Opinionated lightweight ELT pipeline framework


Project description
Mara Pipelines




This package contains a lightweight data transformation framework with a focus on transparency and complexity reduction. It has a number of baked-in assumptions/ principles:
-
Data integration pipelines as code: pipelines, tasks and commands are created using declarative Python code.
-
PostgreSQL as a data processing engine.
-
Extensive web ui. The web browser as the main tool for inspecting, running and debugging pipelines.
-
GNU make semantics. Nodes depend on the completion of upstream nodes. No data dependencies or data flows.
-
No in-app data processing: command line tools as the main tool for interacting with databases and data.
-
Single machine pipeline execution based on Python's multiprocessing. No need for distributed task queues. Easy debugging and output logging.
-
Cost based priority queues: nodes with higher cost (based on recorded run times) are run first.
Installation
To use the library directly, use pip:
pip install mara-pipelines
or
pip install git+https://github.com/mara/mara-pipelines.git
For an example of an integration into a flask application, have a look at the mara example project 1 and mara example project 2.
Due to the heavy use of forking, Mara Pipelines does not run natively on Windows. If you want to run it on Windows, then please use Docker or the Windows Subsystem for Linux.
Example
Here is a pipeline "demo" consisting of three nodes that depend on each other: the task ping_localhost, the pipeline sub_pipeline and the task sleep:
from mara_pipelines.commands.bash import RunBash
from mara_pipelines.pipelines import Pipeline, Task
from mara_pipelines.cli import run_pipeline, run_interactively
pipeline = Pipeline(
id='demo',
description='A small pipeline that demonstrates the interplay between pipelines, tasks and commands')
pipeline.add(Task(id='ping_localhost', description='Pings localhost',
commands=[RunBash('ping -c 3 localhost')]))
sub_pipeline = Pipeline(id='sub_pipeline', description='Pings a number of hosts')
for host in ['google', 'amazon', 'facebook']:
sub_pipeline.add(Task(id=f'ping_{host}', description=f'Pings {host}',
commands=[RunBash(f'ping -c 3 {host}.com')]))
sub_pipeline.add_dependency('ping_amazon', 'ping_facebook')
sub_pipeline.add(Task(id='ping_foo', description='Pings foo',
commands=[RunBash('ping foo')]), ['ping_amazon'])
pipeline.add(sub_pipeline, ['ping_localhost'])
pipeline.add(Task(id='sleep', description='Sleeps for 2 seconds',
commands=[RunBash('sleep 2')]), ['sub_pipeline'])
Tasks contain lists of commands, which do the actual work (in this case running bash commands that ping various hosts).
In order to run the pipeline, a PostgreSQL database is recommended to be configured for storing run-time information, run output and status of incremental processing:
import mara_db.auto_migration
import mara_db.config
import mara_db.dbs
mara_db.config.databases \
= lambda: {'mara': mara_db.dbs.PostgreSQLDB(host='localhost', user='root', database='example_etl_mara')}
mara_db.auto_migration.auto_discover_models_and_migrate()
Given that PostgresSQL is running and the credentials work, the output looks like this (a database with a number of tables is created):
Created database "postgresql+psycopg2://root@localhost/example_etl_mara"
CREATE TABLE data_integration_file_dependency (
node_path TEXT[] NOT NULL,
dependency_type VARCHAR NOT NULL,
hash VARCHAR,
timestamp TIMESTAMP WITHOUT TIME ZONE,
PRIMARY KEY (node_path, dependency_type)
);
.. more tables
CLI UI
This runs a pipeline with output to stdout:
from mara_pipelines.cli import run_pipeline
run_pipeline(pipeline)

And this runs a single node of pipeline sub_pipeline together with all the nodes that it depends on:
run_pipeline(sub_pipeline, nodes=[sub_pipeline.nodes['ping_amazon']], with_upstreams=True)

And finally, there is some sort of menu based on pythondialog that allows to navigate and run pipelines like this:
from mara_pipelines.cli import run_interactively
run_interactively()

Web UI
More importantly, this package provides an extensive web interface. It can be easily integrated into any Flask based app and the mara example project demonstrates how to do this using mara-app.
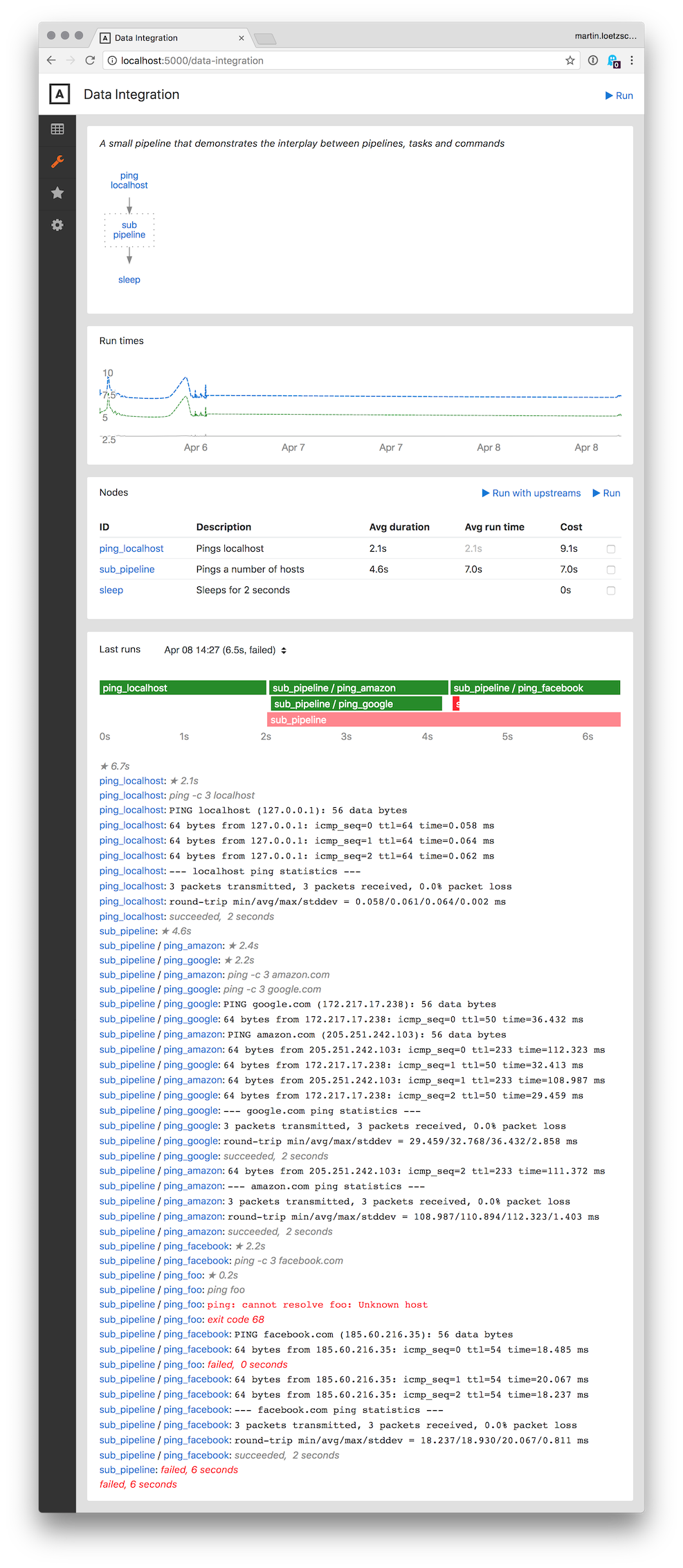
For each pipeline, there is a page that shows
- a graph of all child nodes and the dependencies between them
- a chart of the overal run time of the pipeline and it's most expensive nodes over the last 30 days (configurable)
- a table of all the pipeline's nodes with their average run times and the resulting queuing priority
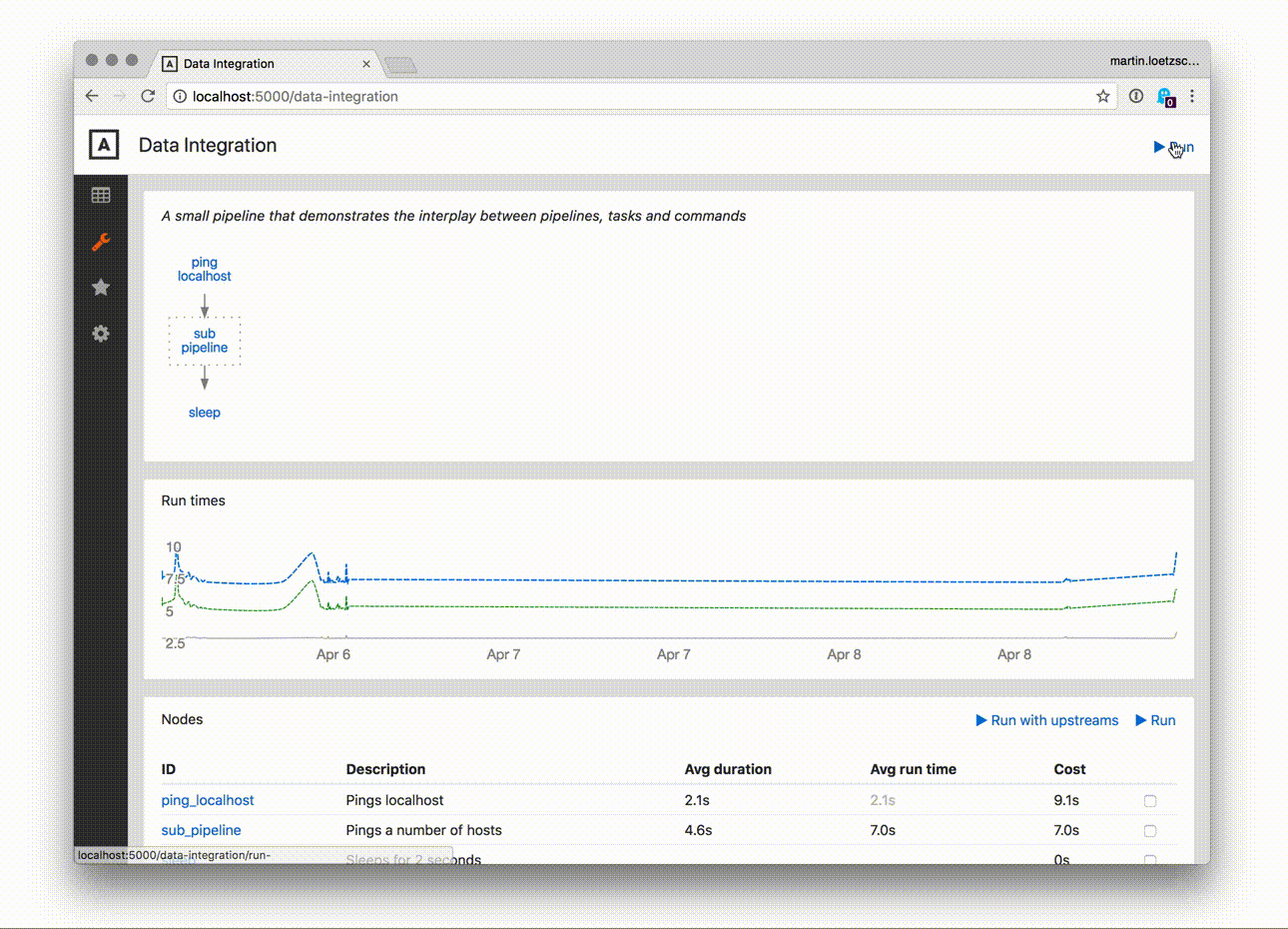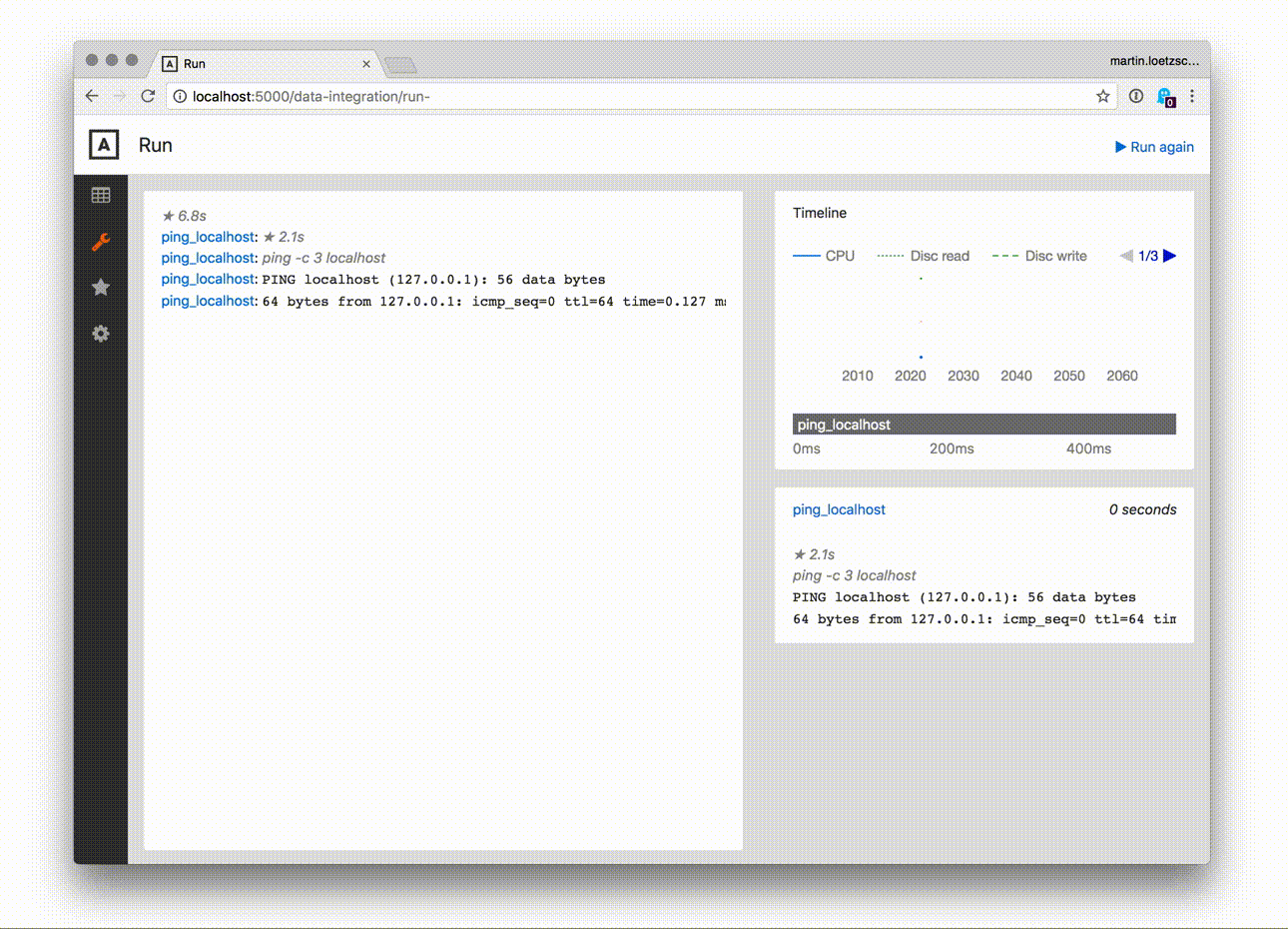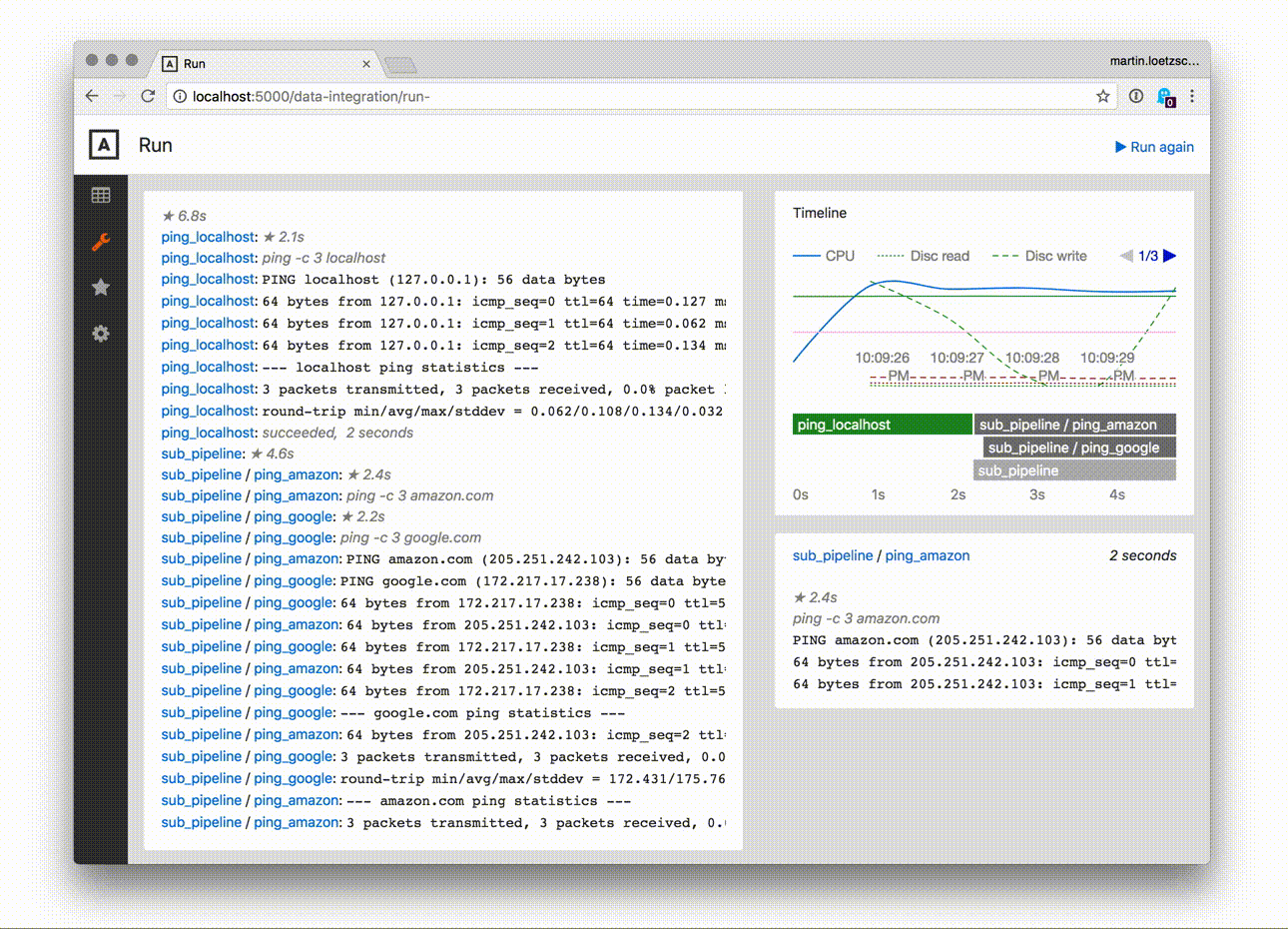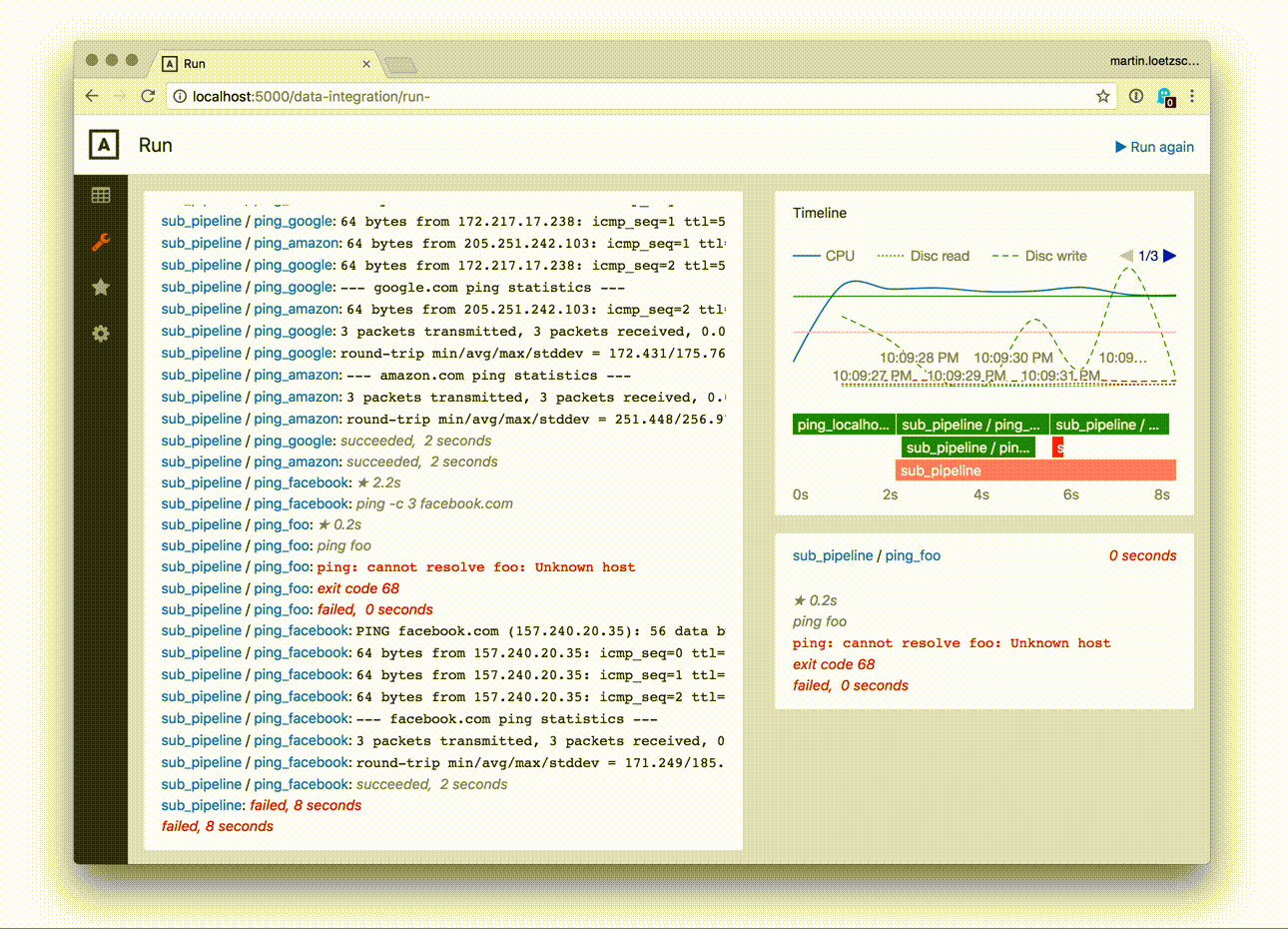
- output and timeline for the last runs of the pipeline
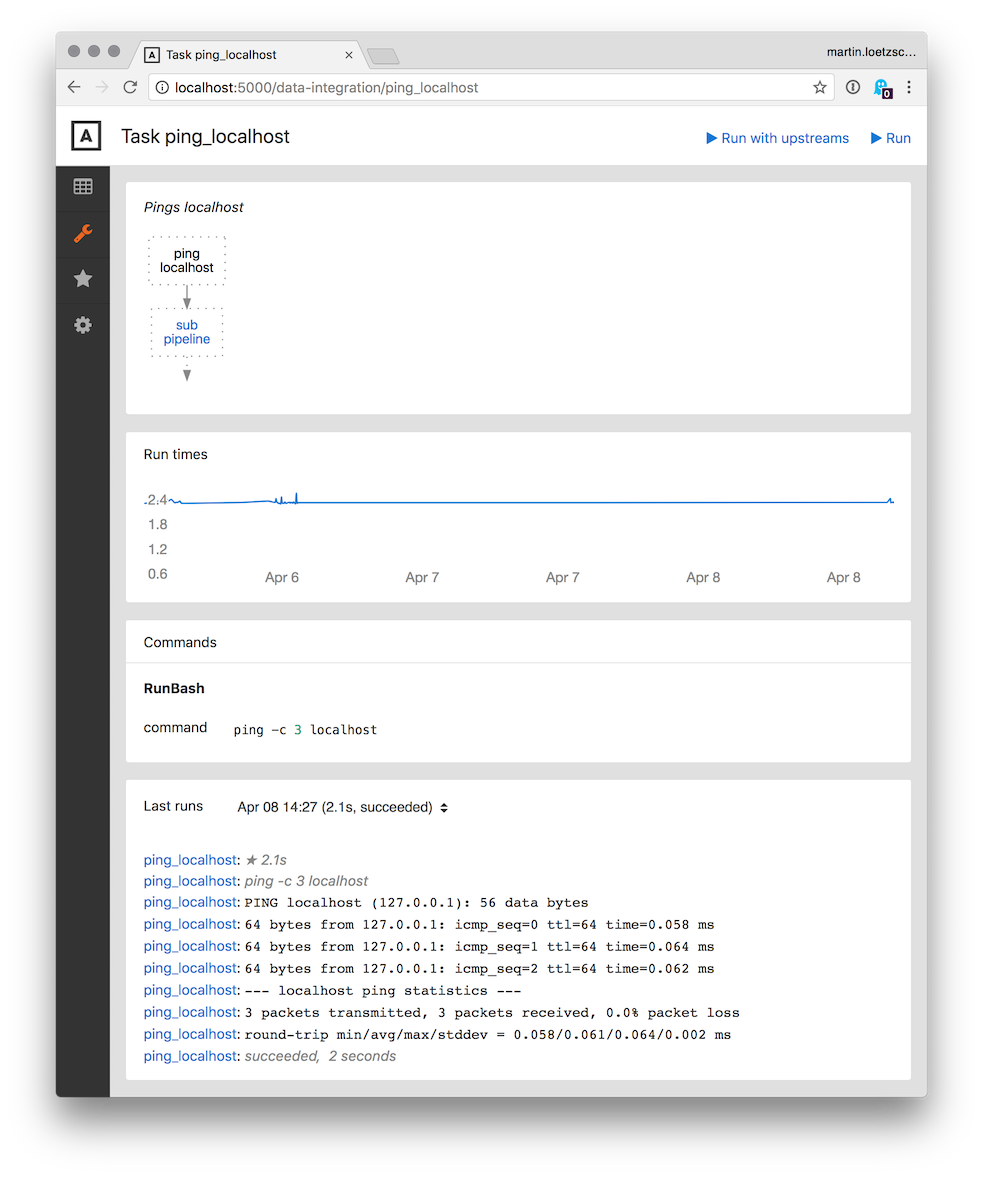
For each task, there is a page showing
- the upstreams and downstreams of the task in the pipeline
- the run times of the task in the last 30 days
- all commands of the task
- output of the last runs of the task
Pipelines and tasks can be run from the web ui directly, which is probably one of the main features of this package:
Getting started
Documentation is currently work in progress. Please use the mara example project 1 and mara example project 2 as a reference for getting started.
Links
- Documentation: https://mara-pipelines.readthedocs.io/
- Changes: https://mara-pipelines.readthedocs.io/en/latest/changes.html
- PyPI Releases: https://pypi.org/project/mara-pipelines/
- Source Code: https://github.com/mara/mara-pipelines
- Issue Tracker: https://github.com/mara/mara-pipelines/issues


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mara-pipelines-3.5.0.tar.gz.
File metadata
- Download URL: mara-pipelines-3.5.0.tar.gz
- Upload date:
- Size: 65.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
03bc1f1d93a3a28ad2395f7c93ea555aa54df55fe3a59728db2f7a2512f0f9f6
|
|
| MD5 |
193040660a4db63138f1603216d422d6
|
|
| BLAKE2b-256 |
5c5e5e31ec0c9192312e5d26108b373e71b5b87e113249f662baadfa91f7497a
|
File details
Details for the file mara_pipelines-3.5.0-py3-none-any.whl.
File metadata
- Download URL: mara_pipelines-3.5.0-py3-none-any.whl
- Upload date:
- Size: 82.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cc61cd4210a7e3e17750957c237e0da8a2d7a75fe30a18f5973add3c213eb58f
|
|
| MD5 |
89233018b6637ac1a37cb264e14885ed
|
|
| BLAKE2b-256 |
6cdefd160025c701b5ba7bf752ad7f7714e244675104e87f4eee81c3c93e037d
|







