Markov Decision Process Python Library

Project description
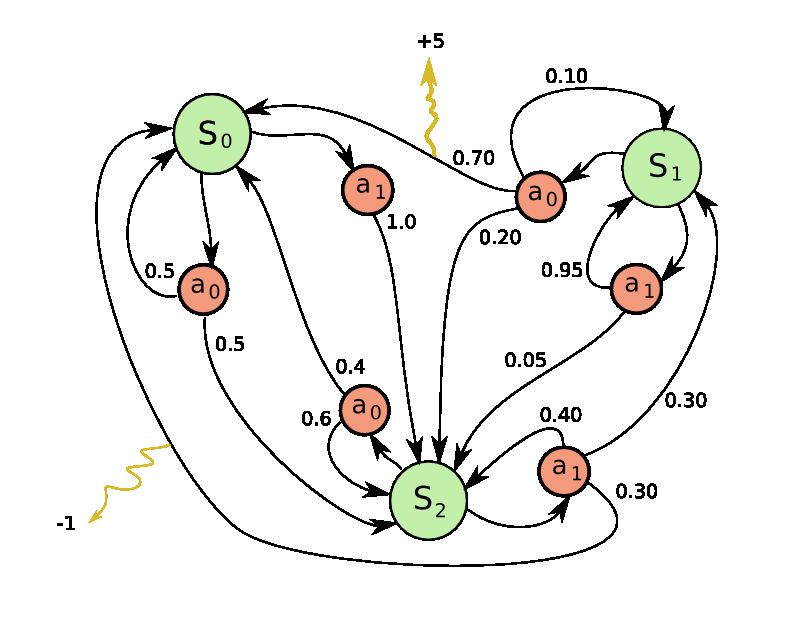
## Markov: Simple Python Library for Markov Decision Processes
#### Author: Stephen Offer
Markov is an easy to use collection of functions and objects to create MDP
functions.
Markov allows for synchronous and asynchronous execution to experiment with
the performance advantages of distributed systems.
#### States:
- Reward, Terminal State, Actions, Value, Previous States, Next States, State
Policy Probabilities.
#### Policies:
- Greedy Policy
- e-Greedy Policy
- More to come...
#### Algorithms:
- Dynamic Programming
- Linear coming soon
#### Optimizers:
- Value/Policy Iteration
- More to come...
#### Environments:
- Gridworld (ASCII, PyGame coming soon)
- Gym coming soon
- More to come...
### Example:
```python
import numpy as np
import argparse
from markov import GreedyPolicy
from markov.envs.gridworld import GridWorld
def value_iteration(K=1,discount_factor=1.):
env = GridWorld()
P = GreedyPolicy(env)
values = np.zeros(env.n_states)
for k in range(K):
for state in env.states:
v = 0
for i, action in enumerate(state.actions):
policy = state.policy[i]
next_state = action(env, state.action_args)
r = next_state.reward
v += policy * (r + discount_factor * next_state.value)
values[state.index] = v
for state in env.states:
state.value = values[state.index]
env.print()
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--k", help="number of k-iterations",
type=int,default=1)
args = parser.parse_args()
k = args.k
value_iteration(k)
if __name__ == "__main__":
main()
```
#### Contributors Welcome
## Markov: Simple Python Library for Markov Decision Processes
#### Author: Stephen Offer
Markov is an easy to use collection of functions and objects to create MDP
functions.
Markov allows for synchronous and asynchronous execution to experiment with
the performance advantages of distributed systems.
#### States:
- Reward, Terminal State, Actions, Value, Previous States, Next States, State
Policy Probabilities.
#### Policies:
- Greedy Policy
- e-Greedy Policy
- More to come...
#### Algorithms:
- Dynamic Programming
- Linear coming soon
#### Optimizers:
- Value/Policy Iteration
- More to come...
#### Environments:
- Gridworld (ASCII, PyGame coming soon)
- Gym coming soon
- More to come...
### Example:
```python
import numpy as np
import argparse
from markov import GreedyPolicy
from markov.envs.gridworld import GridWorld
def value_iteration(K=1,discount_factor=1.):
env = GridWorld()
P = GreedyPolicy(env)
values = np.zeros(env.n_states)
for k in range(K):
for state in env.states:
v = 0
for i, action in enumerate(state.actions):
policy = state.policy[i]
next_state = action(env, state.action_args)
r = next_state.reward
v += policy * (r + discount_factor * next_state.value)
values[state.index] = v
for state in env.states:
state.value = values[state.index]
env.print()
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--k", help="number of k-iterations",
type=int,default=1)
args = parser.parse_args()
k = args.k
value_iteration(k)
if __name__ == "__main__":
main()
```
#### Contributors Welcome
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
markov_rlzoo-0.0.1.tar.gz
(3.7 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file markov_rlzoo-0.0.1.tar.gz.
File metadata
- Download URL: markov_rlzoo-0.0.1.tar.gz
- Upload date:
- Size: 3.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eec2f4855c4c9db2fda8fc2b24174a0a3aeddb2b3f86395ed6757224b8dbf3e5
|
|
| MD5 |
4b1b7e4a7b91f296657557f16eae29ec
|
|
| BLAKE2b-256 |
a1f56cc85a5f78705ba4726839f4d1a2b19d342166dce832fb06dd72718dc6de
|
File details
Details for the file markov_rlzoo-0.0.1-py3-none-any.whl.
File metadata
- Download URL: markov_rlzoo-0.0.1-py3-none-any.whl
- Upload date:
- Size: 6.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.21.0 setuptools/40.8.0 requests-toolbelt/0.9.1 tqdm/4.31.1 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f174ec5bb09f110c26d3f614ad39503ec939855430b6f4f9786151b17326bab6
|
|
| MD5 |
5bcf423620657ba829a6774a6823c084
|
|
| BLAKE2b-256 |
5bd6b196aca969a72600091b860ffea01017f2509be2417d8131d7bcb334ae53
|







