Mixture of Diffusers for scene composition and high resolution image generation .

Project description
Mixture of Diffusers



This repository holds various scripts and tools implementing a method for integrating a mixture of different diffusion processes collaborating to generate a single image. Each diffuser focuses on a particular region on the image, taking into account boundary effects to promote a smooth blending.
If you prefer a more user friendly graphical interface to use this algorithm, I recommend trying the Tiled Diffusion & VAE plugin developed by pkuliyi2015 for AUTOMATIC1111's stable-diffusion-webui.
Motivation
Current image generation methods, such as Stable Diffusion, struggle to position objects at specific locations. While the content of the generated image (somewhat) reflects the objects present in the prompt, it is difficult to frame the prompt in a way that creates an specific composition. For instance, take a prompt expressing a complex composition such as
A charming house in the countryside on the left, in the center a dirt road in the countryside crossing pastures, on the right an old and rusty giant robot lying on a dirt road, by jakub rozalski, sunset lighting on the left and center, dark sunset lighting on the right elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece
Out of a sample of 20 Stable Diffusion generations with different seeds, the generated images that align best with the prompt are the following:
 |
 |
 |
The method proposed here strives to provide a better tool for image composition by using several diffusion processes in parallel, each configured with a specific prompt and settings, and focused on a particular region of the image. For example, the following are three outputs from this method, using the following prompts from left to right:
- "A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
- "A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
- "An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"


The mixture of diffusion processes is done in a way that harmonizes the generation process, preventing "seam" effects in the generated image.
Using several diffusion processes in parallel has also practical advantages when generating very large images, as the GPU memory requirements are similar to that of generating an image of the size of a single tile.
Usage
This repository provides two new pipelines, StableDiffusionTilingPipeline and StableDiffusionCanvasPipeline, that extend the standard Stable Diffusion pipeline from Diffusers. They feature new options that allow defining the mixture of diffusers, which are distributed as a number of "diffusion regions" over the image to be generated. StableDiffusionTilingPipeline is simpler to use and arranges the diffusion regions as a grid over the canvas, while StableDiffusionCanvasPipeline allows a more flexible placement and also features image2image capabilities.
Prerequisites
Since this work is based on Stable Diffusion models, you will need to request access and accept the usage terms of Stable Diffusion. You will also need to configure your Hugging Face User Access Token in your running environment.
StableDiffusionTilingPipeline
The header image in this repo can be generated as follows
from diffusers import LMSDiscreteScheduler
from mixdiff import StableDiffusionTilingPipeline
# Creater scheduler and model (similar to StableDiffusionPipeline)
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipeline = StableDiffusionTilingPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, use_auth_token=True).to("cuda:0")
# Mixture of Diffusers generation
image = pipeline(
prompt=[[
"A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
"A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
"An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
]],
tile_height=640,
tile_width=640,
tile_row_overlap=0,
tile_col_overlap=256,
guidance_scale=8,
seed=7178915308,
num_inference_steps=50,
)["sample"][0]
The prompts must be provided as a list of lists, where each list represents a row of diffusion regions. The geometry of the canvas is inferred from these lists, e.g. in the example above we are creating a grid of 1x3 diffusion regions (1 row and 3 columns). The rest of parameters provide information on the size of these regions, and how much they overlap with their neighbors.
Alternatively, it is possible to specify the grid parameters through a JSON configuration file. In the following example a grid of 10x1 tiles is configured to generate a forest in changing styles:

A StableDiffusionTilingPipeline is configured to use 10 prompts with changing styles. Each tile takes a shape of 768x512 pixels, and tiles overlap 256 pixels to avoid seam effects. All the details are specified in a configuration file:
{
"cpu_vae": true,
"gc": 8,
"gc_tiles": null,
"prompt": [
[
"a forest, ukiyo-e, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, ukiyo-e, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, by velazquez, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, by velazquez, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, impressionist style by van gogh, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, impressionist style by van gogh, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, cubist style by Pablo Picasso intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, cubist style by Pablo Picasso intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, 80s synthwave style, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors",
"a forest, 80s synthwave style, intricate, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece, impressive colors"
]
],
"scheduler": "lms",
"seed": 639688656,
"steps": 50,
"tile_col_overlap": 256,
"tile_height": 768,
"tile_row_overlap": 256,
"tile_width": 512
}
You can try generating this image using this configuration file by running
python generate_grid_from_json.py examples/linearForest.json
The full list of arguments to a StableDiffusionTilingPipeline is:
prompt: either a single string (no tiling) or a list of lists with all the prompts to use (one list for each row of tiles). This will also define the tiling structure.
num_inference_steps: number of diffusions steps.
guidance_scale: classifier-free guidance.
seed: general random seed to initialize latents.
tile_height: height in pixels of each grid tile.
tile_width: width in pixels of each grid tile.
tile_row_overlap: number of overlap pixels between tiles in consecutive rows.
tile_col_overlap: number of overlap pixels between tiles in consecutive columns.
guidance_scale_tiles: specific weights for classifier-free guidance in each tile.
guidance_scale_tiles: specific weights for classifier-free guidance in each tile. IfNone, the value provided inguidance_scalewill be used.
seed_tiles: specific seeds for the initialization latents in each tile. These will override the latents generated for the whole canvas using the standardseedparameter.
seed_tiles_mode: either"full""exclusive". If"full", all the latents affected by the tile be overriden. If"exclusive", only the latents that are affected exclusively by this tile (and no other tiles) will be overrriden.
seed_reroll_regions: a list of tuples in the form (start row, end row, start column, end column, seed) defining regions in pixel space for which the latents will be overriden using the given seed. Takes priority overseed_tiles.
cpu_vae: the decoder from latent space to pixel space can require too mucho GPU RAM for large images. If you find out of memory errors at the end of the generation process, try setting this parameter toTrueto run the decoder in CPU. Slower, but should run without memory issues.
A script showing a more advanced use of this pipeline is available as generate_grid.py.
StableDiffusionCanvasPipeline
The StableDiffusionCanvasPipeline works by defining a list of Text2ImageRegion objects that detail the region of influence of each diffuser. As an illustrative example, the heading image at this repo can be generated with the following code:
from diffusers import LMSDiscreteScheduler
from mixdiff import StableDiffusionCanvasPipeline, Text2ImageRegion
# Creater scheduler and model (similar to StableDiffusionPipeline)
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipeline = StableDiffusionCanvasPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, use_auth_token=True).to("cuda:0")
# Mixture of Diffusers generation
image = pipeline(
canvas_height=640,
canvas_width=1408,
regions=[
Text2ImageRegion(0, 640, 0, 640, guidance_scale=8,
prompt=f"A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"),
Text2ImageRegion(0, 640, 384, 1024, guidance_scale=8,
prompt=f"A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"),
Text2ImageRegion(0, 640, 768, 1408, guidance_scale=8,
prompt=f"An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"),
],
num_inference_steps=50,
seed=7178915308,
)["sample"][0]
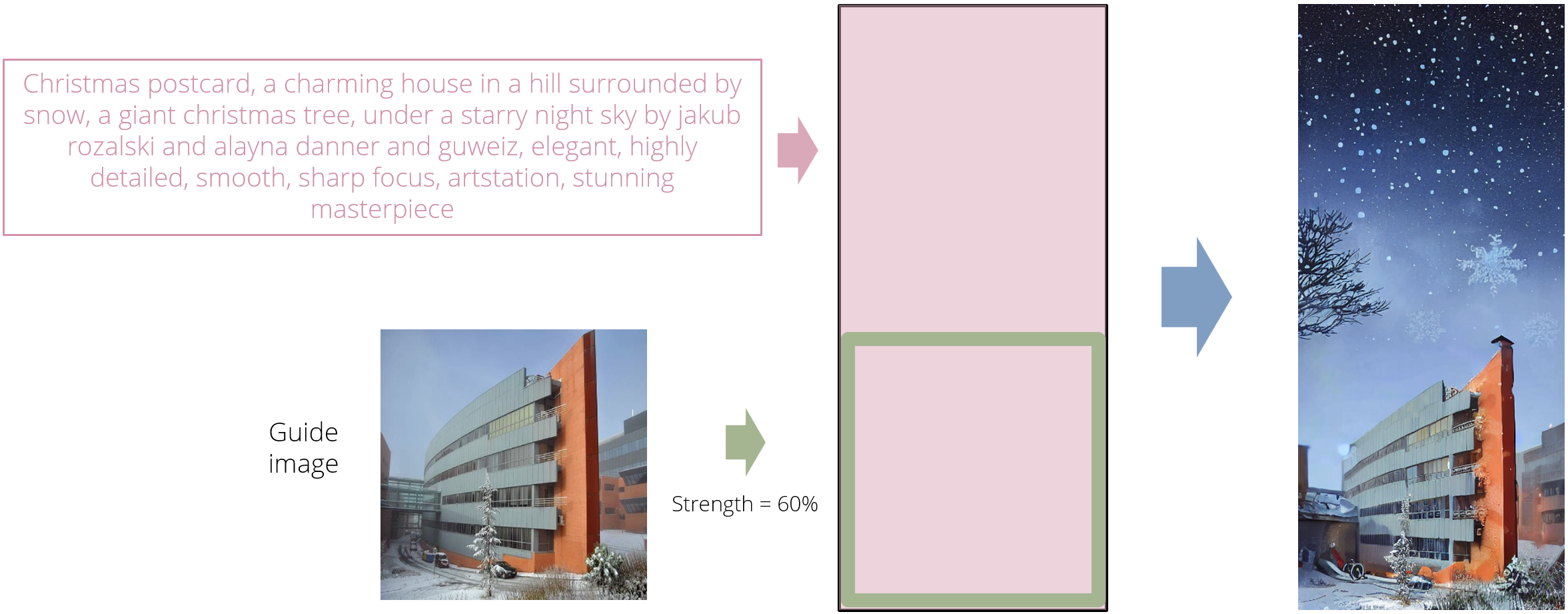
Image2Image regions can also be added at any position, to use a particular image as guidance. In the following example we create a Christmas postcard by taking a photo of a building (available at this repo) and using it as a guidance in a region of the canvas.
from PIL import Image
from diffusers import LMSDiscreteScheduler
from mixdiff import StableDiffusionCanvasPipeline, Text2ImageRegion, Image2ImageRegion, preprocess_image
# Creater scheduler and model (similar to StableDiffusionPipeline)
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipeline = StableDiffusionCanvasPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, use_auth_token=True).to("cuda:0")
# Load and preprocess guide image
iic_image = preprocess_image(Image.open("examples/IIC.png").convert("RGB"))
# Mixture of Diffusers generation
image = pipeline(
canvas_height=800,
canvas_width=352,
regions=[
Text2ImageRegion(0, 800, 0, 352, guidance_scale=8,
prompt=f"Christmas postcard, a charming house in the countryside surrounded by snow, a giant christmas tree, under a starry night sky, by jakub rozalski and alayna danner and guweiz, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"),
Image2ImageRegion(800-352, 800, 0, 352, reference_image=iic_image, strength=0.8),
],
num_inference_steps=57,
seed=5525475061,
)["sample"][0]
The full list of arguments to a StableDiffusionCanvasPipeline is:
canvas_height: height in pixels of the image to generate. Must be a multiple of 8.
canvas_width: width in pixels of the image to generate. Must be a multiple of 8.
regions: list ofText2ImageorImage2Imagediffusion regions (see below).
num_inference_steps: number of diffusions steps.
seed: general random seed to initialize latents.
reroll_regions: list ofRerollRegionregions in which to reroll latents (see below). Useful if you like the overall aspect of the generated image, but want to regenerate a specific region using a different random seed.
cpu_vae: whether to perform encoder-decoder operations in CPU, even if the diffusion process runs in GPU. Usecpu_vae=Trueif you run out of GPU memory at the end of the generation process for large canvas dimensions, or if you create largeImage2Imageregions.
decode_steps: ifTruethe result will include not only the final image, but also all the intermediate steps in the generation. Note: this will greatly increase running times.
All regions are configured with the following parameters:
row_init: starting row in pixel space (included). Must be a multiple of 8.
row_end: end row in pixel space (not included). Must be a multiple of 8.
col_init: starting column in pixel space (included). Must be a multiple of 8.
col_end: end column in pixel space (not included). Must be a multiple of 8.
region_seed: seed for random operations in this region
noise_eps: deviation of a zero-mean gaussian noise to be applied over the latents in this region. Useful for slightly "rerolling" latents
Additionally, Text2Image regions use the following arguments:
prompt: text prompt guiding the diffuser in this region
guidance_scale: guidance scale of the diffuser in this region. If None, randomize.
mask_type: kind of weight mask applied to this region, must be one of["constant", gaussian", quartic"].
mask_weight: global weights multiplier of the mask.
Image2Image regions are configured with the basic region parameters plus ther following:
reference_image: image to use as guidance. Must be loaded as a PIL image and pre-processed using thepreprocess_imagefunction (see example above). It will be automatically rescaled to the shape of the region.
strength: strength of the image guidance, must lie in the range[0.0, 1.0](from no guidance to absolute priority of the original image).
Finally, RerollRegions accept the basic arguments plus the following:
reroll_mode: kind of reroll to perform, eitherreset(completely reset latents with new ones) orepsilon(alter slightly the latents in the region).
Citing and full technical details
If you find this repository useful, please be so kind to cite the corresponding paper, which also contains the full details about this method:
Álvaro Barbero Jiménez. Mixture of Diffusers for scene composition and high resolution image generation. https://arxiv.org/abs/2302.02412
Responsible use
The same recommendations as in Stable Diffusion apply, so please check the corresponding model card.
More broadly speaking, always bear this in mind: YOU are responsible for the content you create using this tool. Do not fully blame, credit, or place the responsibility on the software.
Gallery
Here are some relevant illustrations I have created using this software (and putting quite a few hours into them!).
Darkness Dawning

Yog-Sothoth

Looking through the eyes of giants

Follow me on DeviantArt for more!
Acknowledgements
First and foremost, my most sincere appreciation for the Stable Diffusion team for releasing such an awesome model, and for letting me take part of the closed beta. Kudos also to the Hugging Face community and developers for implementing the Diffusers library.
Thanks to Instituto de Ingeniería del Conocimiento and Grupo de Aprendizaje Automático (Universidad Autónoma de Madrid) for providing GPU resources for testing and experimenting this library.
Thanks also to the vibrant communities of the Stable Diffusion discord channel and Lexica, where I have learned about many amazing artists and styles. And to my friend Abril for sharing many tips on cool artists!


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mixdiff-1.1.5.tar.gz.
File metadata
- Download URL: mixdiff-1.1.5.tar.gz
- Upload date:
- Size: 24.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.11.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2912d1a72eb66e0840356c25688b9995a942b680b480125cd36d481fd9a28850
|
|
| MD5 |
014abb53f5835bac5577bc83384f91ce
|
|
| BLAKE2b-256 |
3b1a672e66c3e6c62b47197c91fad5a494020fde0516a9c49d53ef64fe2ebeaa
|
File details
Details for the file mixdiff-1.1.5-py3-none-any.whl.
File metadata
- Download URL: mixdiff-1.1.5-py3-none-any.whl
- Upload date:
- Size: 20.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.11.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8380d39665331699210726337a800160795299ce0c4f0702b7adb9b89c0f667a
|
|
| MD5 |
00b03872d7dd869d89c440c7329145a2
|
|
| BLAKE2b-256 |
07f90439213bdb3684cb4c37aaded8d288bdc11b524f1d179c3e6dae8aa70410
|







