A framework for developing neural network models for 3D image processing.



Project description
Nobrainer

Nobrainer is a deep learning framework for 3D image processing. It implements several 3D convolutional models from recent literature, methods for loading and augmenting volumetric data that can be used with any TensorFlow or Keras model, losses and metrics for 3D data, and simple utilities for model training, evaluation, prediction, and transfer learning.
Nobrainer also provides pre-trained models for brain extraction, brain segmentation, brain generation and other tasks. Please see the Trained models repository for more information.
The Nobrainer project is supported by NIH RF1MH121885 and is distributed under the Apache 2.0 license. It was started under the support of NIH R01 EB020470.
Table of contents
- Implementations
- Guide Jupyter Notebooks
- Installation
- Using pre-trained networks
- Data augmentation
- Package layout
- Questions or issues
Implementations
Models
| Model | Type | Application |
|---|---|---|
| Highresnet (source) | supervised | segmentation/classification |
| Unet (source) | supervised | segmentation/classification |
| Vnet (source) | supervised | segmentation/classification |
| Meshnet (source) | supervised | segmentation/clssification |
| Bayesian Meshnet (source) | bayesian supervised | segmentation/classification |
| Bayesian Vnet | bayesian supervised | segmentation/classification |
| Semi_Bayesian Vnet | semi-bayesian supervised | segmentation/classification |
| DCGAN | self supervised | generative model |
| Progressive GAN | self supervised | generative model |
| 3D Autoencoder | self supervised | knowledge representation/dimensionality reduction |
| 3D Progressive Autoencoder | self supervised | knowledge representation/dimensionality reduction |
| 3D SimSiam (source) | self supervised | Siamese Representation Learning |
Dropout and regularization layers
Bernouli dropout layer, Concrete dropout layer, Gaussian dropout, Group normalization layer, Costom padding layer
Losses
Dice, Jaccard, Tversky, ELBO, Wasserstien, Gradient Penalty
Metrics
Dice, Generalized Dice, Jaccard, Hamming, Tversky
Augmentation methods
Spatial Transforms
Center crop, Spatial Constant Padding, Random Crop, Resize, Random flip (left and right)
Intensity Transforms
Add gaussian noise, Min-Max intensity scaling, Costom intensity scaling, Intensity masking, Contrast adjustment
Affine Transform
Afifine transformation including rotation, translation, reflection.
Guide Jupyter Notebooks 
Please refer to the Jupyter notebooks in the guide directory to get started with Nobrainer. Try them out in Google Colaboratory!
Installation
Container
We recommend using the official Nobrainer Docker container, which includes all of the dependencies necessary to use the framework. Please see the available images on DockerHub
GPU support
The Nobrainer containers with GPU support use the Tensorflow jupyter GPU containers. Please check the containers for the version of CUDA installed. Nvidia drivers are not included in the container.
$ docker pull neuronets/nobrainer:latest-gpu
$ singularity pull docker://neuronets/nobrainer:latest-gpu
CPU only
This container can be used on all systems that have Docker or Singularity and does not require special hardware. This container, however, should not be used for model training (it will be very slow).
$ docker pull neuronets/nobrainer:latest-cpu
$ singularity pull docker://neuronets/nobrainer:latest-cpu
pip
Nobrainer can also be installed with pip.
$ pip install nobrainer
Using pre-trained networks
Pre-trained networks are available in the Trained models
repository. Prediction can be done on the command-line with nobrainer predict
or in Python. Similarly, generation can be done on the command-line with
nobrainer generate or in Python.
Predicting a brainmask for a T1-weighted brain scan
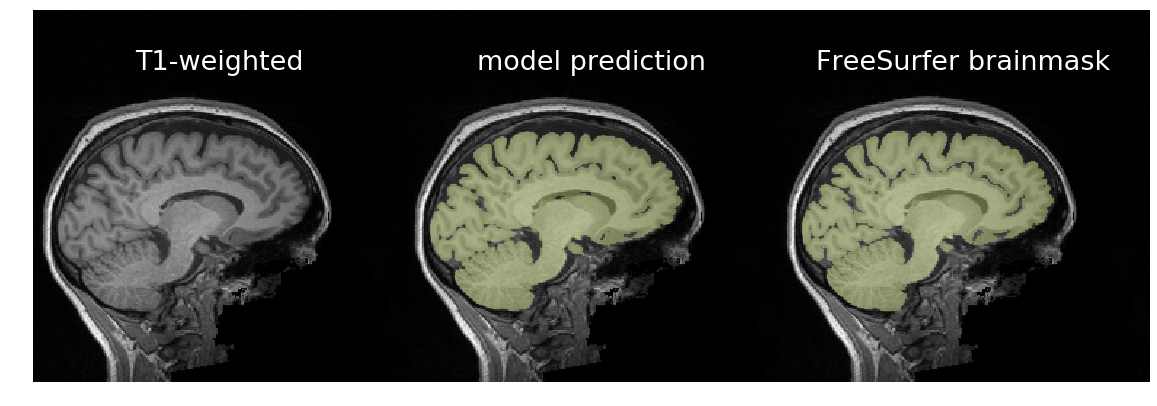
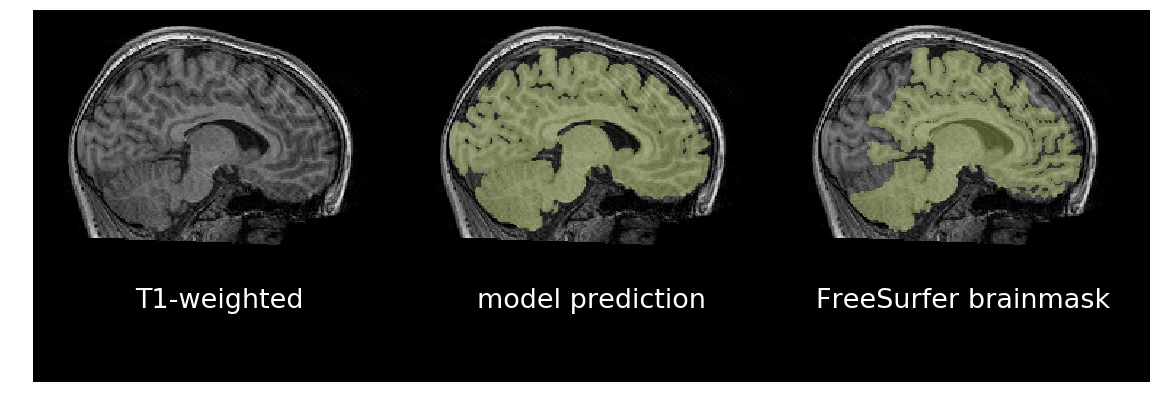
In the following examples, we will use a 3D U-Net trained for brain extraction and documented in Trained models.
In the base case, we run the T1w scan through the model for prediction.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--verbose \
/data/T1w.nii.gz \
/data/brainmask.nii.gz
For binary segmentation where we expect one predicted region, as is the case with brain extraction, we can reduce false positives by removing all predictions not connected to the largest contiguous label.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--largest-label \
--verbose \
/data/T1w.nii.gz \
/data/brainmask-largestlabel.nii.gz
Because the network was trained on randomly rotated data, it should be agnostic
to orientation. Therefore, we can rotate the volume, predict on it, undo the
rotation in the prediction, and average the prediction with that from the original
volume. This can lead to a better overall prediction but will at least double the
processing time. To enable this, use the flag --rotate-and-predict in
nobrainer predict.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--rotate-and-predict \
--verbose \
/data/T1w.nii.gz \
/data/brainmask-withrotation.nii.gz
Combining the above, we can usually achieve the best brain extraction by using
--rotate-and-predict in conjunction with --largest-label.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--largest-label \
--rotate-and-predict \
--verbose \
/data/T1w.nii.gz \
/data/brainmask-maybebest.nii.gz
Generating a synthetic T1-weighted brain scan
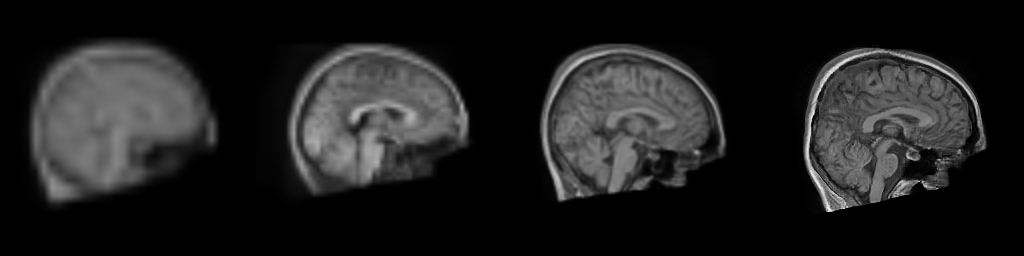
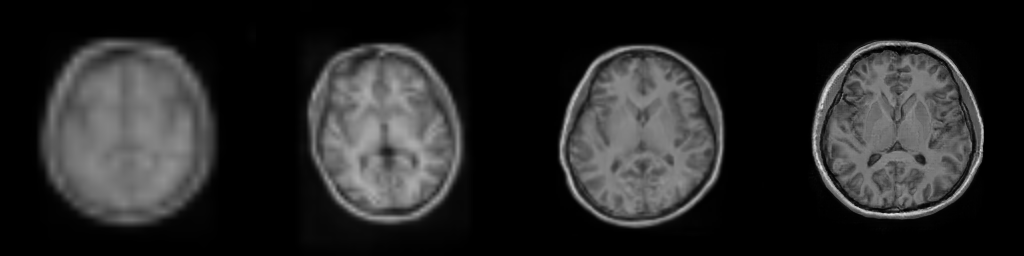
In the following examples, we will use a Progressive Generative Adversarial Network trained for brain image generation and documented in Trained models.
In the base case, we generate a T1w scan through the model for a given resolution.
We need to pass the directory containing the models (tf.SavedModel) created
while training the networks.
docker run --rm -v $PWD:/data neuronets/nobrainer \
generate \
--model=/models/neuronets/braingen/0.1.0 \
--output-shape=128 128 128 \
/data/generated.nii.gz
We can also generate multiple resolutions of the brain image using the same latents to visualize the progression
# Get sample T1w scan.
docker run --rm -v $PWD:/data neuronets/nobrainer \
generate \
--model=/models/neuronets/braingen/0.1.0 \
--multi-resolution \
/data/generated.nii.gz
In the above example, the multi resolution images will be saved as
generated_res_{resolution}.nii.gz
Transfer learning
The pre-trained models can be used for transfer learning. To avoid forgetting important information in the pre-trained model, you can apply regularization to the kernel weights and also use a low learning rate. For more information, please see the Nobrainer guide notebook on transfer learning.
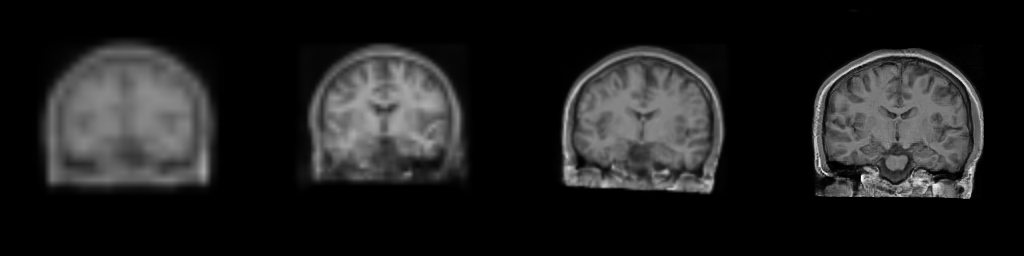
As an example of transfer learning, @kaczmarj re-trained a brain extraction model to label meningiomas in 3D T1-weighted, contrast-enhanced MR scans. The original model is publicly available and was trained on 10,000 T1-weighted MR brain scans from healthy participants. These were all research scans (i.e., non-clinical) and did not include any contrast agents. The meningioma dataset, on the other hand, was composed of relatively few scans, all of which were clinical and used gadolinium as a contrast agent. You can observe the differences in contrast below.
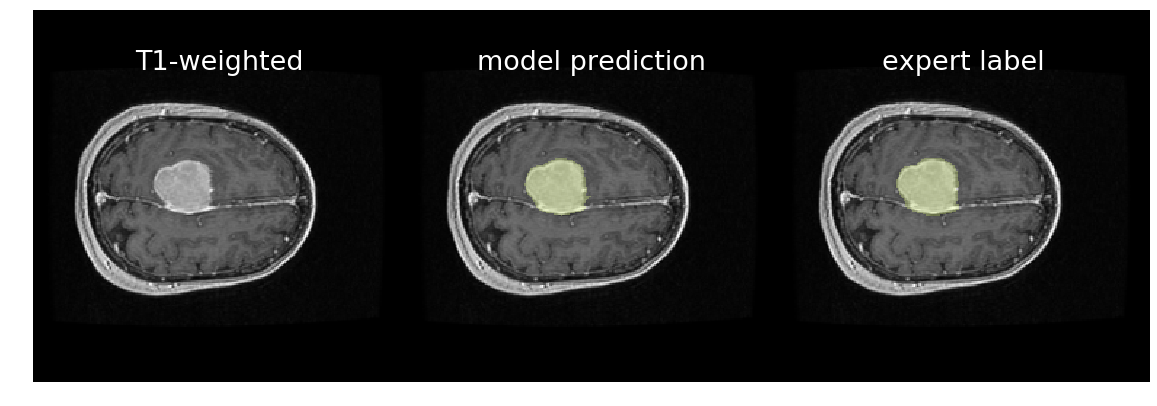
Despite the differences between the two datasets, transfer learning led to a much better model than training from randomly-initialized weights. As evidence, please see below violin plots of Dice coefficients on a validation set. In the left plot are Dice coefficients of predictions obtained with the model trained from randomly-initialized weights, and on the right are Dice coefficients of predictions obtained with the transfer-learned model. In general, Dice coefficients are higher on the right, and the variance of Dice scores is lower. Overall, the model on the right is more accurate and more robust than the one on the left.
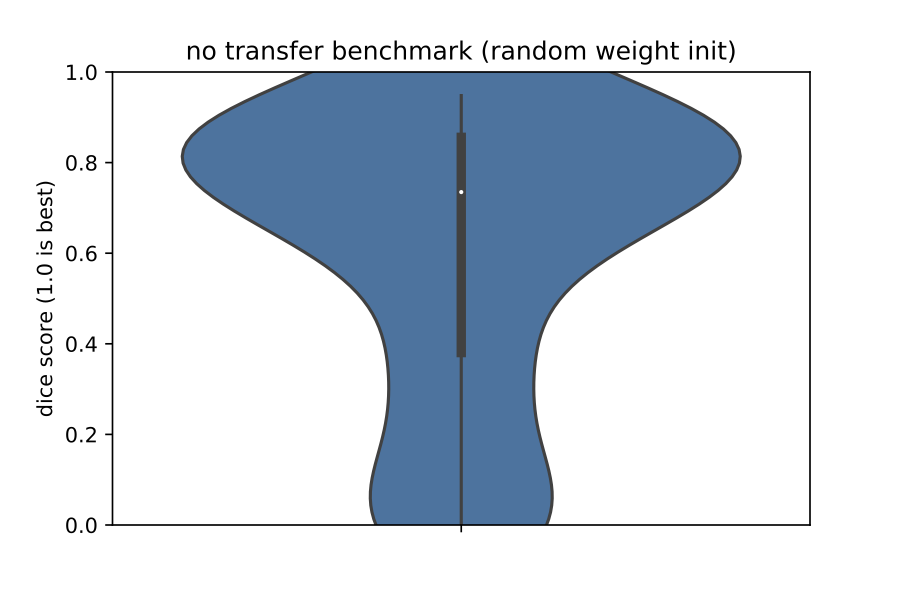
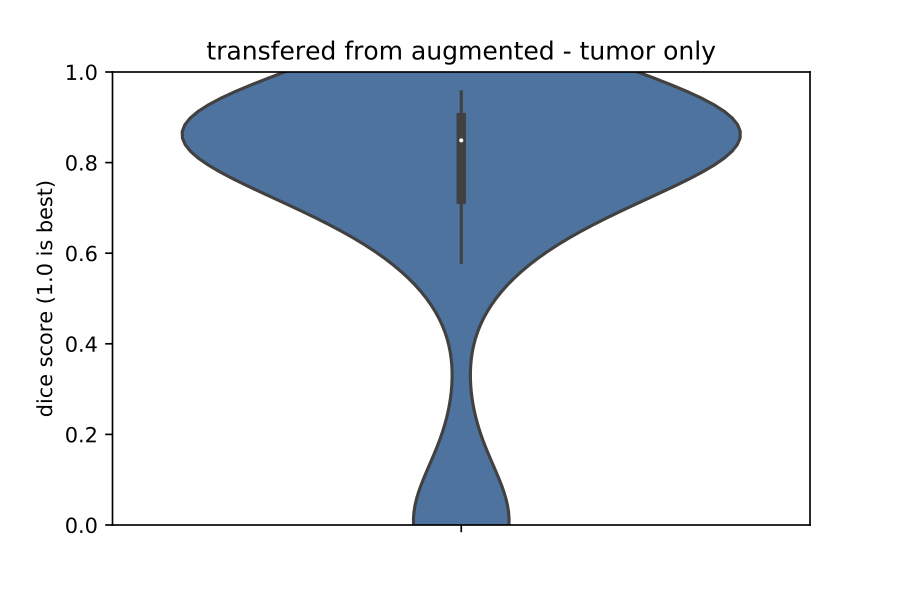
Package layout
nobrainer.io: input/output methodsnobrainer.layers: custom layers, which conform to the Keras APInobrainer.losses: loss functions for volumetric segmentationnobrainer.metrics: metrics for volumetric segmentationnobrainer.models: pre-defined Keras modelsnobrainer.training: training utilities (supports training on single and multiple GPUs)nobrainer.transform: random rigid transformations for data augmentationnobrainer.volume:tf.data.Datasetcreation and data augmentation utilities
Citation
If you use this package, please cite it.
Questions or issues
If you have questions about Nobrainer or encounter any issues using the framework, please submit a GitHub issue.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nobrainer-1.2.1.tar.gz.
File metadata
- Download URL: nobrainer-1.2.1.tar.gz
- Upload date:
- Size: 127.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fbad00b459733ff86ef75dd46b603336183e4cbfeb13248a41db251bb3b3b11f
|
|
| MD5 |
464a7eb1216e2368a129f17f97e9b6a7
|
|
| BLAKE2b-256 |
fd6e602906691c7f12cdd822cf2d6de53f94726ed3f7b1015667e7a60d6c18ab
|
File details
Details for the file nobrainer-1.2.1-py3-none-any.whl.
File metadata
- Download URL: nobrainer-1.2.1-py3-none-any.whl
- Upload date:
- Size: 127.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d31759dcddce43fcefa3edb878db6c49a9e957ab97864d51a0bf74d6e630d283
|
|
| MD5 |
d9ef7b0804dfcd0bfe865af44b6c26c1
|
|
| BLAKE2b-256 |
f4bd9ef30516e4c58c1e2e3070661bd14f6c92c1c01e518170b45d0c5bdda1e8
|







