Simulate random phylogenetic trees

Project description
Ngesh, a library for phylogenetic tree simulation





ngesh is a Python library and command-line tool
for simulating phylogenetic trees and related data (characters, states,
branch length, etc.).
It is intended for benchmarking phylogenetic methods, especially in
historical linguistics and stemmatology. The generation of
stochastic phylogenetic trees also goes by the name "simulation methods
for phylogenetic trees", "synthetic data generation", or just "phylogenetic tree simulation".

Among the highlights of the package, with ngesh:
- any hashable element can be provided as a seed for the pseudo-random number generators, guaranteeing that the synthetic trees are reproducible (including across different systems)
- trees can be generated according to user-specified parameters such as birth and death ratios (and the death ratio can be set to zero, resulting in a birth-only tree)
- trees will have random topologies and, if desired, random branch-lengths
- trees can be constrained in terms of number of extant leaves, evolution time (as related to the birth and death parameters), or both
- non-extant leaves can be pruned from birth-death trees
- speciation events default to two descendants, but the number of descendants can be randomly drawn from a user-defined Poisson process (allowing to model hard politomies)
- character evolution can be simulated in relation to branch lengths, with user-specified ratios for mutation and for horizontal gene transfer, with different rates of change for each character
- nodes can receive unique labels, either sequential ones (like "L01", "L02", and "L03"), random names easy to pronounce (like "Sume", "Fekobir", and "Tukok"), or random biological names approximating the binomial nomenclature standard (like "Sburas wioris", "Zurbata ceglaces", and "Spellis spusso")
- trees are normal ETE3 tree objects that can be exported in a variety of formats, such as Newick trees, ASCII representation, tabular textual listings, etc.
Installation
In any standard Python environment, ngesh can be installed with:
pip install ngesh
The pip installation will fetch the dependencies ete3 and
numpy, if necessary. The built-in tree visualization
tool from ete3 requires the PyQt5 library which is not installed
by default, but which should be available in most systems.
If necessary, it can be
installed along with the package with:
pip install ngesh[gfx]
How to use
You can test your installation from the command line with the ngesh command, which
will return a different random small birth-death tree in Newick format each time it
is called:
$ ngesh
((Vovrera:0.149348,(Wigag:3.11592,(Pallo:2.68125,Zoei:1.85803)1:1.29704)1:0.204529)1:0.607805,(((Avi:0.347942,Uemi:0.0137646)1:1.41697,(((Kufo:0.817012,
(Gapurem:0.0203582,Hukub:0.0203582)1:0.796654)1:0.395727,Tablo:0.00846148)1:0.484705,(Kaza:0.140656,((Tozea:0.240634,Pebigmom:0.240634)1:1.13579,(Kata:0
.109977,((Fabom:0.04242,Upik:0.04242)1:0.549364,(Amue:0.182635,Lunida:0.182635)1:0.409149)1:0.366701)1:0.417941)1:0.162968)1:0.158051)1:1.47281)1:1.0326
,(Kunizob:0.650455,Madku:0.221172)1:1.22008)1:0.587783);
$ ngesh
((((Povi:0.325601,Udo:0.325601)1:0.0750448,Hiruta:0.400646)1:0.181454,(Voebi:0.0293506,Sodi:0.0293506)1:0.55275)1:0.258834,((Vandemif:0.0160558,(((Dubik
:0.0543122,Fuvu:0.0543122)1:0.36458,Hitfuv:0.418892)1:0.0388987,Pizuna:0.457791)1:0.0535386)1:0.179893,(Uo:0.67132,Zegna:0.163427)1:0.0199021)1:0.149711
);
The same command-line tool can use parameters provided in a textual
configuration file. Here, we generate the Nexus data for a
reproducible Yule tree (note the 123 seed)
with a birth ratio of 0.666, at least 8 leaves with "human" labels,
and 10 presence/absence characters:
$ cat ngesh_demo.conf
[Config]
labels=human
birth=0.666
death=0.0
output=nexus
min_leaves=8
num_chars=10
$ ngesh -c ngesh_demo.conf --seed 123
#NEXUS
begin data;
dimensions ntax=16 nchar=38;
format datatype=standard missing=? gap=-;
matrix
Abel 10001001011000010000010010010000100000
Azogu 10001001011000010000010010010000100000
Bou 10001001100010100000010010010000000010
Dipu 10001001010001000010000110010000000001
Gezepsem 10001001100010100000010010010000000010
Gupote 10001001010010010000010010010000000100
Hefi 10100100010010010001000001010001000000
Lerzo 10001001010001000010000110010000000001
Magumel 10001001010010010000010010010000000010
Pao 01001010010100001000100010001000100000
Sanigo 10010100010010000100001000100010010000
Tuzizo 10001001100010100000010010010000000010
Wialum 10001001011000010000010010000100100000
Zudal 10001001010010010000010010010000100000
Zukar 10001001011000010000010010000100100000
Zusu 10010100010010000100001000100010001000
;
end;
All parameters provided in the configuration files can be overridden at the command-line.
A textual representation of the same tree (that is, of the
random tree generated with the set of parameters and the same
seed) can be obtained with the
-o ascii flag:
$ ngesh -c ngesh_demo.conf --seed 123 -o ascii
/-Zudal
|
| /-Azogu
| |
| /-| /-Wialum
| | | /-|
| | \-| \-Zukar
| /-| |
| | | \-Abel
| | |
/-| | | /-Dipu
| | | \-|
| | /-| \-Lerzo
| | | |
| | | | /-Bou
| | | | /-|
| | | | /-| \-Gezepsem
| | /-| | | |
/-| | | | \-| \-Tuzizo
| | | | | |
| | \-| | \-Magumel
| | | |
| | | \-Pao
| | |
--| | \-Gupote
| |
| | /-Zusu
| \-|
| \-Sanigo
|
\-Hefi
The package is, however, designed to be used as a library. If you have PyQt5 installed, the following command will open the ETE Tree Viewer on the same random tree:
$ ngesh -c ngesh_demo.conf --seed 123 -o gfx
Likewise, the following code is useful for quick demonstration and will pop up the Viewer on a random tree each time it is called:
python3 -c "import ngesh ; ngesh.show_random_tree()"
The primary functions for generation are gen_tree()
(doc),
which returns a random tree topology, and
add_characters() (doc),
which simulates character evolution in a provided tree. As they are separate tasks, it is possible to just generate a
random tree or to simulate character evolution in an user provided tree.
The code snippet below shows a basic tree generation, character evolution, and the output flow.
>>> import ngesh
>>> tree = ngesh.gen_tree(1.0, 0.5, max_time=3.0, labels="human")
>>> print(tree)
/-Butobfa
/-|
| | /-Defomze
| \-|
| \-Gegme
--|
| /-Bo
| /-|
| | \-Peoni
\-|
| /-Riuzo
\-|
\-Hoale
>>> tree = ngesh.add_characters(tree, 10, 3.0, 1.0)
>>> print(ngesh.tree2nexus(tree))
#NEXUS
begin data;
dimensions ntax=7 nchar=15;
format datatype=standard missing=? gap=-;
matrix
Hoale 100111101101110
Butobfa 101011101110101
Defomze 101011110110101
Riuzo 100111101101110
Peoni 110011101110110
Bo 110011101110110
Gegme 101011101110101
;
end;
Newick representations of trees can be "sorted", solving comparison issues of these structures (remember that phylogenetic trees are like "hanging mobiles"). The module is self-contained and can be called from the command-line:
$ cat tiago.newick
(Ei:0.98,(Mepale:0.39,(Srufo:0.14,Pulet:0.14):0.24):0.58);
$ src/ngesh/newick.py -i tiago.newick
(((Pulet:0.14,Srufo:0.14):0.24,Mepale:0.39):0.58,Ei:0.98);
Parameters for tree generation
The parameters for tree generation, as also given by the command ngesh -h, are:
birth: The tree birth rate (l)death: The tree death rate (mu)max_time: The stopping criterion for maximum evolution timemin_leaves: The stopping criterion for minimum number of leaveslabels: The model for textual generation of random labels (None,"enum"for a simple enumeration,"human"for randomly generated names, and"bio"for randomly generated specie names)num_chars: The number of characters to be simulatedk_mut: The character mutation gammakparameterth_mut: The character mutation gammathparameterk_hgt: The character HGT gammakparameterth_hgt: The character HGT gammathparametere: The character general mutationeparameter
How does ngesh work?
An event_rate is first computed from the sum of the birth and death rates. At each iteration, which takes place after
a random expovariant time from the event_rate, the library selects one of the extant nodes for an "event": either a
birth or a death, drawn from the proportion of each rate. All other extant leaves have their distances updated
with the event time.
The random labels follow the expected methods for random text generation from a set of patterns, taking care to generate names that should be easy to pronounce by most users.
For random character generation, it adds characters according to parameters of gamma distributions related to the length of each branch. The two possible events are mutation (assumed to be always to a new character, i.e., no parallel evolution) and horizontal gene transfer. No perturbation, such as the simulation of errors in sequencing/data collection, is performed during character generation. However, these can be simulated by the function for bad sampling simulation. Note that character generation only simulates states analogous to those of historical linguistics (cognate sets) and assumes character independence (that is, no block movement as common in stemmatology). While we might implement the latter in the future, there are currently no plans for simulating genetic data.
Bad sampling is simulated in an uniform distribution, i.e., all existing leaves have the same probability of being removed. Note that if a full simulation of tree topology and characters is performed, this task must be carried out after character evolution simulation, as otherwise characters would fit the sampled tree and not the original one. No method for data perturbation is available at the moment, but we have plans to implement them in the future.
Integrating with other software
Integration with other packages is facilitated by various export functions. For example, it is possible to generate random trees with characters for which we know all details on evolution and parameters, and generate Nexus files that can be fed to phylogenetic software such as MrBayes or BEAST2 to either check how they perform or how good is our generation in terms of real data.
Let's simulate phylogenetic data for an analysis using BEAST2 through
BEASTling. We start with
a birth-death tree (lambda=0.9, mu=0.3), with at least 15 leaves, and 100
characters whose evolution is modelled with the default parameters
and a string seed "uppsala" for reproducibility; the tree data is exported
in "wordlist" format:
$ cat examples/example_ngesh.conf
[Config]
labels=human
birth=0.9
death=0.3
output=nexus
min_leaves=15
num_chars=100
$ ngesh -c examples/example_ngesh.conf --seed uppsala > examples/example.csv
$ head -n 20 examples/example.csv
Language_ID,Feature_ID,Value
Akup,feature_0,0
Buter,feature_0,0
Dufou,feature_0,0
Emot,feature_0,0
Kiu,feature_0,0
Kovala,feature_0,0
Lusei,feature_0,0
Oso,feature_0,0
Puota,feature_0,0
Relenin,feature_0,976
Sotok,feature_0,0
Tetosur,feature_0,0
Usimi,feature_0,976
Voe,feature_0,0
Vusodur,feature_0,0
Zeba,feature_0,0
Zufe,feature_0,0
Akup,feature_1,1
Buter,feature_1,1
We can now use a minimal BEASTling configuration and generate an XML model for BEAST2. Let's assume we want to test how well our pipeline performs when assuming a Yule tree when the data actually includes extinct taxa. The results here presented are not expected to perfect, as we will use a short chain length to make it faster and a model which differs from the assumptions used for generation (besides the fact of the default parameters for horizontal gene transfer being too high for this simulation).
$ cat examples/example_beastling.conf
[admin]
basename=example
[MCMC]
chainlength=500000
[model example]
model=covarion
data=example.csv
$ beastling example_beastling.conf
$ beast example.xml
We can go ahead normally here: use BEAST2's treeannotator (or similar
software) to generate a summary tree,
which we store in examples/summary.nex,
and plot the results with figtree (or, again, similar software).
Let's plot our summary tree and compare the results with the actual topology (which we can regenerate with the earlier seed).
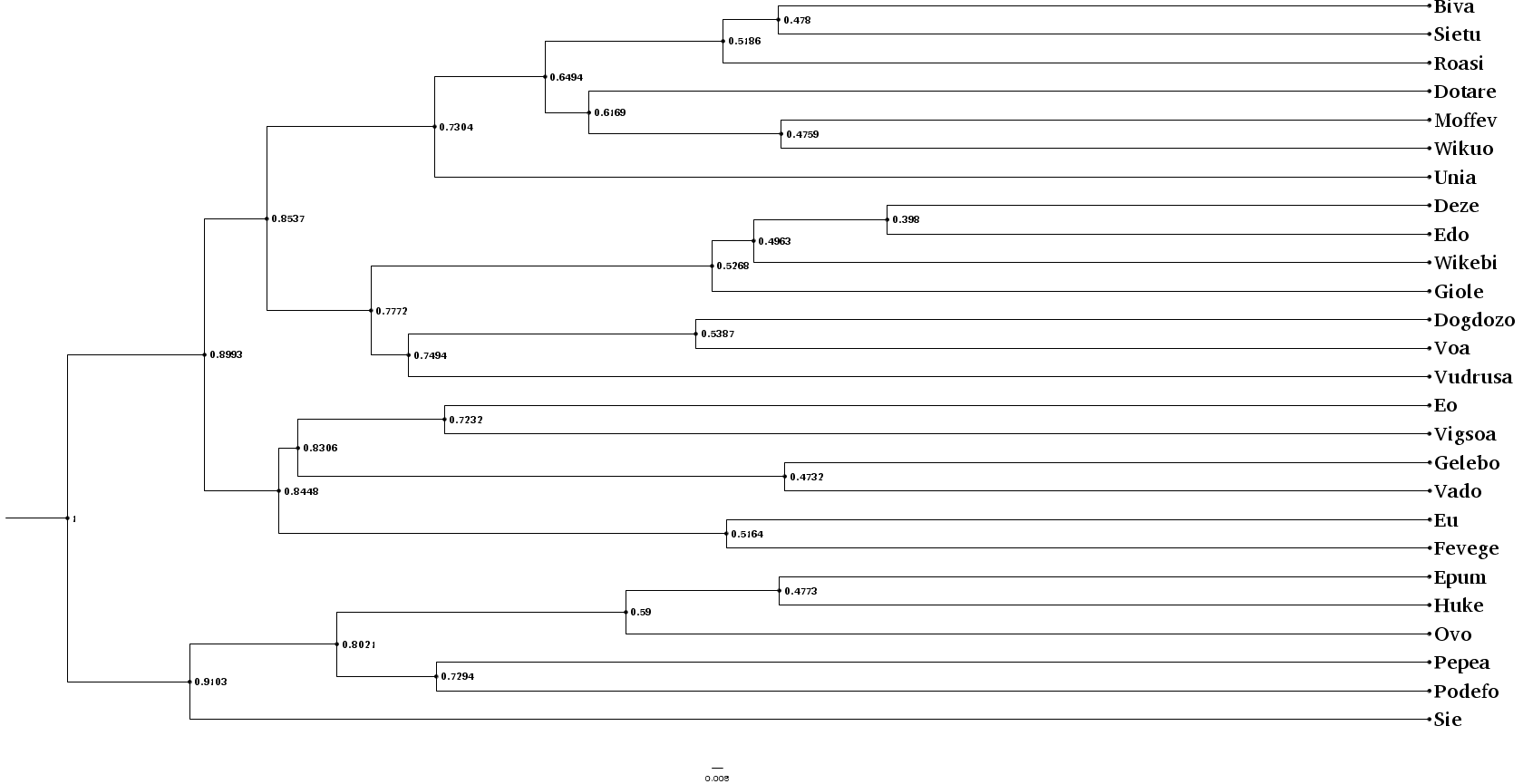
$ ngesh -c examples/example_ngesh.conf --seed uppsala --output newick > examples/example.nw
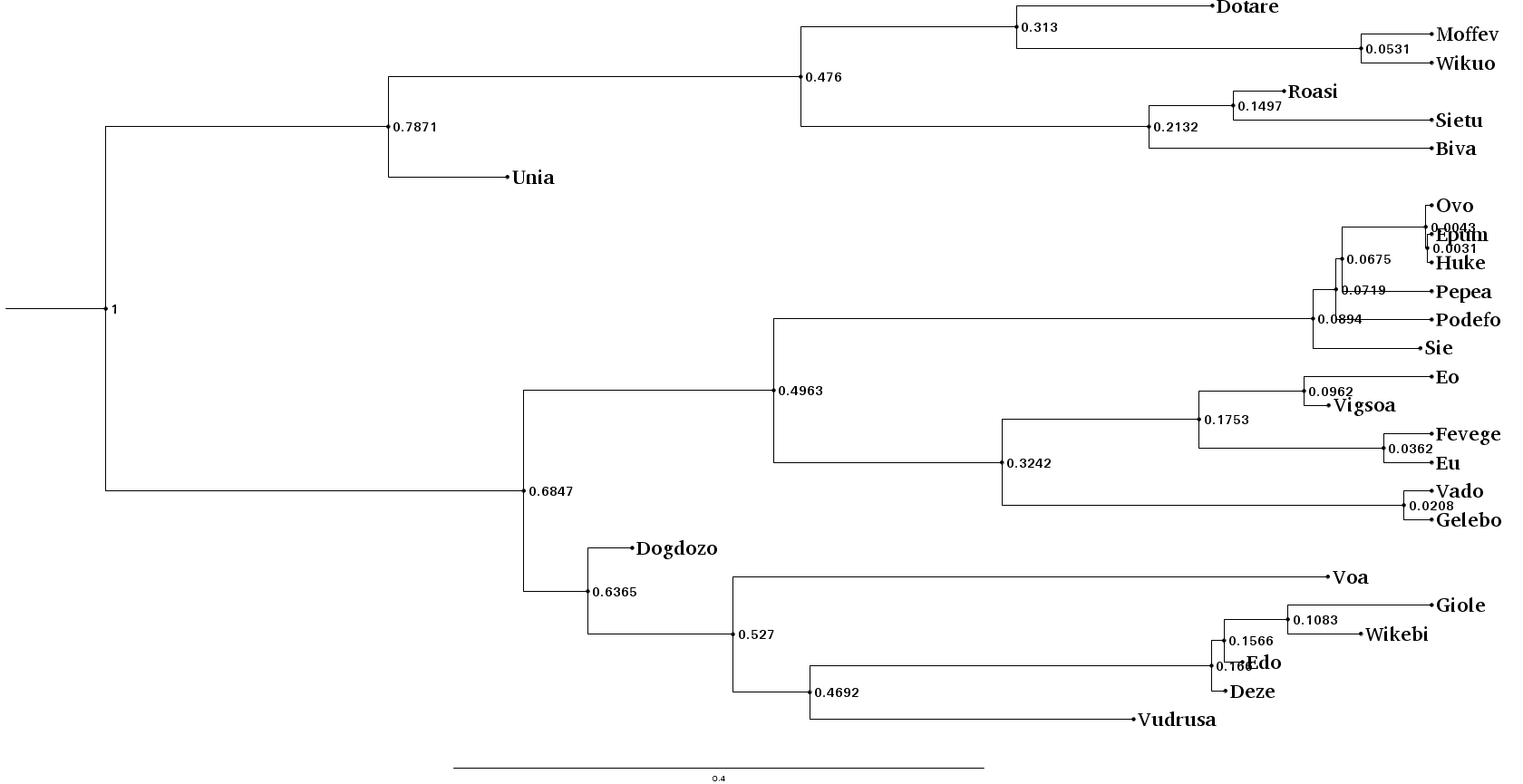
The results are not excellent given the limits we set for quick demonstration, but it still capture major information and sub-groupings (as clearer by the radial layout below) — manual data exploration show that at least some errors, including the group in the first split, are due to horizontal gene transfer. For an analysis of the inference performance, we would need to improve the parameters above and repeat the analysis on a range of random trees, including studying the log of character changes (including borrowings) involved in this random tree.

We can compare trees with common methods of tree
comparison, such as Robinson–Foulds metric.
All packages and programming languages for this purpose should be
able to read the trees exported in Newick or NEXUS format; however,
as ngesh trees are actually ETE3 trees, we can do it directly
from Python:
d = tree1.robinson_foulds(tree_2)
The files used and generated in this example can be found in the
/examples directory.
What does "ngesh" mean?
Technically, "ngesh" is just an unique name, coming from one of the Sumerian words for "tree", ĝeš. The name was chosen because the library was first planned as part of a larger system for simulating language evolution and benchmarking related tools, named Enki after the Sumerian god of (among many other things) language and "randomness".
The intended pronunciation, as in the most accepted reconstructions, is /ŋeʃ/. But don't stress over it, and feel free to call it /n̩.gɛʃ/, as most people have been doing.
Alternatives
There are many tools for simulating phylogenetic processes to obtain
random phylogenetic trees. The most complete is probably the R package
TreeSim
by Tanja Stadler, which includes many flexible tree simulation functions. In
R, one can also use the rtree() function from package ape and the
birthdeath.tree() one from package geiger, as well as manually randomizing taxon
placement in cladograms.
In Python, a snippet that works in a way similar to ngesh, and which served as initial inspiration,
is provided by Marc-Rolland Noutahi on the blog post
How to simulate a phylogenetic tree ? (part 1).
For simpler simulations, the .populate() method of the Tree class
in ETE might be enough as well. Documentation on the method is
available
here.
The toytree and dendropy packages also offer comparable functionality.
A number of on-line tools for simulating trees are available at the time of writing:
- T-Rex (Tree and reticulogram REConstruction at the Université du Québec à Montréal (UQAM)
- Anvi'o Server can be used on-line as a wrapper to T-Rex above
- phyloT, which by randomly sampling taxonomic names, identifiers or protein accessions can be used for the same purpose
Gallery
References
-
Bailey, Norman. T. J. (1964). The elements of stochastic processes with applications to the natural sciences. John Wiley & Sons.
-
Bouckaert, Remco; Vaughan, Timothy G.; Barido-Sottani, Joëlle; Duchêne, Sebastián; Fourment, Mathieu; Gavryushkina, Alexandra., et al. (2019). "BEAST 2.5: An advanced software platform for Bayesian evolutionary analysis". PLoS computational biology, 15(4), e1006650. DOI: 10.1371/journal.pcbi.1006650.
-
Foote, Mike; Hunter, John P.; Janis, Christine M.; and Sepkoski J. John Jr. (1999). "Evolutionary and preservational constraints on origins of biologic groups: Divergence times of eutherian mammals". Science 283:1310–1314.
-
Harmon, Luke J. (2019). Phylogenetic Comparative Methods -- learning from trees. Available at: https://lukejharmon.github.io/pcm/chapter10_birthdeath/. Access date: 2019-03-31.
-
Huerta-Cepas, Jaime; Serra, Francois; and Bork, Peer (2016). "ETE 3: Reconstruction, analysis and visualization of phylogenomic data." Mol Biol Evol. DOI: 10.1093/molbev/msw046.
-
Maurits, Luke; Forkel, Robert; Kaiping, Gereon A.; Atkinson, Quentin D. (2017). "BEASTling: A software tool for linguistic phylogenetics using BEAST 2." PLoS one 12(8), e0180908. DOI: 10.1371/journal.pone.0180908.
-
Noutahi, Marc-Rolland (2017). How to simulate a phylogenetic tree? (part 1). Available at: https://mrnoutahi.com/2017/12/05/How-to-simulate-a-tree/. Access date: 2019-03-31.
-
Robinson, D. R.; Foulds, L. R. (1981). "Comparison of phylogenetic trees". Mathematical Biosciences 53 (1–2): 131–147. DOI: 10.1016/0025-5564(81)90043-2.
-
Stadler, Tanja (2011). "Simulating Trees with a Fixed Number of Extant Species". Systematic Biology 60.5:676-684. DOI: 10.1093/sysbio/syr029.
The ngesh banner was designed by Tiago Tresoldi on basis of the
vignette "Sherwood Forest" by J. Needham
published in Needham, J. (1895) Studies of trees in pencil and in water colors. First
series. London, Glasgow, Edinburgh: Blackie & Son. (under public domain and
available on archive.org).
Community guidelines
While the author can be contacted directly for support, it is recommended that third parties use GitHub standard features, such as issues and pull requests, to contribute, report problems, or seek support.
Contributing guidelines, including a code of conduct, can be found in the
CONTRIBUTING.md file.
Author and citation
The library is developed by Tiago Tresoldi (tiago.tresoldi@lingfil.uu.se). The library is developed in the context of the Cultural Evolution of Texts project, with funding from the Riksbankens Jubileumsfond (grant agreement ID: MXM19-1087:1).
During the first stages of development, the author received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. ERC Grant #715618, Computer-Assisted Language Comparison).
If you use ngesh, please cite it as:
Tresoldi, T., (2021). Ngesh: a Python library for synthetic phylogenetic data. Journal of Open Source Software, 6(66), 3173, https://doi.org/10.21105/joss.03173
In BibTeX:
@article{Tresoldi2021ngesh,
doi = {10.21105/joss.03173},
url = {https://doi.org/10.21105/joss.03173},
year = {2021},
publisher = {The Open Journal},
volume = {6},
number = {66},
pages = {3173},
author = {Tiago Tresoldi},
title = {Ngesh: a Python library for synthetic phylogenetic data},
journal = {Journal of Open Source Software}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ngesh-1.2.1.tar.gz.
File metadata
- Download URL: ngesh-1.2.1.tar.gz
- Upload date:
- Size: 895.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1de2f0d76d4f26c8883c91f6ef18e0c4f25fa49aeb76316f2f804bfa98bed7a0
|
|
| MD5 |
00c380611d21bfef40468609b43a6c22
|
|
| BLAKE2b-256 |
e3fdf37e7ec978ab6ae1988c5fa304e6d06f4cd3971b5c72a03155cd2e1f5936
|
File details
Details for the file ngesh-1.2.1-py3-none-any.whl.
File metadata
- Download URL: ngesh-1.2.1-py3-none-any.whl
- Upload date:
- Size: 29.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
75c3fb1b64d0b0d831f3901f19be7ac14b9450e6aa8ec4f74e355c6403a12cae
|
|
| MD5 |
8506dd943e09f6705e4ff661fd5181d1
|
|
| BLAKE2b-256 |
ef489e352c28f99e0b4ff9bd3e9800ac7e0aebf5058ca2e576693ddfa8d88de9
|







