Deep learning-based Night-to-Day image-translation software

Project description
Night-to-Day Image-translation System
Introduction
As mentioned in the following paper, brightness is a very important and sensitive factor in image processing.
- Night surveillance is a challenging task because of low brightness, low contrast, low Signal to Noise Ratio (SNR) and low appearance information. [1]
- Inhomogeneous illumination induces large contrast variations in images. Detection is difficult in low-contrast regions and may result in loss of color information and in confusing foreground and background regions. [2]
In addition, in the object detection field, brightness is a factor that greatly affects the performance like mAP, and the accuracy of object detection decreases at night. With this in mind, the project proposes a Night-to-Day Image-translation System(hereinafter referred to as "n2dit") that transforms night images to day images. The system supports improving the performance of systems that require object recognition, such as ADAS, black boxes, and computer vision.

CycleGAN, an unsupervised learning-based adversary generation model, was used and Alpha blending was introduced to improve the detection rate of the transformed image. Through this, we proved that, there was a improvement in mAP(mean Average Precision) compared to the existing CLAHE(Contrast Limited Adaptive Histogram Equalization) algorithm.
Implementation
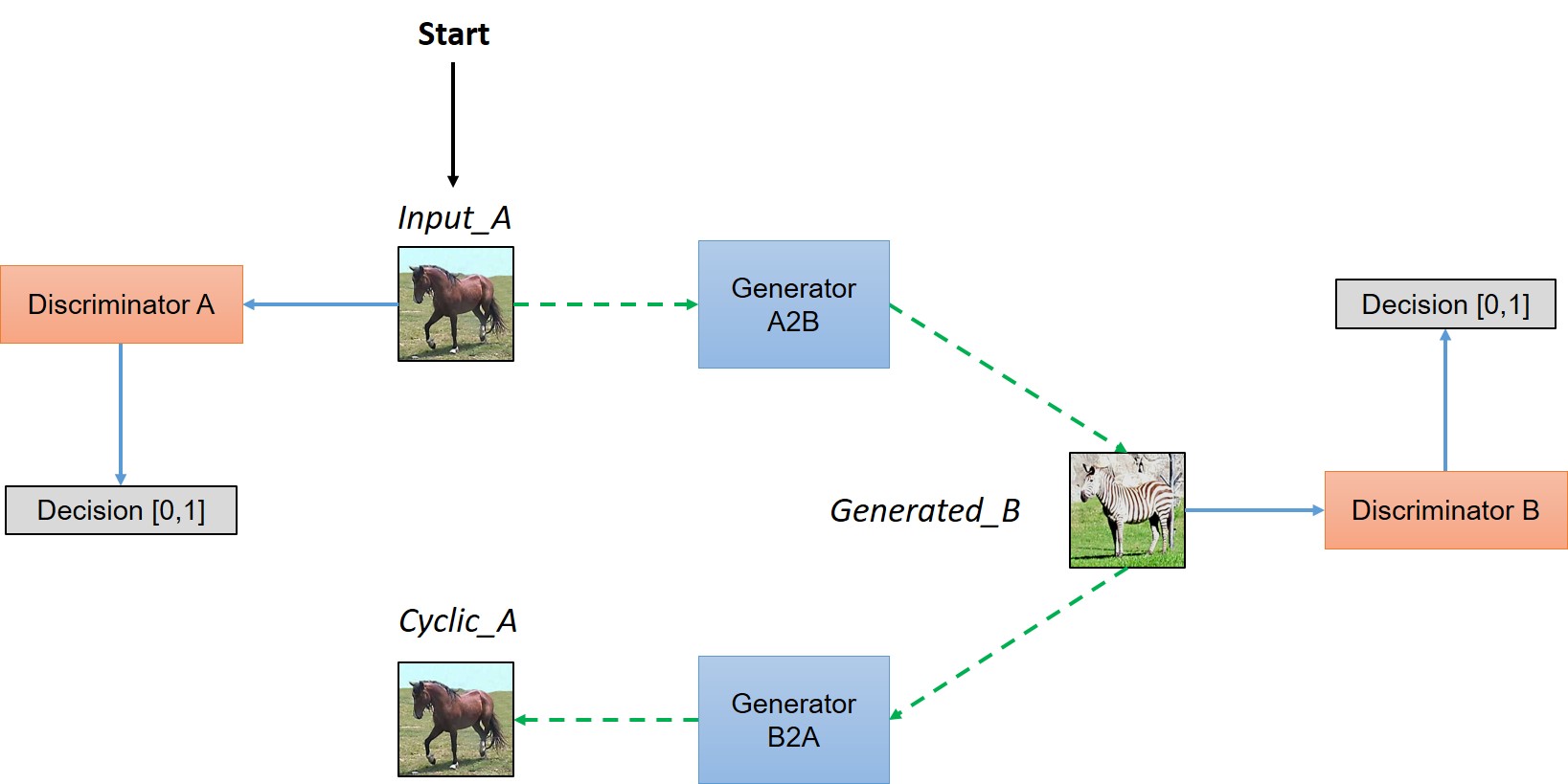
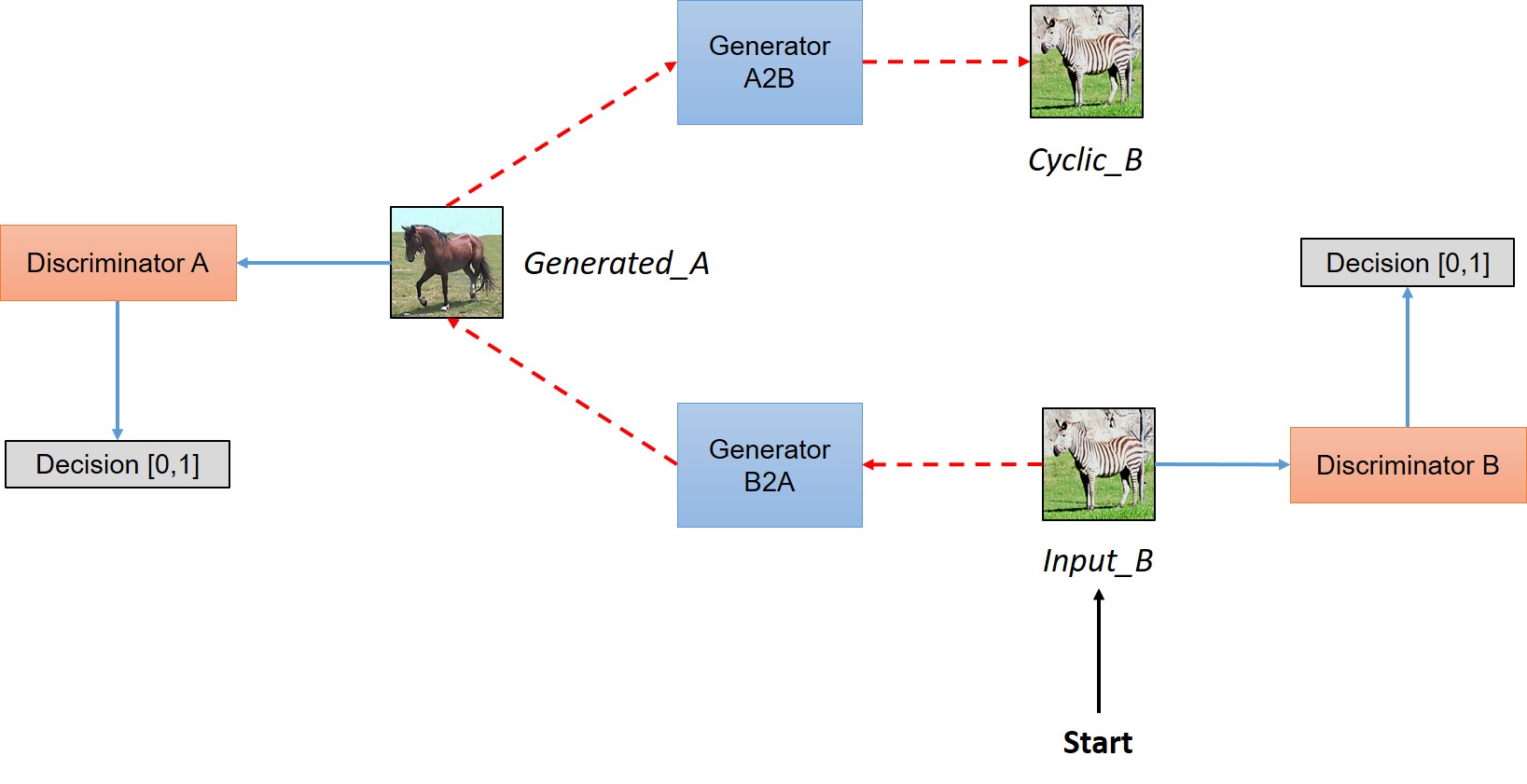
CycleGAN
The project started with CycleGAN[3]. CycleGAN is created by adding cycle-consistency loss to GAN. Cycle-consistency loss helps CycleGAN to only transform the original image to a Fake to the level that can be recovered to Real. In addition, CycleGAN has the great advantage of using a training set that does not require pairing. Thus, allowing CycleGAN to learn domain-to-domain image-translation.
While following the original implementation, we found out that if the depth of the discriminator is less than a certain amount, generator no longer learns after a certain period of time. Therefore, we tried to find the appropriate number of convolutional layers in the discriminator to improve performance through equivalent competitive learning of the generator and discriminator.
Alpha Blending[5]
Alpha blending is also used in 2D computer graphics to put rasterized foreground elements over a background. We experimentally found that the method of displaying a mixture by overlaying the output image to the input image showed higher object detection rates than the conversion method through CycleGAN.

Failed Experiments
-
Perceptual Loss
In Ledig et al.[4], the authors propose a perceptual loss function which consists of an adversarial loss and a content loss. We use this in the objective function to improve the resolution of the fake image generated by CycleGAN.
-
Adding CLAHE-Sobel Loss
Before we applied the perceptual loss, we experimented with adding the following loss to increase the resolution of the generated images: For the mapping function G: X → Y, F: Y → X and CLAHE C, sobel filter S
So the full objective is:
The results during the learning process seemed quite plausible, but the test scores did not improve significantly.
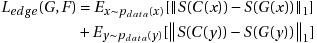
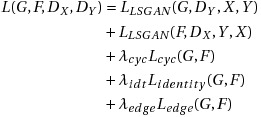
-
Resize Convolution
We found that the checkerboard-like pattern that occurs during the generator's upsampling process reduces the object detection rate and causes low resolution. We found the Bilinear-Resize Convolution[6], which is an alternative to the existing upsampling method, “transposed convolution”. The method resizes the image using the nearest-neighbor interpolation and then upsamples it through the convolutional layer, which improve the “uneven overlap” such as a checkerboard pattern.

Test Process
Preparing Dataset
Extract night and day images from the labels in the BerKeley DeepDrive dataset, redefine the class name in the label as appropriate for the darknet setup, and create the correct label by calculating the width and height from the x1, x2, y1, and y2 coordinate.
Model Training
Train our model with the training dataset prepared using the various options.
Image-translation
Convert the night image in the test dataset into a day image with a trained model.
Object Detection
Calculate mAP of real and transformed images using Darknet with COCO-Yolo v3 pre-trained model. There are 80 classes in the COCO dataset, but we limit it to three classes(person, car, bus) for the characteristics of the BDD dataset.
Refine Model
Repeat training by adjusting network or parameters according to whether object detection is improved.
Results
Result Images
The image translation results of all experiments, including the failed ones, are as follows.

Object Detection Performance
The following table is the result of object detection of 5,000 night images from a BerKeley DeepDrive Dataset with COCO-Yolo v3 weight. The number of classes and objects in a dataset is as follows: (Person: 3611, Car: 45694, Bus: 378) When the generator uses 9 resnet blocks, the discriminator uses 6 convolution layers, and alpha blending is applied, the highest object detection rate is shown in the following table.
| Original | CLAHE | Alpha Blending (Real:0.8, fake:0.2 ratio) |
The discriminator has 6 convolution layers with Alpha Blending |
|
|---|---|---|---|---|
| Person(AP) | 29.75 | 31.90 | 30.71 | 30.98 |
| Car(AP) | 42.09 | 44.41 | 44.54 | 46.19 |
| Bus(AP) | 25.44 | 26.37 | 28.34 | 28.05 |
| mAP | 32.43 | 34.23 | 34.53 | 35.07 |
| mAP(Balanced) | 41.07 | 43.36 | 43.41 | 44.95 |
| Diff | - | 2.30 | 2.35 | 3.88 |
Conclusion
The Night-to-Day Image-translation System adds the characteristics of the target domain, which the original domain did not have, to the original domain for image transformation. Night images with low brightness are converted to day images with high brightness, which is a major factor in improving the performance of object detection. In addition, problems such as noise, low resolution, generated from a bad weather environment or a sensor of image processing devices, etc. that degrade the performance of object detection can be solved by learning them into the original domain and converting them to have desired characteristics. Therefore, the system is considered to be highly utilized in the field of computer vision, and it is possible to apply a target transformation in image processing of various fields as well as night and day transformation.
Reference
-
[1] Object detection and tracking for night surveillance based on salient contrast analysis
-
[2] NightOwls: A pedestrians at night dataset
-
[3] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
-
[4] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
-
[5] Alpha blending in Wikipedia
-
[6] Deconvolution and Checkerboard Artifacts
System Requirements
Hardware
- NVIDIA GPUs 8G
- 10.00 GB of available disk space
Software
-
Docker
- NVIDIA driver - version for CUDA
- Docker Engine - 19.03.4
- (Option 1) tensorflow/tensorflow:1.14.0-gpu-py3(Digest:e72e66b3dcb9)
- matplotlib - 3.1.1
- pillow - 6.2.1
- opencv-python - 3.4.2.17
- (Option 2) n2dit Docker Image
- See below.
Installation
Use pip for Installing
- (Optional) To use the GUI, checkout the gui branch with the following command.
$ git checkout gui - Install the list of requirements with the following command.
$ pip install -r requirements.txt - Install n2dit with the following command from the directory path where the setup.py file is located.
$ pip install . - (Optional) If you are using Anaconda, follow these steps.
- Remove opencv-python from requirements.txt.
- Create and activate the environment you want to use.
- Install opencv-python with the following command.
$ conda install -c menpo opencv - Use the following command as in the two steps above.
$ conda install --file requirements.txt $ pip install .
Docker
-
Build n2dit docker image
- (Optional) To use the GUI, checkout the gui branch with the following command.
- Build the docker image by running the following command where the Dockerfile is located:
$ docker build -t <image-name>:<tag> --target release .
-
Docker Hub
- You can get the docker image that have been built from the following repository.
deeva2019/n2dit:<version>- version
- CLI version: X.X.X
- GUI version: gui-X.X.X
- version
- You can get the docker image that have been built from the following repository.
Excecution
n2dit
-
Training
- Set options via n2dit command options or configuration files.
- Sample configuration files are located in the config directory.
[cyclegan] dirA = ./datasets/day dirB = ./datasets/night results_dir = ./results load_size = 286 crop_size = 256 channels = 3 shuffle = yes pool_size = 50 exp_name = test continue = no epoch = 0 niter = 100 niter_decay = 100 disp_loss_freq = 10 disp_summary_freq = 100 learning_rate = 0.0002 lambda_A = 10.0 lambda_B = 10.0 lambda_idt = 0.5 upsample = resize_conv
- Sample configuration files are located in the config directory.
- Run with the following command.
$ n2dit cyclegan train -C config/sample_train.cfg
- Set options via n2dit command options or configuration files.
-
Test
- Config option values through the n2dit command options or sample configuration file as shown above.
- Run with the following command.
$ n2dit cyclegan test -C config/sample_test.cfg
-
Guide to using docker
- Create a container with the following command to use the host's GPUs.
$ docker run --gpus all <image-name>:<tag> <n2dit options> - The file used by n2dit corresponds to the following options.
- dirA: Source domain image directory you want to transform
- dirB: Target domain image directory
- results_dir: Common results directory used for training and testing
- (Optional) config_file: Configuration file
- So unless you use n2dit inside the container, use the option v to bind the host volume to the container as follows.
$ docker run --gpus all -v /home/deeva/datasets/A/:/work/A\ -v /home/deeva/datasets/B/:/work/B\ -v /home/deeva/results/:/work/results\ n2dit:latest cyclegan train --dirA /work/A --dirB /work/B --results_dir /work/results
- Create a container with the following command to use the host's GPUs.
n2dit GUI
- (Optional) To use the host's GUI inside the container, The script uses a docker option that exposes xhost to render to the display by reading and writing X11 Unix sockets.
- To use GUI's, use the following command. However, This approach is very vulnerable.
$ xhost +local:root
- To use GUI's, use the following command. However, This approach is very vulnerable.
- When you are finished with the container's GUI, run the following command.
$ xhost -local:root - Use easily.
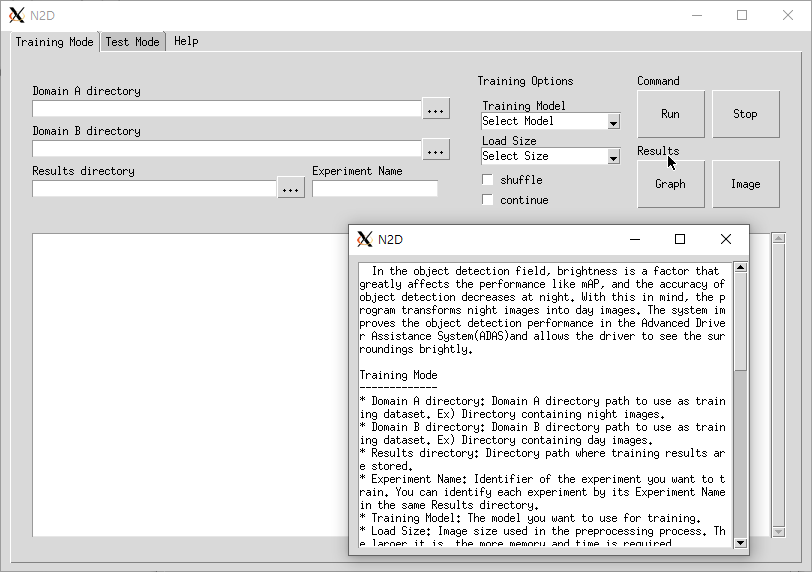
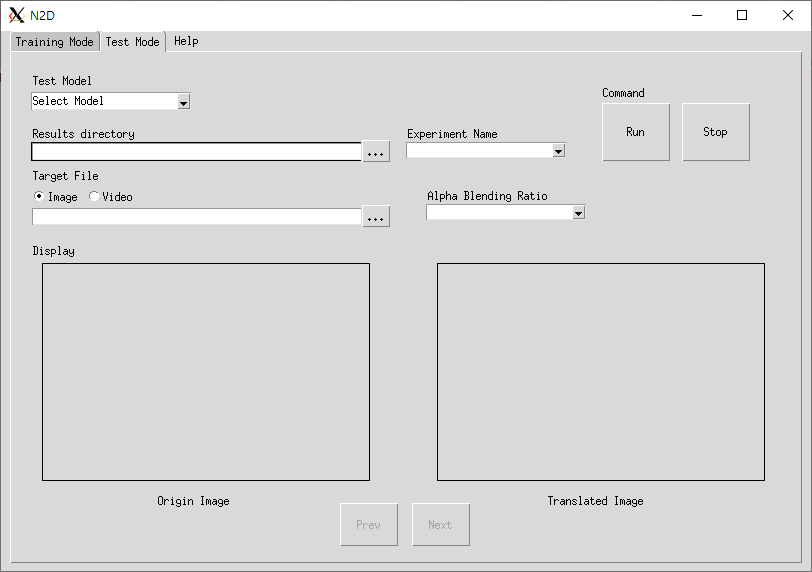
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file n2dit-1.0.0.tar.gz.
File metadata
- Download URL: n2dit-1.0.0.tar.gz
- Upload date:
- Size: 23.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.6.0.post20191030 requests-toolbelt/0.9.1 tqdm/4.40.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8a7487c8f2d9ef93f9cbfe51aae8618bd73caa39447d1fe2c9305bc8b0a6a66e
|
|
| MD5 |
1d9962b3e60c2415d27e912e5b3e9262
|
|
| BLAKE2b-256 |
dc6fdf993e81513866524ec86526d2450ed13a6b952257ce239e78149e6516d4
|
File details
Details for the file n2dit-1.0.0-py3-none-any.whl.
File metadata
- Download URL: n2dit-1.0.0-py3-none-any.whl
- Upload date:
- Size: 22.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.6.0.post20191030 requests-toolbelt/0.9.1 tqdm/4.40.0 CPython/3.7.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
682a87c0bafdef2e3eb6ebeb32f00cd0164424f17bc1ae3d379990d077aabdf2
|
|
| MD5 |
668ef7e61fdbc92817214ff8557cbd8b
|
|
| BLAKE2b-256 |
f25c54efe853f24c44db064b08e3f653d60e3b215dd9df2e5f5741a7908ce26c
|







