A minimal cluster computing framework

Project description
“minimal” here means minimal dependency or platform requirements, as well as its nature of “minimum viable product”. It’s mainly for tackling straightforward “embarrassingly parallel” tasks using multiple commodity machines, also a good choice for experimental and learning purposes. The idea came from Eli Bendersky’s blog .
minimalcluster is built only using plain Python and its standard libraries (mainly multiprocessing). This brings a few advantages, including
no additional installation or configuration is needed
100% cross-platform (you can even have Linux, MacOS, and Windows nodes within a single cluster).
This package can be used with Python 2.7+ or 3.6+. But within a cluster, you can only choose a single version of Python, either 2 or 3.
For more frameworks for parallel or cluster computing, you may also want to refer to Parallel Processing and Multiprocessing in Python .
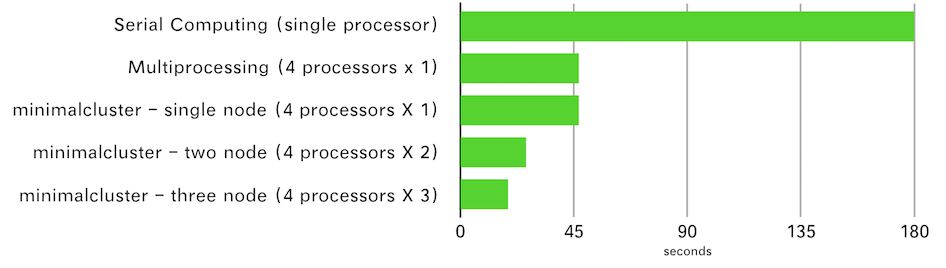
Benchmarking
Usage & Examples
Step 1 - Install this package
pip install minimalclusterStep 2 - Start master node
Open your Python terminal on your machine which will be used as Master Node, and run
from minimalcluster import MasterNode
your_host = '<your master node hostname or IP>'
# or use '0.0.0.0' if you have high enough privilege
your_port= <port to use>
your_authkey = '<the authkey for your cluster>'
master = MasterNode(HOST = your_host, PORT = your_port, AUTHKEY = your_authkey)
master.start_master_server()Please note the master node will join the cluster as worker node as well by default. If you prefer otherwise, you can have argument if_join_as_worker in start_master_server() to be False. In addition, you can also remove it from the cluster by invoking master.stop_as_worker() and join as worker node again by invoking master.join_as_worker().
Step 3 - Start worker nodes
On all your Worker Nodes, run the command below in your Python terminal
from minimalcluster import WorkerNode
your_host = '<your master node hostname or IP>'
your_port= <port to use>
your_authkey = '<the authkey for your cluster>'
N_processors_to_use = <how many processors on your worker node do you want to use>
worker = WorkerNode(your_host, your_port, your_authkey, nprocs = N_processors_to_use)
worker.join_cluster()Note: if your nprocs is bigger than the number of processors on your machine, it will be changed to be the number of processors.
After the operations on the worker nodes, you can go back to your Master node and check the list of connected Worker nodes.
master.list_workers()Step 5 - Submit jobs
Now your cluster is ready. you can try the examples below in your Python terminal on your Master node.
Example 1 - Estimate value of Pi
envir_statement = '''
from random import random
example_pi_estimate_throw = lambda x: 1 if (random() * 2 - 1)**2 + (random() * 2 - 1)**2 < 1 else 0
'''
master.load_envir(envir_statement, from_file = False)
master.register_target_function("example_pi_estimate_throw")
N = int(1e6)
master.load_args(range(N))
result = master.execute()
print("Pi is roughly %f" % (4.0 * sum([x2 for x1, x2 in result.items()]) / N))Example 2 - Factorization
envir_statement = '''
# A naive factorization method. Take integer 'n', return list of factors.
# Ref: https://eli.thegreenplace.net/2012/01/24/distributed-computing-in-python-with-multiprocessing
def example_factorize_naive(n):
if n < 2:
return []
factors = []
p = 2
while True:
if n == 1:
return factors
r = n % p
if r == 0:
factors.append(p)
n = n / p
elif p * p >= n:
factors.append(n)
return factors
elif p > 2:
p += 2
else:
p += 1
assert False, "unreachable"
'''
#Create N large numbers to factorize.
def make_nums(N):
nums = [999999999999]
for i in range(N):
nums.append(nums[-1] + 2)
return nums
master.load_args(make_nums(5000))
master.load_envir(envir_statement, from_file = False)
master.register_target_function("example_factorize_naive")
result = master.execute()
for x in result.items()[:10]: # if running on Python 3, use `list(result.items())` rather than `result.items()`
print(x)Example 3 - Feed multiple arguments to target function
It’s possible that you need to feed multiple arguments to target function. A small trick will be needed here: you need to wrap your arguments into a tuple, then pass the tuple to the target function as a “single” argument. Within your argument function, you can “unzip” this tuple and obtain your arguments.
envir_statement = '''
f = lambda x:x[0]+x[1]
'''
master.load_envir(envir_statement, from_file = False)
master.register_target_function("f")
master.load_args([(1,2), (3,4), (5, 6), (7, 8)])
result = master.execute()
print(result)Step 6 - Shutdown the cluster
You can shutdown the cluster by running
master.shutdown()Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file minimalcluster-0.1.0.dev13-py2.py3-none-any.whl.
File metadata
- Download URL: minimalcluster-0.1.0.dev13-py2.py3-none-any.whl
- Upload date:
- Size: 14.6 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
34c85045d43f8959f78037f16af3a65cee0dee85033be198679c13abf4f44d78
|
|
| MD5 |
f0be742558da8a5a3cd1a6f077712c8d
|
|
| BLAKE2b-256 |
15e0c307375c9dfa0002672b61af8695016a66c54d5d723075a0927ecd9f383f
|







