Pixel and label classification using OpenCL-based Random Forest Classifiers

Project description
napari-accelerated-pixel-and-object-classification (APOC)








clesperanto meets scikit-learn to classify pixels and objects in images, on a GPU using OpenCL in napari.
For using the accelerated pixel and object classifiers in python, check out apoc. Training classifiers from pairs of image and label-mask folders is explained in this notebook. For executing APOC's pixel and object classifiers in Fiji using clij2 please read the documentation of the corresponding Fiji plugin. Table classifiers and object mergers are not compatible with Fiji yet.
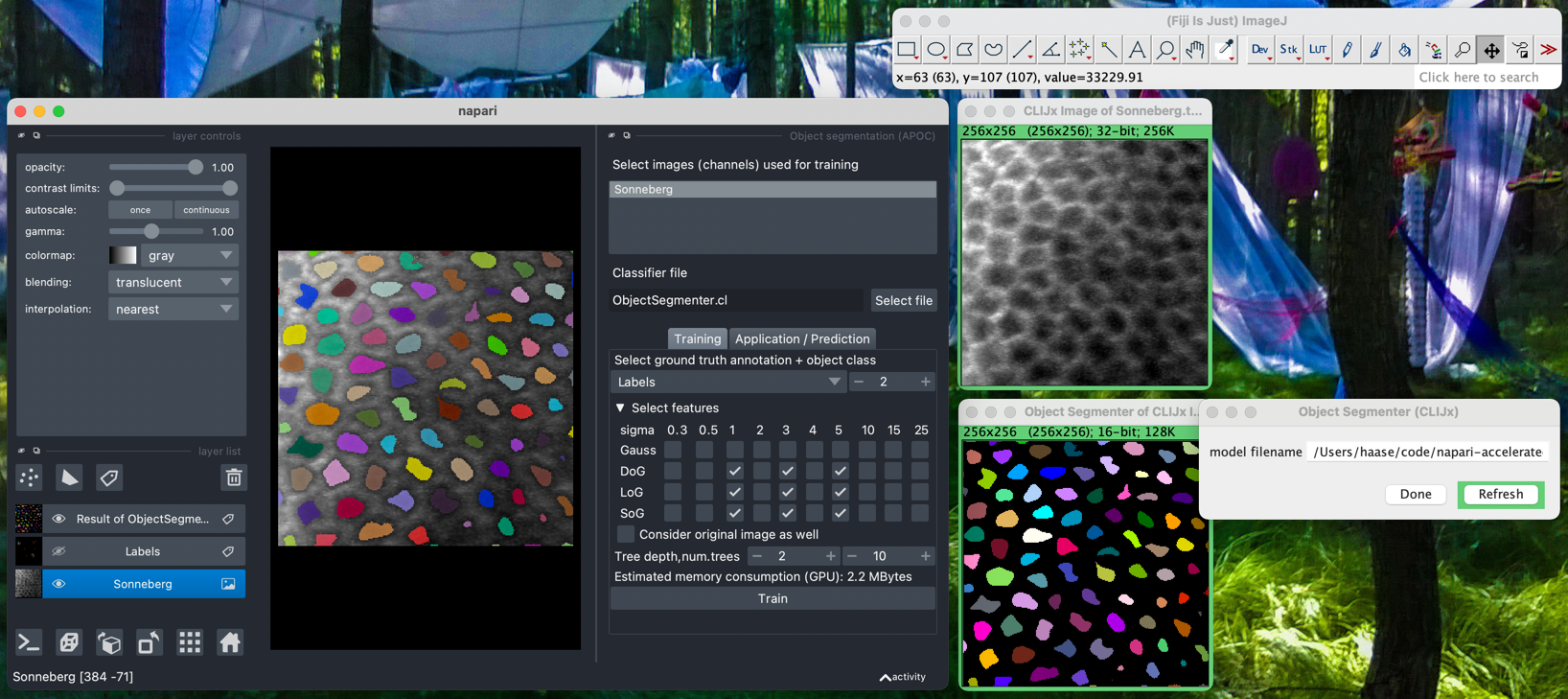
Usage
Object and Semantic Segmentation
Starting point is napari with at least one image layer and one labels layer (your annotation).
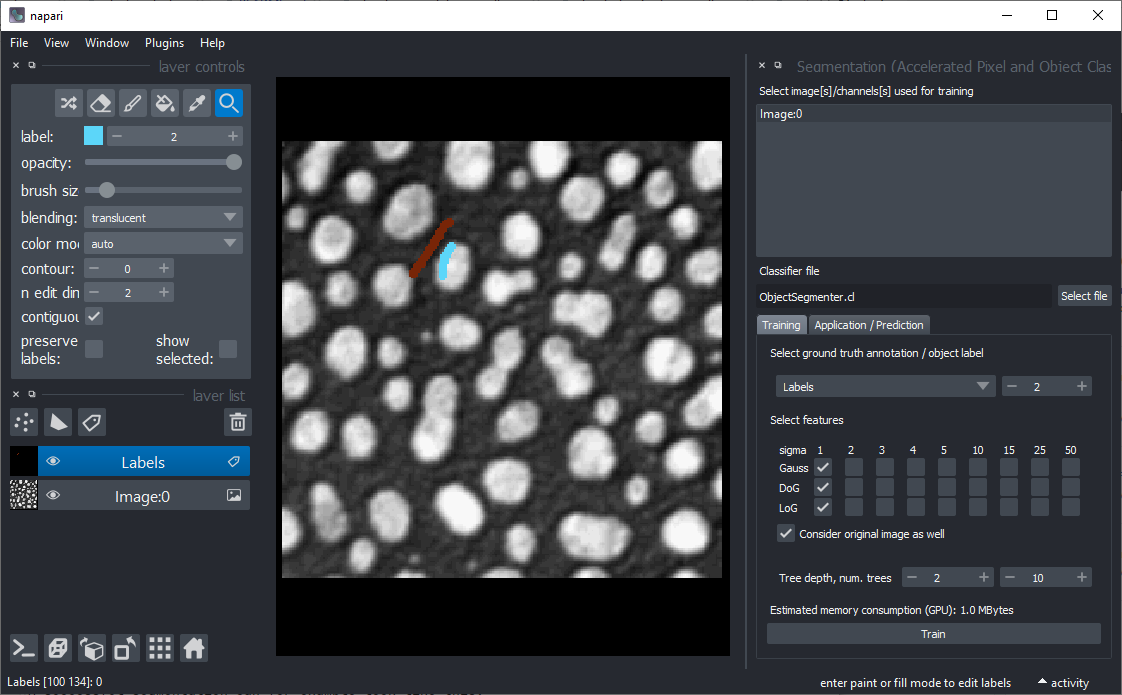
You find Object and Semantic Segmentation in the Tools > Segmentation / labeling. When starting those, the following graphical user interface will show up.
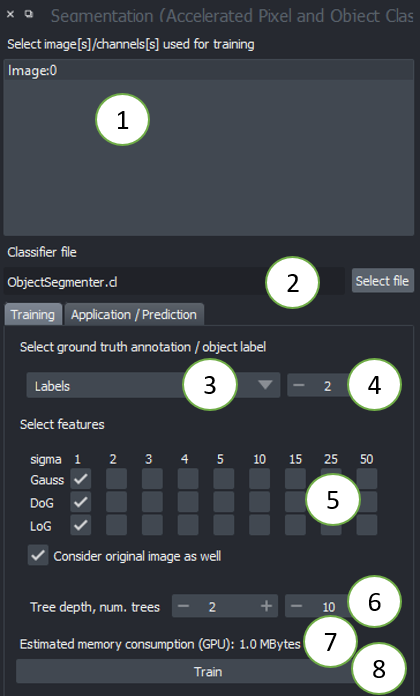
- Choose one or multiple images to train on. These images will be considered as multiple channels. Thus, they need to be spatially correlated. Training from multiple images showing different scenes is not (yet) supported from the graphical user interface. Check out this notebook if you want to train from multiple image-annotation pairs.
- Select a file where the classifier should be saved. If the file exists already, it will be overwritten.
- Select the ground-truth annotation labels layer.
- Select which label corresponds to foreground (not available in Semantic Segmentation)
- Select the feature images that should be considered for segmentation. If segmentation appears pixelated, try increasing the selected sigma values and untick
Consider original image. - Tree depth and number of trees allow you to fine-tune how to deal with manifold regions of different characteristics. The higher these numbers, the longer segmentation will take. In case you use many images and many features, high depth and number of trees might be necessary. (See also
max_depthandn_estimatorsin the scikit-learn documentation of the Random Forest Classifier. - The estimation of memory consumption allows you to tune the configuration to your GPU-hardware. Also consider the GPU-hardware of others who want to use your classifier.
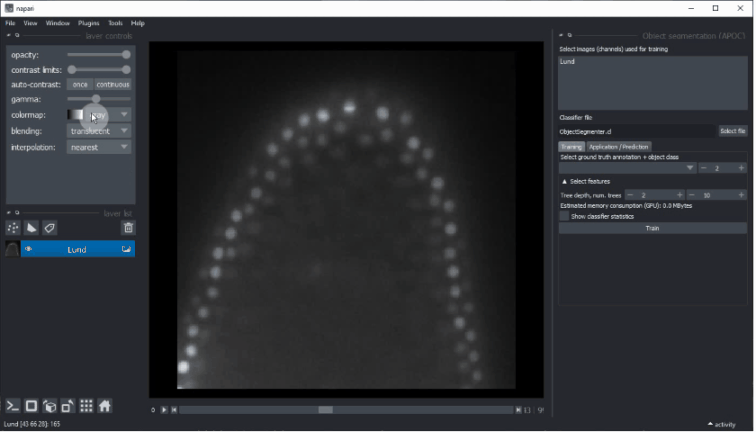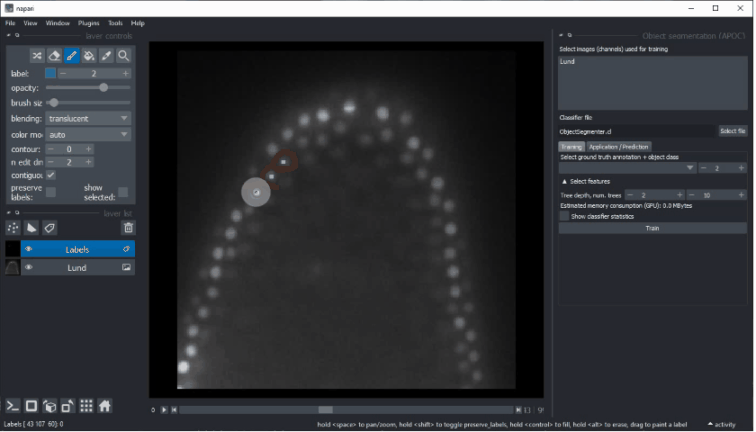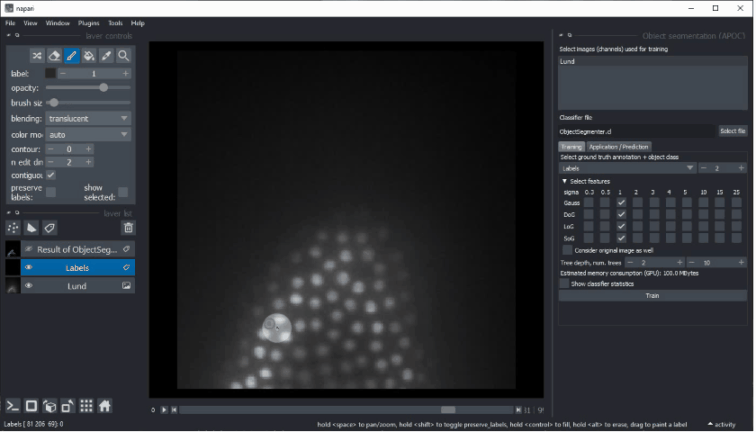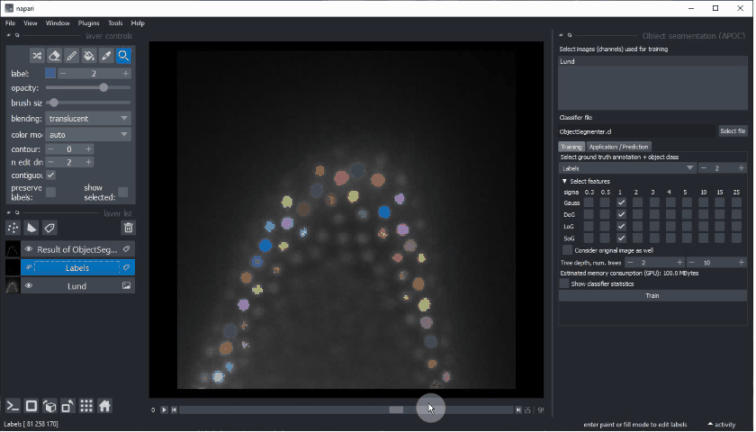
- Click on Run when you're done with configuring. If the segmentation doesn't fit after the first execution, consider fine-tuning the ground-truth annotation and try again.
A successful segmentation can for example look like this:
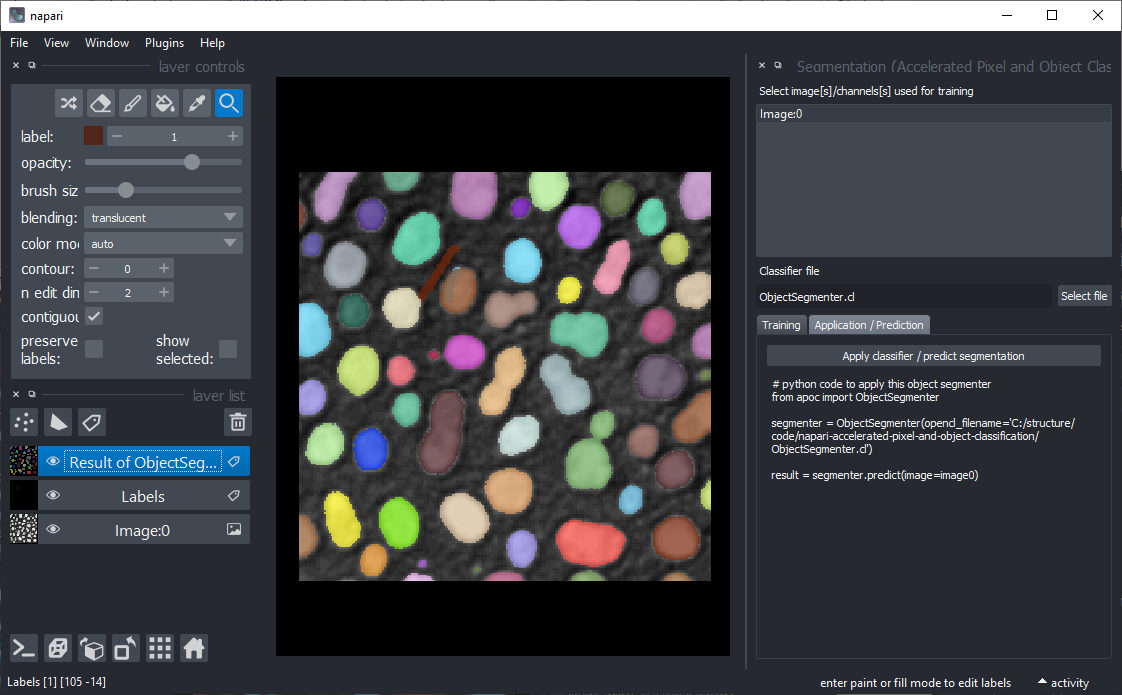
After your classifier has been trained successfully, click on the "Application / Prediction" tab. If you apply the classifier again, python code will be generated. You can use this code for example to apply the same classifier to a folder of images. If you're new to this, check out this notebook.
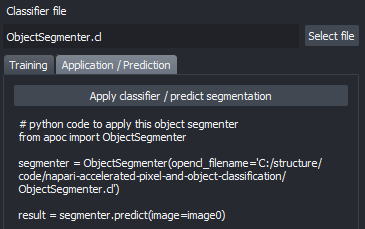
A pre-trained classifier can be applied from scripts as shown in the example notebook or from the Tools > Segmentation / labeling > Object segmentation (apply pretrained, APOC).
Integration with the napari-assistant
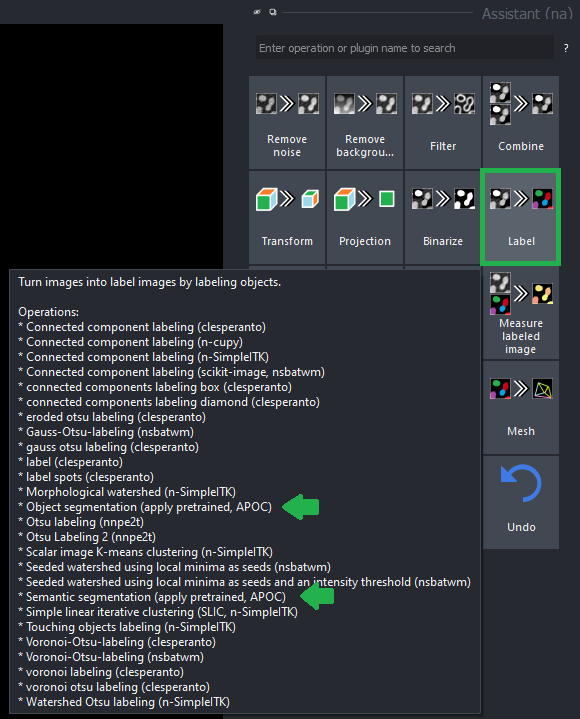
Pre-trained models can also be assembled to workflows using the napari-assistant. You find APOC-operations in the categories Filter, Label and Label Filters:
Semantic segmentation
Users can also generate semantic segmentation label images where the label identifier corresponds to a class the pixel has been allocated to.
The tool can be found in the menu Tools > Segmentation / labeling > Semantic segmentation (APOC).
It works analogously like the Object Segmenter, just without the need to specify the class identifier that objects correspond to.

Probability maps
The tool for generating probability maps (Tools > Filtering > Probability Mapper (APOC) menu) works analogously to the Object Segmenter as well.
The only difference is that the result image is not a label image but an intensity image where the intensity represents the probability (between 0 and 1)
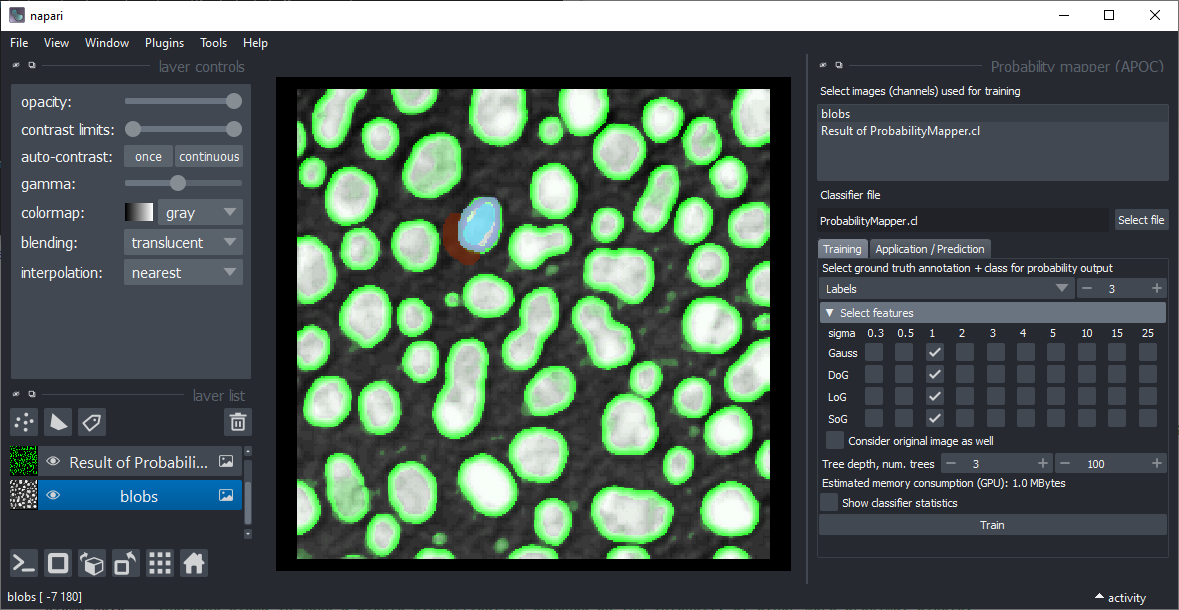
that a pixel belongs to a given class. In this example: The raw image (grey) has been annotated with three classes: background (black, label 1), foreground (white, label 2) and edges (grey, label 3).
The probability mapper was configured to create probability image (shown in green) for edges (label 3):
Classifier statistics
While training, you can also activate the Show classifier statistics checkbox.
When doing so, it is recommended to increase the number of trees so that the measurements are more reliable, especially when selecting many features.
This will open a small table after training where you can see how large the share of decision trees are for each analysed feature image.
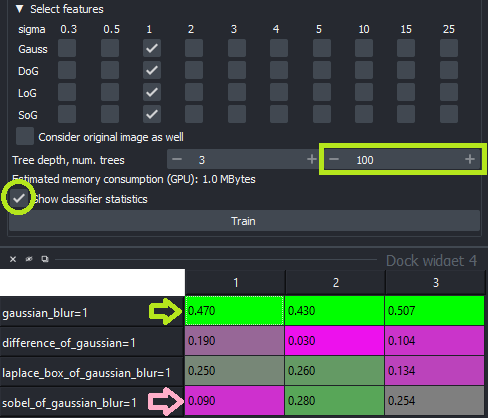
It is recommended to turn on/off the features that hold a very large share (green) or a very small share (magenta) of trees in the random forest. Retrain the classifier to see how the features influence the decision making.
Note: Multiple of these parameters may be correlated. If you select 11 feature images, which all allow to make the pixel classification similarly, but 10 of those are correlated, these 10 may appear with a share of about 0.05 while the 11th parameter has a share of 0.5. Thus, study these values with care.
Merging objects
After segmentation, you can merge labeled objects using the Tools > Segmentation post-processing > Merge objects (APOC) menu.
Annotate label edges that should be merged with intensity 1 and those which should be kept with intensity 2 in a blank label image.
Select which features should be considered for merging:
touch_portion: The relative amount an object touches another. E.g. in a symmetric, honey-comb like tissue, neighboring cells have a touch-portion of1/6to each other.touch_count: The number of pixels where object touch. When using this parameter, make sure that images used for training and prediction have the same voxel size.mean_touch_intensity: The mean average intensity between touching objects. When using this parameter, make sure images used for training and prediction are normalized the same way.centroid_distance: The distance (in pixels or voxels) between centroids of labeled objects.mean_intensity_difference: The absolute difference between the mean intensity of the two objects. This measurement allows differentiating bright and dark object and [not] merging them.standard_deviation_intensity_difference: The absolute difference between the standard deviation of the two objects. This measurement allows to differentiate [in]homogeneous objects and [not] merge them.area_difference: The difference in area/volume/pixel-count allows differentiating small and large objects and [not] merging them.mean_max_distance_to_centroid_ratio_difference: This parameter is a shape descriptor, similar to elongation, allowing to differentiate roundish and elongate object and [not] merging them.
Note: most features are recommended to be used in isotropic images only.
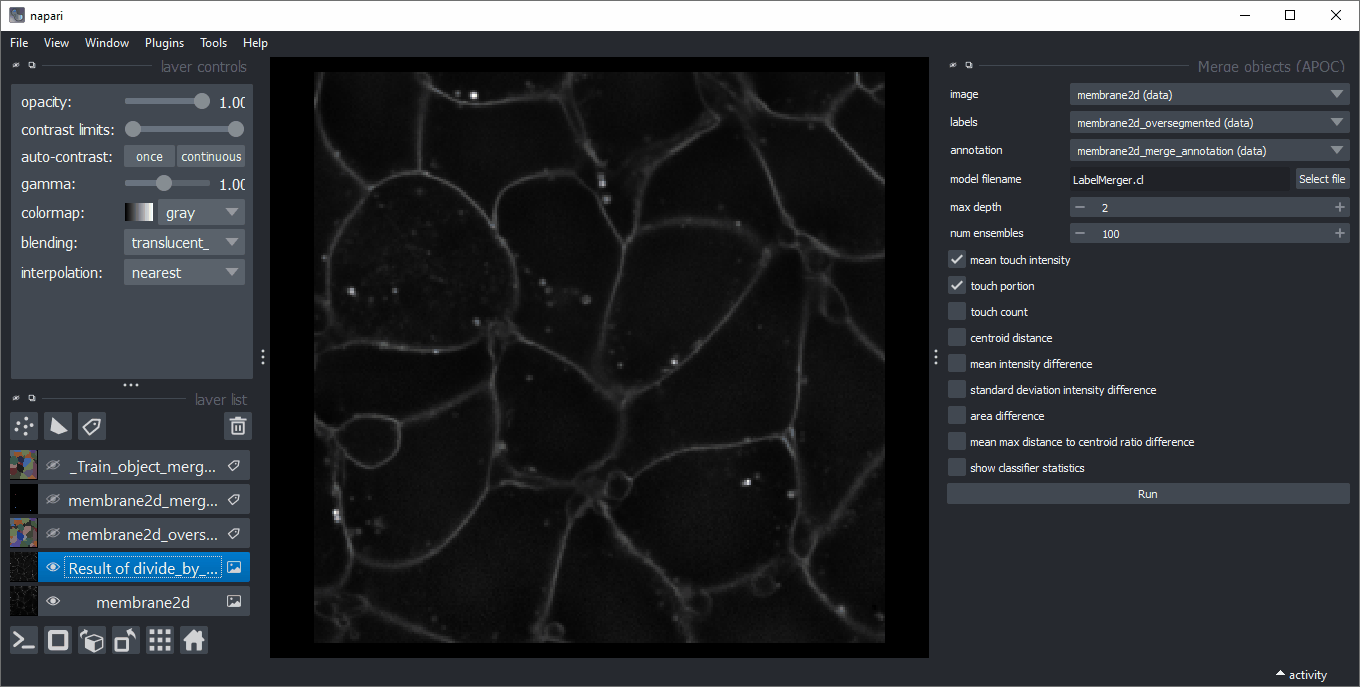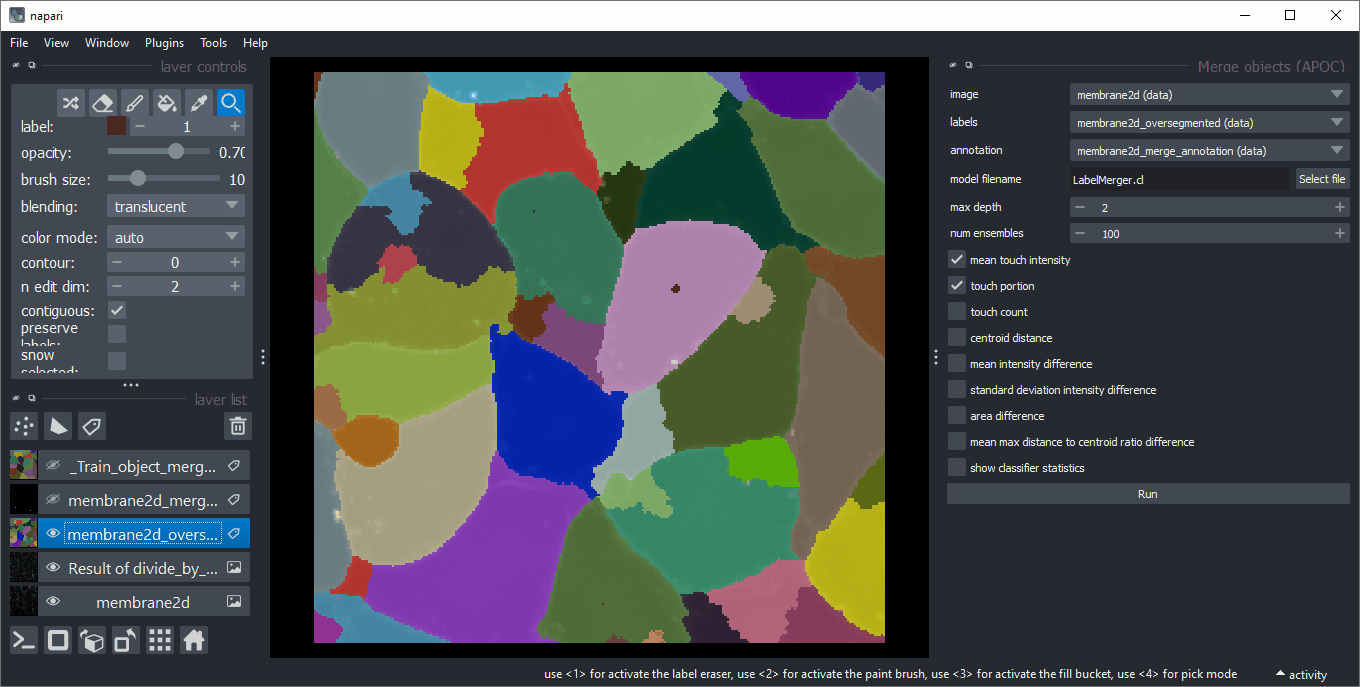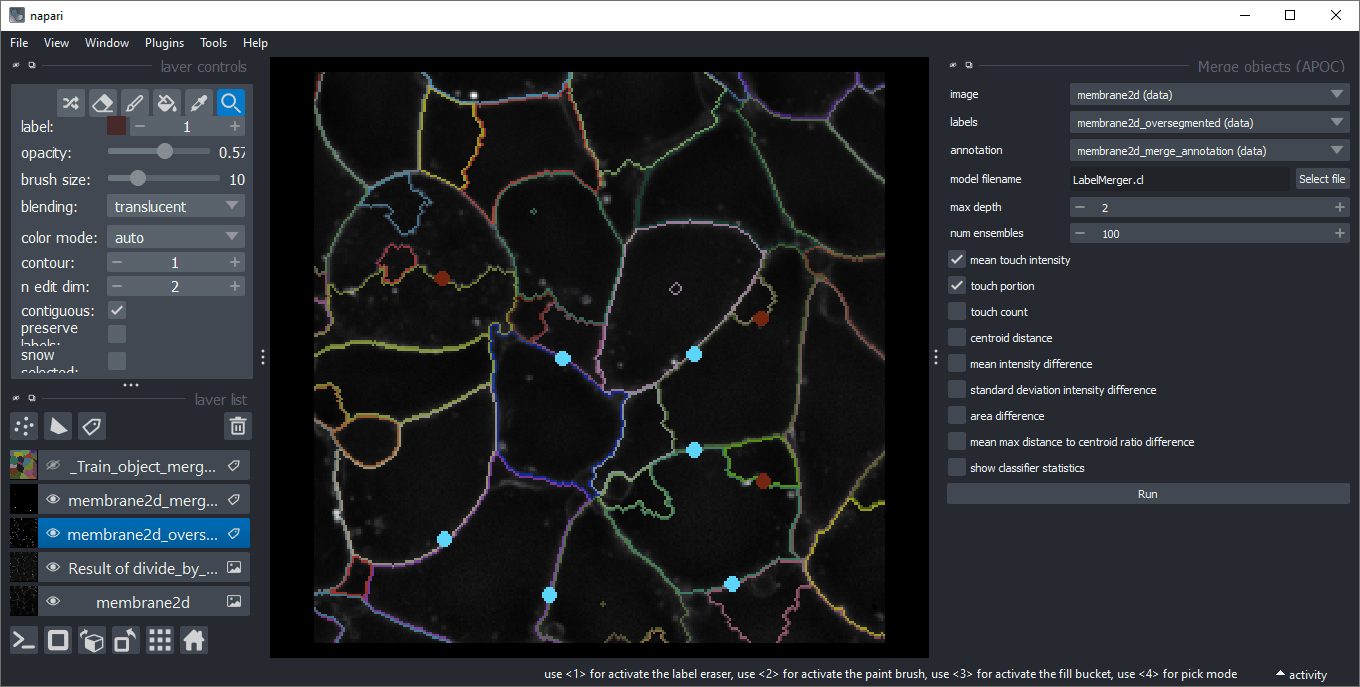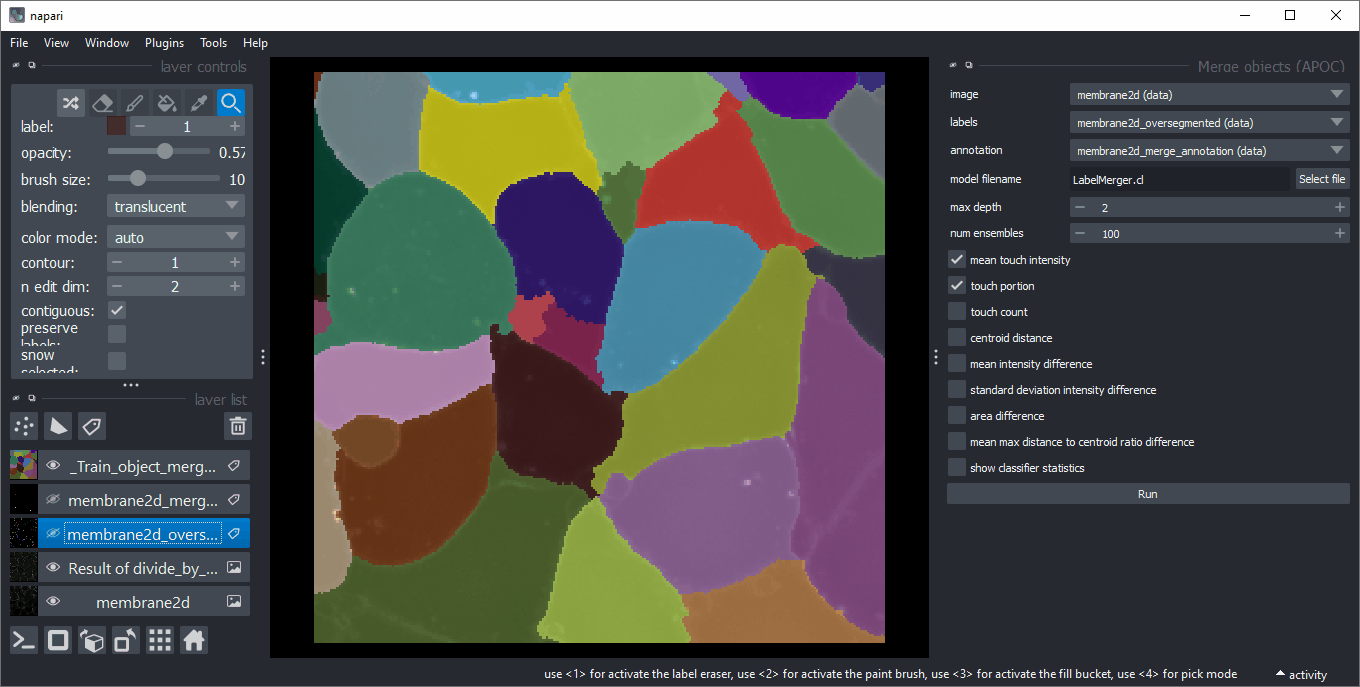
For training, use an image with equivalized intensity (1), an over-segmented label image (2) and annotations (3). When drawing annotations in a new labels layer, make sure to misguide the algorithm draw on edges of touching objects a 1 if those should be merged and a 2 if they should be kept. Make sure there are no 1/2 annotation circles on both: labels which should be merged and kept.

Object classification
Click the menu Tools > Segmentation post-processing > Object classification (APOC).
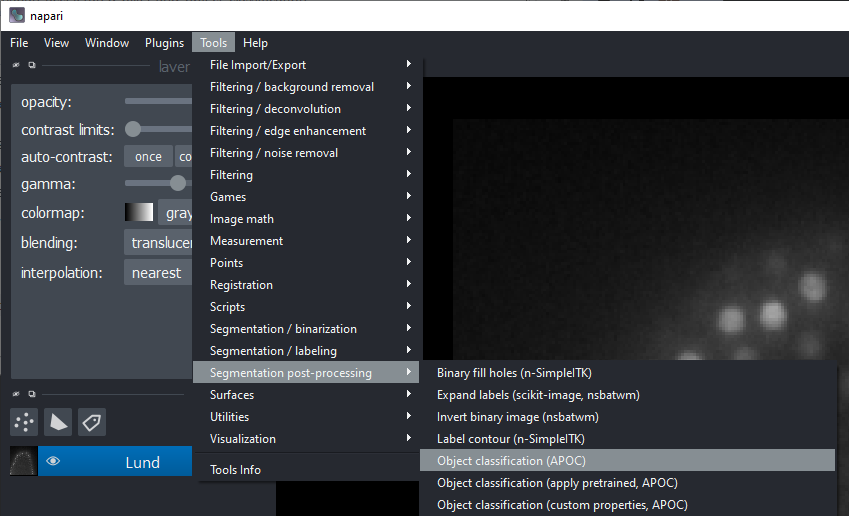
This user interface will be shown:
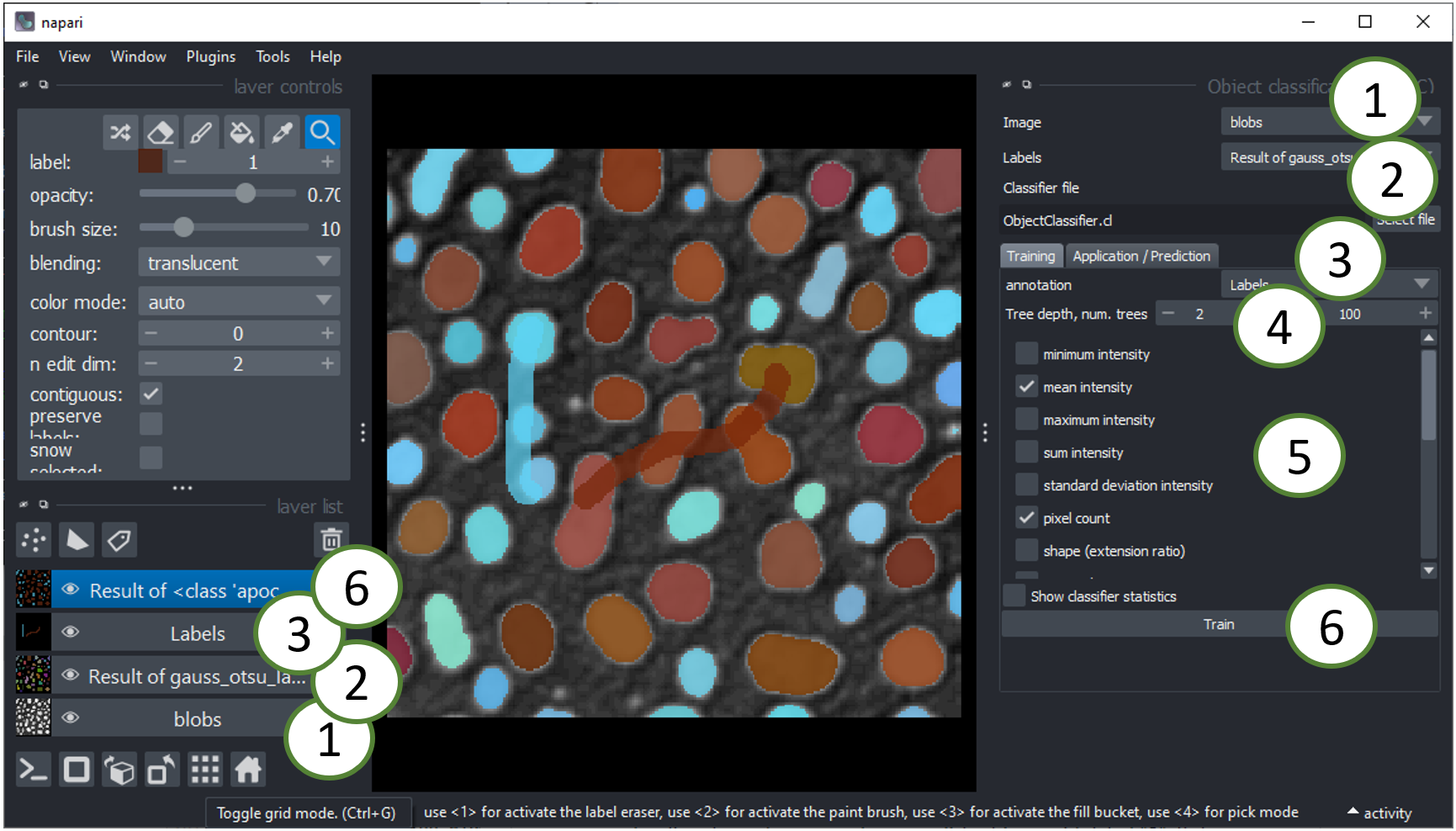
- The image layer will be used for intensity based feature extraction (see below).
- The labels layer should be contain the segmentation of objects that should be classified. You can use the Object Segmenter explained above to create this layer.
- The annotation layer should contain manual annotations of object classes. You can draw lines crossing single and multiple objects of the same kind. For example draw a line through some elongated objects with label "1" and another line through some rather roundish objects with label "2". If these lines touch the background, that will be ignored.
- Tree depth and number of trees allow you to fine-tune how to deal with manifold objects of different characteristics. The higher these numbers, the longer classification will take. In case you use many features, high depth and number of trees might be necessary. (See also
max_depthandn_estimatorsin the scikit-learn documentation of the Random Forest Classifier. - Select the right features for training. For example, for differentiating objects according to their shape as suggested above, select "shape". The features are extracted using clEsperanto and are shown by example in this notebook.
- Click on the
Runbutton. If classification doesn't perform well in the first attempt, try changing selected features.
If classification worked well, it may for example look like this. Note the two thick lines which were drawn to annotate elongated and roundish objects with brown and cyan:
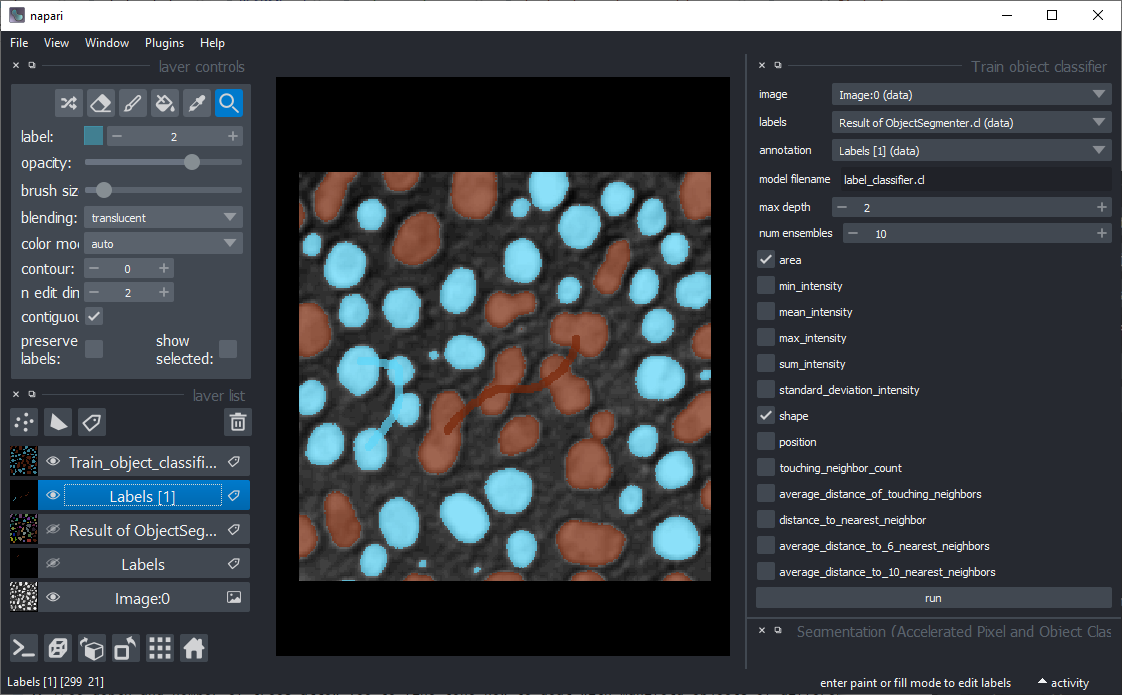
A pre-trained model can later be applied from scripts as shown in the example notebook or using the menu Tools > Segmentation post-processing > Object classification (apply pretrained, APOC).
Object selection
Analogously to object classification, the object selector removes all objects from a label image that do not belong to a specified class.
It can be found in the menu Tools > Segmentation post-processing > Object selection (APOC).
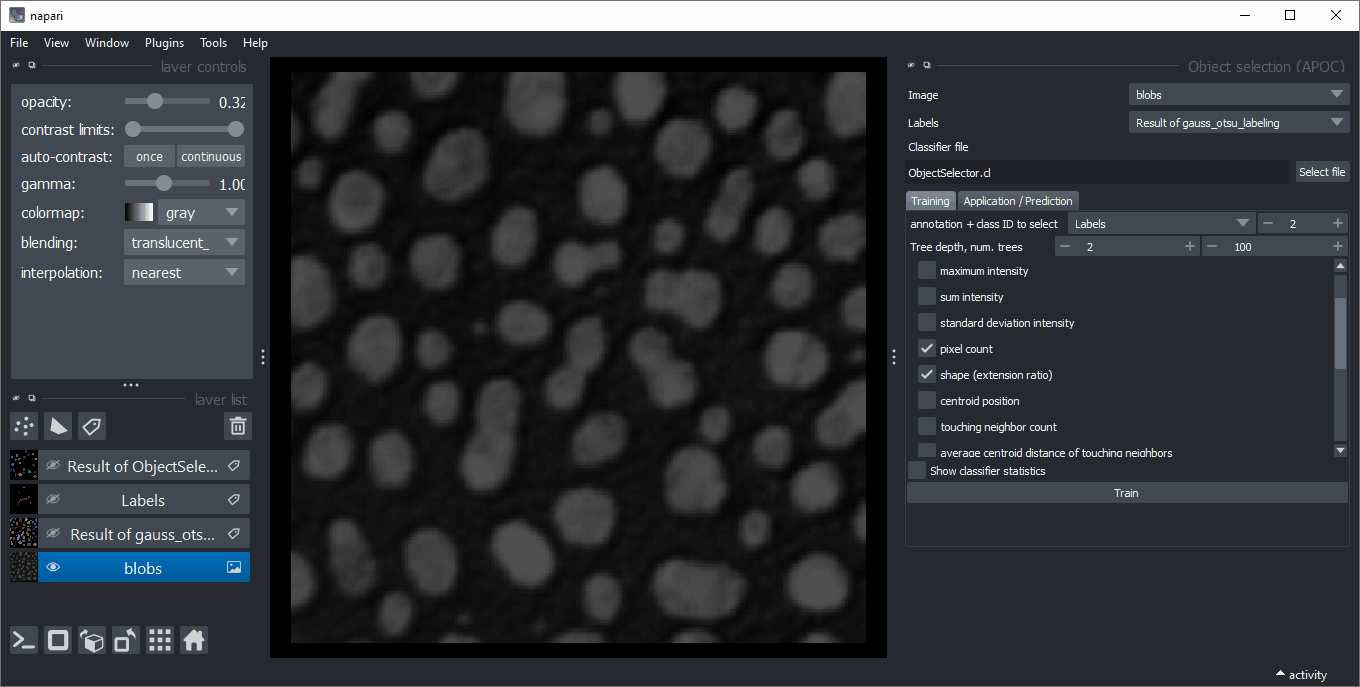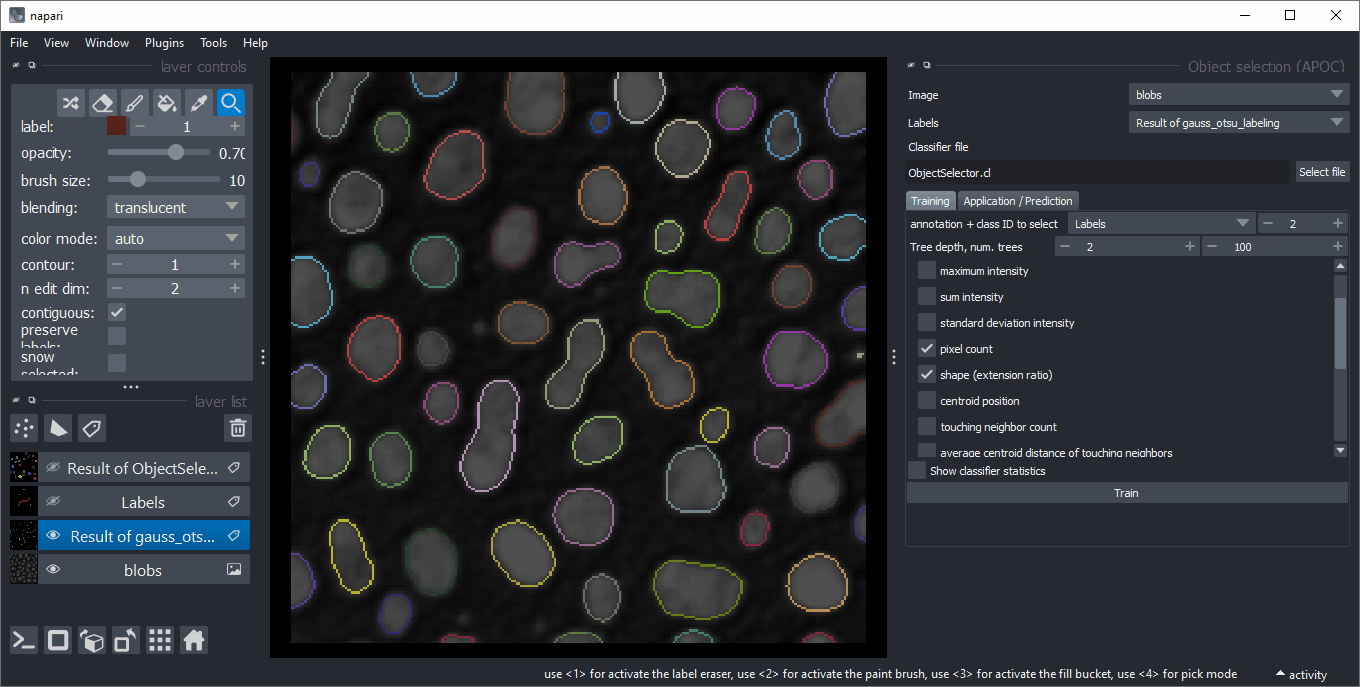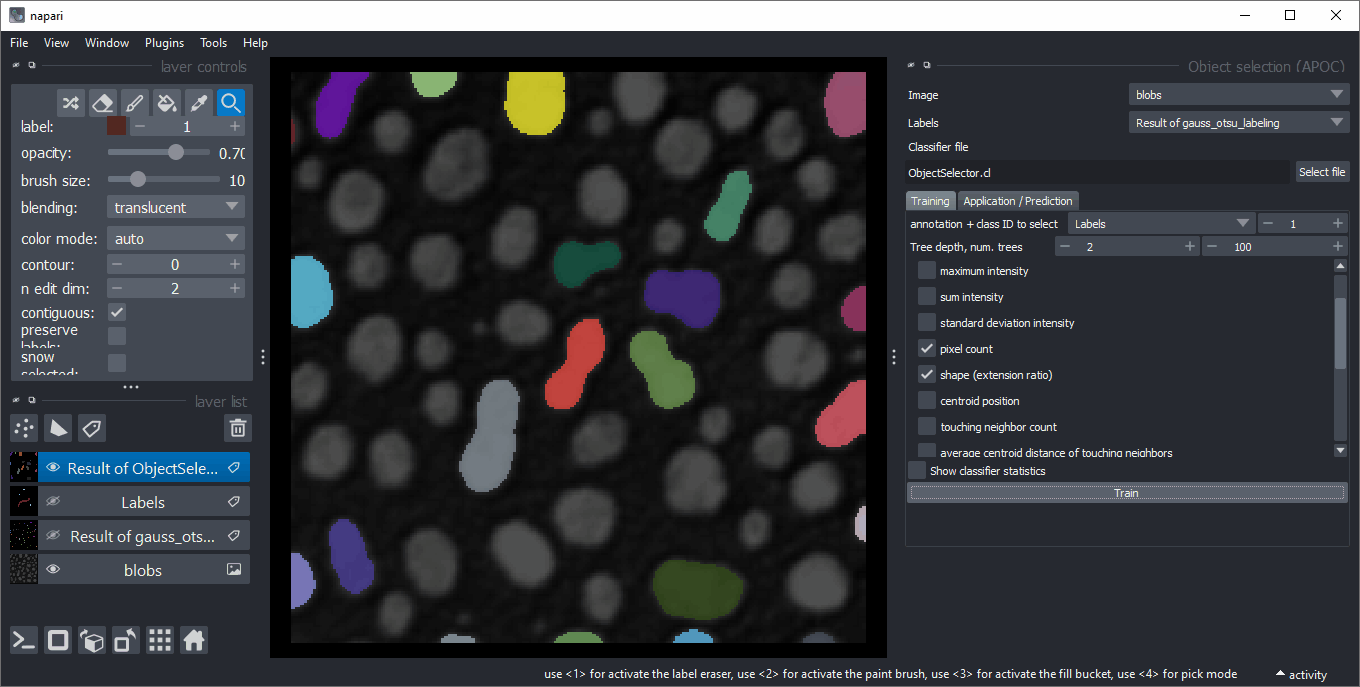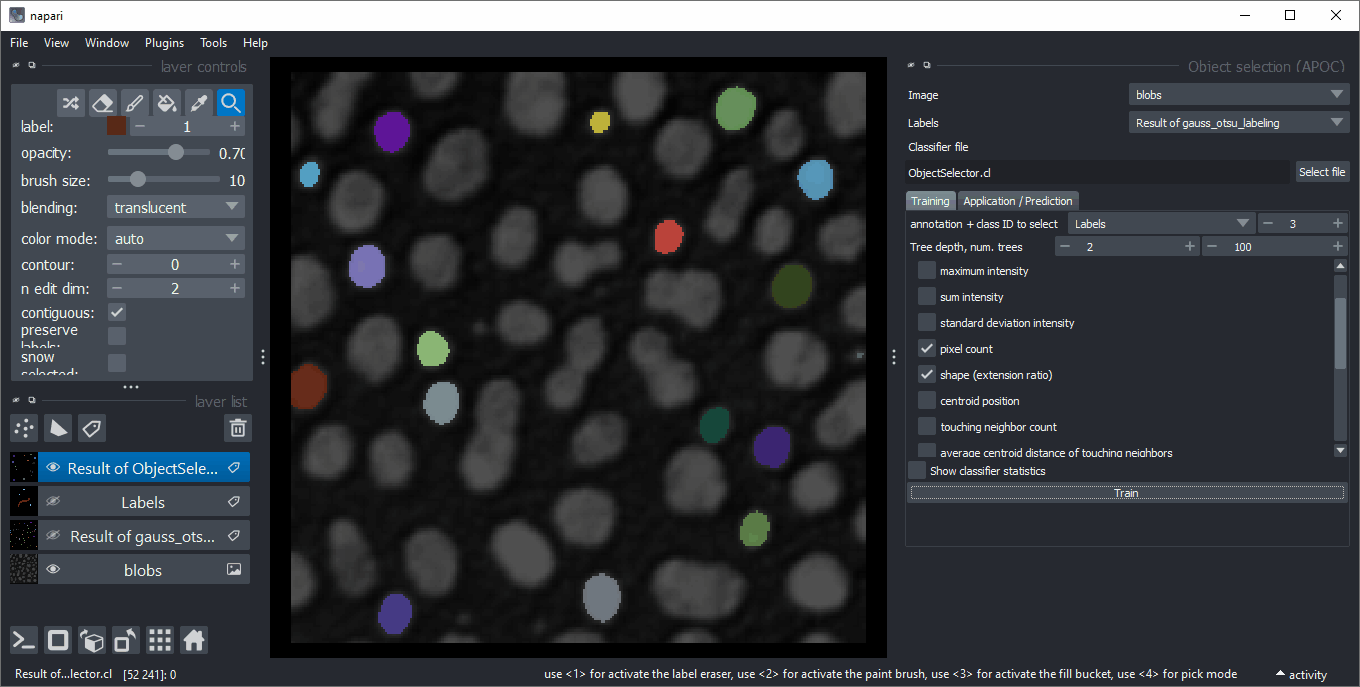
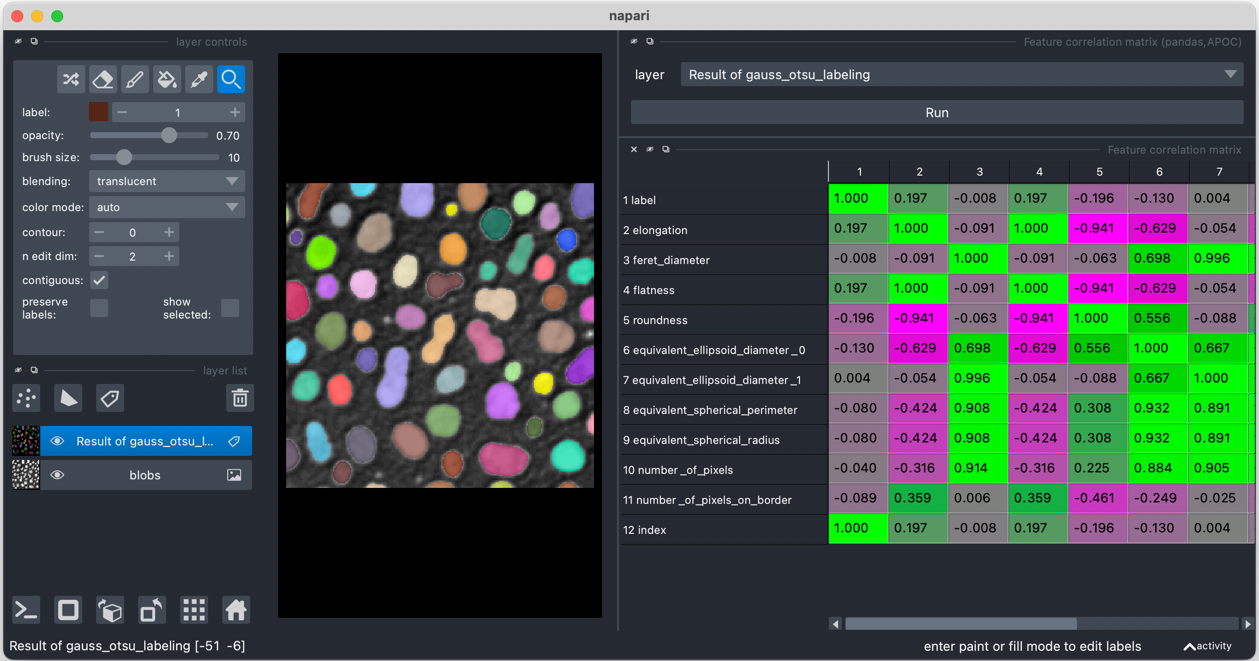
Feature correlation matrix
When training object classifiers it is crucial to investigate to which degree features are correlated and select the right, ideally uncorrelated features to classify objects robustly.
After measuring features with any compatible napari plugin listed below, you can visualize the feature correlation matrix using the menu Tools > Measurement tables > Show feature correlation matrix (pandas, APOC) and by selecting the labels layer which has been analyzed.
Before computing the correlation matrix, all rows containing NaN values are removed.
For further details, please refer to the documentation of the underlying function in pandas.
Surface Vertex Classification (SVeC)
When using napari-APOC in combination with napari-process-points-and-surfaces>=0.3.3,
one can also classify vertices. Therefore, use for example the menu Measurement > Surface quality table (vedo, nppas) to determine quantitative measurements
and the menu Surfaces > Annotate surface manually (nppas) for manual annotations. It is recommended to annotate the entire surface with value 1 as background, and specific regions of interest with integer numbers > 1.
After measurements have been extracted and annotations were made, start SVeC from the Surfaces > Surface vertex classification (custom properties, APOC) menu. It can be used like the Object Classifier explained above.

Classifier statistics
After classifier training, you can study the share of the individual features/measurements and how they are correlated by activating the checkboxes Show classifier statistics and Show feature correlation matrix.
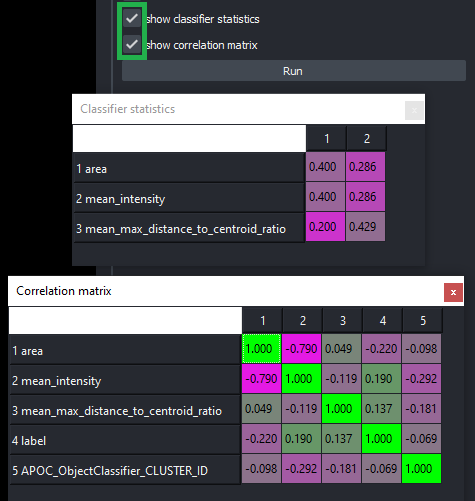
This can help understanding how the classifier works. Furthermore, you can accelerate the classifier by reducing the number of correlated features.
Object classification from custom measurements
You can also classify labeled objects according to custom measurements. For deriving those measurements, you can use these napari plugins:
- morphometrics
- PartSeg
- napari-simpleitk-image-processing
- napari-cupy-image-processing
- napari-pyclesperanto-assistant
- napari-skimage-regionprops
Furthermore, if you use napari from Python, you can also create a dictionary or pandas DataFrame with measurements and store it in the labels_layer.features to make them available in the object classifier.
After labels have been measured, you can start the Object Classifier (custom properties, APOC) from the Tools > Segmentation post-processing menu:
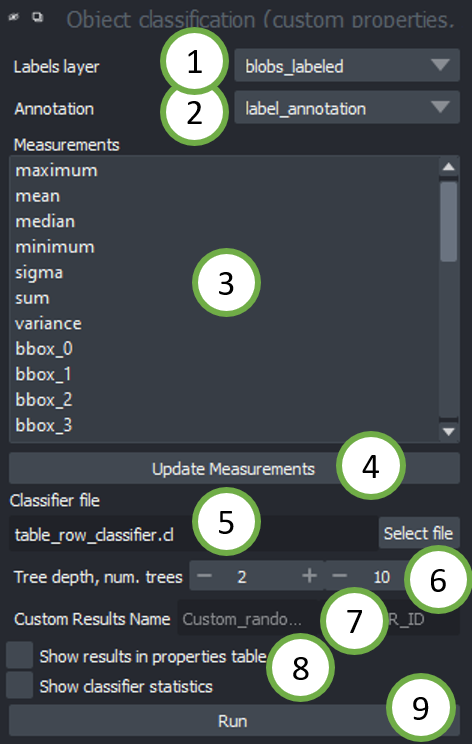
- Select the labels layers that has been measured.
- The annotation layer should contain manual annotations of object classes. You can draw lines crossing single and multiple objects of the same kind. For example draw a line through some elongated objects with label "1" and another line through some rather roundish objects with label "2". If these lines touch the background, that will be ignored.
- Select the measurements / features that should be used for object classification.
- Use the
Update Measurementsbutton in case you did new measurements after Object classifier dialog was opened. - Enter the filename of the classifier to be trained here. This file will be overwritten in case it existed already.
- Tree depth and number of trees allow you to fine-tune how to deal with manifold objects of different characteristics. The higher these numbers, the longer classification will take. In case you use many features, high depth and number of trees might be necessary. (See also
max_depthandn_estimatorsin the scikit-learn documentation of the Random Forest Classifier. - The classification result will be stored under this name in the labels-layer's properties.
- Choose if the results table should be shown. Choose if classifier statistics should be shown. Read more about classifier statistics.
- Click on
Runto start training and prediction.
You can also train those classifiers from Python and reuse them: Read more about using the TableRowClassifier from python
Classifier statistics and correlation matrix
After classifier training, you can study the share of the individual features/measurements and how they are correlated by activating the checkboxes Show classifier statistics and Show correlation matrix.
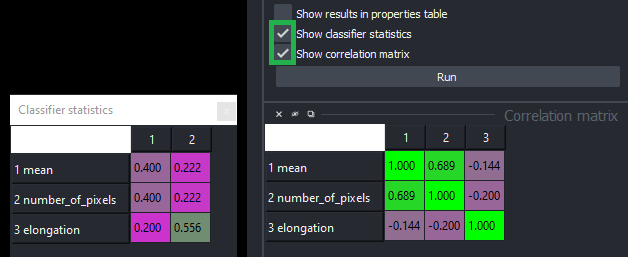
This can help understanding how the classifier works. Furthermore, you can accelerate the classifier by reducing the number of correlated features.
This napari plugin was generated with Cookiecutter using with @napari's cookiecutter-napari-plugin template.
Installation
It is recommended to install the plugin in a conda environment. Therefore install conda first, e.g. mini-conda. If you never worked with conda before, reading this short introduction might be helpful.
Optional: Setup a fresh conda environment, activate it and install napari:
conda create --name napari_apoc python=3.9
conda activate napari_apoc
conda install napari
If your conda environment is set up, you can install napari-accelerated-pixel-and-object-classification using pip. Note: you need pyopencl first.
conda install -c conda-forge pyopencl
pip install napari-accelerated-pixel-and-object-classification
Mac-users please also install this:
conda install -c conda-forge ocl_icd_wrapper_apple
Linux users please also install this:
conda install -c conda-forge ocl-icd-system
Contributing
Contributions, feedback and suggestions are very welcome. Tests can be run with tox, please ensure the coverage at least stays the same before you submit a pull request.
Similar software
There are other napari plugins and other software with similar functionality for interactive classification of pixels and objects.
License
Distributed under the terms of the BSD-3 license, "napari-accelerated-pixel-and-object-classification" is free and open source software
Issues
If you encounter any problems, please open a thread on image.sc along with a detailed description and tag @haesleinhuepf.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file napari-accelerated-pixel-and-object-classification-0.14.1.tar.gz.
File metadata
- Download URL: napari-accelerated-pixel-and-object-classification-0.14.1.tar.gz
- Upload date:
- Size: 55.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2f626a9c2d671bf32cade62df74666eef328e6dc3f6d7f3ab6091a992131fb5c
|
|
| MD5 |
e7044d9a2833a4303c90e8d7a832efe7
|
|
| BLAKE2b-256 |
2a02deee925bd122e5eab619122d794460bfa0e998aeea099dded78c45746b24
|
File details
Details for the file napari_accelerated_pixel_and_object_classification-0.14.1-py3-none-any.whl.
File metadata
- Download URL: napari_accelerated_pixel_and_object_classification-0.14.1-py3-none-any.whl
- Upload date:
- Size: 33.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
041bc5347e40cf8b4581a9e0c1f1d20c6526c9f1fa68e7056c594db4dd057b88
|
|
| MD5 |
0ace4e511dd0c6be41f806545c4fe42b
|
|
| BLAKE2b-256 |
cb0d11fca309754dd4c97332f0e4837ab985d91c65c71d0b07e5614ede74c35d
|







