A Linux profiling multi-tool with visualisation.

Project description
MARPLE - Multi-tool Analysis of Runtime Performance on Linux Environments



Description
MARPLE is a performance analysis and visualisation tool for Linux. It unifies a wide variety of pre-existing Linux tools such as perf and eBPF into one, simple user interface. MARPLE uses these Linux tools to collect data and write it to disk, and provides a variety of visualisation tools to display the data.
Installation
- Install Python 3 and Git.
$ sudo apt-get update
$ sudo apt-get install python3 git
- Install MARPLE.
$ sudo python3 -m pip install marple
Note that sudo is not necessary. However, without it pip will by default
install MARPLE scripts at ~/.local/bin, which is not usually included in the
PATH variable. Ensure it is before proceeding.
-
Setup MARPLE - either manually or automatically.
- Automatic setup (beta)
$ marple_setupThis will install the various dependencies required by MARPLE (see below). Note in particular that the FD.io VPP repository will be installed into your home directory.
- Manual setup
- Install
aptpackages
$ sudo apt-get install perl python3-tkinter libgtk2.0-dev linux-tools-generic linux-tools-common linux-tools-`uname -r`- Install BCC (see instructions)
- Install G2
# Clone repository git clone https://gerrit.fd.io/r/vpp cd vpp git reset --hard 4146c65f0dd0b5412746064f230b70ec894d2980 # Setup cd src libtoolize aclocal autoconf automake --add-missing autoreconf # Install cd ../build-root make --silent g2-install - Install
-
MARPLE is now installed, and can be run by invoking the
marplecommand, as described in the usage section.. When you first use MARPLE, it will create a config file at~/.marpleconfig. If you have installed G2 manually, ensure that the config file has the correct path to your G2 executable. -
You can also run MARPLE unit tests:
$ marple_test
Usage
MARPLE can be separately invoked to either collect or display data.
usage: sudo marple (--collect | --display) [-h] [options]
Or alternatively:
usage: sudo marple (-c | -d) [-h] [options]
You may wish to set an alias in your ~/.bashrc:
alias marple="sudo `which marple`"
Collecting data
usage: sudo marple --collect [-h] [-o OUTFILE] [-t TIME]
subcommand [subcommand ...]
Collect performance data.
optional arguments:
-h, --help show this help message and exit
subcommand interfaces to use for data collection.
When multiple interfaces are specified, they will all
be used to collect data simultaneously.
Users can also define their own groups of interfaces
using the config file.
Built-in interfaces are:
cpusched, disklat, mallocstacks, memleak, memtime,
callstack, ipc, memevents, diskblockrq, perf_malloc,
lib
Current user-defined groups are:
boot: memleak,cpusched,disklat
-o OUTFILE, --outfile OUTFILE
specify the data output file.
By default this will create a directory named
'marple_out' in the current working directory, and
files will be named by date and time.
Specifying a file name will write to the 'marple_out'
directory - pass in a path to override the save
location too.
-t TIME, --time TIME specify the duration for data collection (in seconds)
The subommands are listed below. Each one collects either event-based, stack-based, or 2D point-based data.
cpusched: collect CPU scheduling event-based data.disklat: collect disk latency event-based data.mallocstacks: collectmalloc()call information (including call graph data and size of allocation) as stack-based data.memleak: collect outstanding memory allocation data (including call grap data) as stack-based data.memtime: collect data on memory usage over time as point data.callstack: collect call stack data.ipc: collect inter-process communication (IPC) data via TCP as event-based data.memevents: collect memory accesses (including call graph data) as stack-based data.diskblockrq: collect disk block accesses as event-based data.perf_malloc: collectmalloc()call information (including call graph data) as stack-based data.lib: Not yet implemented.
MARPLE allows simultaneous collection using multiple subcommands at once - they are simply passed as multiple arguments, or as a custom collection group. Users can define custom collection groups by using the config file. When using many subcommands, all data will be written to a single file.
Displaying data
usage: sudo marple --display [-h] [-fg | -tm] [-g2 | -tcp] [-hm | -sp] [-i INFILE]
[-o OUTFILE]
Display collected data in required format
optional arguments:
-h, --help show this help message and exit
-fg, --flamegraph display as flamegraph
-tm, --treemap display as treemap
-g2, --g2 display as g2 image
-tcp, --tcpplot display as TCP plot
-hm, --heatmap display as heatmap
-sp, --stackplot display as stackplot
-i INFILE, --infile INFILE
Input file where collected data to display is stored
-o OUTFILE, --outfile OUTFILE
Output file where the graph is stored
Tree maps and flame graphs can be used to display stack-based data. G2 and TCP plots can be used to display event-based data. Heat maps and stack plots can be used to display 2D point-based data.
In general, MARPLE will not require specification of the display mode - it will determine this itself using defaults in the config file. These can be overriden on a case-by-case basis using the command-line arguments. In particular, if displaying a data file with many data sets, overriding stack-based plots to display as flame graphs by using -fg will result in all stack-based data in that file being displayed as a flame graph for example.
Note that if collecting and displaying data on the same machine, MARPLE remembers the last data file written - in this case, no display options are necessary and simply invoking marple -d will give the correct display.
Design aims
MARPLE consists of two core packages: [data collection](#the-data-collection package) and data visualisation. These two share some common modules. Two key aims of the design are:
-
Ease-of-use: the user should not have to be concerned with the underlying tools used to analyse system performance. Instead, they simply specify the part of the system they would like to analyse, and MARPLE does the rest.
-
Separation of data collection and visualisation: the data collection module writes a data file to disk, which is later used by the visualisation module. Importantly, these two phases do not need to be run on the same machine. This allows data to be collected by one user, and sent off elsewhere for analysis by another user.
The workflow for using MARPLE is as follows:
-
Collect data - specify areas of interest and duration of collection as command line arguments, and MARPLE will collect data and write it to disk.
-
(optional) Transfer collected data to another machine - the data can be moved to another machine and still viewed.
-
Display data - specify the input data file, and MARPLE will automatically select the best visualiser to display this data. Alternatively, defaults can be set in the configuration file or pass as command line arguments.
Data collection tools used by MARPLE
There are a few different tools used to collect data, and the interfaces to these are detailed below.
Perf
Sometimes referred to as perf-events, perf is a Linux performance-analysis tool built into Linux from kernel version 2.6.31. It has many subcommands and can be difficult to use.
Currently, MARPLE can collect data on the following aspects of the system using perf:
- Memory: load and store events (with call graph information)
- Memory: calls to malloc (with call graph information)
- Stack: stack traces
- CPU: scheduling events
- Disk: block requests
For more information on perf, see Brendan Gregg's blog.
Iosnoop
This is another Linux tool, designed for usage on Linux kernel versions 3.2 and later. It is part of Brendan Gregg's perf-tools, which use perf and another Linux tool called ftrace. Iosnoop itself uses ftrace, and traces disk IO. MARPLE therefore uses iosnoop to trace disk latency.
eBPF and BCC
[Berkeley Packet Filter](https://prototype-kernel.readthedocs.io/en/latest/bpf/ | Extended Berkeley Packet Filter) (eBPF) is derived from the [https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/networking/filter.txt](Berkeley Packet Filter) (BPF, also known as Linux Socket Filtering or LSF). BPF allows a user-space program to filter any socket, blocking and allowing data based on any criteria. BPF programs are executed in-kernel by a sandboxed virtual machine. Linux makes this process relatively straightforward compared to other UNIX flavours such as BSD - the user simply has to write the code for the filter, then send it to the kernel using a specific function call.
eBPF has extended BPF to give a general in-kernel virtual machine, with hooks throughout the kernel allowing it to trace more than just packets, and do more actions than simple filtering. The user writes a program, which is compiled to BPF bytecode and sent to the kernel. The kernel then ensures that an eBPF program cannot harm the system, using static analysis before loading to ensure that it terminates and is safe to execute. It then uses BPF to execute the program, making use of kernel-/user-space probes for dynamic tracing (kprobes and uprobes respectively) and other tracepoints for static tracing and more (see the eBPF workflow diagram). The eBPF programs also use eBPF maps, a generic data structure for storing resulting information. A single eBPF program can be attached to many events, and many programs can use a single map (and vice-versa). Linux kernel versions 3.15 and onwards support eBPF.
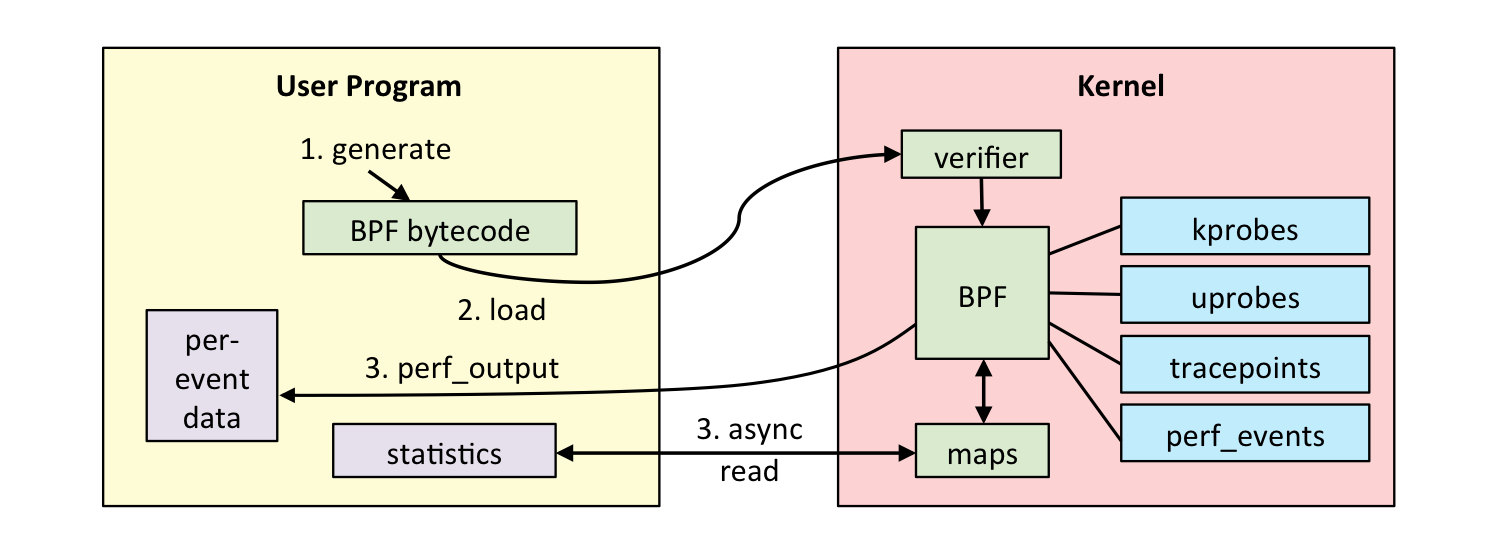
Figure: The worflow of using eBPF.
The BPF Compiler Collection (BCC) is a "toolkit for creating efficient kernel tracing and manipulation programs", generally requiring Linux kernel version 4.1 or higher. BCC uses eBPF extensively, and makes it simpler to write eBPF programs by providing a Python interfaces to the various tools. The eBPF programs are written in C, and handled in strings in the BCC code. Many useful example tools are provided too (see the diagram below).
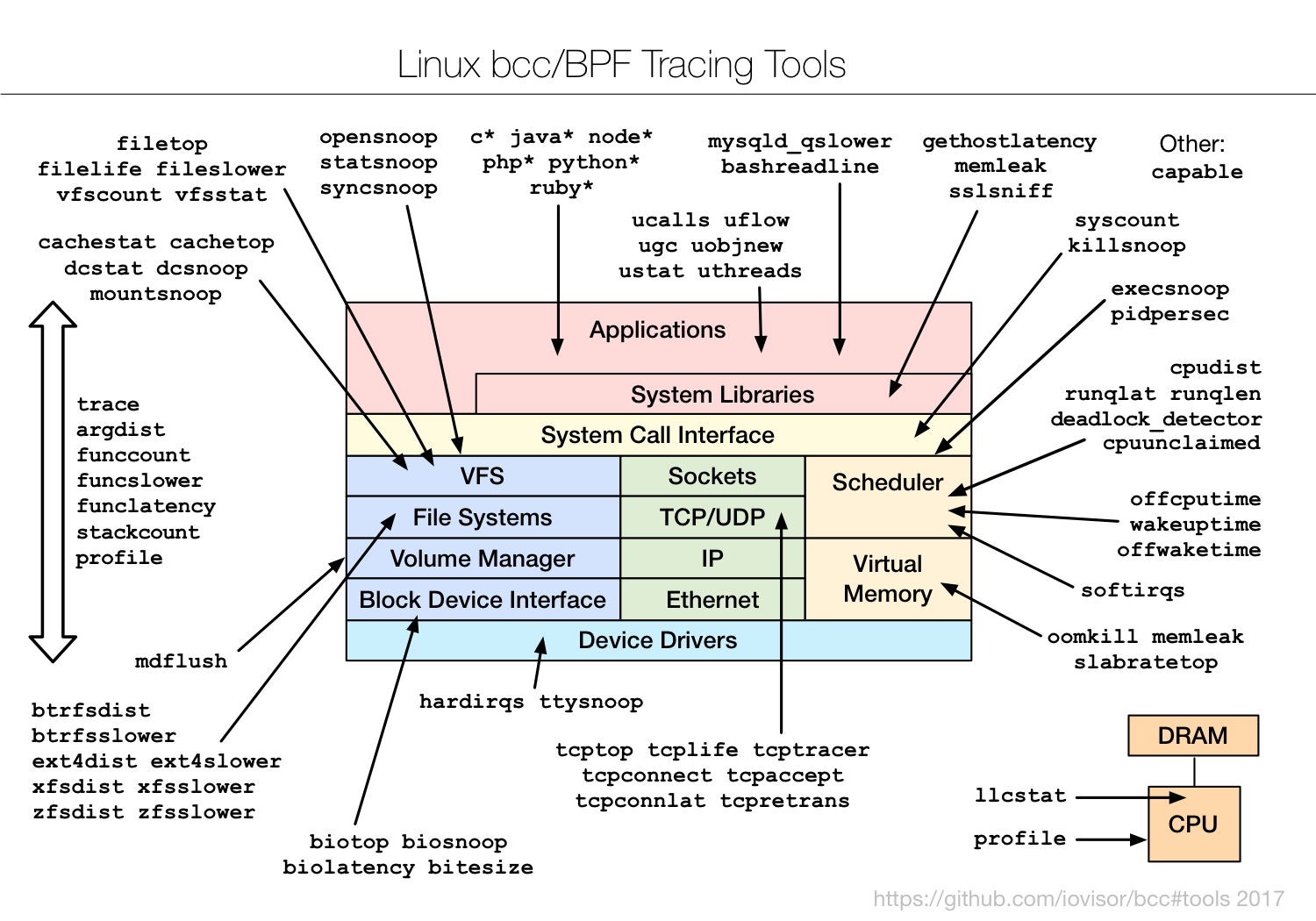
Figure: The BCC tools collection.
Currently, MARPLE uses the following BCC tools:
mallocstacks- traceslibcmalloc()function calls for memory allocation, and shows call stacks and the total number of bytes allocated.memleak- traces the top outstanding memory allocations, allowing for detection of memory leaks.tcptracer- traces TCPconnect(),accept(), andclose()system call. In MARPLE this is used to monitor inter-process communication (IPC) which uses TCP.
For more information on these tools, see Brendan Gregg's blog.
Smem
The smem memory reporting tool allows the user to track physical memory usage, and takes into account shared memory pages (unlike many other tools). It requires a Linux kernel which provides the "Proportional Set Size" (PSS) metric for reporting a process' proportion of shared memory - this is usually version 2.6.27 or higher. MARPLE uses smem to regularly sample memory usage.
The tool has a very high latency - it was initially used as it helpfully sorts the processes recorded by memory usage. This is not strictly necessary however, so a command such as top could be used in its place. Alternatively, the smemcap is a lightweight version designed to run on resource-constrained systems - see the bottom of the man page.
Data visualisation tools used by MARPLE
Flamegraphs
Brendan Gregg's flame graphs are a useful visualisation for profiled software, as they show call stack data. An example taken from Brendan Gregg's website is below. Flame graphs are interactive, allowing the user to zoom in to a certain process.

Figure: An example flame graph, showing CPU usage for a MySQL program.
In general any form of stack data is easily viewed as a flame graph.
Tree maps
Tree maps, like flamegraphs, are a useful visualisation tool for call stack data. Unlike flame graphs, which show all levels of the current call stack at any one time, tree maps display only a single level, giving users a more detailed view of that level and the opportunity to drill down into deeper levels. These tree maps are interactive, allowing the user to see useful information on hover, and drill down into each node of the tree. An example tree map .html file can be found here.
Heat maps
Heat maps allow three-dimensional data to be visualised, using colour as a third dimension. In MARPLE, heat maps are used as histograms - data is grouped into buckets, and colour is used to represent the amount of data falling in each bucket.

Figure: An example heat map, showing disk latency data.
G2
G2 is an event-log viewer. It is very efficient and scalable, and is part of the Vector Packet Processing (VPP) platform. This is a framework providing switch/router functionality, and is the open-source version of Cisco's VPP technology.
See below for an example G2 window.

Figure: An example G2 window, showing scheduling event data.
G2 has many display features, a few of these are listed below.
- Pressing the 'c' key will colour the graph.
- Multiple 'tracks' of events are displayed, and their labels are shown on the left. In the figure above, the tracks are CPU cores.
- The events are ordered chronologically, with a timescale at the bottom of the screen.
- Event types can be hidden/shown using the checkboxes on the right.
- There are navigational and search controls along the bottom of the screen, and in the lower-right conrner.
For more information, consult the G2 wiki.
Stack plots
Stack plots (also known as stacked graphs or stacked charts) show 'parts to the whole'. They are effectively line graphs subdivided to show the various components that make up the overall line value. They can be seen as a form of pie chart, but one that changes with respect to another dimension (usually time). An example stack plot is shown below.

Figure: An example stack plot, showing memory usage by process over time.
Miscellaneous
- MARPLE logs can be found in
/var/log/marple/.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file marple-0.1.dev1.tar.gz.
File metadata
- Download URL: marple-0.1.dev1.tar.gz
- Upload date:
- Size: 117.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.11.0 pkginfo/1.4.2 requests/2.19.1 setuptools/40.2.0 requests-toolbelt/0.8.0 tqdm/4.25.0 CPython/3.6.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
efd68a990fb86f33be1dc0622a996a6c1fc307b4019cbd2d8f84dd07badd3d86
|
|
| MD5 |
65de90123a89524f32e544cb1c05e1eb
|
|
| BLAKE2b-256 |
6c9af49797f56d6e83e605b7bc0accd1fb6fadbf674d69fe99553c37244f2b4f
|
File details
Details for the file marple-0.1.dev1-py3-none-any.whl.
File metadata
- Download URL: marple-0.1.dev1-py3-none-any.whl
- Upload date:
- Size: 144.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.11.0 pkginfo/1.4.2 requests/2.19.1 setuptools/40.2.0 requests-toolbelt/0.8.0 tqdm/4.25.0 CPython/3.6.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3a9c87d927bfff9cc7d4d4c532135f097a46d455c88ea43552099d468b5f37f3
|
|
| MD5 |
f169ff9a099115c0df44829468468640
|
|
| BLAKE2b-256 |
492f9134c0e61fa884870f68bb21e053448bdc1cb8c66293eb3485c5e0318fd9
|







