Data-driven materials discovery based on composition or structure.

Project description
DiSCoVeR















A materials discovery algorithm geared towards exploring high performance candidates in new chemical spaces using composition-only.
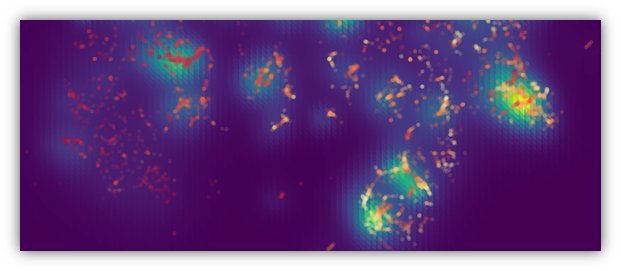
Bulk modulus values overlaid on DensMAP densities (cropped).
The documentation describes the Descending from Stochastic Clustering Variance Regression (DiSCoVeR) algorithm, how to install mat_discover, and basic usage (fit/predict, custom or built-in datasets, adaptive design, and cluster plots). Interactive plots for several types of
Pareto front plots are available. We also describe how to contribute, and what to do if you run into bugs or have questions. Various examples (including a teaching example), the interactive figures mentioned, and the Python API are also hosted at https://mat-discover.readthedocs.io. The open-access article is published at Digital Discovery. If you find this useful, please consider citing as follows:
Citing
Baird, S. G.; Diep, T. Q.; Sparks, T. D. DiSCoVeR: A Materials Discovery Screening Tool for High Performance, Unique Chemical Compositions. Digital Discovery 2022. https://doi.org/10.1039/D1DD00028D.
@article{bairdDiSCoVeRMaterialsDiscovery2022,
title = {{{DiSCoVeR}}: A {{Materials Discovery Screening Tool}} for {{High Performance}}, {{Unique Chemical Compositions}}},
shorttitle = {{{DiSCoVeR}}},
author = {Baird, Sterling Gregory and Diep, Tran Q. and Sparks, Taylor D.},
year = {2022},
month = feb,
journal = {Digital Discovery},
publisher = {{RSC}},
issn = {2635-098X},
doi = {10.1039/D1DD00028D},
abstract = {We present Descending from Stochastic Clustering Variance Regression (DiSCoVeR) (https://github.com/sparks-baird/mat_discover), a Python tool for identifying and assessing high-performing, chemically unique compositions relative to existing compounds using a combination of a chemical distance metric, density-aware dimensionality reduction, clustering, and a regression model. In this work, we create pairwise distance matrices between compounds via Element Mover's Distance (ElMD) and use these to create 2D density-aware embeddings for chemical compositions via Density-preserving Uniform Manifold Approximation and Projection (DensMAP). Because ElMD assigns distances between compounds that are more chemically intuitive than Euclidean-based distances, the compounds can then be clustered into chemically homogeneous clusters via Hierarchical Density-based Spatial Clustering of Applications with Noise (HDBSCAN*). In combination with performance predictions via Compositionally-Restricted Attention-Based Network (CrabNet), we introduce several new metrics for materials discovery and validate DiSCoVeR on Materials Project bulk moduli using compound-wise and cluster-wise validation methods. We visualize these via multi-objective Pareto front plots and assign a weighted score to each composition that encompasses the trade-off between performance and density-based chemical uniqueness. In addition to density-based metrics, we explore an additional uniqueness proxy related to property gradients in DensMAP space. As a validation study, we use DiSCoVeR to screen materials for both performance and uniqueness to extrapolate to new chemical spaces. Top-10 rankings are provided for the compound-wise density and property gradient uniqueness proxies. Top-ranked compounds can be further curated via literature searches, physics-based simulations, and/or experimental synthesis. Finally, we compare DiSCoVeR against the naive baseline of random search for several parameter combinations in an adaptive design scheme. To our knowledge, this is the first time automated screening has been performed with explicit emphasis on discovering high-performing, novel materials.},
langid = {english},
}
If you use this software, in addition to the above reference, please also cite the Zenodo DOI and state the version that you used:
Sterling Baird. (2022). sparks-baird/mat_discover. Zenodo. https://doi.org/10.5281/zenodo.5594678
@software{sterling_baird_2022_6116258,
author = {Sterling Baird},
title = {sparks-baird/mat\_discover},
month = feb,
year = 2022,
publisher = {Zenodo},
doi = {10.5281/zenodo.5594678},
url = {https://doi.org/10.5281/zenodo.5594678}
}
If you use this software as an installed dependency in another GitHub repository, please add mat_discover to a requirements.txt file in your repository via e.g.:
pip install pipreqs
pipreqs .
pipreqs generates (at least a starting point) for a requirements.txt file based on import statements in your working directory and subfolders. For an example, see requirements.txt.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mat_discover-2.2.9.tar.gz.
File metadata
- Download URL: mat_discover-2.2.9.tar.gz
- Upload date:
- Size: 18.1 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.31.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
519033f5a585728538b4448dfe455dd76b7779f563ffd77df5f643f34ff8b529
|
|
| MD5 |
a06fb93506fba02ed47ff05e15612e8f
|
|
| BLAKE2b-256 |
a77ea8a3a7b58cc6a6018695852ab9932f4bcf3ee47d0c31d58803023d082694
|
File details
Details for the file mat_discover-2.2.9-py2.py3-none-any.whl.
File metadata
- Download URL: mat_discover-2.2.9-py2.py3-none-any.whl
- Upload date:
- Size: 83.8 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: python-requests/2.31.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bc8fe1d92bc98589aba1be1108cb381e5446c402a3305805396205f3bc2da520
|
|
| MD5 |
b3b51a31922dbc2f05b1a6e11395c597
|
|
| BLAKE2b-256 |
d91d6eb37d4075e8358c4779c99f1dcbc9caede99015af08c75692289eca96d8
|







