. See the
other optional dependency possibilities in the install with pip section.
python -m venv .venv
source .venv/bin/activate
python -m pip install -e '.[test]'
The LIT repo does not include a distributable version of the LIT app. You must build it from source.
(cd lit_nlp; yarn && yarn build)
Note: if you see an error
running yarn on Ubuntu/Debian, be sure you have the
correct version installed.
Running LIT
Explore a collection of hosted demos on the demos page.
Using container images
See the containerization guide for instructions on using LIT locally in Docker, Podman, etc.
LIT also provides pre-built images that can take advantage of accelerators, making Generative AI and LLM use cases easier to work with. Check out the LIT on GCP docs for more.
Quick-start: classification and regression
To explore classification and regression models tasks from the popular GLUE benchmark:
python -m lit_nlp.examples.glue.demo --port=5432 --quickstart
Navigate to http://localhost:5432 to access the LIT UI.
Your default view will be a small BERT-based model fine-tuned on the Stanford Sentiment Treebank, but you can switch to STS-B or MultiNLI using the toolbar or the gear icon in the upper right.
And navigate to http://localhost:5432 for the UI.
Notebook usage
Colab notebooks showing the use of LIT inside of notebooks can be found at lit_nlp/examples/notebooks.
We provide a simple Colab demo. Run all the cells to see LIT on an example classification model in the notebook.
More Examples
See lit_nlp/examples. Most are run similarly to the quickstart example above:
python -m lit_nlp.examples.<example_name>.demo --port=5432 [optional --args]
User Guide
To learn about LIT's features, check out the user guide, or watch this video.
Adding your own models or data
You can easily run LIT with your own model by creating a custom demo.py
launcher, similar to those in lit_nlp/examples. The
basic steps are:
- Write a data loader which follows the
DatasetAPI - Write a model wrapper which follows the
ModelAPI - Pass models, datasets, and any additional components to the LIT server class
For a full walkthrough, see adding models and data.
Extending LIT with new components
LIT is easy to extend with new interpretability components, generators, and more, both on the frontend or the backend. See our documentation to get started.
Pull Request Process
To make code changes to LIT, please work off of the dev branch and
create pull requests
(PRs) against that branch. The main branch is for stable releases, and it is
expected that the dev branch will always be ahead of main.
Draft PRs are encouraged, especially for first-time contributors or contributors working on complex tasks (e.g., Google Summer of Code contributors). Please use these to communicate ideas and implementations with the LIT team, in addition to issues.
Prior to sending your PR or marking a Draft PR as "Ready for Review", please run the Python and TypeScript linters on your code to ensure compliance with Google's Python and TypeScript Style Guides.
# Run Pylint on your code using the following command from the root of this repo
(cd lit_nlp; pylint)
# Run ESLint on your code using the following command from the root of this repo
(cd lit_nlp; yarn lint)
Citing LIT
If you use LIT as part of your work, please cite the EMNLP paper or the Sequence Salience paper
@misc{tenney2020language,
title={The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for {NLP} Models},
author={Ian Tenney and James Wexler and Jasmijn Bastings and Tolga Bolukbasi and Andy Coenen and Sebastian Gehrmann and Ellen Jiang and Mahima Pushkarna and Carey Radebaugh and Emily Reif and Ann Yuan},
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
year = "2020",
publisher = "Association for Computational Linguistics",
pages = "107--118",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.15",
}
@article{tenney2024interactive,
title={Interactive prompt debugging with sequence salience},
author={Tenney, Ian and Mullins, Ryan and Du, Bin and Pandya, Shree and Kahng, Minsuk and Dixon, Lucas},
journal={arXiv preprint arXiv:2404.07498},
year={2024}
}
Disclaimer
This is not an official Google product.
LIT is a research project and under active development by a small team. We want LIT to be an open platform, not a walled garden, and would love your suggestions and feedback – please report any bugs and reach out on the Discussions page.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lit_nlp-1.3.1.tar.gz.
File metadata
- Download URL: lit_nlp-1.3.1.tar.gz
- Upload date:
- Size: 11.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.10.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7e9e5d7fcdf614106e96a3fb0c2ce1f2a34b4f225aeee589a267bbbb0fce84e2
|
|
| MD5 |
0db4657c107951a3987194db03e0460a
|
|
| BLAKE2b-256 |
422c53efdcf6b7859218d996d6df5f84a471fc1c52ec701cf4212059927d4058
|
File details
Details for the file lit_nlp-1.3.1-py3-none-any.whl.
File metadata
- Download URL: lit_nlp-1.3.1-py3-none-any.whl
- Upload date:
- Size: 11.8 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.10.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a904081b1588c79a480acbc09fa64a30973821082e6d05c4c04c03409fffee29
|
|
| MD5 |
f7e07bc6cda3d503cee7ecfa8c5a6639
|
|
| BLAKE2b-256 |
41a4dc87479c9abdaf29e77345b2cc3e678340577d8d97f25f7fdcd7f8130600
|







