Python wrapper for the Lolo machine learning library

Project description
Python Wrapper for Lolo
lolopy implements a Python interface to the Lolo machine learning library.
Lolo is a Scala library that contains a variety of machine learning algorithms, with a particular focus on algorithms that provide robust uncertainty estimates.
lolopy gives access to these algorithms as scikit-learn compatible interfaces and automatically manages the interface between Python and the JVM (i.e., you can use lolopy without knowing that it is running on the JVM)
Installation
lolopy is available on PyPi. Install it by calling:
pip install lolopy
To use lolopy, you will also need to install Java JRE >= 1.8 on your system.
The lolopy PyPi package contains the compiled lolo library, so it is ready to use after installation.
Development
Lolopy requires Python >= 3.9, Java JDK >= 1.8, and sbt to be installed on your system when developing lolopy.
Before developing lolopy, compile lolo on your system using sbt.
We have provided a Makefile that contains the needed operations.
To build and install lolopy call make in this directory.
Use
The RandomForestRegressor class most clearly demonstrates the use of lolopy.
This class is based on the Random Forest with Jackknife-based uncertainty estimates of Wagner et al,
which - in effect - uses the variance between different trees in the forest to produce estimates of the uncertainty of each prediction.
Using this algorithm is as simple as using the RandomForestRegressor from scikit-learn:
from lolopy.learners import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X, y)
y_pred, y_std = rf.predict(X, return_std=True)
The results of this code is to produce the predicted values (y_pred) and their uncertainties (y_std).
See the examples folder for more examples and details.
You may need to increase the amount of memory available to lolopy when using it on larger dataset sizes.
Setting the maximum memory footprint for the JVM running the machine learning calculations can be
achieved by setting the LOLOPY_JVM_MEMORY environment variable.
The value for LOLOPY_JVM_MEMORY is used to set the maximum heap size for the JVM
(see Oracle's documentation for details).
For example, "4g" allows lolo to use 4GB of memory.
Implementation and Performance
lolopy is built using the Py4J library to interface with the Lolo scala library.
Py4J provides the ability to easily managing a JVM server, create Java objects in that JVM, and call Java methods from Python.
However, Py4J has slow performance in transfering large arrays.
To transfer arrays of features (e.g., training data) to the JVM before model training or evaluation, we transform the data to/from Byte arrays on the Java and Python sides.
Transfering data as byte arrays does allow for quickly moving data between the JVM and Python but requires holding 3 copies of the data in memory at once (Python, Java Byte array, and Java numerical array).
We could reduce memory usage by passing the byte array in chunks, but this is currently not implemented.
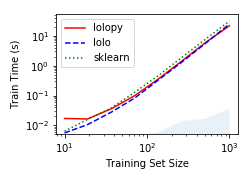
Our performance for model training is comparable to scikit-learn, as shown in the figure below.
The blue-shaded region in the figure represents the time required to pass training data to the JVM.
We note that training times are equivalent between using the Scala interface to Lolo and lolopy for training set sizes above 100.
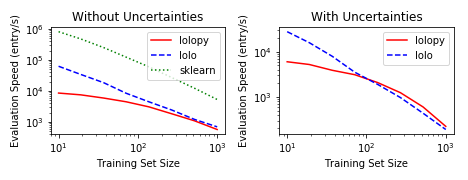
Lolopy and lolo are currently slower than scikit-learn for model evaluation, as shown in the figure below.
The model timings are evaluated on a dataset size of 1000 with 145 features.
The decrease in model performance with training set size is an effect of the number of trees in the forest being equal to the training set size.
Lolopy and lolo have similar performance for models with training set sizes of above 100.
Below a training set size of 100, the cost of sending data limits the performance of lolopy.
For more details, see the benchmarking notebook.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lolopy-3.0.7.tar.gz.
File metadata
- Download URL: lolopy-3.0.7.tar.gz
- Upload date:
- Size: 41.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6780f3d944368719468cef64fa6f2ce7b282b8bf3308f1dba5b1c94bad8cf332
|
|
| MD5 |
0d71c7cea402f418a851234f714e7672
|
|
| BLAKE2b-256 |
9be8b1af9d6bc75ff0ffc88fd930ce1c0de430e53aa41f9e6b80c8709964b499
|
File details
Details for the file lolopy-3.0.7-py2.py3-none-any.whl.
File metadata
- Download URL: lolopy-3.0.7-py2.py3-none-any.whl
- Upload date:
- Size: 41.9 MB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9a08444ea2964c49e059185cd3b726709150ddb6da0921869e7f8a23fb8dfaa
|
|
| MD5 |
76afb18304119fbb3b767509c7a4586e
|
|
| BLAKE2b-256 |
ea9f63fd5c1fa546feafce8b8f7357e0d5f39ac967eb11850e9c22cf124a0e0b
|







