Generative materials benchmarking metrics, inspired by CDVAE.

Project description







This is not an official repository of Matbench, but eventually, it may be incorporated into Matbench
matbench-genmetrics 
Generative materials benchmarking metrics, inspired by guacamol and CDVAE.
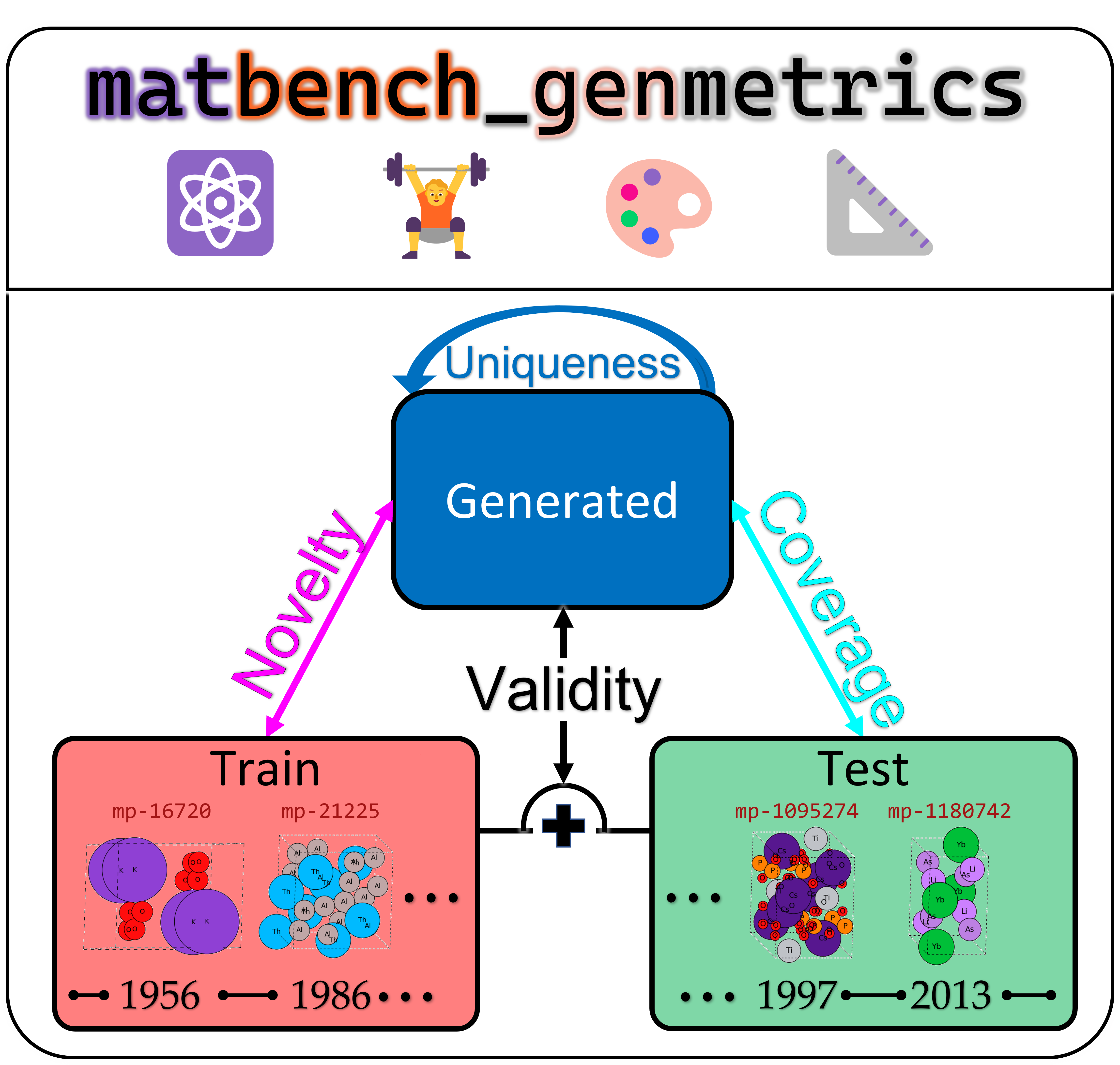
This repository provides standardized benchmarks for benchmarking generative models for crystal structure. Each benchmark has a fixed dataset, a predefined split, and notions of best (i.e. metrics) associated with it.
NOTE: This project is separate from https://matbench-discovery.materialsproject.org/ which provides a slick leaderboard and package for benchmarking ML models on crystal stability prediction from unrelaxed structures. This project instead looks at assessing the quality of generative models for crystal structures.
Getting Started
Installation, a dummy example, output metrics for the example, and descriptions of the benchmark metrics.
Installation
pip install matbench-genmetrics
See Advanced Installation for more information.
Example
NOTE: be sure to set
dummy=Falsefor the real/full benchmark run.MPTSMetrics10is intended for fast prototyping and debugging, as it assumes only 10 generated structures.
>>> from matbench_genmetrics.mp_time_split.utils.gen import DummyGenerator
>>> from matbench_genmetrics.core.metrics import MPTSMetrics10, MPTSMetrics100, MPTSMetrics1000, MPTSMetrics10000
>>> mptm = MPTSMetrics10(dummy=True)
>>> for fold in mptm.folds:
>>> train_val_inputs = mptm.get_train_and_val_data(fold)
>>> dg = DummyGenerator()
>>> dg.fit(train_val_inputs)
>>> gen_structures = dg.gen(n=mptm.num_gen)
>>> mptm.evaluate_and_record(fold, gen_structures)
>>> print(mptm.recorded_metrics)
{
0: {
"validity": 0.4375,
"coverage": 0.0,
"novelty": 1.0,
"uniqueness": 0.9777777777777777,
},
1: {
"validity": 0.4390681003584229,
"coverage": 0.0,
"novelty": 1.0,
"uniqueness": 0.9333333333333333,
},
2: {
"validity": 0.4401197604790419,
"coverage": 0.0,
"novelty": 1.0,
"uniqueness": 0.8222222222222222,
},
3: {
"validity": 0.4408740359897172,
"coverage": 0.0,
"novelty": 1.0,
"uniqueness": 0.8444444444444444,
},
4: {
"validity": 0.4414414414414415,
"coverage": 0.0,
"novelty": 1.0,
"uniqueness": 0.9111111111111111,
},
}
Metrics
| Metric | Description |
|---|---|
| Validity | A loose measure of how "valid" the set of generated structures are by comparing the space group number distribution of the generated structures with the benchmark data. Formally, this is one minus (Wasserstein distance between distribution of space group numbers for train and generated structures divided by distance of dummy case between train and space_group_number == 1). See also https://github.com/sparks-baird/matbench-genmetrics/issues/44 |
| Coverage | A form of "rediscovery", where structures from the future that were held out were "discovered" by the generative model, i.e., when the generative model "predicted the future". Formally, this is the match counts between held-out test structures and generated structures divided by number of test structures. |
| Novelty | A measure of how novel the generated structures are relative to the structures that were used to train the generative model. Formally, this is one minus (match counts between train structures and generated structures divided by number of generated structures). |
| Uniqueness | A measure of whether the generative model is suggesting repeat structures or not. Formally, this is one minus (non-self-comparing match counts within generated structures divided by total possible non-self-comparing matches). |
A match is when StructureMatcher(stol=0.5, ltol=0.3, angle_tol=10.0).fit(s1, s2) evaluates to True.
Detailed descriptions of the metrics are given on the Metrics page.
We performed a "slow march of time" benchmarking study, which uses the mp-time-split data from a future fold as the "generated" structures for the previous fold. The results are presented in the charts below. See the corresponding notebook for details.

Advanced Installation
PyPI (pip) installation
Create and activate a new conda environment named matbench-genmetrics (-n) with python==3.11.* or your preferred Python version, then install matbench-genmetrics via pip.
conda create -n matbench-genmetrics python==3.11.*
conda activate matbench-genmetrics
pip install matbench-genmetrics
Editable installation
In order to set up the necessary environment:
-
clone and enter the repository via:
git clone https://github.com/sparks-baird/matbench-genmetrics.git cd matbench-genmetrics
-
create and activate a new conda environment (optional, but recommended)
conda env create --name matbench-genmetrics python==3.11.* conda activate matbench-genmetrics
-
perform an editable (
-e) installation in the current directory (.):pip install -e .
NOTE: Some changes, e.g. in
setup.cfg, might require you to runpip install -e .again.
Optional and needed only once after git clone:
-
install several pre-commit git hooks with:
pre-commit install # You might also want to run `pre-commit autoupdate`
and checkout the configuration under
.pre-commit-config.yaml. The-n, --no-verifyflag ofgit commitcan be used to deactivate pre-commit hooks temporarily. -
install nbstripout git hooks to remove the output cells of committed notebooks with:
nbstripout --install --attributes notebooks/.gitattributes
This is useful to avoid large diffs due to plots in your notebooks. A simple
nbstripout --uninstallwill revert these changes.
Then take a look into the scripts and notebooks folders.
Dependency Management & Reproducibility
-
Always keep your abstract (unpinned) dependencies updated in
environment.ymland eventually insetup.cfgif you want to ship and install your package viapiplater on. -
Create concrete dependencies as
environment.lock.ymlfor the exact reproduction of your environment with:conda env export -n matbench-genmetrics -f environment.lock.yml
For multi-OS development, consider using
--no-buildsduring the export. -
Update your current environment with respect to a new
environment.lock.ymlusing:conda env update -f environment.lock.yml --prune
Project Organization
├── AUTHORS.md <- List of developers and maintainers.
├── CHANGELOG.md <- Changelog to keep track of new features and fixes.
├── CONTRIBUTING.md <- Guidelines for contributing to this project.
├── Dockerfile <- Build a docker container with `docker build .`.
├── LICENSE.txt <- License as chosen on the command-line.
├── README.md <- The top-level README for developers.
├── configs <- Directory for configurations of model & application.
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
├── docs <- Directory for Sphinx documentation in rst or md.
├── environment.yml <- The conda environment file for reproducibility.
├── models <- Trained and serialized models, model predictions,
│ or model summaries.
├── notebooks <- Jupyter notebooks. Naming convention is a number (for
│ ordering), the creator's initials and a description,
│ e.g. `1.0-fw-initial-data-exploration`.
├── pyproject.toml <- Build configuration. Don't change! Use `pip install -e .`
│ to install for development or to build `tox -e build`.
├── references <- Data dictionaries, manuals, and all other materials.
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated plots and figures for reports.
├── scripts <- Analysis and production scripts which import the
│ actual PYTHON_PKG, e.g. train_model.
├── setup.cfg <- Declarative configuration of your project.
├── setup.py <- [DEPRECATED] Use `python setup.py develop` to install for
│ development or `python setup.py bdist_wheel` to build.
├── src
│ └── matbench_genmetrics <- Actual Python package where the main functionality goes.
├── tests <- Unit tests which can be run with `pytest`.
├── .coveragerc <- Configuration for coverage reports of unit tests.
├── .isort.cfg <- Configuration for git hook that sorts imports.
└── .pre-commit-config.yaml <- Configuration of pre-commit git hooks.
Note
This project has been set up using PyScaffold 4.2.2.post1.dev2+ge50b5e1 and the dsproject extension 0.7.2.post1.dev2+geb5d6b6.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file matbench-genmetrics-0.6.5.tar.gz.
File metadata
- Download URL: matbench-genmetrics-0.6.5.tar.gz
- Upload date:
- Size: 4.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
87b885fb8cb8f71e8e94c135874e10c826e00362a539d3f8c7f459a7cb759997
|
|
| MD5 |
9273f7a5ec57db3a50c9d1555029fd43
|
|
| BLAKE2b-256 |
ada6ded44dac75e3a91ea61d751990bb330b3847648a7cd7912dc436bdc28bd5
|
File details
Details for the file matbench_genmetrics-0.6.5-py3-none-any.whl.
File metadata
- Download URL: matbench_genmetrics-0.6.5-py3-none-any.whl
- Upload date:
- Size: 51.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ffd943ee85a14035d899dc90d69d240cde36ec5b055fa1b39fe598b58d084283
|
|
| MD5 |
782572342e511517956bc79ccb4cea80
|
|
| BLAKE2b-256 |
db1b11428538da10a1d0aff210aa487e7ffe555eef0a41f5a661a9c52f13f9b1
|







