NWB extensions for storing hierarchical behavioral data



Project description
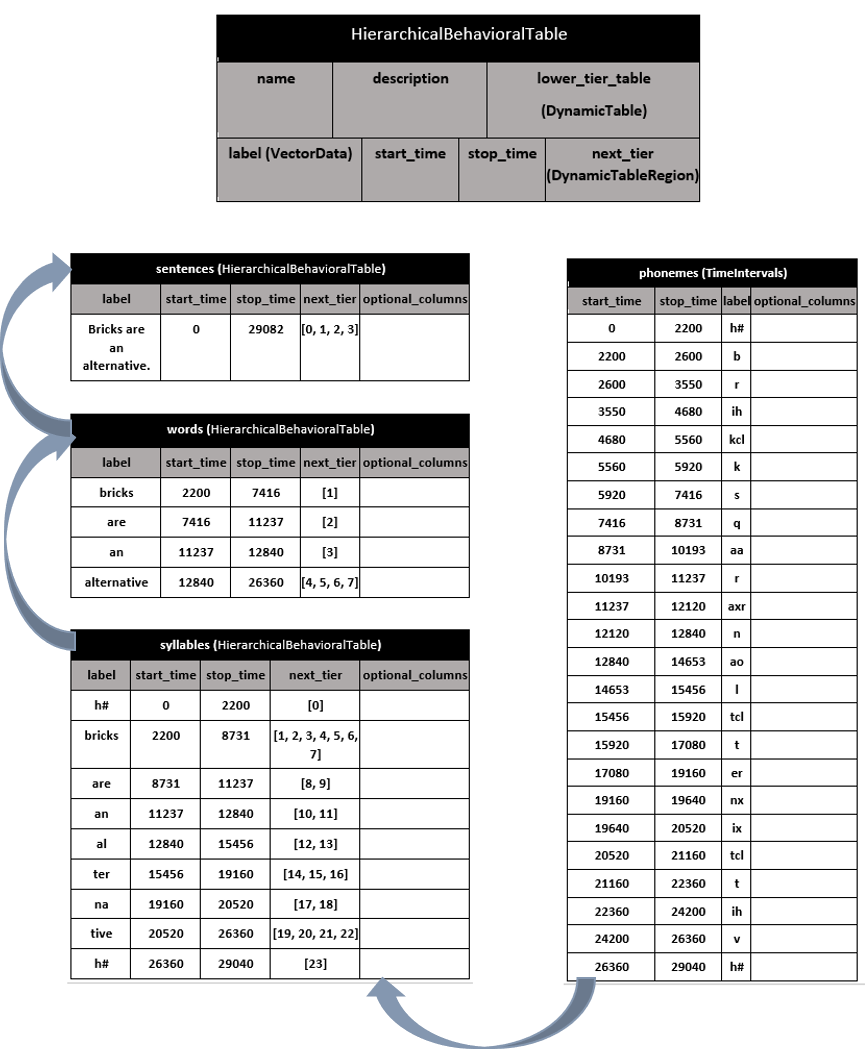
ndx-hierarchical-behavioral-data Extension for NWB

Installation
pip install ndx-hierarchical-behavioral-data
Usage
Use pre-made hierarchical transcription tables:
from ndx_hierarchical_behavioral_data.definitions.transcription import TIPhonemes, HBTSyllables, HBTWords, HBTSentences
# Phonemes level
phonemes = TIPhonemes()
phonemes.add_column('max_pitch', 'maximum pitch for this phoneme. NaN for unvoiced')
for i, p in enumerate('abcdefghijkl'):
phonemes.add_interval(label=p, start_time=float(i), stop_time=float(i+1), max_pitch=i**2)
# Syllables level
syllables = HBTSyllables(lower_tier_table=phonemes)
syllables.add_interval(label='abc', next_tier=[0, 1, 2])
syllables.add_interval(label='def', next_tier=[3, 4, 5])
syllables.add_interval(label='ghi', next_tier=[6, 7, 8])
syllables.add_interval(label='jkl', next_tier=[9, 10, 11])
# Words level
words = HBTWords(lower_tier_table=syllables)
words.add_column('emphasis', 'boolean indicating whether this word was emphasized')
words.add_interval(label='A-F', next_tier=[0, 1], emphasis=False)
words.add_interval(label='G-L', next_tier=[2, 3], emphasis=True)
# Sentences level
sentences = HBTSentences(lower_tier_table=words)
sentences.add_interval(label='A-L', next_tier=[0, 1])
View individual tiers:
sentences.to_dataframe()
| label | start_time | stop_time | next_tier | |
|---|---|---|---|---|
| id | ||||
| 0 | A-L | 0.0 | 12.0 | label start_time stop_time \\id ... |
words.to_dataframe()
| label | start_time | stop_time | next_tier | emphasis | |
|---|---|---|---|---|---|
| id | |||||
| 0 | A-F | 0.0 | 6.0 | label start_time stop_time \\ id 0 abc 0.0 3.0 1 def 3.0 6.0 next_tier id 0 start_time stop_time label max_pitch id 0 0.0 1.0 a 0 1 1.0 2.0 b 1 2 2.0 3.0 c 4 1 start_time stop_time label max_pitch id 3 3.0 4.0 d 9 4 4.0 5.0 e 16 5 5.0 6.0 f 25 | False |
| 1 | G-L | 6.0 | 12.0 | label start_time stop_time \\ id 2 ghi 6.0 9.0 3 jkl 9.0 12.0 next_tier id 2 start_time stop_time label max_pitch id 6 6.0 7.0 g 36 7 7.0 8.0 h 49 8 8.0 9.0 i 64 3 start_time stop_time label max_pitch id 9 9.0 10.0 j 81 10 10.0 11.0 k 100 11 11.0 12.0 l 121 | True |
syllables.to_dataframe()
| label | start_time | stop_time | next_tier | |
|---|---|---|---|---|
| id | ||||
| 0 | abc | 0.0 | 3.0 | start_time stop_time label id 0 0.0 1.0 a 1 1.0 2.0 b 2 2.0 3.0 c |
| 1 | def | 3.0 | 6.0 | start_time stop_time label id 3 3.0 4.0 d 4 4.0 5.0 e 5 5.0 6.0 f |
| 2 | ghi | 6.0 | 9.0 | start_time stop_time label id 6 6.0 7.0 g 7 7.0 8.0 h 8 8.0 9.0 i |
| 3 | jkl | 9.0 | 12.0 | start_time stop_time label id 9 9.0 10.0 j 10 10.0 11.0 k 11 11.0 12.0 l |
phonemes.to_dataframe()
| start_time | stop_time | label | max_pitch | |
|---|---|---|---|---|
| id | ||||
| 0 | 0.0 | 1.0 | a | 0 |
| 1 | 1.0 | 2.0 | b | 1 |
| 2 | 2.0 | 3.0 | c | 4 |
| 3 | 3.0 | 4.0 | d | 9 |
| 4 | 4.0 | 5.0 | e | 16 |
| 5 | 5.0 | 6.0 | f | 25 |
| 6 | 6.0 | 7.0 | g | 36 |
| 7 | 7.0 | 8.0 | h | 49 |
| 8 | 8.0 | 9.0 | i | 64 |
| 9 | 9.0 | 10.0 | j | 81 |
| 10 | 10.0 | 11.0 | k | 100 |
| 11 | 11.0 | 12.0 | l | 121 |
Hierarchical dataframe:
sentences.to_hierarchical_dataframe()
| source_table | phonemes | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| label | id | start_time | stop_time | label | max_pitch | ||||||||||||
| sentences_id | sentences_label | sentences_start_time | sentences_stop_time | words_id | words_label | words_start_time | words_stop_time | words_emphasis | syllables_id | syllables_label | syllables_start_time | syllables_stop_time | |||||
| 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 3.0 | 1 | 1.0 | 2.0 | b | 1 | ||||||||||||
| 3.0 | 2 | 2.0 | 3.0 | c | 4 | ||||||||||||
| 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 | |||||||||
| 6.0 | 4 | 4.0 | 5.0 | e | 16 | ||||||||||||
| 6.0 | 5 | 5.0 | 6.0 | f | 25 | ||||||||||||
| 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 | ||||
| 9.0 | 7 | 7.0 | 8.0 | h | 49 | ||||||||||||
| 9.0 | 8 | 8.0 | 9.0 | i | 64 | ||||||||||||
| 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 | |||||||||
| 12.0 | 10 | 10.0 | 11.0 | k | 100 | ||||||||||||
| 12.0 | 11 | 11.0 | 12.0 | l | 121 |
Hierachical columns, flattened rows:
from hdmf.common.hierarchicaltable import flatten_column_index
flatten_column_index(sentences.to_hierarchical_dataframe(), 1)
| id | start_time | stop_time | label | max_pitch | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sentences_id | sentences_label | sentences_start_time | sentences_stop_time | words_id | words_label | words_start_time | words_stop_time | words_emphasis | syllables_id | syllables_label | syllables_start_time | syllables_stop_time | |||||
| 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 3.0 | 1 | 1.0 | 2.0 | b | 1 | ||||||||||||
| 3.0 | 2 | 2.0 | 3.0 | c | 4 | ||||||||||||
| 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 | |||||||||
| 6.0 | 4 | 4.0 | 5.0 | e | 16 | ||||||||||||
| 6.0 | 5 | 5.0 | 6.0 | f | 25 | ||||||||||||
| 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 | ||||
| 9.0 | 7 | 7.0 | 8.0 | h | 49 | ||||||||||||
| 9.0 | 8 | 8.0 | 9.0 | i | 64 | ||||||||||||
| 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 | |||||||||
| 12.0 | 10 | 10.0 | 11.0 | k | 100 | ||||||||||||
| 12.0 | 11 | 11.0 | 12.0 | l | 121 |
Denormalized dataframe:
from hdmf.common.hierarchicaltable import to_hierarchical_dataframe
to_hierarchical_dataframe(sentences).reset_index()
| source_table | sentences | words | syllables | phonemes | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| label | id | label | start_time | stop_time | id | label | start_time | stop_time | emphasis | id | label | start_time | stop_time | id | start_time | stop_time | label | max_pitch |
| 0 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 1 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 1 | 1.0 | 2.0 | b | 1 |
| 2 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 2 | 2.0 | 3.0 | c | 4 |
| 3 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 |
| 4 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 4 | 4.0 | 5.0 | e | 16 |
| 5 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 5 | 5.0 | 6.0 | f | 25 |
| 6 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 |
| 7 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 7 | 7.0 | 8.0 | h | 49 |
| 8 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 8 | 8.0 | 9.0 | i | 64 |
| 9 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 |
| 10 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 10 | 10.0 | 11.0 | k | 100 |
| 11 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 11 | 11.0 | 12.0 | l | 121 |
Denormalized dataframe with flattened columns:
from hdmf.common.hierarchicaltable import flatten_column_index
flatten_column_index(sentences.to_hierarchical_dataframe(), 1).reset_index()
| sentences_id | sentences_label | sentences_start_time | sentences_stop_time | words_id | words_label | words_start_time | words_stop_time | words_emphasis | syllables_id | syllables_label | syllables_start_time | syllables_stop_time | id | start_time | stop_time | label | max_pitch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 1 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 1 | 1.0 | 2.0 | b | 1 |
| 2 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 2 | 2.0 | 3.0 | c | 4 |
| 3 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 |
| 4 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 4 | 4.0 | 5.0 | e | 16 |
| 5 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 5 | 5.0 | 6.0 | f | 25 |
| 6 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 |
| 7 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 7 | 7.0 | 8.0 | h | 49 |
| 8 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 8 | 8.0 | 9.0 | i | 64 |
| 9 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 |
| 10 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 10 | 10.0 | 11.0 | k | 100 |
| 11 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 11 | 11.0 | 12.0 | l | 121 |
This extension was created using ndx-template.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ndx-hierarchical-behavioral-data-0.1.2.tar.gz.
File metadata
- Download URL: ndx-hierarchical-behavioral-data-0.1.2.tar.gz
- Upload date:
- Size: 23.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
51c9ceaeff91d94a5f87825282135a25a9410b417feaeee6520ce5d3aeaebcc1
|
|
| MD5 |
d1082277a6ff7db9716eb4749f8bcdeb
|
|
| BLAKE2b-256 |
d68dc1bc28043c951d4c9e2a2796f2fb02eedc3d3cb0d028a1066c35262b20dd
|
File details
Details for the file ndx_hierarchical_behavioral_data-0.1.2-py2.py3-none-any.whl.
File metadata
- Download URL: ndx_hierarchical_behavioral_data-0.1.2-py2.py3-none-any.whl
- Upload date:
- Size: 15.9 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
998938256e8128077aec932f66883d8d9f69580b5226f47c5862883058b4dda0
|
|
| MD5 |
fa23967c18efc79a3395906c09a63dca
|
|
| BLAKE2b-256 |
d8dfe84fe4e68a51bea3ac0797aec0bf14051d05976540aad0ca4fd07cb53a4f
|







