Package to merge tokens from different tokenizers.

Project description
🤝 Merge-Tokenizers



Algorithm suite to align tokens from different tokenizations
📖 Introduction
In some use cases, we need to align the tokens of a text tokenized with multiple tokenizers that have different vocabularies. For instance, we could need to align token-level features like probabilities or hidden states from different models, but each model could have a different tokenizer. This repo contains merge-tokenizers, a package aimed to align tokens from multiple tokenizers by providing a set of algorithms like Dynamic Time Warping or greedy approaches based on text distances or word ids.
As an example, look how the text "This is how preprocesssing wooorks" is tokenized by roberta-base and bert-base-uncased tokenizers:
roberta-base: ['[s]', 'this', 'Ġis', 'Ġhow', 'Ġpre', 'process', 'sing', 'Ġwoo', 'orks', '[s]']
bert-base-uncased: ['[CLS]', 'this', 'is', 'how', 'prep', '##ro', '##ces', '##ssing', 'woo', '##or', '##ks', '[SEP]']
and how one alignment between them can look:
alignment (tokens): [('[s]', ['[CLS]']), ('this', ['this']), ('Ġis', ['is']), ('Ġhow', ['how']), ('Ġpre', ['prep']), ('process', ['##ro', '##ces']), ('sing', ['##ssing']), ('Ġwoo', ['woo']), ('orks', ['##or', '##ks']), ('[s]', ['[SEP]'])]
alignment (positions): [(0, [0]), (1, [1]), (2, [2]), (3, [3]), (4, [4]), (5, [5, 6]), (6, [7]), (7, [8]), (8, [9, 10]), (9, [11])]
🔧 Installation
Requirement: python >= 3.8
Install with pip
$ pip install merge-tokenizers
Install from source
$ pip install -e .
🎨 Current algorithms
Actually, there are 6 algorithms implemented in merge-tokenizers:
Dynamic Time Warping (DTW): a dynamic programming algorithm to compute the optimal, $\mathcal{O}(N^2)$, alignment between two signals that may vary in speed. DTW is applied to two texts, considering text distances between the tokens of each text. merge-tokenizers provides a C and a Python (numba jit) implementation of DTW.
FastDTW: applies an approximate DTW algorithm that provides optimal or near-optimal alignments with an $\mathcal{O}(N)$ time and memory complexity, using a Bag of Character representation of each token and cosine/euclidean distance.
Tamuhey: computes alignments using the Myer's algorithm following this procedure. Thanks to Yohei Tamura and his repo.
Word ids: aligns two tokenized texts using the word_ids provided by HuggingFace tokenizers. This algorithm do not use token distances, and instead tries to match all the tokens of the same word from both texts in order, using a modified version of the posting list intersection algorithm.
Greedy-distance: matches each token in a text $x$ with the tokens in a surrounding window of another text $y$, according to the following equation if word_ids are passed:
$$\textrm{match}(x_i) = \underset{{i-k\leq j\leq i+k}}{\textrm{min}}\ \textrm{dist}(x_i, y_j) * s_{ij}$$
$$s_{ij} = 1\ \textrm{if}\ \textrm{word-id}(x_i)=\textrm{word-id}(y_j),\ \infty\ otherwise$$
or the following equation if word_ids are not passed:
$$\textrm{match}(x_i) = \underset{i-k\leq j\leq i+k}{\textrm{min}}\ \textrm{dist}(x_i, y_j)$$
It is recommended to use a large radius k (e.g., 30) to avoid introducing matching errors at the end of the sequence if the "speed" of the tokenizations varies a lot.
Greedy-coverage: aligns the tokens from two different tokenizers, using a greedy matching algorithm based on text coverage. This algorithm first remove whitespaces from the text, and finds the char positions (start, end) that each token covers in the text without whitespaces. This step can be avoided if you pass the char spans that each token covers, for instance, using token_to_chars from HuggingFace tokenizers. Once we have the lists of (start, end) for each token and for each tokenization, we merge the tokens of the second tokenization that are spanned by the tokens of the first tokenization. For instance, having computed $spans_a$ = [(0, 5), (5, 13), (13, 23)] and $spans_b$ = [(0, 4), (5, 8), (8, 11), (11, 14), (15, 19), (19, 21), (21, 23)], the alignment will be [(0, [0]), (1, [1, 2, 3]), (2, [4, 5, 6])]. merge-tokenizers provides a C and a Python implementation of this algorithm.
🔎 What algorithm should I use?
To determine what aligner should be used in a specific use case, you have to consider four main factors:
- Speed: how fast is the aligner, which is specially relevant for long sequences.
- Quality: how good are the alignments produced by the aligner. Quality is related with optimality, most of the aligners provided in
merge-tokenizersrely on dynamic programming approaches which compute optimal solutions (alignments with the lowest distance), but some of them relax the problem to be faster, thus loosing optimality. - Constraints: whether the aligner imposes some constraints like using word_ids provided by the tokenizers (not all the tokenizers provide this)
- Failure points: some aligners does not work well under specific situations, for instance, missing alignments of some tokens when the tokenizations are very dissimilar. These situations could lead the user to implement custom solutions for feature merging, like including random tokens in empty alignments.
The following table categorizes each approach according to these factors.
| Speed | Optimal | Quality | Constraints | Failure points | |
|---|---|---|---|---|---|
| C-DTW | medium | yes | high | none | none |
| Py-DTW | low | yes | high | none | none |
| Fast-DTW | medium | no | high | none | none |
| Tamuhey | high | no | high | none | Missing alignments when the tokenizations are very dissimilar (both in tokens and in length) |
| Greedy-distance | medium | no | medium | none | none |
| Greedy-coverage | high | no | high | none | none |
| Word-ids | high | no | medium | Tokenizer must return word_ids | none |
To delve more on the speed factor, the following plot depicts the speed (seconds in logarithmic scale) that each aligner takes to align one pair of tokenizations, with different token lengths (6 examples averaged on 100 runs).
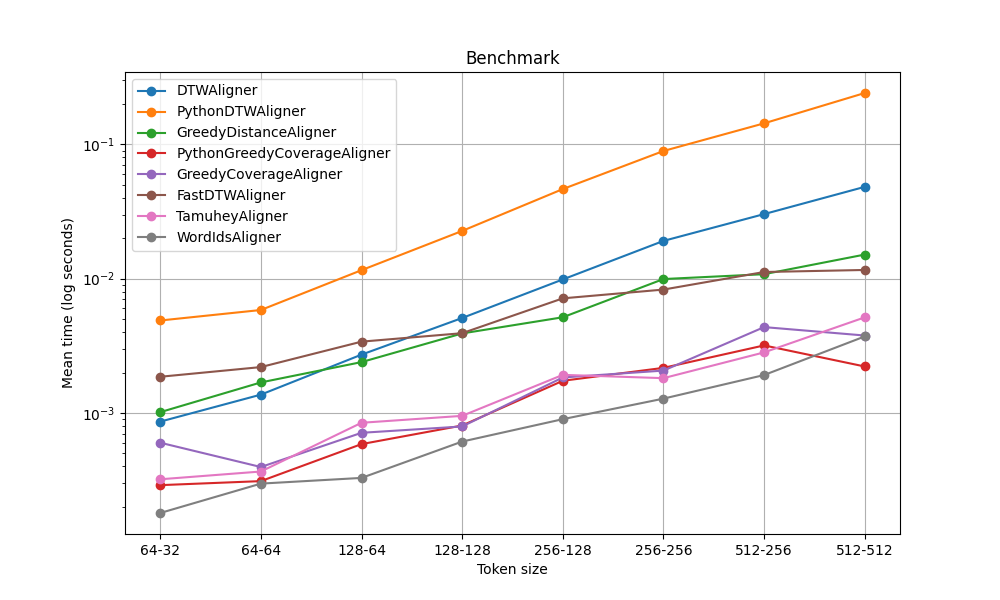
You can also look the results of the benchmark in assets/benchmark.md and run it as python scripts/benchmark.py after intalling merge-tokenizers.
👀 Quick Tour
Let's illustrate how the aligners provided by merge-tokenizers can be used to align a text tokenized with three different tokenizers, where each tokenization has its own associated token-level features. The whole code of this guide can be found in scripts/example.py.
Note that you need to install transformers to use the tokenizers of the example.
Prepare the use case
First, prepare the tokenization for this use case:
import numpy as np
from transformers import AutoTokenizer
# Load tokenizers.
tokenizer_1 = AutoTokenizer.from_pretrained("roberta-base")
tokenizer_2 = AutoTokenizer.from_pretrained("bert-base-uncased")
tokenizer_3 = AutoTokenizer.from_pretrained("openai-community/gpt2")
# Tokenize a text.
text = "this is how preprocesssing wooorks"
tokenized_1 = tokenizer_1([text])
tokenized_2 = tokenizer_2([text])
tokenized_3 = tokenizer_3([text])
# Get the tokens of a text.
tokens_1 = tokenized_1.tokens()
tokens_2 = tokenized_2.tokens()
tokens_3 = tokenized_3.tokens()
# Get word_ids (only tokenizers that allow it)
# which can be used only in aligners based on word_ids
# like `WordIdsAligner`
word_ids_1 = tokenized_1.word_ids()
word_ids_2 = tokenized_2.word_ids()
word_ids_3 = tokenized_3.word_ids()
# Here we have features associated to each token,
# e.g., token probabilities or hidden states.
dim = 3
features_1 = np.random.rand(len(tokens_1), dim)
features_2 = np.random.rand(len(tokens_2), dim)
features_3 = np.random.rand(len(tokens_3), dim)
Align two tokenizations
We can instantiate a DTW aligner and align two tokenizations, e.g., the one from roberta-base with the one from bert-base-uncased. This can be done just by calling the align method of the aligner and getting the first result.
# Let's align two tokenized texts with the aligner based on DTW.
aligner = DTWAligner("levenshtein")
alignment = aligner.align(TokenizedSet(tokens=[tokens_1, tokens_2]))[0]
The result is an Alignment object, containing the position and token matches between the two tokenizations:
# Print position matches
print(list(alignment))
# [(0, [0]), (1, [1]), (2, [2]), (3, [3]), (4, [4, 5]), (5, [6]), (6, [7]), (7, [8]), (8, [9, 10]), (9, [11])]
# Print token matches
print(list(alignment.__tokens__()))
#[('<s>', ['[CLS]']), ('this', ['this']), ('Ġis', ['is']), ('Ġhow', ['how']), ('Ġpre', ['prep', '##ro']), ('process', ['##ces']), ('sing', ['##ssing']), ('Ġwoo', ['woo']), ('orks', ['##or', '##ks']), ('</s>', ['[SEP]'])]
Align multiple tokenizations
The align method allows also to align multiple tokenizers at once. This is done by picking the first tokenizer as reference and align the other ones with it. Therefore, the output is a list of alignments, where the length of each alignment matches the length of the tokenization used as reference.
alignments = aligner.align(TokenizedSet(tokens=[tokens_1, tokens_2, tokens_3]))
# Print position matches
print([list(alignment) for alignment in alignments])
# > [(0, [0]), (1, [1]), (2, [2]), (3, [3]), (4, [4, 5]), (5, [6]), (6, [7]), (7, [8]), (8, [9, 10]), (9, [11])]
# > [(0, [0]), (1, [0]), (2, [1]), (3, [2]), (4, [3]), (5, [4]), (6, [5]), (7, [6]), (8, [7]), (9, [7])]]
# Print token matches
print([list(alignment.__tokens__()) for alignment in alignments])
# > [('<s>', ['[CLS]']), ('this', ['this']), ('Ġis', ['is']), ('Ġhow', ['how']), ('Ġpre', ['prep', '##ro']), ('process', ['##ces']), ('sing', ['##ssing']), ('Ġwoo', ['woo']), ('orks', ['##or', '##ks']), ('</s>', ['[SEP]'])]
# > [('<s>', ['this']), ('this', ['this']), ('Ġis', ['Ġis']), ('Ġhow', ['Ġhow']), ('Ġpre', ['Ġpre']), ('process', ['process']), ('sing', ['sing']), ('Ġwoo', ['Ġwoo']), ('orks', ['orks']), ('</s>', ['orks'])]
Aggregating features of two tokenizations
merge-tokenizers allows you too to aggregate features associated to the tokens of each tokenization. The aligners provides a method called aggregate_features to aggregate the features. This method aligns tokenizations and merges the features to match the shape of the first tokenization provided. The following example shows how to aggregate features from two tokenizations:
# We can merge features associated to each tokenization.
# With `stack` = True we can stack all the features in a numpy array,
# otherwise the result will be a list of features after aligning tokens.
aggregated_features = aligner.aggregate_features(
TokenizedSet(tokens=[tokens_1, tokens_2], features=[features_1, features_2]),
stack=True,
)
assert (
aggregated_features.shape[0] == len(tokens_1)
and aggregated_features.shape[1] == dim * 2
)
Aggregating features from multiple tokenizations
Under the same philosophy than aligning multiple tokenizations, the aggregate_features method allows you to aggregate features from multiple tokenizers. This is done by aligning all the tokenizations with the first one, and then aggregating the features of each tokenization to match the first tokenization:
aggregated_features = aligner.aggregate_features(
TokenizedSet(
tokens=[tokens_1, tokens_2, tokens_3],
features=[features_1, features_2, features_3],
),
stack=True,
)
assert (
aggregated_features.shape[0] == len(tokens_1)
and aggregated_features.shape[1] == dim * 3
)
Using all the current aligners
The following code illustrates how to use all the current aligners.
# Let's test all the aligners
dtw_aligner = DTWAligner(distance_name="levenshtein")
dtw_py_aligner = PythonDTWAligner(distance_name="levenshtein")
greedy_distance_aligner = GreedyDistanceAligner(distance_name="levenshtein")
py_greedy_coverage_aligner = PythonGreedyCoverageAligner()
greedy_coverage_aligner = GreedyCoverageAligner()
fastdtw_aligner = FastDTWAligner(distance_name="euclidean")
tamuhey_aligner = TamuheyAligner()
word_ids_aligner = WordIdsAligner()
aligned_dtw = dtw_aligner.align(TokenizedSet(tokens=[tokens_1, tokens_2]))[0]
aligned_py_dtw = dtw_py_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2])
)[0]
aligned_greedy_distance = greedy_distance_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2])
)[0]
aligned_py_greedy_coverage = py_greedy_coverage_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2], text=text)
)[0]
aligned_greedy_coverage = greedy_coverage_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2], text=text)
)[0]
aligned_fastdtw = fastdtw_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2])
)[0]
aligned_tamuhey = tamuhey_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2])
)[0]
aligned_word_ids = word_ids_aligner.align(
TokenizedSet(tokens=[tokens_1, tokens_2], word_ids=[word_ids_1, word_ids_2])
)[0]
print("C-DTW:", list(aligned_dtw.__tokens__()))
print("PY-DTW:", list(aligned_py_dtw.__tokens__()))
print("Greedy-distance:", list(aligned_greedy_distance.__tokens__()))
print("PY-Greedy-coverage:", list(aligned_py_greedy_coverage.__tokens__()))
print("C-Greedy-coverage:", list(aligned_greedy_coverage.__tokens__()))
print("FastDTW:", list(aligned_fastdtw.__tokens__()))
print("Tamuhey:", list(aligned_tamuhey.__tokens__()))
print("WordIds:", list(aligned_word_ids.__tokens__()))
Defining new aligners
You can implement your own aligners by writing a class inheriting from Aligner within a new module in merge_tokenizers/aligners.
Aligners are required to implement just one method called align_pair which computes an alignment between two tokenizations that are wrapped in a TokenizedPair object, containing the tokens, the preprocessed tokens (automatically computed by the base aligner), the word_ids and token-level features if required. Therefore align_pair takes a TokenizedPair as input and returns an Alignment.
Take a look at merge_tokenizers/aligners/tamuhey.py to have a reference about how to define your custom aligners.
🙏 Contribute
Feel free to contribute to merge-tokenizers by raising an issue.
Please, use the dev-tools for correctly formatting the code when contributing to this repo.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file merge-tokenizers-0.0.6.tar.gz.
File metadata
- Download URL: merge-tokenizers-0.0.6.tar.gz
- Upload date:
- Size: 28.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
137d6c68fbd04bbfeb204ee0098e645c4bb578e97955d8401bf06af7aa91f8ea
|
|
| MD5 |
fac44e65b71acbaf85f30eff81798bd4
|
|
| BLAKE2b-256 |
8da4f95a8ad51488f8bf52c0787c5324919056dd98321b8af5d02a6e0e3f76ac
|







