An heterogeneous deep learning compiler framework.

Project description
EdgeCortix® MERA™ - A heterogeneous deep learning compiler framework
This repository contains the source code for the frontend stack of EdgeCortix® MERA™ compiler framework, developed by EdgeCortix Inc.. If you are interested in the latest (bleeding edge) capabilities of MERA™ framework and the different Dynamic Neural Accelerator® architecture configurations, contact EdgeCortix AI Accelerator Team.
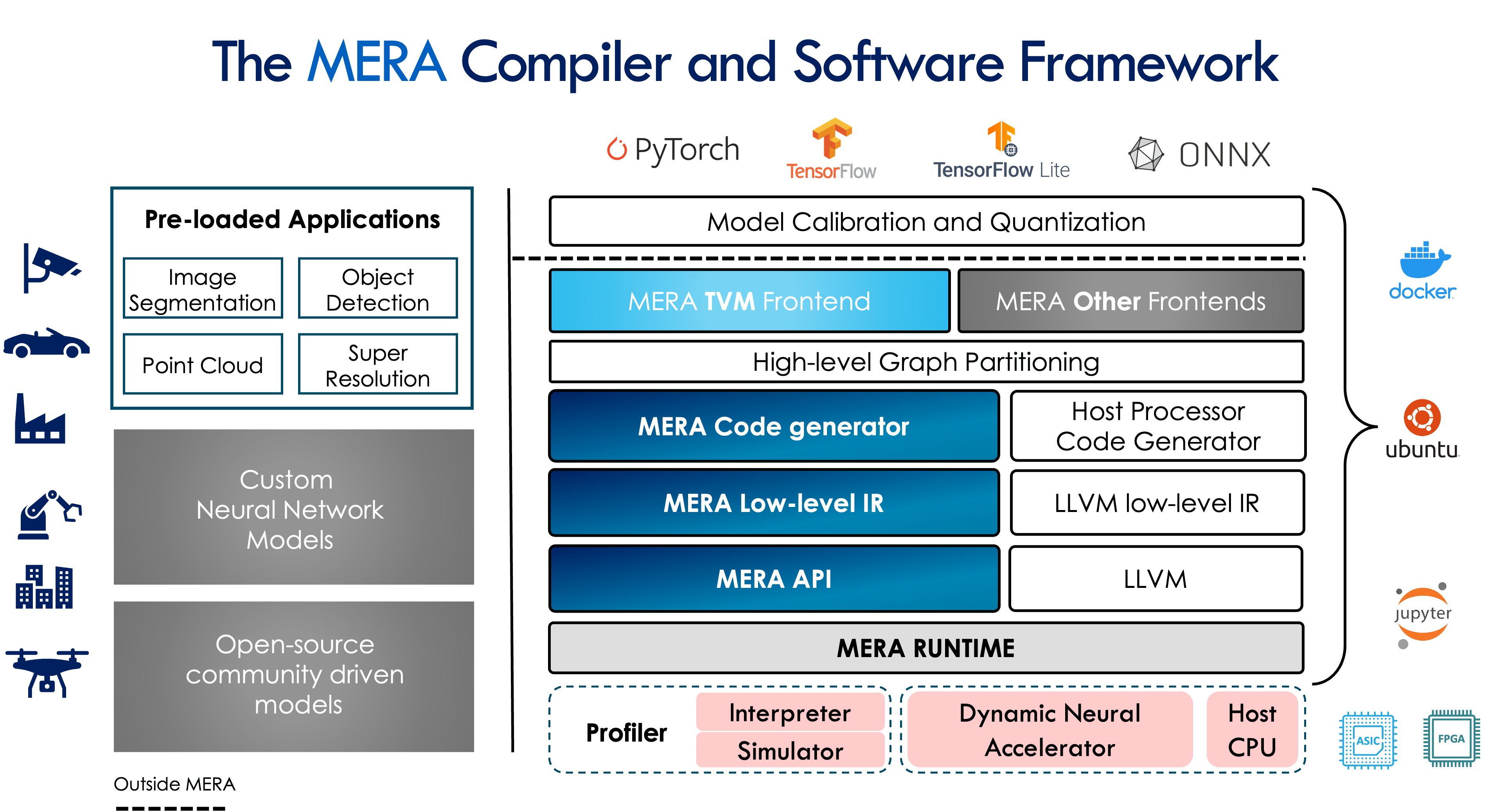
The current release of EdgeCortix® MERA™ supports the following Dynamic Neural Accelerator architectures for FPGAs and ASICs:
| Platform Identifiers | Platform | TOPS | TFLOPS |
|---|---|---|---|
| SAKURA_1 | ASIC | 40 | N/A |
| SAKURA_II | ASIC | 60 | 30 |
When using a platform identifier corresponding to the ASIC platforms, the recommended minimum frequency setting is 800 MHz. In the case of FPGA platforms, the minimum recommended frequency is 300 MHz. In the above table, the TOPS corresponds to these minimum frequency specifications.
Installation Guide
This document describes the steps needed to install MERA in your system.
Quick installation of MERA on Ubuntu 20.04 LTS
To install MERA for Python 3.8 and all its dependencies source the provided script:
source install/install-mera-py38.sh
Quick installation of MERA on Ubuntu 22.04 LTS
To install MERA for Python 3.10 and all its dependencies source the provided script:
source install/install-mera-py310.sh
Manual Installation
If the install-mera.sh script is not enough for your environment, the following section describes how to install
all the dependencies manually in your system.
System Requirements
For an x86 architecture, you will need Ubuntu 20.04 or Ubuntu 22.04 as your OS, whereas for aarch64 you will need Ubuntu 20.04.
The following software packages will also need to be installed:
sudo apt update && sudo apt install llvm-10 libgomp1 ocl-icd-libopencl1 software-properties-common \
libgoogle-glog0v5 libboost-graph-dev virtualenv wget build-essential
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt update
sudo apt install libstdc++6
MERA Installation
The MERA environment provides 3 different modes depending on the target usage:
runtime: Meant for running inference in HW accelerators using the DNA IP, requires extra system dependencies depending on the HW device.full: Meant for users who want the functionality of bothhost-onlyandruntimemodels
MERA pip packages are available for both Python3.8 and Python3.10 variants.
After choosing the desired mode, you can install MERA with the following command:
# Create virtual environment with Python 3.8
MERA_VENV=mera-env
virtualenv -p python3.8 $MERA_VENV
source $MERA_VENV/bin/activate
# Install MERA full version
pip install --upgrade pip
pip install mera[full]
# Install extra dependencies. These are needed to run our tutorials and demos
pip install tqdm easydict wget notebook pandas matplotlib opencv-python gdown seaborn tensorflow_datasets
# Test the installation
$ mera --version
>>> Mera Environment Versions:
* mera version x.y.z released on dd/mm/yyyy
* mera-tvm version x.y.z
* mera-dna version vx.y.z+git=<hash>
mera provides packages for installing in both x86 and aarch64 architectures.
The pip command will also install all the necessary dependencies to perform deployments with MERA. Note that some of the tutorials require some extra
dependencies to be installed. Please check the tutorial's README.md file to check which other packages might be needed.
MERA Documentation
Please follow the instructions in docs on how to generate the HTML documentation for the MERA framework.
Introduction to the MERA Software Stack
The MERA Software Stack provides a full end-to-end deployment framework for EdgeCortix DNA platforms. It provides:
- Import models in PyTorch, TensorFlow/TFLite and ONNX formats.
- Support for INT8 precision models quantized with the official built-in quantization tools of PyTorch and TensorFlow.
- Support for EdgeCortix custom quantization: quantize FP32 models from PyTorch, TensorFlow and ONNX using only MERA Quantizer tools.
- Multi-network support allows to fuse several models together into a single workload to maximize hardware utilization. Several models can be compiled and optimized together into a single deployment binary artifact.
- Several targets to validate models on increasing level optimizations:
- Interpreters to emulate the DNA platform internal math with minimal amount of optimizations.
- Software simulators to perform functional and cycle accurate simulations of the MERA DNA platforms on x86 hardware.
- Targets to generate binary deployments for FPGA and ASIC.
- Different user configurable levels of optimization for fast development, validation and testing.
- Separate PIP packages for different scenarios. Separate packages for model compilation and inference runtime.
MERA compiler framework targets
Several targets are supported by the MERA Software Stack:
-
InterpreterHw: simplest node by node execution of the computational graph with minimal graph fusion and model parameters processing. This target only emulates the way the accelerator IP does the math operations in fixed-point precision.
-
Simulator: for this target more passes are enabled and several local and global optimizations are applied to the computational graph. Further lowering into accelerator instructions together with scheduling, allocation, synchronization and instruction encoding produce assembly programs that can be run with the C++ simulator which provides a functional simulation of the selected accelerator IP.
-
IP: further encoding into binary instructions and binary artifacts that can be consumed by real hardware. This target is suitable for both FPGA and ASIC IPs. The differences between both are determined in the compiler thanks to the mera.Platform code names that can be specified during compilation as, for example, mera.Platform.DNAF200L0003 for an FPGA IP case or mera.Platform.DNAA600L0002 for an ASIC IP.
-
VerilatorSimulator: this target generates binary encoding of the instructions and executes the generated program on a RTL Verilator based cycle accurate library.
Deploying models with MERA
For futher details on how to deploy models with MERA software stack please refer to the tutorials and the API reference.
Improving inference time
There are extra compilation options available that can improve the final inference time. During deployment, it is possible to specify these options as part of the compiler configuration. Usually the compilation options provide the IP model for either ASIC or FPGA:
#
# Compilation options example for ASIC IP
#
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.SAKURA_1,
target=Target.IP,
host_arch="x86")
#
# Compilation options example for FPGA IP
#
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.DNAF200L0003,
target=Target.IP,
host_arch="x86")
These examples assume some default compiler options, in particular, the Fast scheduling mode, which provides fast compilation times but not the best inference times.
NOTE: To facilitate testing of the MERA software stack all the tutorials and scripts use the fast scheduling mode. To get the best latency for production environments please use the high effort scheduling mode instead.
In order to improve the performance of our deployments we can specify extra scheduler and memory allocator options, this is known as the Slow scheduler mode. This mode increases the effort made by the scheduler and allocation algorithms to get a better utilization of the DNA IPs by searching better instruction schedules and reducing memory bank conflicts during memory allocation.
Examples of better compiler configuration are:
#
# Better compilation options
#
build_config = {
"compiler_workers": 4,
"scheduler_config": {
"mode": "Slow",
}
}
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.SAKURA_1,
target=Target.IP,
host_arch="x86",
build_config=build_config) # new option
These options provide a trade off between compilation time and inference time but in general higher compilation time should improve the performance of the model being deployed.
NOTE: There are no changes in neither model accuracy or model outputs while using the different scheduling modes. It is guaranteed that the outputs of a model that has been compiled in two different scheduling modes will be exactly the same.
Depending on the nature of the model there will be different rooms for improvement.
NOTE: During development and early deployment of a model it is recommended to use the fast scheduler mode as this mode will provide the best compilation times. Once the deployment scripts has been validated, switch to the Slow scheduler mode is a trivial change that will only reduce the latency of the model while giving exactly the same model outputs than the fast scheduling mode.
RTL based cycle accurate ASIC simulations
The C++ IP simulator target (Simulator target) is not cycle accurate. We provide a way to perform a fully cycle accurate ASIC IP simulation through a the target named VerilatorSimulator. Please note that these libraries are not publicly available. Please contact the EdgeCortix AI Accelerator Team.
In order to do a cycle accurate simulation it is only necessary to change the target during compilation. We usually choose the Simulator or IP targets:
#
# Compile for FPGA IP hardware
#
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.DNAF200L0003,
target=Target.IP,
host_arch="x86")
#
# Compile for FPGA IP C++ simulator
#
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.DNAF200L0003,
target=Target.Simulator,
host_arch="x86")
In order to compile a model and do a cycle accurate simulation we should choose the following target:
#
# Compile for verilator simulator using the SAKURA 1 ASIC architecture (40 TOPs)
#
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.SAKURA_1,
target=Target.VerilatorSimulator,
host_arch="x86")
Note that choosing this target is independent on the scheduler Slow or Fast modes, both can be used for this target but it is recommended to use the Slow (high effort) scheduling mode for the final compilation that will be used to benchmark a model.
In summary, the required configuration to perform a cycle accurate ASIC IP simulation for the SAKURA_1 architecture, with high effort scheduling mode, are the following changes:
#
# Compile for verilator simulator using the SAKURA_1 ASIC architecture (40 TOPs)
# With high effort compilation mode (slow scheduling mode)
#
build_config = {
"compiler_workers": 4,
"scheduler_config": {
"mode": "Slow",
}
}
with mera.TVMDeployer(output_dir, overwrite=True) as deployer:
model = ...
deploy_ip = deployer.deploy(
model,
mera_platform=Platform.SAKURA_1,
target=Target.VerilatorSimulator,
host_arch="x86",
build_config=build_config)
The inference times are now more accurate. We observe that in general the Simulator target takes less time to finish a simulation but it will not give us very accurate inference times. While the RTL based simulation will take much longer to complete but will return more accurate inference times. When possible, RTL based simulations in high effort scheduling mode are recommended for model benchmarking.
MERA Tutorials
The tutorials folder contains a list of tutorials on how to use the MERA Software Stack to deploy and run inference on typical deep neural network models using both PyTorch and TFLite frameworks. Check the corresponding docs for information about the tutorial contents.
Tutorial List
- PyTorch Resnet50 on Simulator (
pytorch/resnet50_simulator.py):
Contains an example on how to deploy and run a traced resnet50 model in x86 host simulation.
Can be executed with the following command:
cd tutorials/pytorch
python3 resnet50_simulator.py
- PyTorch Resnet50 on IP (
pytorch/resnet50_ip.py):
Contains an example on how to deploy and run a traced resnet50 model in FPGA environment.
Needs to have FPGA runtime setup before running.
Can be executed with the following command:
cd tutorials/pytorch
# Needs to enable RUN_IP env in order to actually run the tutorial in HW
RUN_IP=1 python3 resnet50_ip.py
- TFLite EfficientNet on Simulator (
tflite/efficientnet_simulator.py):
Contains an example on how to deploy and run a quantized efficientnet-lite1 and efficientnet-lite4 model in x86 host simulation and run an example object classification.
Can be executed with the following command:
cd tutorials/tflite
python3 efficientnet_simulator.py
- TFLite EfficientNet on IP (
tflite/efficientnet_ip.py):
Contains an example on how to deploy and run a quantized efficientnet-lite1 and efficientnet-lite4 model in
FPGA environment and run an example object classification. Needs to have FPGA runtime setup before running.
Can be executed with the following command:
cd tutorials/tflite
# Needs to enable RUN_IP env in order to actually run the tutorial in HW
RUN_IP=1 python3 efficientnet_ip.py
- Multi-Model Deployment via Simulator (
multi_models/fused_resnet_mobilenet_simulator.py):
Contains an example on how to fuse two quantized PyTorch models (i.e., resnet18 and mobilenet_v2) and then deploy the fused model in x86 host simulation.
Can be executed with the following command:
cd tutorials/multi_models
python3 fused_resnet_mobilenet_simulator.py
- Vision Transformer deployment via Simulator (
tutorials/transformers/detr/):
Shows how to deploy and run the DE:TR vision transformer model using BrainFloat-16 precision on Simulator. Can be executed with the following command:
cd tutorials/transformers/detr
python downloader.py
python deploy.py
python demo_model.py
License
This library is licensed under the Apache License Version 2.0.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mera-1.6.0.post1-cp310-cp310-manylinux_2_27_x86_64.whl.
File metadata
- Download URL: mera-1.6.0.post1-cp310-cp310-manylinux_2_27_x86_64.whl
- Upload date:
- Size: 327.7 kB
- Tags: CPython 3.10, manylinux: glibc 2.27+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 colorama/0.4.4 importlib-metadata/4.6.4 keyring/23.5.0 pkginfo/1.8.2 readme-renderer/34.0 requests-toolbelt/0.9.1 requests/2.25.1 rfc3986/1.5.0 tqdm/4.57.0 urllib3/1.26.5 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a72515bb9bd1a44c36ede576641e070b8fd14d1a6a25055c1dc2b96398673622
|
|
| MD5 |
7e51d9b763a1e1e88b846295be503712
|
|
| BLAKE2b-256 |
236a6aaabaae604da19f1177681fc164890a1983f5437a91c46413b94890bbbe
|
File details
Details for the file mera-1.6.0.post1-cp38-cp38-manylinux_2_27_x86_64.whl.
File metadata
- Download URL: mera-1.6.0.post1-cp38-cp38-manylinux_2_27_x86_64.whl
- Upload date:
- Size: 328.0 kB
- Tags: CPython 3.8, manylinux: glibc 2.27+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 colorama/0.4.4 importlib-metadata/4.6.4 keyring/23.5.0 pkginfo/1.8.2 readme-renderer/34.0 requests-toolbelt/0.9.1 requests/2.25.1 rfc3986/1.5.0 tqdm/4.57.0 urllib3/1.26.5 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b2e648a188aaa9504b7e63a52aac54fa2bf325e6a6f0cf00bc727417088dd8ae
|
|
| MD5 |
5c6f7d50e0db5fd8d1bf1e30e18f3846
|
|
| BLAKE2b-256 |
56a6148c8ef88b076925300e92ddaa4f38a972f2705e12f94e6ad524edefa52b
|







