A framework for evaluating large multi-modality language models
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

LMMs-Eval: Probing Intelligence in the Real World





We are building the unified evaluation toolkit for frontier models and probing the abilities in real world, shape what we build next.
🌐 Available in 17 languages
简体中文 | 繁體中文 | 日本語 | 한국어 | Español | Français | Deutsch | Português | Русский | Italiano | Nederlands | Polski | Türkçe | العربية | हिन्दी | Tiếng Việt | Indonesia
📚 Documentation | 📖 100+ Tasks | 🌟 30+ Models | ⚡ Quickstart
🏠 Homepage | 💬 Discord | 🤝 Contributing
Why lmms-eval?
Benchmarks decide what gets built next. A model team that trusts its eval numbers can focus on real improvements instead of chasing noise. But the multimodal evaluation ecosystem is fragmented - scattered datasets, inconsistent post-processing, and single-number accuracy scores that hide whether a gain is real or random. Two teams evaluating the same model on the same benchmark routinely report different results.
We believe better evals lead to better models. Good evaluation maps the border of what models can do and shapes what we build next.
We are building lmms-eval and focusing on three core principles:
- Reproducible - One pipeline, deterministic results. Same model, same benchmark, same numbers, every time.
- Efficient - Evaluation should not be the bottleneck, even at large scale. Async serving, adaptive batching, and video I/O optimizations keep your GPUs saturated end to end.
- Trustworthy - Not just accuracy. Confidence intervals, clustered standard errors, paired comparisons, and ongoing research into evaluation methodology. Results you can trust enough to act on.
For how the pipeline works and the concrete mechanisms behind these principles, see How the Evaluation Pipeline Works and Why it's Efficient and Trustworthy.
What's New
v0.7 (Feb 2026) - Operational simplicity and pipeline maturity. 25+ new tasks across 8 domains, 2 new model backends, agentic task evaluation (generate_until_agentic), video I/O overhaul with TorchCodec (up to 3.58x faster), Lance-backed video distribution on Hugging Face, safety/red-teaming baselines, efficiency metrics (per-sample token counts, run-level throughput), and streamlined flattened JSONL log output for cleaner post-analysis. Release notes | Changelog.
v0.6 (Feb 2026) - Evaluation as a service. Standalone HTTP eval server, ~7.5x throughput over v0.5, statistically grounded results (CI, paired t-test), 50+ new tasks. Release notes | Changelog.
v0.5 (Oct 2025) - Audio expansion. Comprehensive audio evaluation, response caching, 50+ benchmark variants across audio, vision, and reasoning. Release notes.
Older updates
- [2025-01] Video-MMMU - Knowledge acquisition from multi-discipline professional videos.
- [2024-12] MME-Survey - Comprehensive survey on evaluation of multimodal LLMs.
- [2024-11] v0.3 - Audio evaluation support (Qwen2-Audio, Gemini-Audio). Release notes.
- [2024-06] v0.2 - Video evaluation (LLaVA-NeXT Video, Gemini 1.5 Pro, VideoMME, EgoSchema). Blog.
- [2024-03] v0.1 - First release. Blog.
Quickstart
Install and run your first evaluation in under 5 minutes:
git clone https://github.com/EvolvingLMMs-Lab/lmms-eval.git
cd lmms-eval && uv pip install -e ".[all]"
# Run a quick evaluation (Qwen2.5-VL on MME, 8 samples)
python -m lmms_eval \
--model qwen2_5_vl \
--model_args pretrained=Qwen/Qwen2.5-VL-3B-Instruct \
--tasks mme \
--batch_size 1 \
--limit 8
If it prints metrics, your environment is ready. For the full guide, see docs/getting-started/quickstart.md.
Installation
Using uv (Recommended for consistent environments)
We use uv for package management to ensure all developers use exactly the same package versions. First, install uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
For development with consistent environment:
git clone https://github.com/EvolvingLMMs-Lab/lmms-eval
cd lmms-eval
# Recommend
uv pip install -e ".[all]"
# If you want to use uv sync
# uv sync # This creates/updates your environment from uv.lock
To run commands:
uv run python -m lmms_eval --help # Run any command with uv run
To add new dependencies:
uv add <package> # Updates both pyproject.toml and uv.lock
Alternative Installation
For direct usage from Git:
uv venv eval
uv venv --python 3.12
source eval/bin/activate
# You might need to add and include your own task yaml if using this installation
uv pip install git+https://github.com/EvolvingLMMs-Lab/lmms-eval.git
Reproduction of LLaVA-1.5's paper results
You can check the torch environment info and results check to reproduce LLaVA-1.5's paper results. We found torch/cuda versions difference would cause small variations in the results.
If you want to test on caption dataset such as coco, refcoco, and nocaps, you will need to have java==1.8.0 to let pycocoeval api to work. If you don't have it, you can install by using conda
conda install openjdk=8
you can then check your java version by java -version
Comprehensive Evaluation Results of LLaVA Family Models
As demonstrated by the extensive table below, we aim to provide detailed information for readers to understand the datasets included in lmms-eval and some specific details about these datasets (we remain grateful for any corrections readers may have during our evaluation process).
We provide a Google Sheet for the detailed results of the LLaVA series models on different datasets. You can access the sheet here. It's a live sheet, and we are updating it with new results.
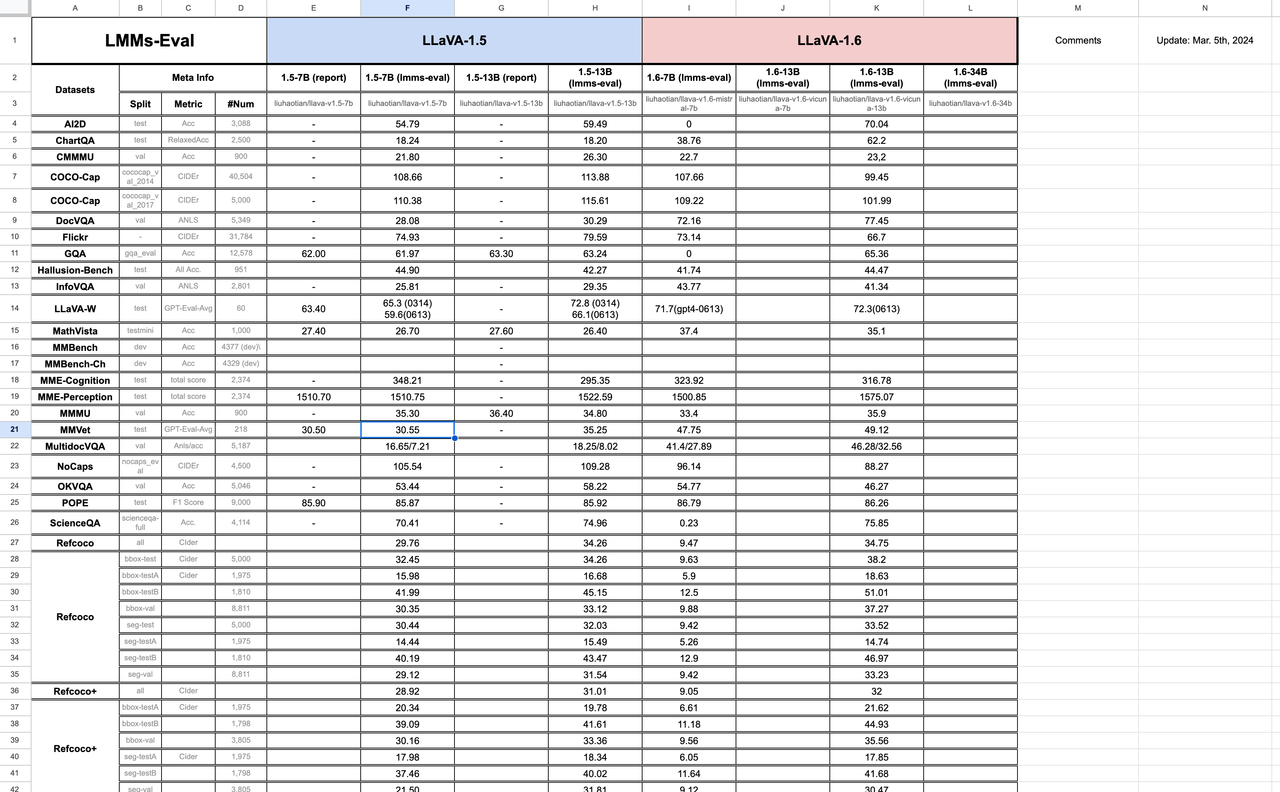
We also provide the raw data exported from Weights & Biases for the detailed results of the LLaVA series models on different datasets. You can access the raw data here.
If you want to test VILA, you should install the following dependencies:
pip install s2wrapper@git+https://github.com/bfshi/scaling_on_scales
Our Development will be continuing on the main branch, and we encourage you to give us feedback on what features are desired and how to improve the library further, or ask questions, either in issues or PRs on GitHub.
Usage Examples
More examples can be found in examples/models
Evaluation with vLLM
Qwen2.5-VL:
bash examples/models/vllm_qwen2vl.sh
Qwen3-VL:
bash examples/models/vllm_qwen3vl.sh
Qwen3.5:
bash examples/models/vllm_qwen35.sh
Evaluation with SGLang
bash examples/models/sglang.sh
Qwen3.5:
bash examples/models/sglang_qwen35.sh
Evaluation of OpenAI-Compatible Model
bash examples/models/openai_compatible.sh
Evaluation of Qwen2.5-VL
bash examples/models/qwen25vl.sh
Evaluation of Qwen3-VL
bash examples/models/qwen3vl.sh
More Parameters
python3 -m lmms_eval --help
Environmental Variables
Before running experiments and evaluations, we recommend you to export following environment variables to your environment. Some are necessary for certain tasks to run.
export OPENAI_API_KEY="<YOUR_API_KEY>"
export HF_HOME="<Path to HF cache>"
export HF_TOKEN="<YOUR_API_KEY>"
export HF_HUB_ENABLE_HF_TRANSFER="1"
export REKA_API_KEY="<YOUR_API_KEY>"
# Other possible environment variables include
# ANTHROPIC_API_KEY,DASHSCOPE_API_KEY etc.
Common Environment Issues
Sometimes you might encounter some common issues for example error related to httpx or protobuf. To solve these issues, you can first try
python3 -m pip install httpx==0.23.3;
python3 -m pip install protobuf==3.20;
# If you are using numpy==2.x, sometimes may causing errors
python3 -m pip install numpy==1.26;
# Someties sentencepiece are required for tokenizer to work
python3 -m pip install sentencepiece;
Custom Model Integration
lmms-eval supports two types of models: Chat (recommended) and Simple (legacy).
Chat Models (Recommended) 🌟
- Location:
lmms_eval/models/chat/ - Use:
doc_to_messagesfunction from task - Input: Structured
ChatMessageswith roles (user,system,assistant) and content types (text,image,video,audio) - Supports: Interleaved multimodal content
- Uses: Model's
apply_chat_template()method - Reference:
lmms_eval/models/chat/qwen2_5_vl.pyorlmms_eval/models/chat/qwen3_vl.py
Example input format:
[
{"role": "user", "content": [
{"type": "image", "url": <image>},
{"type": "text", "text": "What's in this image?"}
]}
]
Simple Models (Legacy)
- Location:
lmms_eval/models/simple/ - Use:
doc_to_visual+doc_to_textfunctions from task - Input: Plain text with
<image>placeholders + separate visual list - Supports: Limited (mainly images)
- Manual processing: No chat template support
- Reference:
lmms_eval/models/simple/instructblip.py
Example input format:
# Separate visual and text
doc_to_visual -> [PIL.Image]
doc_to_text -> "What's in this image?"
Key Differences
| Aspect | Chat Models | Simple Models |
|---|---|---|
| File location | models/chat/ |
models/simple/ |
| Input method | doc_to_messages |
doc_to_visual + doc_to_text |
| Message format | Structured (roles + content types) | Plain text with placeholders |
| Interleaved support | ✅ Yes | ❌ Limited |
| Chat template | ✅ Built-in | ❌ Manual/None |
| Recommendation | Use this | Legacy only |
Why Use Chat Models?
- ✅ Built-in chat template support
- ✅ Interleaved multimodal content
- ✅ Structured message protocol
- ✅ Better video/audio support
- ✅ Consistent with modern LLM APIs
Chat Model Implementation Example
from lmms_eval.api.registry import register_model
from lmms_eval.api.model import lmms
from lmms_eval.protocol import ChatMessages
@register_model("my_chat_model")
class MyChatModel(lmms):
is_simple = False # Use chat interface
def generate_until(self, requests):
for request in requests:
# 5 elements for chat models
doc_to_messages, gen_kwargs, doc_id, task, split = request.args
# Get structured messages
raw_messages = doc_to_messages(self.task_dict[task][split][doc_id])
messages = ChatMessages(messages=raw_messages)
# Extract media and apply chat template
images, videos, audios = messages.extract_media()
hf_messages = messages.to_hf_messages()
text = self.processor.apply_chat_template(hf_messages)
# Generate...
For more details, see the Model Guide.
Custom Dataset Integration
Task Configuration with doc_to_messages
Implement doc_to_messages to transform dataset documents into structured chat messages:
def my_doc_to_messages(doc, lmms_eval_specific_kwargs=None):
# Extract visuals and text from doc
visuals = my_doc_to_visual(doc)
text = my_doc_to_text(doc, lmms_eval_specific_kwargs)
# Build structured messages
messages = [{"role": "user", "content": []}]
# Add visuals first
for visual in visuals:
messages[0]["content"].append({"type": "image", "url": visual})
# Add text
messages[0]["content"].append({"type": "text", "text": text})
return messages
YAML Configuration
task: "my_benchmark"
dataset_path: "my-org/my-dataset"
test_split: test
output_type: generate_until
# For chat models (recommended)
doc_to_messages: !function utils.my_doc_to_messages
# OR legacy approach:
doc_to_visual: !function utils.my_doc_to_visual
doc_to_text: !function utils.my_doc_to_text
process_results: !function utils.my_process_results
metric_list:
- metric: acc
Key Features
doc_to_messages
- Transforms dataset document into structured chat messages
- Returns: List of message dicts with
roleandcontent - Content supports:
text,image,video,audiotypes - Protocol: Defined in
lmms_eval/protocol.py(ChatMessagesclass) - Auto-fallback: If not provided, uses
doc_to_visual+doc_to_text
For more details, see the Task Guide.
Web UI
LMMS-Eval includes an optional Web UI for interactive evaluation configuration.
Requirements
- Node.js 18+ (for building the frontend, auto-built on first run)
Usage
# Start the Web UI (opens browser automatically)
uv run lmms-eval-ui
# Custom port
LMMS_SERVER_PORT=3000 uv run lmms-eval-ui
The web UI provides:
- Model selection from all available models
- Task selection with search/filter
- Real-time command preview
- Live evaluation output streaming
- Start/Stop evaluation controls
- Log Viewer for browsing saved evaluation results and samples
For more details, see Web UI README.
HTTP Evaluation Server
LMMS-Eval includes a production-ready HTTP server for remote evaluation workflows.
Why Use Eval Server?
- Decoupled evaluation: Run evaluations on dedicated GPU nodes while training continues
- Async workflow: Submit jobs without blocking training loops
- Queue management: Sequential job processing with automatic resource management
- Remote access: Evaluate models from any machine
Start Server
from lmms_eval.entrypoints import ServerArgs, launch_server
# Configure server
args = ServerArgs(
host="0.0.0.0",
port=8000,
max_completed_jobs=200,
temp_dir_prefix="lmms_eval_"
)
# Launch server
launch_server(args)
Server runs at http://host:port with auto-generated API docs at /docs
Client Usage
Sync Client:
from lmms_eval.entrypoints import EvalClient
client = EvalClient("http://eval-server:8000")
# Submit evaluation (non-blocking)
job = client.evaluate(
model="qwen2_5_vl",
tasks=["mmmu_val", "mme"],
model_args={"pretrained": "Qwen/Qwen2.5-VL-7B-Instruct"},
num_fewshot=0,
batch_size=1,
device="cuda:0",
)
# Continue training...
# Later, retrieve results
result = client.wait_for_job(job["job_id"])
print(result["result"])
Async Client:
from lmms_eval.entrypoints import AsyncEvalClient
async with AsyncEvalClient("http://eval-server:8000") as client:
job = await client.evaluate(
model="qwen3_vl",
tasks=["mmmu_val"],
model_args={"pretrained": "Qwen/Qwen3-VL-4B-Instruct"},
)
result = await client.wait_for_job(job["job_id"])
Server API Endpoints
| Endpoint | Method | Description |
|---|---|---|
/health |
GET | Server health check |
/evaluate |
POST | Submit evaluation job |
/jobs/{job_id} |
GET | Get job status and results |
/queue |
GET | View queue status |
/tasks |
GET | List available tasks |
/models |
GET | List available models |
/jobs/{job_id} |
DELETE | Cancel queued job |
/merge |
POST | Merge FSDP2 sharded checkpoints |
Example Workflow
# Training loop pseudocode
for epoch in range(num_epochs):
train_one_epoch()
# After every N epochs, evaluate checkpoint
if epoch % 5 == 0:
checkpoint_path = f"checkpoints/epoch_{epoch}"
# Submit async evaluation (non-blocking)
eval_job = client.evaluate(
model="vllm",
model_args={"model": checkpoint_path},
tasks=["mmmu_val", "mathvista"],
)
# Training continues immediately
print(f"Evaluation job submitted: {eval_job['job_id']}")
# After training completes, retrieve all results
results = []
for job_id in eval_jobs:
result = client.wait_for_job(job_id)
results.append(result)
Security Note
⚠️ This server is intended for trusted environments only. Do NOT expose to untrusted networks without additional security layers (authentication, rate limiting, network isolation).
For more details, see the v0.6 release notes.
Frequently Asked Questions
What models does lmms-eval support?
We support 30+ model families out of the box, including Qwen2.5-VL, Qwen3-VL, LLaVA-OneVision, InternVL-2, VILA, and more. Any OpenAI-compatible API endpoint is also supported. See the full list in lmms_eval/models/.
Qwen3.5 is supported through existing runtime backends (--model vllm and --model sglang) by setting model=Qwen/Qwen3.5-397B-A17B in --model_args.
The Qwen3.5 example scripts align with official runtime references (for example, max_model_len/context_length=262144 and reasoning_parser=qwen3).
If a new model family is already fully supported by vLLM or SGLang at runtime, we generally only need documentation and examples instead of adding a dedicated model wrapper.
What benchmarks and tasks are available?
Over 100 evaluation tasks across image, video, and audio modalities, including MMMU, MME, MMBench, MathVista, VideoMME, EgoSchema, and many more. Check docs/advanced/current_tasks.md for the full list.
How do I add my own benchmark?
Create a YAML config under lmms_eval/tasks/ with dataset path, splits, and a doc_to_messages function. See docs/guides/task_guide.md for a step-by-step guide.
Can I evaluate a model behind an API (e.g., GPT-4o, Claude)?
Yes. Use --model openai with --model_args model=gpt-4o and set OPENAI_API_KEY. Any OpenAI-compatible endpoint works, including local vLLM/SGLang servers.
How do I run evaluations on multiple GPUs?
Use accelerate launch or pass --device cuda with tensor parallelism via vLLM/SGLang backends. See docs/getting-started/commands.md for multi-GPU flags.
How do I cite lmms-eval?
Use the BibTeX entries below, or click the "Cite this repository" button in the GitHub sidebar (powered by our CITATION.cff).
Acknowledgement
lmms_eval is a fork of lm-eval-harness. We recommend you to read through the docs of lm-eval-harness for relevant information.
Below are the changes we made to the original API:
- Build context now only pass in idx and process image and doc during the model responding phase. This is due to the fact that dataset now contains lots of images and we can't store them in the doc like the original lm-eval-harness otherwise the cpu memory would explode.
- Instance.args (lmms_eval/api/instance.py) now contains a list of images to be inputted to lmms.
- lm-eval-harness supports all HF language models as single model class. Currently this is not possible of lmms because the input/output format of lmms in HF are not yet unified. Therefore, we have to create a new class for each lmms model. This is not ideal and we will try to unify them in the future.
Citations
@misc{zhang2024lmmsevalrealitycheckevaluation,
title={LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models},
author={Kaichen Zhang and Bo Li and Peiyuan Zhang and Fanyi Pu and Joshua Adrian Cahyono and Kairui Hu and Shuai Liu and Yuanhan Zhang and Jingkang Yang and Chunyuan Li and Ziwei Liu},
year={2024},
eprint={2407.12772},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.12772},
}
@misc{lmms_eval2024,
title={LMMs-Eval: Accelerating the Development of Large Multimoal Models},
url={https://github.com/EvolvingLMMs-Lab/lmms-eval},
author={Bo Li*, Peiyuan Zhang*, Kaichen Zhang*, Fanyi Pu*, Xinrun Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li and Ziwei Liu},
publisher = {Zenodo},
version = {v0.1.0},
month={March},
year={2024}
}
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lmms_eval-0.7.2.tar.gz.
File metadata
- Download URL: lmms_eval-0.7.2.tar.gz
- Upload date:
- Size: 2.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.11.24 {"installer":{"name":"uv","version":"0.11.24","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c3a2e6d412479b0d8ea72d037bd4532534337e1eb33e6d0d3ef468c29d5ed029
|
|
| MD5 |
304fcf3efe933f8401432509897d9319
|
|
| BLAKE2b-256 |
e82b80b1fe95c844f66dfb987868d1d1895e01e6c1ba1baf53d925eba13e5125
|
File details
Details for the file lmms_eval-0.7.2-py3-none-any.whl.
File metadata
- Download URL: lmms_eval-0.7.2-py3-none-any.whl
- Upload date:
- Size: 3.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.11.24 {"installer":{"name":"uv","version":"0.11.24","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fb437fc40064f92e20f752d4d298bf77d72cb30ac9c841f78b6c5126c9bc8bc8
|
|
| MD5 |
0d03425f5ebef7dccc570088509c588f
|
|
| BLAKE2b-256 |
dfd04e556037fb7c1bdf5ab8704fdfc56f12c406023414b6a4e32e135cdf525e
|







