Ml framework.

Project description

Simple ML framework





- Auto ML.
- Unified pipeline.
- Stable CV scheme.
- One configuration file.
- Multi-stage optimization.
Mlshell based on Pycnfg library. All parameters controlled from single Python configuration.
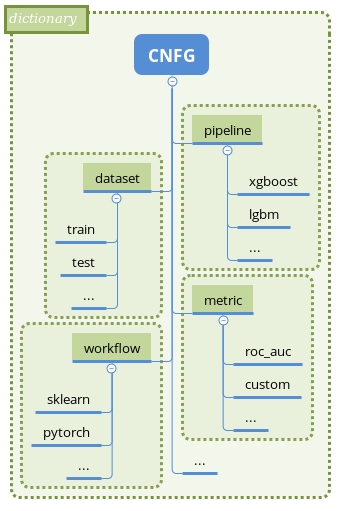
For details, please refer to Concepts.
Installation
PyPi
pip install mlshell
Development installation (tests and docs):
pip install mlshell[dev]
Docker 
docker run -it nizaevka/mlshell
Tested on: Python 3.6+.
Docs
Getting started
example
"""Configuration example - tune LGBM on iris dataset."""
import lightgbm
import mlshell
import pycnfg
import sklearn.datasets
# Optimization hp ranges.
hp_grid = {
'reduce_dimensions__skip': [False, True], # PCA on/off
# 'estimate__classifier__n_estimators': np.linspace(50, 1000, 10, dtype=int),
# ...
}
"""
The single configuration CNFG controls whole ml task.
Each section sub-configurations produce object (pipeline/metric/dataset/workflow)
pipeline-wise:
object init state
=> transform object with steps (producer methods)
=> store result
Sub-configuration with greater priority (workflow) could utilize previously
created objects.
"""
CNFG = {
# Pipeline section - make pipeline object(s).
'pipeline': {
'lgbm': {
'init': mlshell.Pipeline,
'producer': mlshell.PipelineProducer,
'priority': 3,
'steps': [
('make', {
'estimator_type': 'classifier',
'steps': mlshell.pipeline.Steps,
'estimator': lightgbm.sklearn.LGBMClassifier(
num_leaves=5, max_depth=5, n_estimators=100,
random_state=42), # last stage of pipeline.
}),
],
}
},
# Metric section - make scorer object(s).
'metric': {
'accuracy': {
'init': mlshell.Metric,
'producer': mlshell.MetricProducer,
'priority': 4,
'steps': [
('make', {
'score_func': sklearn.metrics.accuracy_score,
'greater_is_better': True,
}),
],
},
'confusion_matrix': {
'init': mlshell.Metric,
'producer': mlshell.MetricProducer,
'priority': 4,
'steps': [
('make', {
'score_func': sklearn.metrics.confusion_matrix,
}),
],
},
},
# Dataset section - dataset loading/preprocessing/splitting.
'dataset': {
'train': {
'init': mlshell.Dataset({
'data': sklearn.datasets.load_iris(as_frame=True).frame
}),
'producer': mlshell.DatasetProducer,
'priority': 5,
'steps': [
('preprocess', {'targets_names': ['target']}),
('split', {'train_size': 0.75, 'shuffle': True,
'random_state': 42}),
],
},
},
# Workflow section
# - fit/predict pipelines on datasets,
# - optimize/validate metrics,
# - predict/dump predictions on datasets.
'workflow': {
'conf': {
'init': {},
'producer': mlshell.Workflow,
'priority': 6,
'steps': [
# Optimize 'lgbm' pipeline on 'train' subset of 'train' dataset
# on hp combinations from 'hp_grid'. Score and refit on
# 'accuracy' scorer.
('optimize', {
'pipeline_id': 'pipeline__lgbm',
'dataset_id': 'dataset__train',
'subset_id': 'train',
'metric_id': ['metric__accuracy'],
'hp_grid': hp_grid,
'gs_params': {
'n_iter': None,
'n_jobs': 1,
'refit': 'metric__accuracy',
'cv': sklearn.model_selection.KFold(n_splits=3,
shuffle=True,
random_state=42),
'verbose': 1,
'pre_dispatch': 'n_jobs',
'return_train_score': True,
},
}),
# Validate 'lgbm' pipeline on 'train' and 'test' subsets of
# 'train' dataset with 'accuracy' and 'confusion_matrix'.
('validate', {
'pipeline_id': 'pipeline__lgbm',
'dataset_id': 'dataset__train',
'subset_id': ['train', 'test'],
'metric_id': ['metric__accuracy',
'metric__confusion_matrix'],
}),
],
},
},
}
if __name__ == '__main__':
# mlshell.CNFG contains default section / configuration keys for typical ml
# task, including pretty logger and project path detection.
objects = pycnfg.run(CNFG, dcnfg=mlshell.CNFG)
Examples
Check examples folder.
Contribution guide
License
Apache License, Version 2.0 LICENSE.

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
mlshell-0.0.2.tar.gz
(42.0 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
mlshell-0.0.2-py3-none-any.whl
(48.6 kB
view details)
File details
Details for the file mlshell-0.0.2.tar.gz.
File metadata
- Download URL: mlshell-0.0.2.tar.gz
- Upload date:
- Size: 42.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.3.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.7.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dd1478c0dabc79749d9962bd457a4cdeaa83eee556f6ffc7c04357444ed2b472
|
|
| MD5 |
f5df3800db710741427c59116f0c0b95
|
|
| BLAKE2b-256 |
4d84dfff8069d22ac0c61fda4fd2e34a280c518405138081e3800d190e6cc1c5
|
File details
Details for the file mlshell-0.0.2-py3-none-any.whl.
File metadata
- Download URL: mlshell-0.0.2-py3-none-any.whl
- Upload date:
- Size: 48.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/50.3.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.7.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d6b9d8764ed4fb0c918ca0166c4fa03ccbff53a8bd9645b14675767dd83dde0d
|
|
| MD5 |
8e0d1048cdae295b7e0bda82580a2610
|
|
| BLAKE2b-256 |
4453fd5471eefca24f0e5d481490b72f77cec1239589111e444b6b9c9f6a1302
|







