Log pattern analyzer

Project description
logmine - a log pattern analyzer CLI

A command-line tool to help you quickly inspect your log files and identify patterns.
Install
pip install logmine
Usage
cat sample/Apache_2k.log | logmine
logmine helps to cluster the logs into multiple clusters with common patterns
along with the number of messages in each cluster.

You can have more granular clusters by adjusting -m value, the lower the
value, the more details you will get.
cat sample/Apache_2k.log | logmine -m0.2
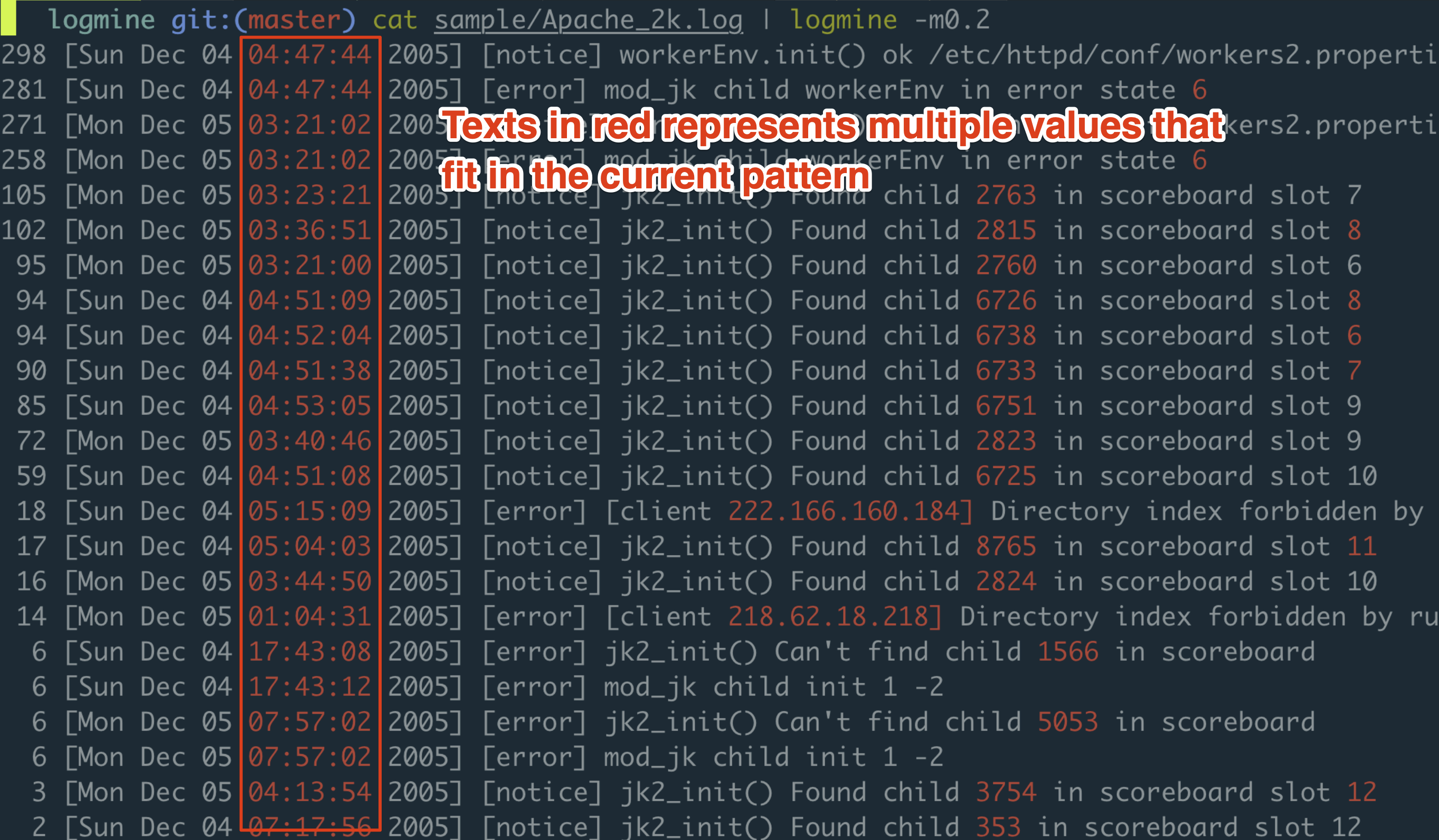
The texts in red are the placeholder for multiple values that fit in the pattern, you can replace those with your own placeholder.
cat sample/Apache_2k.log | logmine -m0.2 -p'---'
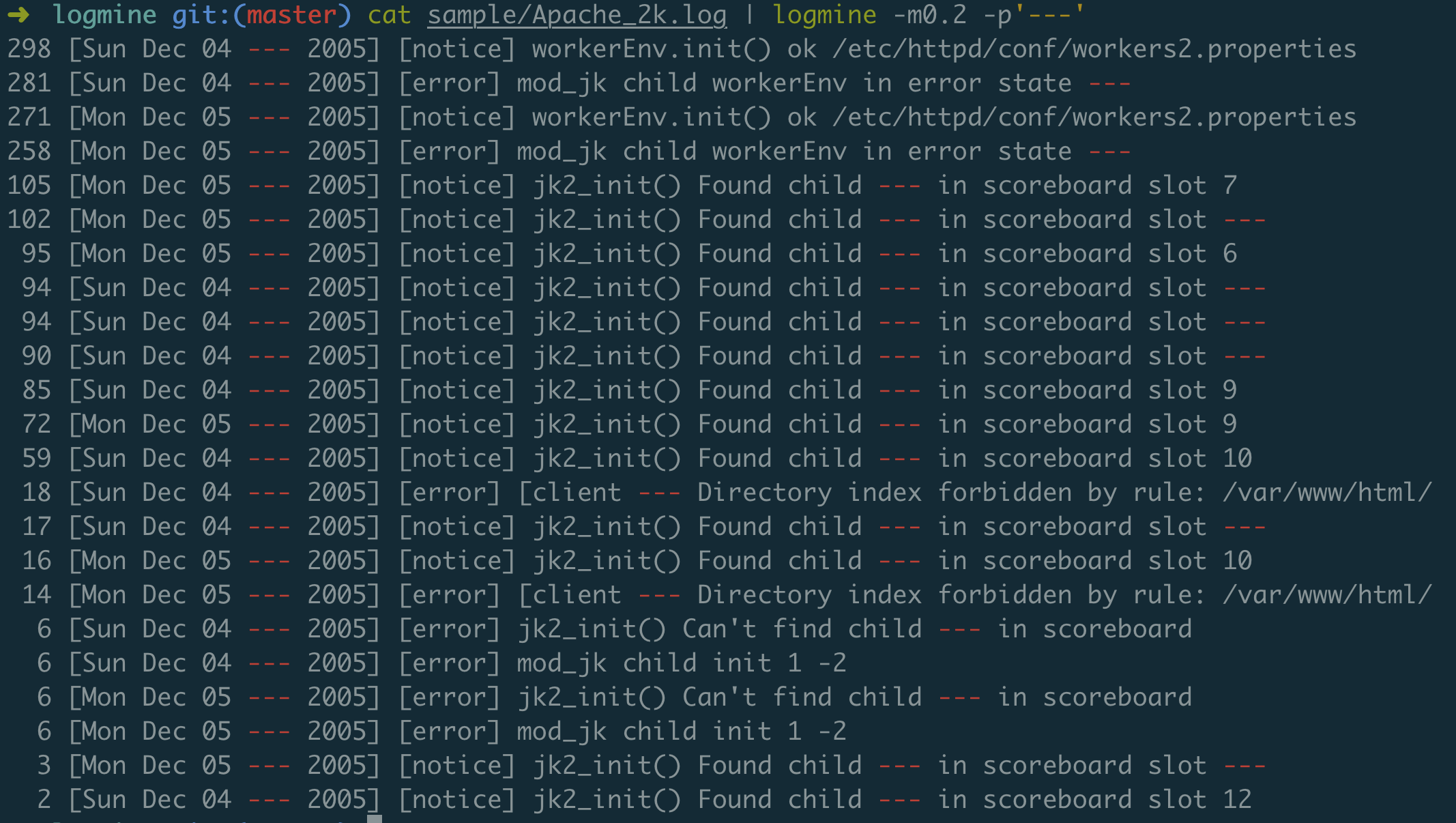
You can define variables to reduce the number unnecessary patterns and have
less clusters. For example, the command bellow replaces all time texts
with <time> variable.
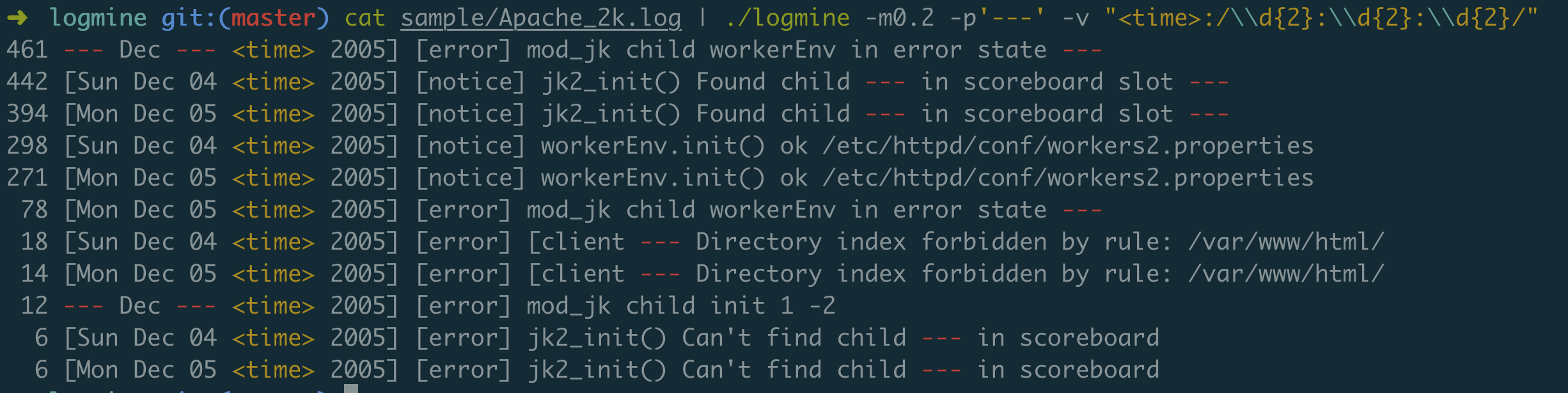
cat sample/Apache_2k.log | logmine -m0.2 -p'---' -v "<time>:/\\d{2}:\\d{2}:\\d{2}/"
How it works
LogMine is an implementation of the same name paper LogMine: Fast Pattern Recognition for Log Analytics. The idea is to use a distance function to calculate a distance between to log line and group them into clusters.
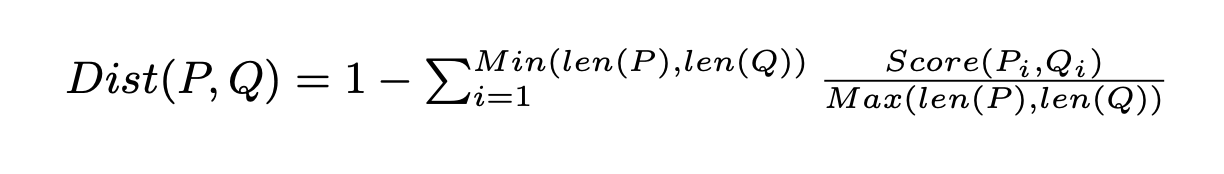
The distance function is designed to work well on log dataset, where all log messages from the same application are generated by a finite set of formats.
The Max Distance variable (max_dist or the -m option) represents the
maximum distance between any log message in a cluster. The smaller max_dist,
the more clusters will be generated. This can be useful to analyze a set of log
messages at multiple levels.
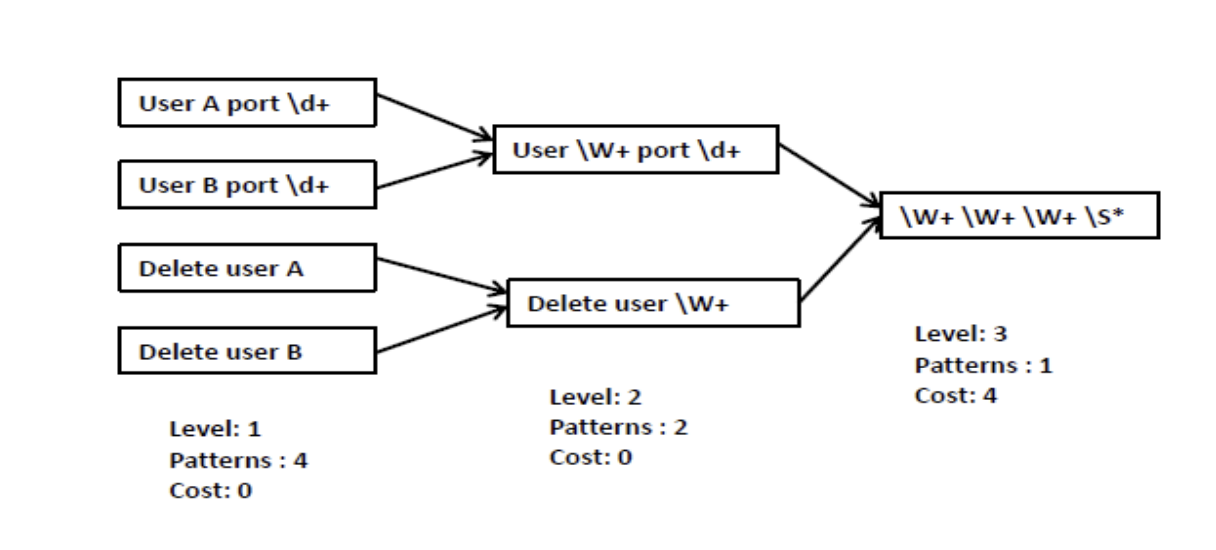
More details on the clustering algorithm and pattern generation are available in the paper.
Features
- Customizable
max_distand many other variables - Parallel processing on multiple cores
- Colorful output
- Support pipe/redirect
- No dependencies
- Tail mode: watch the clusters on a continuous input stream (TODO)
- Sampling to reduce processing time on a large dataset (TODO)
Contribute / Development
-
Welcome all contributions
-
Install
virtualenv(and optionallytwineif you intend to publish):python3 -m pip install virtualenv twine -
Create (if not yet exists) & activate virtual env:
python3 -m virtualenv -p $(which python3) .v -
Activate the virtualenv
source ./.v/bin/activate -
Run tests:
./test.sh -
Run the dev version:
./logmine sample/Apache_2k.log -
Publish:
- Update the version value in
setup.pyfollowing semver. - run
./publish.sh
- Update the version value in
CLI options
usage: logmine [-h] [-m MAX_DIST] [-v [VARIABLES [VARIABLES ...]]]
[-d DELIMETERS] [-i MIN_MEMBERS] [-k1 K1] [-k2 K2]
[-s {desc,asc}] [-da] [-p PATTERN_PLACEHOLDER] [-dhp] [-dm]
[-dhv] [-c]
[file [file ...]]
LogMine: a log pattern analyzer
positional arguments:
file Filenames or glob pattern to analyze. Default: stdin
optional arguments:
-h, --help show this help message and exit
-m MAX_DIST, --max-dist MAX_DIST
This parameter control how the granularity of the
clustering algorithm. Lower the value will provide
more granular clusters (more clusters generated).
Default: 0.6
-v [VARIABLES [VARIABLES ...]], --variables [VARIABLES [VARIABLES ...]]
List of variables to replace before process the log
file. A variable is a pair of name and a regex
pattern. Format: "name:/regex/". During processing
time, LogMine will consider all texts that match
varible regexes to be the same value. This is useful
to reduce the number of unnecessary cluster generated,
with trade off of processing time. Default: None
-d DELIMETERS, --delimeters DELIMETERS
A regex pattern used to split a line into multiple
fields. Default: "\s+"
-i MIN_MEMBERS, --min-members MIN_MEMBERS
Minimum number of members in a cluster to show in the
result. Default: 2
-k1 K1, --fixed-value-weight K1
Internal weighting variable. This value will be used
as the weight value when two fields have the same
value. This is used in the score function to calculate
the distance between two lines. Default: 1
-k2 K2, --variable-weight K2
Similar to k1 but for comparing variables. Two
variable is considering the same if they have same
name. Default: 1
-s {desc,asc}, --sorted {desc,asc}
Sort the clusters by number of members. Default: desc
-da, --disable-number-align
Disable number align in output. Default: True
-p PATTERN_PLACEHOLDER, --pattern-placeholder PATTERN_PLACEHOLDER
Use a string as placeholder for patterns in output.
Default: None
-dhp, --disable-highlight-patterns
Disable highlighting for patterns in output. Default:
True
-dm, --disable-mask-variables
Disable masks for variables in output. When disabled
variables will be shown as the actual value. Default:
True
-dhv, --disable-highlight-variables
Disable highlighting for variables in output. Default:
True
-c, --single-core Force LogMine to only run on 1 core. This will
increase the processing time. Note: the result output
can be different compare to when run with multicores,
this is expected. Default: False
Capturing the analysis result in a buffer
By default, logmine writes the analysis results to stdout. In order to capture this output, a file-like object can be passed using the set_output_file() method to capture the result string, like in the below example :
buffer = io.StringIO()
lm = LogMine() # pass the usual parameters
lm.output.set_output_file(file=buffer)
lm.run()
# The captured output can be accessed in the buffer.
print(buffer.getvalue())
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file logmine-0.4.1-py3-none-any.whl.
File metadata
- Download URL: logmine-0.4.1-py3-none-any.whl
- Upload date:
- Size: 38.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.6.0 importlib_metadata/4.8.2 pkginfo/1.8.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bc70a7cdc65f73ac16ccc1a012b5c5b3d3972540f32463eeda5c94c45a4a7fc2
|
|
| MD5 |
3dcdb315d18f11175e21b911c72537d9
|
|
| BLAKE2b-256 |
09adc1e27e30ab809bdb5dd1c9028a6c480506ada17f66bb8306bbe26d68269f
|







