Mapping of DWH database tables to business entities, attributes & metrics in Python, with automatic creation of flattened tables


Project description
Mara Schema




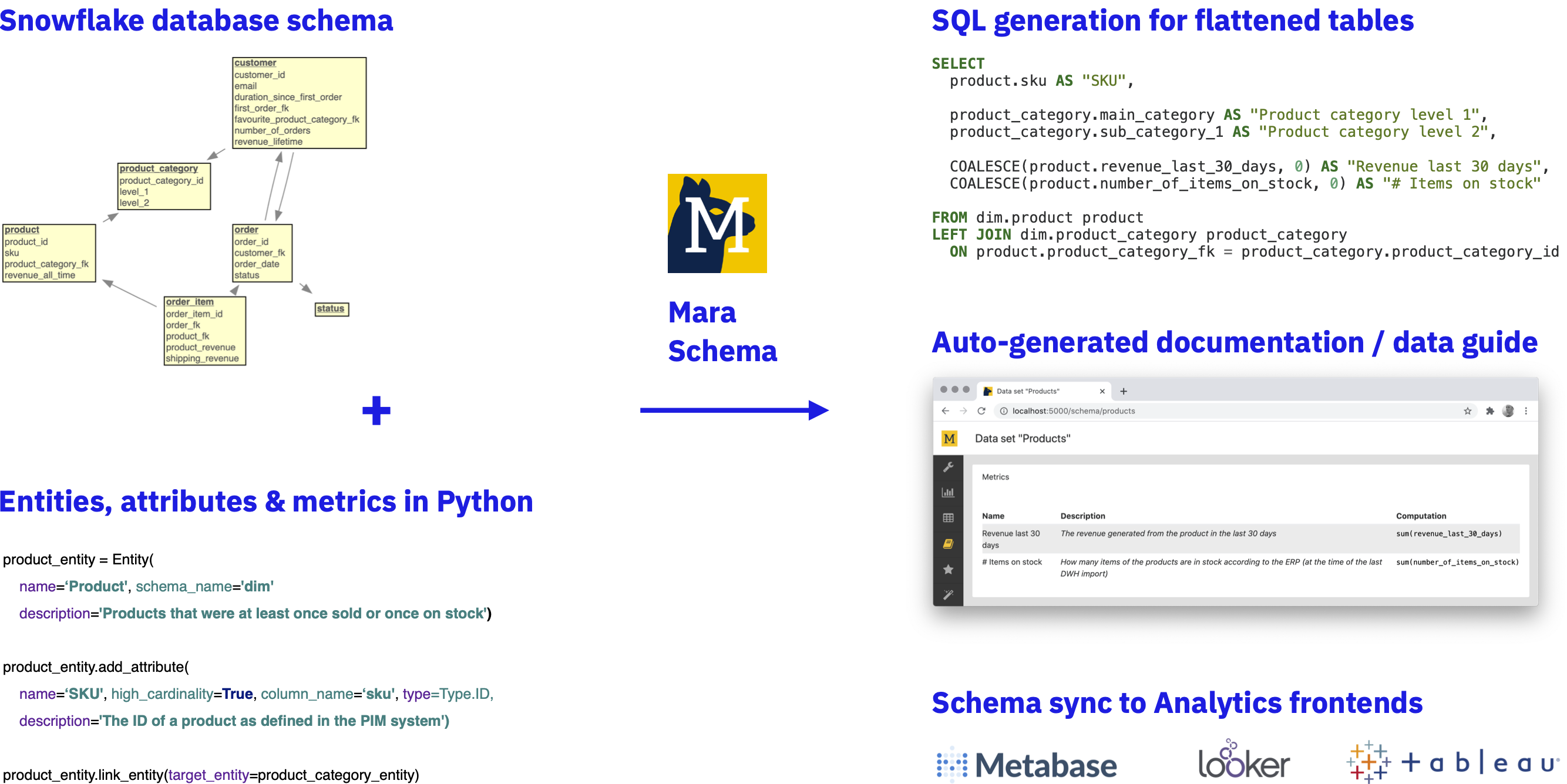
Python based mapping of physical data warehouse tables to logical business entities (a.k.a. "cubes", "models", "data sets", etc.). It comes with
- sql query generation for flattening normalized database tables into wide tables for various analytics front-ends
- a flask based visualization of the schema that can serve as a documentation of the business definitions of a data warehouse (a.k.a "data dictionary" or "data guide")
- the possibility to sync schemas to reporting front-ends that have meta-data APIs (e.g. Metabase, Looker, Tableau)
Have a look at a real-world application of Mara Schema in the Mara Example Project 1.
Why should I use Mara Schema?
-
Definition of analytical business entities as code: There are many solutions for documenting the company-wide definitions of attributes & metrics for the users of a data warehouse. These can range from simple spreadsheets or wikis to metadata management tools inside reporting front-ends. However, these definitions can quickly get out of sync when new columns are added or changed in the underlying data warehouse. Mara Schema allows to deploy definition changes together with changes in the underlying ETL processes so that all definitions will always be in sync with the underlying data warehouse schema.
-
Automatic generation of aggregates / artifacts: When a company wants to enforce a single source of truth in their data warehouse, then a heavily normalized Kimball-style snowflake schema is still the weapon of choice. It enforces an agreed-upon unified modelling of business entities across domains and ensures referential consistency. However, snowflake schemas are not ideal for analytics or data science because they require a lot of joins. Most analytical databases and reporting tools nowadays work better with pre-flattened wide tables. Creating such flattened tables is an error-prone and dull activity, but with Mara Schema one can automate most of the work in creating flattened data set tables in the ETL.
Installation
To use the library directly, use pip:
pip install mara-schema
or
pip install git+https://github.com/mara/mara-schema.git
Defining entities, attributes, metrics & data sets
Let's consider the following toy example of a dimensional schema in the data warehouse of a hypothetical e-commerce company:

Each box is a database table with its columns, and the lines between tables show the foreign key constraints. That's a classic Kimball style snowflake schema and it requires a proper modelling / ETL layer in your data warehouse. A script that creates these example tables in PostgreSQL can be found in example/dimensional-schema.sql.
It's a prototypical data warehouse schema for B2C e-commerce: There are orders composed of individual product purchases (order items) made by customers. There are circular references: Orders have a customer, and customers have a first order. Order items have a product (and thus a product category) and customers have a favourite product category.
The respective entity and data set definitions for this database schema can be found in the mara_schema/example directory.
In Mara Schema, each business relevant table in the dimensional schema is mapped to an Entity. In dimensional modelling terms, entities can be both fact tables and dimensions. For example, a customer entity can be a dimension of an order items data set (a.k.a. "cube", "model", "data mart") and a customer data set of its own.
Here's a shortened defnition of the "Order item" entity based on the dim.order_item table:
from mara_schema.entity import Entity
order_item_entity = Entity(
name='Order item',
description='Individual products sold as part of an order',
schema_name='dim')
It assumes that there is an order_item table in the dim schema of the data warehouse, with order_item_id as the primary key. The optional table_name and pk_column_name parameters can be used when another naming scheme for tables and primary keys is used.
Attributes represent facts about an entity. They correspond to the non-numerical columns in a fact or dimension table:
from mara_schema.attribute import Type
order_item_entity.add_attribute(
name='Order item ID',
description='The ID of the order item in the backend',
column_name='order_item_id',
type=Type.ID,
high_cardinality=True)
They come with a speaking name (as shown in reporting front-ends), a description and a column_name in the underlying database table.
There a several parameters for controlling the generation of artifact tables and the visibility in front-ends:
- Setting
personal_datatoTruemeans that the attribute contains personally identifiable information and thus should be hidden from most users. - When
high_cardinalityisTrue, then the attribute is hidden in front-ends that can not deal well with dimensions with a lot of values. - The
typeattribute controls how some fields are treated in artifact creation. See mara_schema/attribute.py#L7. - An
important_fieldhighlights the data set and is shown by default in overviews. - When
accessible_via_entity_linkisFalse, then the attribute will be hidden in data sets that use the entity as an dimension.
The attributes of the dimensions of an entity are recursively linked with the link_entity method:
from .order import order_entity
from .product import product_entity
order_item_entity.link_entity(target_entity=order_entity, prefix='')
order_item_entity.link_entity(target_entity=product_entity)
This pulls in attributes of other entities that are connected to an entity table via foreign key columns. When the other entity is called "Foo bar", then it's assumed that there is a foo_bar_fk in the entity table (can be overwritten with the fk_column parameter). The optional prefix controls how linked attributes are named (e.g. "First order date" vs "Order date") and also helps to disambiguate when there are multiple links from one entity to another.
Once all entities and their relationships are established, Data Sets (a.k.a "cubes", "models" or "data marts") add metrics and attributes from linked entities to an entity:
from mara_schema.data_set import DataSet
from ..entities.order_item import order_item_entity
order_items_data_set = DataSet(entity=order_item_entity, name='Order items')
There are two kinds of Metrics (a.k.a "Measures") in Mara Schema: simple metrics and composed metrics. Simple metrics are computed as direct aggregations on an entity table column:
from mara_schema.data_set import Aggregation
order_items_data_set.add_simple_metric(
name='# Orders',
description='The number of valid orders (orders with an invoice)',
column_name='order_fk',
aggregation=Aggregation.DISTINCT_COUNT,
important_field=True)
order_items_data_set.add_simple_metric(
name='Product revenue',
description='The price of the ordered products as shown in the cart',
aggregation=Aggregation.SUM,
column_name='product_revenue',
important_field=True)
In this example the metric "# Orders" is defined as the distinct count on the order_fk column, and "Product revenue" as the sum of the product_revenue column.
Composed metrics are built from other metrics (both simple and composed) like this:
order_items_data_set.add_composed_metric(
name='Revenue',
description='The total cart value of the order',
formula='[Product revenue] + [Shipping revenue]',
important_field=True)
order_items_data_set.add_composed_metric(
name='AOV',
description='The average revenue per order. Attention: not meaningful when split by product',
formula='[Revenue] / [# Orders]',
important_field=True)
The formula parameter takes simple algebraic expressions (+, -, *, / and parentheses) with the names of the parent metrics in rectangular brackets, e.g. ([a] + [b]) / [c].
With complex snowflake schemas the graph of linked entities can become rather big. To avoid cluttering data sets with unnecessary attributes, Mara Schema has a way for excluding entire entity links:
customers_data_set.exclude_path(['Order', 'Customer'])
This means that the customer of the first order of a customer will not be part of the customers data set. Similarly, it is possible to limit the list of attributes from a linked entity:
order_items_data_set.include_attributes(['Order', 'Customer', 'Order'], ['Order date'])
Here only the order date of the first order of the customer of the order will be included in the data set.
Visualization
Mara schema comes with (an optional) Flask based visualization that documents the metrics and attributes of all data sets:
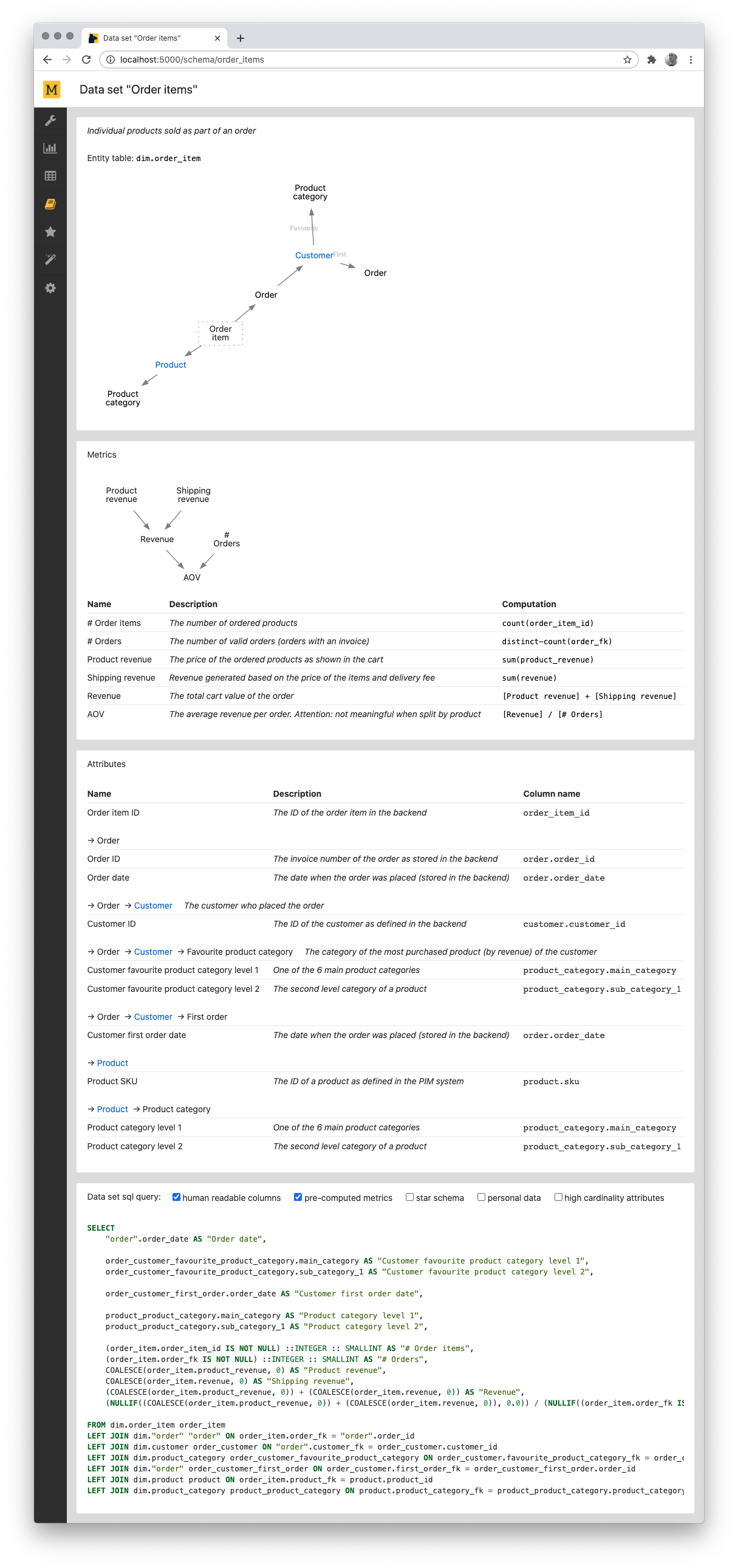
When made available to business users, then this can serve as the "data dictionary", "data guide" or "data catalog" of a company.
Artifact generation
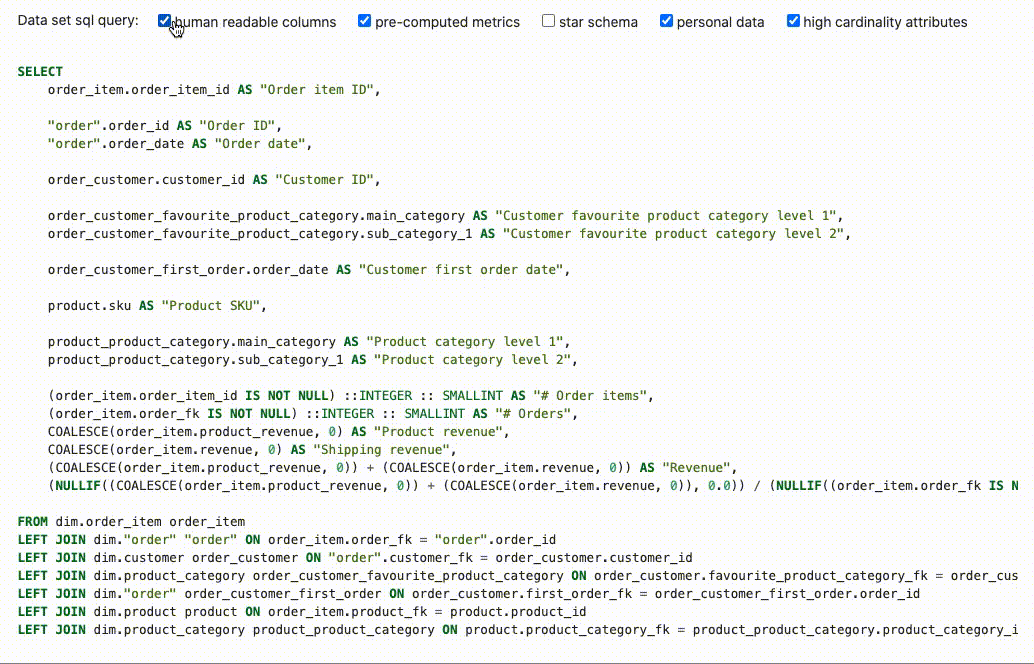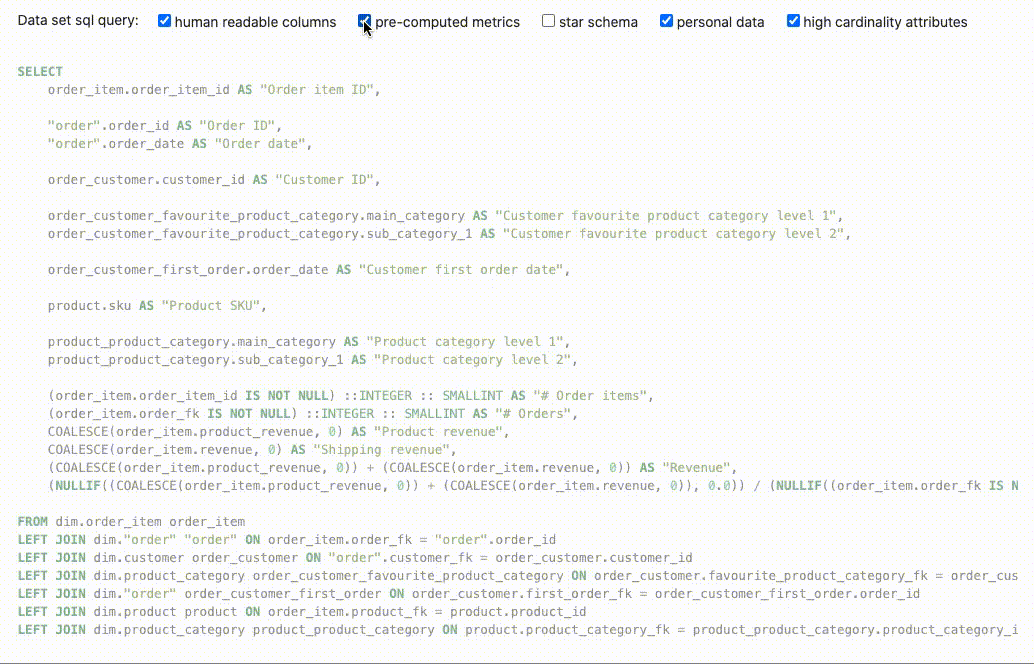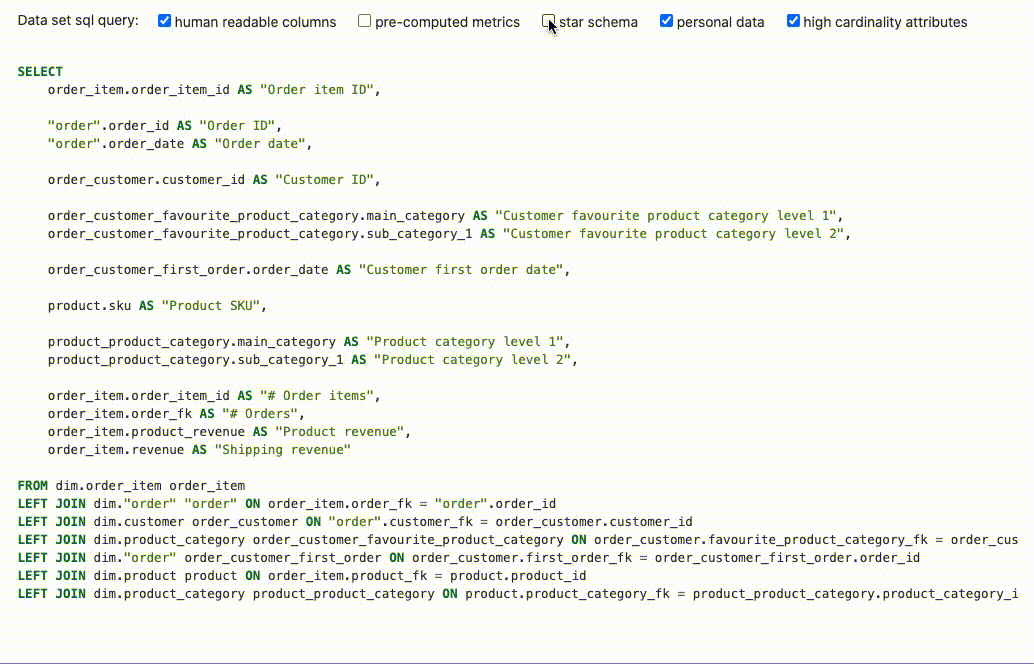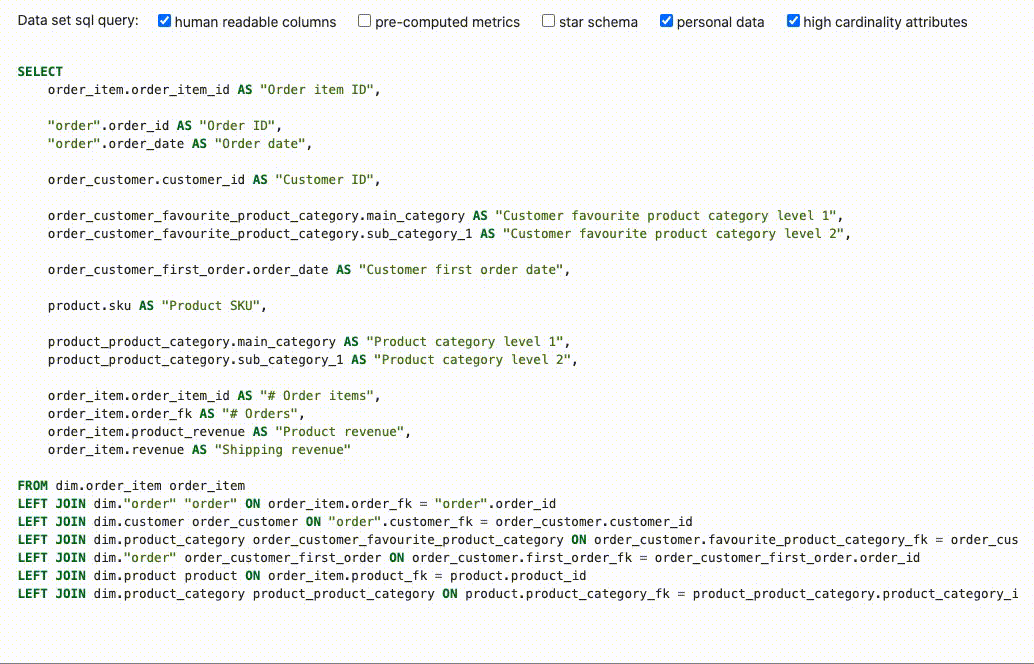
The function data_set_sql_query in mara_schema/sql_generation.py can be used to flatten the entities of a data set into a wide data set table:
data_set_sql_query(data_set=order_items_data_set, human_readable_columns=True, pre_computed_metrics=False,
star_schema=False, personal_data=False, high_cardinality_attributes=True)
The resulting SELECT statement can be used for creating a data set table that is specifically tailored for the use in Metabase:
SELECT
order_item.order_item_id AS "Order item ID",
"order".order_id AS "Order ID",
"order".order_date AS "Order date",
order_customer.customer_id AS "Customer ID",
order_customer_favourite_product_category.main_category AS "Customer favourite product category level 1",
order_customer_favourite_product_category.sub_category_1 AS "Customer favourite product category level 2",
order_customer_first_order.order_date AS "Customer first order date",
product.sku AS "Product SKU",
product_product_category.main_category AS "Product category level 1",
product_product_category.sub_category_1 AS "Product category level 2",
order_item.order_item_id AS "# Order items",
order_item.order_fk AS "# Orders",
order_item.product_revenue AS "Product revenue",
order_item.revenue AS "Shipping revenue"
FROM dim.order_item order_item
LEFT JOIN dim."order" "order" ON order_item.order_fk = "order".order_id
LEFT JOIN dim.customer order_customer ON "order".customer_fk = order_customer.customer_id
LEFT JOIN dim.product_category order_customer_favourite_product_category ON order_customer.favourite_product_category_fk = order_customer_favourite_product_category.product_category_id
LEFT JOIN dim."order" order_customer_first_order ON order_customer.first_order_fk = order_customer_first_order.order_id
LEFT JOIN dim.product product ON order_item.product_fk = product.product_id
LEFT JOIN dim.product_category product_product_category ON product.product_category_fk = product_product_category.product_category_id
Please note that the data_set_sql_query only returns SQL select statements, it's a matter of executing these statements somewhere in the ETL of the Data Warehouse. Here is an example for creating data set tables for Metabase using Mara Pipelines.
There are several parameters for controlling the output of the data_set_sql_query function:
human_readable_columns: Whether to use "Customer name" rather than "customer_name" as column namepre_computed_metrics: Whether to pre-compute composed metrics, counts and distinct counts on row levelstar_schema: Whether to add foreign keys to the tables of linked entities rather than including their attributespersonal_data: Whether to include attributes that are marked as personal datahigh_cardinality_attributes: Whether to include attributes that are marked to have a high cardinality
Schema sync to front-ends
When reporting tools have a Metadata API (e.g. Metabase, Tableau) or can read schema definitions from text files (e.g. Looker, Mondrian), then it's easy to sync definitions with them. The Mara Metabase package contains a function for syncing Mara Schema definitions with Metabase and the Mara Mondrian package contains a generator for a Mondrian schema.
We welcome contributions for creating Looker LookML files, for syncing definitions with Tableau, and for syncing with any other BI front-end.
Also, we see a potential for automatically creating data guides in other Wikis or documentation tools.
Installation
To use the library directly, use pip:
pip install mara-schema
or
pip install git+https://github.com/mara/mara-schema.git
For an example of an integration into a flask application, have a look at the Mara Example Project 1.
Links
- Documentation: https://mara-schema.readthedocs.io/
- Changes: https://mara-schema.readthedocs.io/en/stable/changes.html
- PyPI Releases: https://pypi.org/project/mara-schema/
- Source Code: https://github.com/mara/mara-schema
- Issue Tracker: https://github.com/mara/mara-schema/issues


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mara-schema-1.2.1.tar.gz.
File metadata
- Download URL: mara-schema-1.2.1.tar.gz
- Upload date:
- Size: 28.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3b676ba1149ad66c9a52f5fc9b191168860fb46f21246e2c579bcf0706a7702e
|
|
| MD5 |
747289add5fd8fee57ee46211b546fc3
|
|
| BLAKE2b-256 |
3e107a22bcbef24d7f659dc4d177cba97e7be7658469588f76d4d057a882ea0e
|
File details
Details for the file mara_schema-1.2.1-py3-none-any.whl.
File metadata
- Download URL: mara_schema-1.2.1-py3-none-any.whl
- Upload date:
- Size: 30.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f8e47586573ef3c057ec6a075a03396d2373d3385d416f1b6926d78d8a2a97e5
|
|
| MD5 |
2bd17e609c4f6d8af6d23d5f14cb1792
|
|
| BLAKE2b-256 |
916c51876c39adc0c9b217a5273c7bbefb811753723987347e40eb203133ec0e
|







