(Not too) deep clustering

Project description

Welcome to the stable master branch of N2D!! The active development branch is on dev, if you are contributing, please make branches from that!
Changes
- Finally easily extensible (no more writing classes!)
- Model saving and loading! [x] TF2 ready
Not Too Deep Clustering
This is a library implementation of n2d. To learn more about N2D, and clustering manifolds of autoencoded embeddings, please refer to the amazing paper published August 2019.
What is it?
Not too deep clustering is a state of the art "deep" clustering technique, in which first, the data is embedded using an autoencoder. Then, instead of clustering that using some deep clustering network, we use a manifold learner to find the underlying (local) manifold in the embedding. Then, we cluster that manifold. In the paper, this was shown to produce high quality clusters without the standard extreme feature engineering required for clustering.
In this repository, a framework for A) reproducing the study and B) extending the study is given, for further research and use in a variety of applications
Documentation
Full documentation is available on read the docs
Installation
N2D is available on pypi
pip install n2d
Usage
First, lets load in some data. In this example, we will use the Human Activity Recognition(HAR) dataset. In this dataset, sets of time series with data from mobile devices is used to classify what the person is doing (walking, sitting, etc.)
import n2d as nd
import n2d.datasets as data
x,y, y_names = data.load_har()
Next, lets set up our deep learning environment, as well as load in necessary libraries:
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use(['seaborn-white', 'seaborn-paper'])
sns.set_context("paper", font_scale=1.3)
matplotlib.use('agg')
Finally, we are ready to get clustering!
The first step of any not too deep clustering algorithm is to use an autoencoder to learn an embedding, so that is what we will do!
n_clusters = 6
ae = n2d.AutoEncoder(x.shape[-1], n_clusters)
The next step in this framework is to initialize a manifold clustering algorithm, in general UmapGMM, which builds an autoencoder network and gets everything ready for clustering:
manifold_clusterer = n2d.UmapGMM(n_clusters)
Finally, we pass both of these into the N2D class:
harcluster = n2d.n2d(ae, manifold_clusterer)
Next, we fit the data. In this step, the autoencoder is trained on the data, setting up weights.
harcluster.fit(x, weight_id = "har.h5")
The next time we want to use this autoencoder, we will instead use the weights argument:
harcluster.fit(x, weights = "har.h5")
Now we can make a prediction, as well as visualize and assess. In this step, the manifold learner learns the manifold for the data, which is then clustered. By default, it makes the prediction on the data stored internally, however you can specify a new x in order to make predictions on new data.
preds = harcluster.predict(x)
# predictions are stored in harcluster.preds
harcluster.visualize(y, y_names, n_clusters = n_clusters)
print(harcluster.assess(y))
# (0.81212, 0.71669, 0.64013)
Before viewing the results, lets talk about the metrics. The first metric is cluster accuracy, which we see here is 81.2%, which is absolutely state of the art for the HAR dataset. The next metric is NMI, which is another metric which describes cluster quality based on labels, independent of the number of clusters. We have an NMI of 0.717, which is again absolutely state of the art for this dataset. The last metric, ARI, shows another comparison between the actual groupings and our grouping. A value of 1 means the groupings are nearly the same, while a value of 0 means they completely disagree. We have a value of 0.64013, which indicates that are predictions are more or less in agreement with the truth, however they are not perfect.
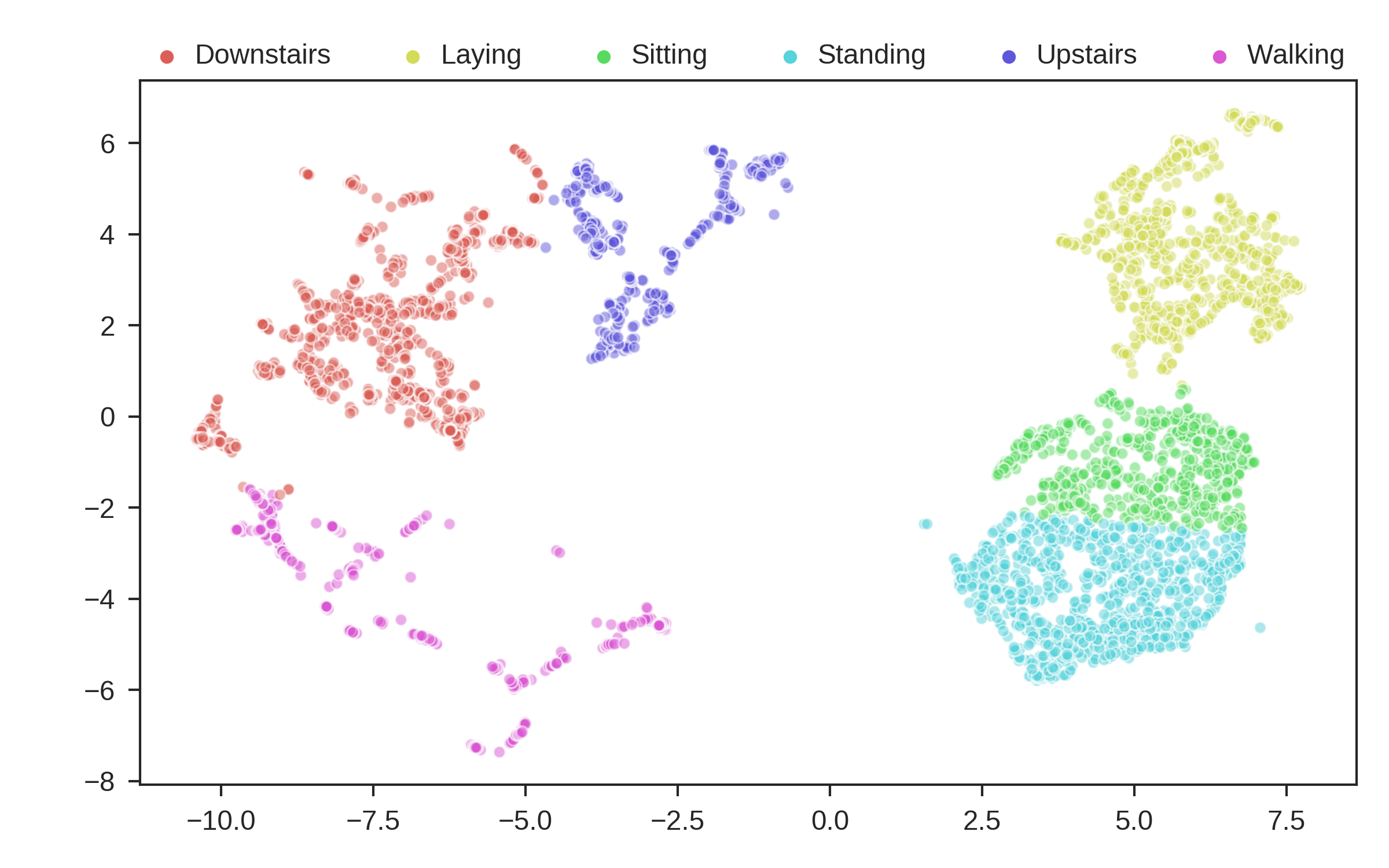
N2D prediction
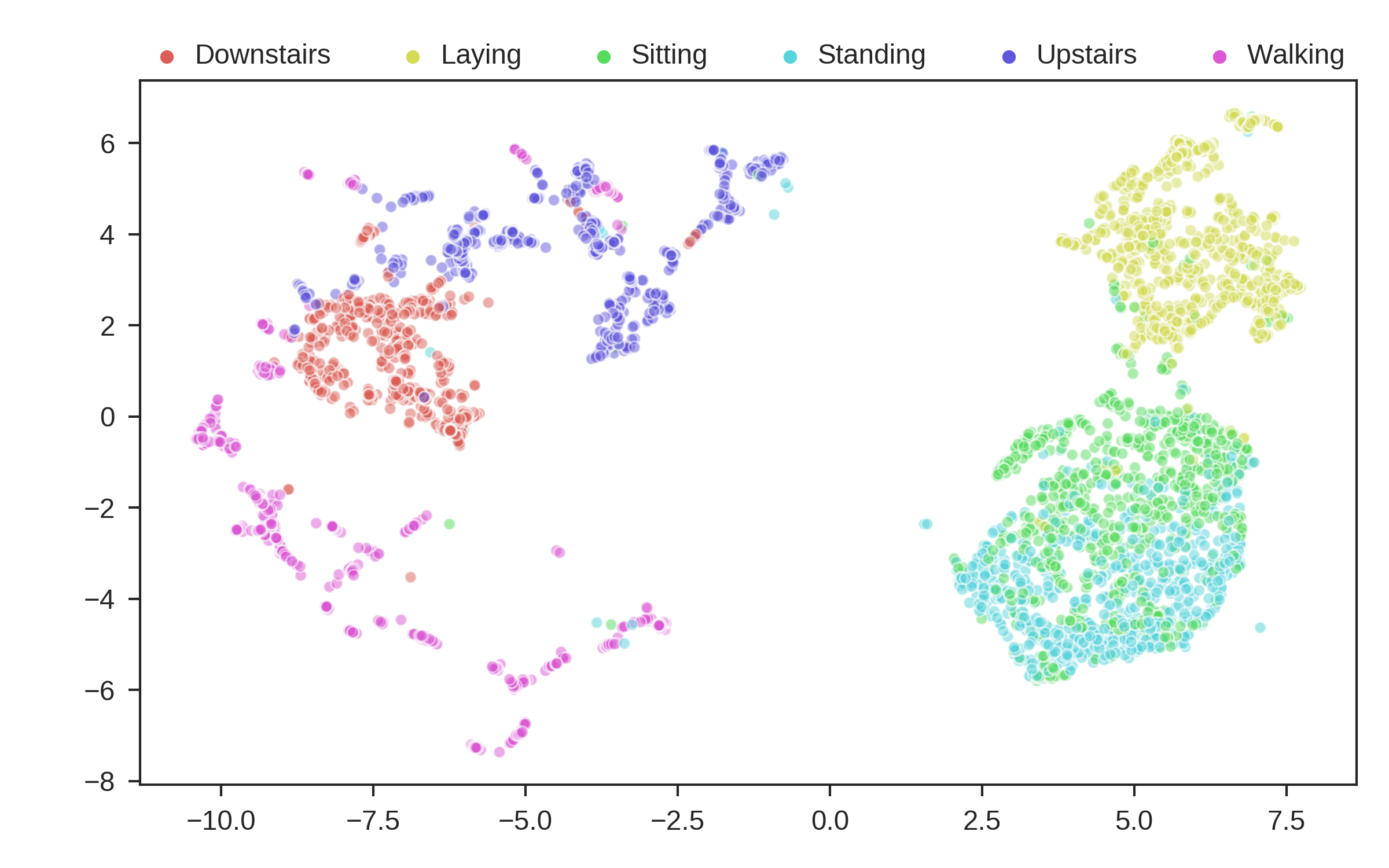
Extending
This library comes with 2 special generator classes, which make it much easier to extend the library. For more in depth discussion, please see the documentation
Replacing the manifold clustering mechanism
Lets assume we want to use hdbscan to cluster our manifold, instead of gaussian mixing. In this case, we use the manifold_cluster_generator class. Below is a short example using hdbscan
import n2d
import numpy as np
import n2d.datasets as data
import hdbscan
import umap
# load up mnist example
x,y = data.load_mnist()
# autoencoder can be just passed normally, see the other examples for extending
# it
ae = n2d.AutoEncoder(input_dim=x.shape[-1], latent_dim=40)
# arguments for clusterer go in a dict
hdbscan_args = {"min_samples":10,"min_cluster_size":500, 'prediction_data':True}
# arguments for manifold learner go in a dict
umap_args = {"metric":"euclidean", "n_components":2, "n_neighbors":30,"min_dist":0}
# pass the classes and dicts into the generator
# manifold class, manifold args, cluster class, cluster args
db = n2d.manifold_cluster_generator(umap.UMAP, umap_args, hdbscan.HDBSCAN, hdbscan_args)
# pass the manifold-cluster tool and the autoencoder into the n2d class
db_clust = n2d.n2d(ae, db)
# fit
db_clust.fit(x, epochs = 10)
# the clusterer is a normal hdbscan object
print(db_clust.clusterer.probabilities_)
print(db_clust.clusterer.labels_)
# access the manifold learner at
print(db_clust.manifolder)
# if the parent classes have a method you can likely use it (make an issue if not)
db_clust.fit_predict(x, epochs = 10)
# however this will error because hdbscan doesnt have that method
db_clust.predict(x)
# predict on new data with the approximate prediction
x_test, y_test = data.load_mnist_test()
# access the parts of the autoencoder within n2d or outside of it
test_embedding = db_clust.encoder.predict(x_test)
test_embedding - test_n2d_embedding
# all zeros
test_labels, strengths = hdbscan.approximate_predict(db_clust.clusterer, db_clust.manifolder.transform(test_embedding))
print(test_labels)
print(strengths)
Replacing the embedding mechanism
We can also pretty easily replace the autoencoder with a new one using the autoencoder_generator class:
import n2d
from n2d import datasets as data
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.models import Model
import seaborn as sns
import umap
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
plt.style.use(['seaborn-white', 'seaborn-paper'])
sns.set_context("paper", font_scale=1.3)
# load up data
x,y, y_names = data.load_fashion()
# define number of clusters
n_clusters = 10
# set up manifold learner
umapgmm = n2d.UmapGMM(n_clusters)
# set up parameters for denoising autoencoder
def add_noise(x, noise_factor):
x_clean = x
x_noisy = x_clean + noise_factor * np.random.normal(loc = 0.0, scale = 1.0, size = x_clean.shape)
x_noisy = np.clip(x_noisy, 0., 1.)
return x_noisy
# define stages of networks
hidden_dims = [500, 500, 2000]
input_dim = x.shape[-1]
inputs = Input(input_dim)
encoded = inputs
for d in hidden_dims:
encoded = Dense(d, activation = "relu")(encoded)
encoded = Dense(n_clusters)(encoded)
decoded = encoded
for d in hidden_dims[::-1]:
decoded = Dense(d, activation = "relu")(decoded)
outputs = Dense(input_dim)(decoded)
# inputs: iterable of inputs, center, outputs of ae, lambda for noise (x_lambda is not a necessary argument)
denoising_ae = n2d.autoencoder_generator((inputs, encoded, outputs), x_lambda = lambda x: add_noise(x, 0.5))
# define model
model = n2d.n2d(denousing_ae, umapgmm)
# fit the model
model.fit(x, epochs=10)
# make some predictions
model.predict(x)
model.visualize(y, y_names, n_clusters = n_clusters)
plt.show()
print(model.assess(y))
Roadmap
- Package library
- Package data
- Early stopping
- Implement data augmentation techniques for images, sequences, and time series
- Make autoencoder interchangeable just like the rest
- Simpler way to extract embedding
- Implement other types of autoencoders as well as convolutional layers
- Manage file saving paths better
- Implement other promising methods
- Make assessment/visualization more extensible
- Documentation?
- Find an elegant way to deal with pre training weights
- Package on Nix
- Blog post?
- Clean up code examples!
Contributing
N2D is a work in progress and is open to suggestions to make it faster, more extensible, and generally more usable. Please make an issue if you have any ideas of how to be more accessible and more usable!
Citation
If you use N2D in your research, please credit the original authors of the paper. Bibtex included below:
@article{2019arXiv190805968M,
title = {N2D:(Not Too) Deep Clustering via Clustering the Local Manifold of an Autoencoded Embedding},
author = {{McConville}, Ryan and {Santos-Rodriguez}, Raul and {Piechocki}, Robert J and {Craddock}, Ian},
journal = {arXiv preprint arXiv:1908.05968},
year = "2019",
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file n2d-0.3.2.tar.gz.
File metadata
- Download URL: n2d-0.3.2.tar.gz
- Upload date:
- Size: 30.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/44.0.0.post20200106 requests-toolbelt/0.9.1 tqdm/4.40.2 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e4be4fd198b06937b6b2ed6d7179fa81aaf8d634dec5c0f0bf046c539598609f
|
|
| MD5 |
86ce2dfae24e151240ce0833167332d1
|
|
| BLAKE2b-256 |
4829fdafd1aad6aac9467f26bb45346c4f2fd08d0d45cef2e448341a316d7d5f
|
File details
Details for the file n2d-0.3.2-py3-none-any.whl.
File metadata
- Download URL: n2d-0.3.2-py3-none-any.whl
- Upload date:
- Size: 14.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/44.0.0.post20200106 requests-toolbelt/0.9.1 tqdm/4.40.2 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a0cfe6eb5723a6404d1bc25f7fec09632e8b93d11e34150b78ef93a6a0dca842
|
|
| MD5 |
adc96a4d1550fecaff4c1139639e5f73
|
|
| BLAKE2b-256 |
24bc548e0d998c03b5ff8283d18a6f77191edb1e1d720b8a25780d64cdd666a5
|







