MountainSort 5 spike sorting algorithm

Project description
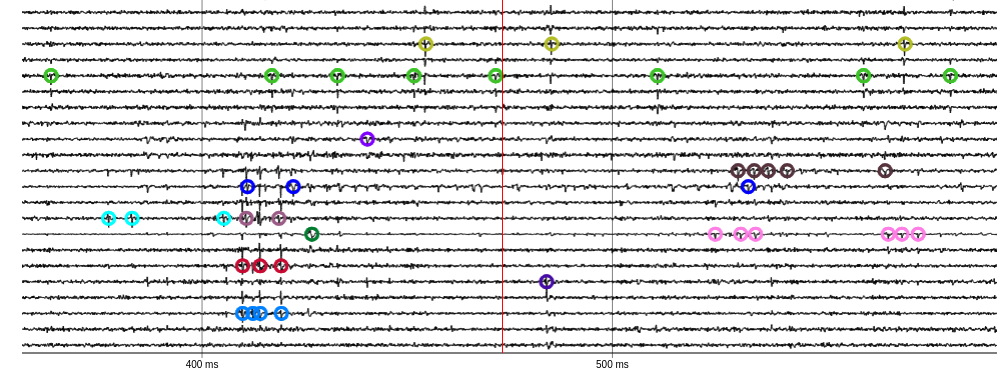
MountainSort 5



This is the most recent version of the MountainSort spike sorting algorithm. An implementation of the previous version of this algorithm can be found here.
- Uses Isosplit clustering
- Runs faster than previous versions, especially for large channel counts
- Better handles time-overlapping events and drifting waveforms
- Runs fast on CPU
- Uses SpikeInterface for I/O and preprocessing
- Supports multiple sorting schemes, each suited for different experimental setups
Installation
pip install --upgrade mountainsort5
Dependencies:
Python, SpikeInterface, scikit-learn, isosplit6
Usage
MountainSort5 utilizes SpikeInterface recording and sorting objects. See the SpikeInterface documentation to learn how you can load and preprocess your ephys data.
Once you have loaded a SpikeInterface recording object, you can run MountainSort5 using the following code:
from tempfile import TemporaryDirectory
import numpy as np
import spikeinterface as si
import spikeinterface.preprocessing as spre
import mountainsort5 as ms5
from mountainsort5.util import create_cached_recording
recording = ... # load your recording using SpikeInterface
# Make sure the recording is preprocessed appropriately
# Note that if the recording traces are of float type, you may need to scale
# it to a reasonable voltage range in order for whitening to work properly
# recording = spre.scale(recording, gain=...)
# lazy preprocessing
recording_filtered = spre.bandpass_filter(recording, freq_min=300, freq_max=6000, dtype=np.float32)
recording_preprocessed: si.BaseRecording = spre.whiten(recording_filtered)
with TemporaryDirectory(dir='/tmp') as tmpdir:
# cache the recording to a temporary directory for efficient reading
recording_cached = create_cached_recording(recording_preprocessed, folder=tmpdir)
# use scheme 1
sorting = ms5.sorting_scheme1(
recording=recording_cached,
sorting_parameters=ms5.Scheme1SortingParameters(...)
)
# or use scheme 2
sorting = ms5.sorting_scheme2(
recording=recording_cached,
sorting_parameters=ms5.Scheme2SortingParameters(...)
)
# or use scheme 3
sorting = ms5.sorting_scheme3(
recording=recording_cached,
sorting_parameters=ms5.Scheme3SortingParameters(...)
)
# Now you have a sorting object that you can save to disk or use for further analysis
To give it a try with simulated data, run the following scripts in the examples directory:
Scheme 1: examples/scheme1/toy_example.py
Scheme 2: examples/scheme2/toy_example.py
Scheme 3: examples/scheme3/toy_example.py
To give it a try with data collected using Neuropixels and SpikeGLX, adapt the following quickstart script:
Neuropixel (SpikeGLX) Quickstart: examples/neuropixel_quickstart/spikeglx.py
Preprocessing
MountainSort5 is designed to operate on preprocessed data. You should bandpass filter and whiten the recording as shown in the examples. SpikeInterface provides a variety of lazy preprocessing tools so that intermediate files do not need to be stored to disk.
Sorting schemes
MountainSort5 is organized into three sorting schemes. Different schemes are appropriate for different experimental setups.
Sorting scheme 1
This is the simplest sorting scheme and is useful for quick tests. The entire recording is loaded into memory, and clustering is performed in a single pass. In general, scheme 1 should only be used for testing and debugging as scheme 2 does a better job handling events that overlap in time, and works with larger datasets on limited RAM systems. Scheme 1 is used as a first pass in scheme 2, so reading about the parameters of scheme 1 will help you understand the other schemes better.
Sorting scheme 2
The second sorting scheme is generally preferred over scheme 1 because it can handle larger datasets that cannot be fully loaded into memory, and also has other advantages in terms of accurately detecting and labeling spikes.
In phase 1, the first scheme is used as a training step, performing unsupervised clustering on a subset of the dataset. Then in phase 2, a set of classifiers are trained based on the labels of the training step. The classifiers are then used to label the spikes in the entire recording.
Sorting scheme 3
Sorting scheme 3 is designed to handle long recordings that may involve waveform drift. The recording is divided into blocks, and each block is spike sorted using scheme 2. Then the snippet classifiers for the blocks are used to associate matching units between blocks.
Citing MountainSort
For now, please cite the original MountainSort paper that corresponds to a previous version:
@article{chung2017fully,
title={A fully automated approach to spike sorting},
author={Chung, Jason E and Magland, Jeremy F and Barnett, Alex H and Tolosa, Vanessa M and Tooker, Angela C and Lee, Kye Y and Shah, Kedar G and Felix, Sarah H and Frank, Loren M and Greengard, Leslie F},
journal={Neuron},
volume={95},
number={6},
pages={1381--1394},
year={2017},
publisher={Elsevier}
}
In addition, if you use the SpikeInterface framework, please cite the following paper:
@article{buccino2020spikeinterface,
title={SpikeInterface, a unified framework for spike sorting},
author={Buccino, Alessio Paolo and Hurwitz, Cole Lincoln and Garcia, Samuel and Magland, Jeremy and Siegle, Joshua H and Hurwitz, Roger and Hennig, Matthias H},
journal={Elife},
volume={9},
pages={e61834},
year={2020},
publisher={eLife Sciences Publications Limited}
}
Contributing
Feel free to open an issue or pull request if you have any questions or suggestions.
Please star this repository if you find it useful!
Authors
Jeremy Magland, Center for Computational Mathematics, Flatiron Institute
Acknowledgements
Thank you to Loren Frank and members of his lab for their support of this project at all stages of development.
Thank you to Alex Barnett, Leslie Greengard, and Jason Chung for their work on the original Isosplit and MountainSort algorithms.
Thank you to the SpikeInterface team, especially Alessio Buccino and Samuel Garcia, for their work on the SpikeInterface framework, which supports pre- and post-processing and makes it easy to use MountainSort5 with a variety of file formats.
Thank you to Jeff Soules for his work on sortingview and related visualization tools that make it possible to inspect the results of MountainSort5 and other algorithms.
Thank you Joshua Melander for providing the guide on getting started with Neuropixels and SpikeGLX.
Finally, thank you to all the users of the previous version of MountainSort who have provided feedback and suggestions.
License
Apache-2.0
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mountainsort5-0.5.9.tar.gz.
File metadata
- Download URL: mountainsort5-0.5.9.tar.gz
- Upload date:
- Size: 33.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8c04d53046d773fdf94cdac639c2e5a8eb156d2af4395f5bf51b99f3f9d33423
|
|
| MD5 |
bc97a039f1183ad112cf30a239d15570
|
|
| BLAKE2b-256 |
cc36bf6fd36b01ef43c5c7e2b3a6126743a6efe6fabeb30d2af0025d960c1e12
|
File details
Details for the file mountainsort5-0.5.9-py3-none-any.whl.
File metadata
- Download URL: mountainsort5-0.5.9-py3-none-any.whl
- Upload date:
- Size: 36.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cba04c35a6788438fbce0bb91a625ea81b5d7675b1bdc4d81038efcb191ccad1
|
|
| MD5 |
57e29e60db8d8a4f45d8cb85a8deac95
|
|
| BLAKE2b-256 |
c752d66b70399194384b5bfd5b73030b50837fb0a927d113a4ad35b149a57aeb
|







