No project description provided

Project description

NNX
Neural Networks for JAX
NNX is a Neural Networks library for JAX that provides a simple yet powerful module system that adheres to standard Python semantics. Its aim is to combine the robustness of Flax with a simplified, Pythonic API akin to that of PyTorch.
- Pythonic: Modules are just regular python classes, they contain their own state, are fully mutable, and allow sharing references between Modules.
- Compatible: Easily convert back and forth between Modules and pytrees using the Functional API to integrate with any JAX API.
- Safe: NNX incorporates mechanisms to try to prevent tracer leakage, avoid stale RNGs, and ensure proper state propagation in order to help produce correct JAX programs.
- Semantic: Partition a Module's state into different semantic collections, allowing for fine-grained control when applying JAX transformations.
Table of Contents
Installation
To get started with nnx, install the package via pip:
pip install nnx
For the most recent version, install directly from our GitHub repository:
pip install git+https://github.com/cgarciae/nnx
Getting Started
The following example guides you through creating a basic Linear model with NNX and executing a forward pass. It also demonstrate how handle mutable state by showing how to keep track of the number of times the model has been called.
import nnx
import jax
import jax.numpy as jnp
class Count(nnx.Variable): pass
class Linear(nnx.Module):
def __init__(self, din: int, dout: int, *, ctx: nnx.Context):
key = ctx.make_rng("params")
self.w = nnx.Param(jax.random.uniform(key, (din, dout)))
self.b = nnx.Param(jnp.zeros((dout,)))
self.count = Count(0) # track the number of calls
def __call__(self, x):
self.count += 1
return x @ self.w + self.b
model = Linear(din=12, dout=2, ctx=nnx.context(0))
# Forward pass and verify the call count
x = jnp.ones((8, 12))
y = model(x)
assert model.count == 1
In this example nnx.context(0) create a PRNGKey for params with seed 0, this is used by make_rng
inside __init__ to generate a random key to initialize the parameters.
Training with the Functional API
The Functional API converts an NNX Module python semantics into pure pytree object with functional semantics. It is the recommended way to use NNX as it provides tight control over the state, allows you to use regular JAX transformations, and it minimizes overhead. In this example the model will be trained using Stochastic Gradient Descent (SGD).
(params, counts), moduledef = model.partition(nnx.Param, Count)
@jax.jit
def train_step(params, counts, x, y):
def loss_fn(params):
y_pred, (updates, _) = moduledef.apply(params, counts)(x)
loss = jax.numpy.mean((y_pred - y) ** 2)
return loss, updates.filter(Count)
# compute gradient
grads, counts = jax.grad(loss_fn, has_aux=True)(params)
# SGD update
params = jax.tree_map(lambda w, g: w - 0.1 * g, params, grads)
return params, counts
# execute the training step
params, counts = train_step(params, counts, x, y)
model = moduledef.merge(params, counts)
assert model.count == 2
Training with Lifted Transforms
Lifted Transforms provide a convenient way interact with NNX Modules. In this example, we use the nnx.jit and nnx.grad lifted transforms to define the training step. The model is trained using Stochastic Gradient Descent (SGD). Because lifted transforms automatically update the Module's state, train_step doesn't require a return statement.
@nnx.jit
def train_step(model, x, y):
def loss_fn(model):
y_pred = model(x)
return jax.numpy.mean((y_pred - y) ** 2)
# compute gradient
grads: nnx.State = nnx.grad(loss_fn, wrt=nnx.Param)(model)
# SGD update
model.update_state(
jax.tree_map(lambda w, g: w - 0.1 * g, model.filter(nnx.Param), grads)
)
# execute the training step
train_step(model, x, y)
assert model.count == 2
Note: Using nnx.jit introduces some overhead when compared to using jax.jit directly. Use nnx.jit for simple prototypes, but for production code use jax.jit directly.
Examples
- Using the Functional API: Shows how to train a simple model using the functional API.
- Using Lifted Transforms: Shows how to train a simple model using lifted transforms.
- Using TrainState: Shows how to train a simple model using the functional API with the help of
TrainState. - Using PureModule (experimental): Shows how to train a simple model using the functional API and leveraging
PureModuleto simplify the code. - Training a VAE: Shows how to train a VAE on the binarized MNIST dataset, uses the functional API,
TrainState, and shows how to use capture intermediate values to retrievekl_loss. - Scan over layers: An contrived example that implements scan over layers with dropout and a share BatcNorm layer to showcase how lifted transforms can be implemented. It uses the functional API along with
jax.vmapandjax.lax.scan. - Creating a Transformer: Shows how to create a Transformer with an auto-regressive decoder that uses scan over layers and a kv-cache for fast inference. Credits to @levskaya.
FAQs
Status
NNX is still in early development so expect bugs and breaking changes. That said, current API is the result of months of experimentation and we don't expect any major changes in the near future.
How is it different from Flax?
NNX takes the best features that allow Flax to scale to large projects and integrates them into a much simpler Module system with pythonic semantics.
One place in which NNX strongly deviates from Flax is that (currently) it avoids shape inference in favor of static initialization. It is not a technical limitation but rather a design choice. This design both simplifies the internal implementation and makes it easier to reason about the code for the user, at the cost of being more verbose at times. On the other hand, Pytorch users will feel right at home.
How is it different from Equinox?
While they might look similar at a surface-level, NNX's Module system is more powerful and flexible than Equinox's, it contains the following additional features:
- Uses regular python classes (no mandatory dataclass behavior).
- Modules are mutable
- Reference sharing between Modules is allowed
- Mutable state lives inside the Module (no need for a separate State container).
- Supports node metadata and semantic partitioning.
One major difference between the two frameworks is that, by design, NNX Modules are not Pytrees. This adds a safety layer as it prevents state updates from being lost by accident due to referential transparency. It also removes the need of threading a separate State container throughout the code in order to propagate state. In NNX state updates are either always preserved or explicitly discarded by the user.
User Guide
Modules
NNX Modules are normal python classes, they obey regular python semantics such as mutability and reference sharing, including reference cycles. They can contain 2 types of attributes: node attributes and static attributes. Node attributes include NNX Variables (e.g. nnx.Param), Numpy arrays, JAX arrays, submodules Modules, and other NNX types. All other types are treated as static attributes.
class Foo(nnx.Module):
def __init__(self, ctx: nnx.Context):
# node attributes
self.variable = nnx.Param(jnp.array(1))
self.np_buffer = np.array(2)
self.jax_buffer = jnp.array(3)
self.node = nnx.Node([4, 5])
self.submodule = nnx.Linear(2, 4, ctx=ctx)
# static attributes
self.int = 1
self.float = 2.0
self.str = "hello"
self.list = [1, 2, 3]
model = Foo(din=12, dout=2, ctx=nnx.context(0))
As shown above, python container types such as list, tuple, and dict are treated as static attributes, if similar functionality is needed, NNX provides the Sequence and Dict Modules.
Functional API
NNX Modules are not pytrees so they cannot be passed to JAX transformations. In order to interact with JAX, a Module must be partitioned into a State and ModuleDef objects. The State object is a flat dictionary-like pytree structure that contains all the deduplicated node attributes, and the ModuleDef contains the static attributes and structural information needed to reconstruct the Module.
state, moduledef = model.partition()
State({
('jax_buffer',): Array(3),
('node',): Node(value=[4, 5]),
('np_buffer',): array(2),
('submodule', 'bias'): Param(value=Array(...)),
('submodule', 'kernel'): Param(value=Array(...)),
('variable',): Param(value=Array(1))
})
State and ModuleDef are pytrees so they can be passed to JAX transformations. More over, ModuleDef provides 2 very important methods: merge and apply. The merge method can be used to create a new Module from a State object:
model = moduledef.merge(state)
This can be use to e.g. recreate a module inside a JAX transformation. The apply provides a functional interface to the module, it can be used call any method or submodule and get the output and the updated state:
# run __call__
y, (state, moduledef) = moduledef.apply(state)(x)
# run some_method
y, (state, moduledef) = moduledef.apply(state).some_method(x)
# run submodule
y, (state, moduledef) = moduledef.apply(state).submodule(x)
apply can call any nested method or submodule as long as it can be accessed via the . or [] operators.
Partitioning State
In NNX you can filter based on any node type, most commonly you will want to filter based on nnx.Variable subclasses such as nnx.Param or nnx.BatchStat.
Here are various examples of how you can use the partition method to split a module into multiple substates:
# partition the module into the state with all the nodes and the moduledef
state, moduledef = model.partition()
# verify that the state contains only params, else raise an error
params, moduledef = model.partition(nnx.Param)
# split the state into params and batch_stats, verify no nodes are left
(params, batch_stats), moduledef = model.partition(nnx.Param, nnx.BatchStat)
# if there are any nodes left, use the `...` filter to capture them
(params, batch_stats, rest), moduledef = model.partition(nnx.Param, nnx.BatchStat, ...)
# using `...` as the only filter is equivalent to not passing any filters
model.partition(...) = model.partition()
partition will make sure all nodes are match by atleast one filter, else it will raise an error. If you have non-Variable nodes like nnx.Node, jax.Array, or numpy.ndarray attributes, you can use the ... filter which will match any node. For a more general filter you can pass a predicate function of the form:
(path: Tuple[str, ...], value: Any) -> bool
To reconstruct the module from a set of substates, you can use merge as usual but passing the substates as additional arguments:
model = moduledef.merge(params, batch_stats, rest)
The same is true for apply.
y, (state, moduledef) = moduledef.apply(params, batch_stats, rest)(x)
Note that apply will return a single state object, if you need to re-partition the state you can use State's own partition method:
params, batch_stats, rest = state.partition(nnx.Param, nnx.BatchStat, ...)
Alternatively, if you are just interested in a subset of partitions, you can use the State.filter method which will not raise an error if some nodes are not matched by any filter:
# only get params
params = state.filter(nnx.Param)
# get params and batch_stats
params, batch_stats = state.filter(nnx.Param, nnx.BatchStat)
Filters
Filters let you select subsets of nodes based on some criteria. These are use throughout the API in method like partition, filter, and pop_state. There are 4 types of filters:
type: matches all node instances of the given type....: matches all nodes.(path, any) -> bool: a predicate function that takes a node path and value and returns a boolean.Tuple[Filter, ...]: a tuple of filters, matches all nodes that match any of the filters.
NNX also provides the following custom filters:
nnx.Not(filter): matches all nodes that do not match the given filternnx.buffers: matches allnumpy.ndarrayandjax.Arraynodes
Here is an example of how to use Not and buffers:
rest = module.filter(nnx.Not(nnx.Param))
buffers = module.filter(nnx.buffers)
Capturing Intermediate Values
In NNX you can easily propagate intemediate values by simply assigning them to an attribute at runtime. For convenience, you should assign them to a Variable attribute with a collection name by using nnx.var so you can easily retrieve them later.
Here is an example of how to create a Linear module that captures its output into a Variable attribute with the intermediates collection name:
class Linear(nnx.Module):
def __init__(self, din: int, dout: int, *, ctx: nnx.Context):
key = ctx.make_rng("params")
self.w = nnx.Param(jax.random.uniform(key, (din, dout)))
self.b = nnx.Param(jnp.zeros((dout,)))
def __call__(self, x):
y = x @ self.w + self.b
self.y = nnx.Intermediate(y)
return y
model = Linear(12, 2, ctx=nnx.context(0))
Since y is only created when the module is called, it is not available upon initialization. However, once you call the module y will be created. It is recommended that you use pop_state to retrieve temporary collections like Intermediate:
y = model(jnp.ones((8, 12)))
intermediates = model.pop_state(nnx.Intermediate)
pop_state will return a State object with the nodes that match the given filter and remove them from the module's attributes.
State({
('y',): Intermediate(
value=Array(...)
)
})
If you use the functional API to call the module instead, the Intermediate nodes will be present in the output state. To retrieve the intermediates nodes and optionally separate them from the output state you can use State.partition:
state, moduledef = model.partition()
y, (state, moduledef) = moduledef.apply(state)(jnp.ones((8, 12)))
# "pop" the intermediates from the state
intermediates, state = state.partition("intermediates", ...)
Alternatively, you can use State.filter to retrieve the intermediates nodes without removing them from the state.
Lifted Transforms
NNX lifted transforms analogous versions of JAX transforms but they know how to work with Modules. They usually perform the following tasks:
- Handle the Module's substates and Context's RNG streams according to the transform's semantics.
- Properly propagating state in and out of the transform, including updating the input Module's state with updates that happen inside the transform.
Here's a diagram illustrating how lifted transformations work:
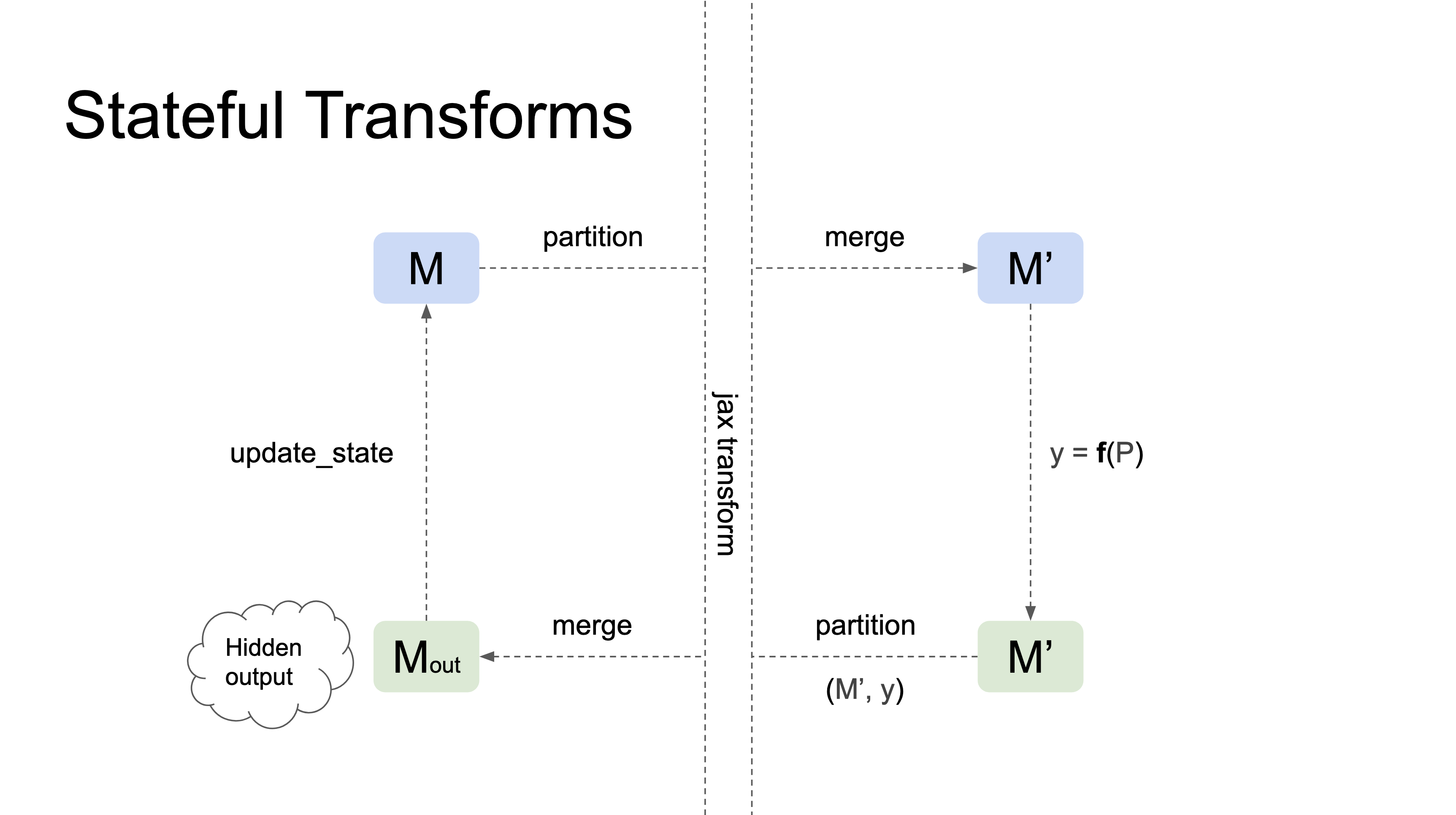
Currently NNX provides the jit, grad, and scan lifted transforms.
Manual Lifting
In case you want to use JAX transforms directly you can always use the functional API to manually lift your Modules.
Here we will create an example of how to implement an MLP that uses "scan over layers" to efficiently process a sequence of inputs assuming that each layer has the same parameters and input/output dimensions. The first thing we need to do is create a Block module that represents a single layer, this block with just contain a Linear layer, a Dropout layer, and a GELU activation function:
class Block(nnx.Module):
def __init__(self, dim: int, *, ctx: nnx.Context):
self.linear = nnx.Linear(dim, dim, ctx=ctx)
self.dropout = nnx.Dropout(0.5)
def __call__(self, x: jax.Array, *, train: bool, ctx: nnx.Context) -> jax.Array:
x = self.linear(x)
x = self.dropout(x, deterministic=not train, ctx=ctx)
x = jax.nn.gelu(x)
return x
Now we will define ScanMLP. During __init__, instead of creating a list of Blocks, we will use jax.vmap to create a single Block whose parameters have an addtional layer axis. This will allow us to pass the parameters as inputs to scan so it will apply a layer at each step.
class ScanMLP(nnx.Module):
def __init__(self, dim: int, *, n_layers: int, ctx: nnx.Context):
params_key = jax.random.split(ctx.make_rng("params"), n_layers)
self.n_layers = n_layers
self.layers = jax.vmap(
lambda key: Block(dim, ctx=nnx.context(params=key)).partition()
)(params_key).merge()
Note that we split the params key into n_layers keys so each layer has different parameters.
Now we will define __call__. Here we need to split the dropout key into n_layers keys so each layer has a different dropout mask, and partition the layers to get their params. Both params and dropout_key will be passed as inputs, x will be the carry value. Inside the scan_fn we will merge the params back into a Block module and
apply it to the input x, passing the sliced dropout_key as part of the Context.
def __call__(self, x: jax.Array, *, train: bool, ctx: nnx.Context) -> jax.Array:
dropout_key = jax.random.split(ctx.make_rng("dropout"), self.n_layers)
params, moduledef = self.layers.partition(nnx.Param)
def scan_fn(x: inputs):
params, dropout_key = inputs
module = moduledef.merge(params)
x = module(x, train=train, ctx=nnx.context(dropout=dropout_key))
return x, module.filter(nnx.Param)
x, params = jax.lax.scan(scan_fn, x, (params, dropout_key))
self.layers.update_state(params)
return x
Finally we apply jax.lax.scan, update the layers state with the new params, and return the final x value.
Here is a simple way to test our ScanMLP:
model = ScanMLP(10, n_layers=5, ctx=nnx.context(0))
x = jnp.ones((3, 10))
y = model(x, train=True, ctx=nnx.context(dropout=1))
For a more robust implementation with comments take a look at the Scan over layers example.
Case Studies
Shared State
In NNX, you can create modules that share state between them. This is useful when designing complex neural network architectures, as it allows you to reuse certain layers and reduce the number of learnable parameters.
Here's an example of creating a module with shared state:
class Block(nnx.Module):
def __init__(self, linear: nnx.Linear, *, ctx: nnx.Context):
self.linear = linear
self.bn = nnx.BatchNorm(2, ctx=ctx)
def __call__(self, x, *, ctx: nnx.Context):
x = self.linear(x)
x = self.bn(x, ctx=ctx)
x = nnx.relu(x)
return x
class Model(nnx.Module):
def __init__(self, *, ctx: nnx.Context):
shared = nnx.Linear(2, 2, ctx=ctx)
self.block1 = Block(shared, ctx=ctx)
self.block2 = Block(shared, ctx=ctx)
def __call__(self, x, *, ctx: nnx.Context):
x = self.block1(x, ctx=ctx)
x = self.block2(x, ctx=ctx)
return x
In this example, the Model module contains two instances of the Block module. Each instance shares the same nnx.Linear module. To run the model, you can use the Context flags argument to set the use_running_average flag for all BatchNorm modules.
Here's an example of computing the loss for a Model instance:
def loss_fn(model: Model, x: jax.Array, y: jax.Array):
ctx = nnx.context(flags=dict(use_running_average=True))
y_pred = model(x, ctx=ctx)
return jnp.mean((y - y_pred) ** 2)
It's important to note that the state for the shared nnx.Linear module will be kept in sync at all times on both Block instances, including during gradient updates.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nnx-0.0.8.tar.gz.
File metadata
- Download URL: nnx-0.0.8.tar.gz
- Upload date:
- Size: 48.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.4.0 CPython/3.9.17 Linux/5.15.0-1041-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4dad51c36053ef73290c83620b373a9cba660ad7721bd4e9a44a9c84524ef7b8
|
|
| MD5 |
7a341640a0d67b15d691d234c6b1436a
|
|
| BLAKE2b-256 |
34f71c4e9661b2081b02947dfc65f3344a29e331208e6ee04fbd5893d92fc6ce
|
File details
Details for the file nnx-0.0.8-py3-none-any.whl.
File metadata
- Download URL: nnx-0.0.8-py3-none-any.whl
- Upload date:
- Size: 49.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.4.0 CPython/3.9.17 Linux/5.15.0-1041-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b140efed7809992b3a38da0a0c70bf90a06d5505ea729f603babffd1e0881e70
|
|
| MD5 |
88407e5dfd4844a215a55a7b91c9a407
|
|
| BLAKE2b-256 |
b4c28889c64b8461d7ab6548f1c25fe5a72c35c97ec4f02767631d2693a64cbb
|







