Build reactive back end with ease

Project description
onto



"boiler": Backend-Originated Instantly-Loaded Entity Repository
NOTE: This package is not profiled or checked for memory usage. It is recommended that you use Kubernetes to increase fault tolerance.
Flask-boiler manages your application state with Firestore. You can create view models that aggregates underlying data sources and store them immediately and permanently in Firestore. As a result, your front end development will be as easy as using Firestore. Flask-boiler is comparable to Spring Web Reactive.
Demo:
When you change the attendance status of one of the participants in the meeting, all other participants receive an updated version of the list of people attending the meeting.
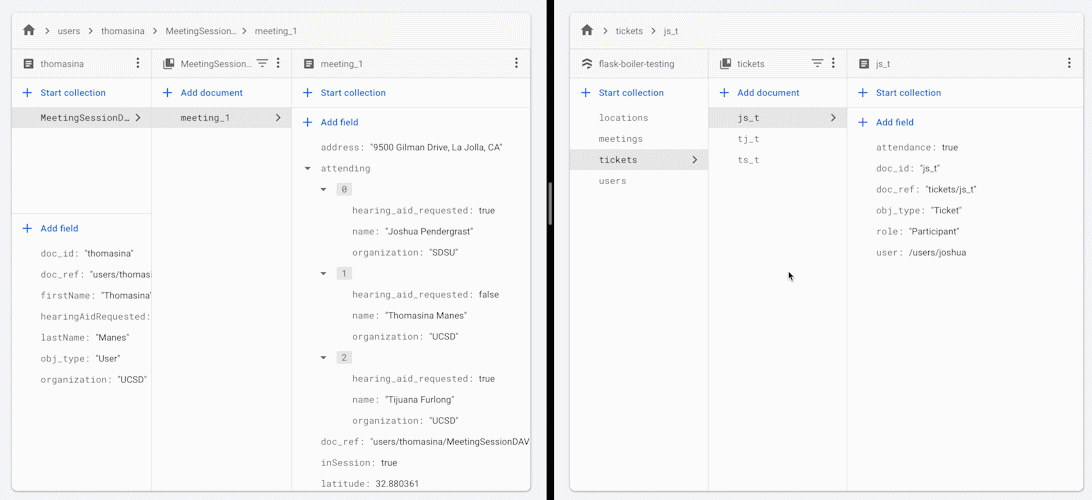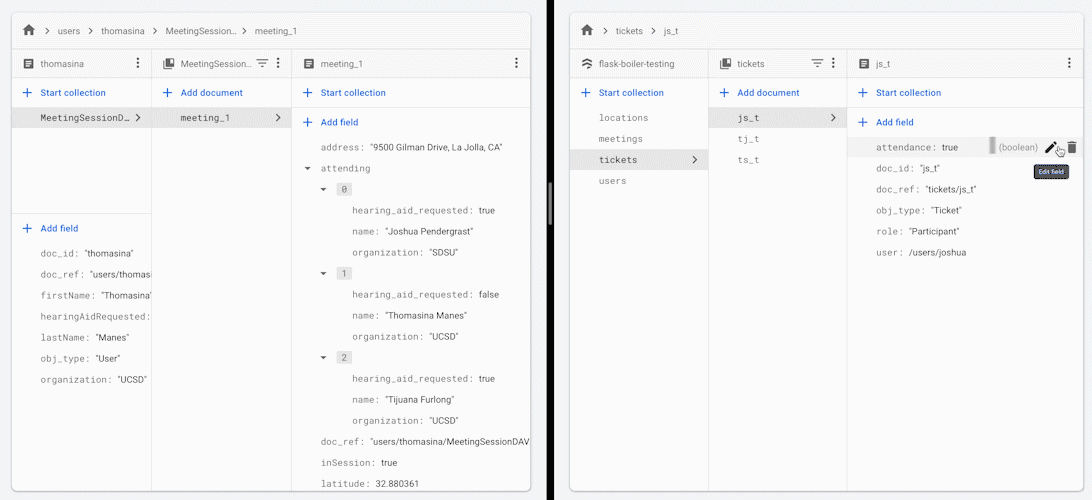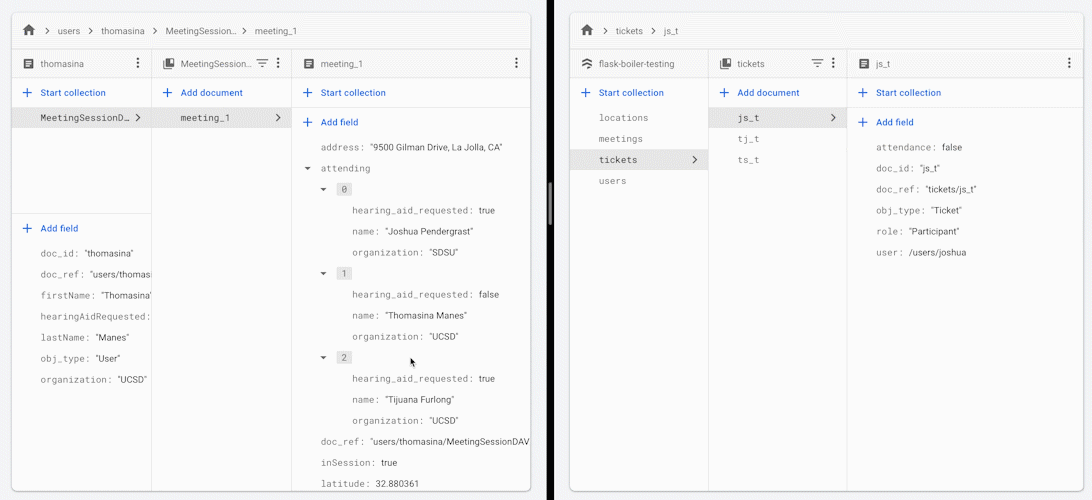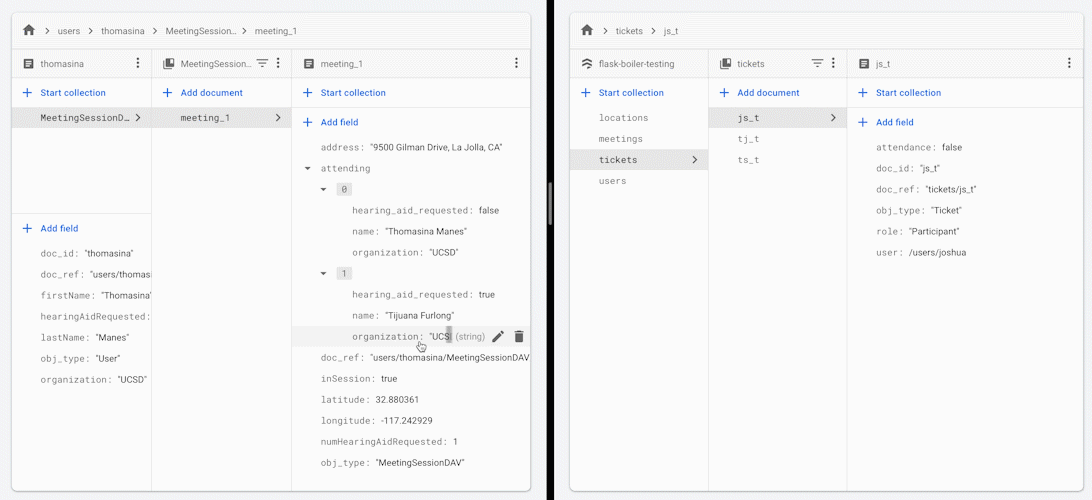
Some reasons that you may want to use this framework or architectual practice:
- You want to build a reactive system and not just a reactive view.
- You want to build a scalable app that is native to distributed systems.
- You want a framework with a higher level of abstraction, so you can exchange components such as transportation protocols
- You want your code to be readable and clear and written mostly in python, while maintaining compatibility to different APIs.
- You have constantly-shifting requirements, and want to have the flexibility to migrate different layers, for example, switch from REST API to WebSocket to serve a resource.
This framework is at beta testing stage. API is not guaranteed and may change.
Documentations: readthedocs
Quickstart: Quickstart
API Documentations: API Docs
Example of a Project using flask-boiler: gravitate-backend
Ideal Usage
boiler will compile your python code into flink jobs, web servers, and more to be run on a kubernetes engine (not currently implemented).

Connectors supported
Implemented:
- REST API (Flask and Flasgger)
- GraphQL (Starlette)
- Firestore
- Firebase Functions
- JsonRPC (flask-jsonrpc)
- Leancloud Engine
- WebSocket (flask socketio)
To be supported:
- Flink Table API
- Kafka
Design Pattern
onto abstracts to MVVM (Model-View-ViewModel), where,
- Model consists of a transactional database or datastore, and lives in back end.
- ViewModel consists of a distributed state consists of Model and aggregator. It is the main part of boiler. For client-read, it receives the streams coming in from the Model layer, and output them as a View to the View layer. For client-write, it receives the change streams from View layer, and operate on Model layer to persist the change. ViewModel lives in the back end, and may be operated as boiler python code, or compiled as flink jobs in the case of big data application (to be implemented).
- View is the presentational layer for the back end. It serves
1NF normalized data that are readable to the front end
without further aggregation. Client reads and writes to View.
View should be ephemeral, and can be rebuilt from ViewModel.
View may be a remote system, eg. firestore or leancloud.
Installation
In your project directory,
pip install onto
See more in Quickstart.
State Management
You can combine information gathered in domain models and serve them in Firestore, so that front end can read all data required from a single document or collection, without client-side queries and excessive server roundtrip time.
There is a medium article that explains a similar architecture called "reSolve" architecture.
See examples/meeting_room/view_models on how to use onto
to expose a "view model" in firestore that can be queried directly
by front end without aggregation.
Processor Modes
onto is essentially a framework for source-sink operations:
Source(s) -> Processor -> Sink(s)
Take query as an example,
- Boiler
- NoSQL
- Flink
- staticmethods: converts to UDF
- classmethods: converts to operators and aggregator's
Declare View Model
class CityView(ViewModel):
name = attrs.bproperty()
country = attrs.bproperty()
@classmethod
def new(cls, snapshot):
store = CityStore()
store.add_snapshot("city", dm_cls=City, snapshot=snapshot)
store.refresh()
return cls(store=store)
@name.getter
def name(self):
return self.store.city.city_name
@country.getter
def country(self):
return self.store.city.country
@property
def doc_ref(self):
return CTX.db.document(f"cityView/{self.store.city.doc_id}")
Document View
class MeetingSessionGet(Mediator):
from onto import source, sink
source = source.domain_model(Meeting)
sink = sink.firestore() # TODO: check variable resolution order
@source.triggers.on_update
@source.triggers.on_create
def materialize_meeting_session(self, obj):
meeting = obj
assert isinstance(meeting, Meeting)
def notify(obj):
for ref in obj._view_refs:
self.sink.emit(reference=ref, snapshot=obj.to_snapshot())
_ = MeetingSession.get(
doc_id=meeting.doc_id,
once=False,
f_notify=notify
)
# mediator.notify(obj=obj)
@classmethod
def start(cls):
cls.source.start()
WebSocket View
class Demo(WsMediator):
pass
mediator = Demo(view_model_cls=rainbow_vm,
mutation_cls=None,
namespace="/palette")
io = flask_socketio.SocketIO(app=app)
io.on_namespace(mediator)
Create Flask View
You can use a RestMediator to create a REST API. OpenAPI3 docs will be
automatically generated in <site_url>/apidocs when you run _ = Swagger(app).
app = Flask(__name__)
class MeetingSessionRest(Mediator):
# from onto import source, sink
view_model_cls = MeetingSessionC
rest = RestViewModelSource()
@rest.route('/<doc_id>', methods=('GET',))
def materialize_meeting_session(self, doc_id):
meeting = Meeting.get(doc_id=doc_id)
def notify(obj):
d = obj.to_snapshot().to_dict()
content = jsonify(d)
self.rest.emit(content)
_ = MeetingSessionC.get(
doc_id=meeting.doc_id,
once=False,
f_notify=notify
)
# @rest.route('/', methods=('GET',))
# def list_meeting_ids(self):
# return [meeting.to_snapshot().to_dict() for meeting in Meeting.all()]
@classmethod
def start(cls, app):
cls.rest.start(app)
swagger = Swagger(app)
app.run(debug=True)
(currently under implementation)
Object Lifecycle
Once
Object created with cls.new ->
Object exported with obj.to_view_dict.
Multi
Object created when a new domain model is created in database ->
Object changed when underlying datasource changes ->
Object calls self.notify
Typical ViewMediator Use Cases
Data flow direction is described as Source -> Sink. "Read" describes the flow of data where front end would find data in Sink useful. "Write" describes the flow of data where the Sink is the single source of truth.
Rest
Read: Request -> Response
Write: Request -> Document
- Front end sends HTTP request to Server
- Server queries datastore
- Server returns response
Query
Read: Document -> Document
Write: Document -> Document
- Datastore triggers update function
- Server rebuilds ViewModel that may be changed as a result
- Server saves newly built ViewModel to datastore
Query+Task
Read: Document -> Document
Write: Document -> Document
- Datastore triggers update function for document
dat timet - Server starts a transaction
- Server sets write_option to only allow commit if documents are last updated at time
t(still under design) - Server builds ViewModel with transaction
- Server saves ViewModel with transaction
- Server marks document
das processed (remove document or update a field) - Server retries up to MAX_RETRIES from step 2 if precondition failed
WebSocket
Read: Document -> WebSocket Event
Write: WebSocket Event -> Document
- Front end subscribes to a ViewModel by sending a WebSocket event to server
- Server attaches listener to the result of the query
- Every time the result of the query is changed and consistent:
- Server rebuilds ViewModel that may be changed as a result
- Server publishes newly built ViewModel
- Front end ends the session
- Document listeners are released
Document
Read: Document -> Document
Write: Document -> Document
Comparisons
| Rest | Query | Query+Task | WebSocket | Document | |
|---|---|---|---|---|---|
| Guarantees | ≤1 (At-Most-Once) | ≥ 1 (At-Least-Once) | =1[^1] (Exactly-Once) | ≤1 (At-Most-Once) | ≥ 1 (At-Least-Once) |
| Idempotence | If Implemented | No | Yes, with transaction[^1] | If Implemented | No |
| Designed For | Stateless Lambda | Stateful Container | Stateless Lambda | Stateless Lambda | Stateful Container |
| Latency | Higher | Higher | Higher | Lower | Higher |
| Throughput | Higher when Scaled | Lower[^2] | Lower | Higher when Scaled | Lower[^2] |
| Stateful | No | If Implemented | If Implemented | Yes | Yes |
| Reactive | No | Yes | Yes | Yes | Yes |
[^1]: A message may be received and processed by multiple consumer, but only one consumer can successfully commit change and mark the event as processed. [^2]: Scalability is limited by the number of listeners you can attach to the datastore.
Advantages
Decoupled Domain Model and View Model
Using Firebase Firestore sometimes require duplicated fields across several documents in order to both query the data and display them properly in front end. Flask-boiler solves this problem by decoupling domain model and view model. View model are generated and refreshed automatically as domain model changes. This means that you will only have to write business logics on the domain model without worrying about how the data will be displayed. This also means that the View Models can be displayed directly in front end, while supporting real-time features of Firebase Firestore.
One-step Configuration
Rather than configuring the network and different certificate settings for your database and other cloud services. All you have to do is to enable related services on Google Cloud Console, and add your certificate. Flask-boiler configures all the services you need, and expose them as a singleton Context object across the project.
Redundancy
Since all View Models are persisted in Firebase Firestore. Even if your App Instance is offline, the users can still access a view of the data from Firebase Firestore. Every View is also a Flask View, so you can also access the data with auto-generated REST API, in case Firebase Firestore is not viable.
Added Safety
By separating business data from documents that are accessible to the front end, you have more control over which data is displayed depending on the user's role.
One-step Documentation
All ViewModels have automatically generated documentations (provided by Flasgger). This helps AGILE teams keep their documentations and actual code in sync.
Fully-extendable
When you need better performance or relational database
support, you can always refactor a specific layer by
adding modules such as flask-sqlalchemy.
Comparisons
GraphQL
In GraphQL, the fields are evaluated with each query, but onto evaluates the fields if and only if the underlying data source changes. This leads to faster read for data that has not changed for a while. Also, the data source is expected to be consistent, as the field evaluation are triggered after all changes made in one transaction to firestore is read.
GraphQL, however, lets front-end customize the return. You must define the exact structure you want to return in onto. This nevertheless has its advantage as most documentations of the request and response can be done the same way as REST API.
REST API / Flask
REST API does not cache or store the response. When a view model is evaluated by onto, the response is stored in firestore forever until update or manual removal.
Flask-boiler controls role-based access with security rules integrated with Firestore. REST API usually controls these access with a JWT token.
Redux
Redux is implemented mostly in front end. Flask-boiler targets back end and is more scalable, since all data are communicated with Firestore, a infinitely scalable NoSQL datastore.
Flask-boiler is declarative, and Redux is imperative. The design pattern of REDUX requires you to write functional programming in domain models, but onto favors a different approach: ViewModel reads and calculates data from domain models and exposes the attribute as a property getter. (When writing to DomainModel, the view model changes domain model and exposes the operation as a property setter). Nevertheless, you can still add function callbacks that are triggered after a domain model is updated, but this may introduce concurrency issues and is not perfectly supported due to the design tradeoff in onto.
Architecture Diagram:
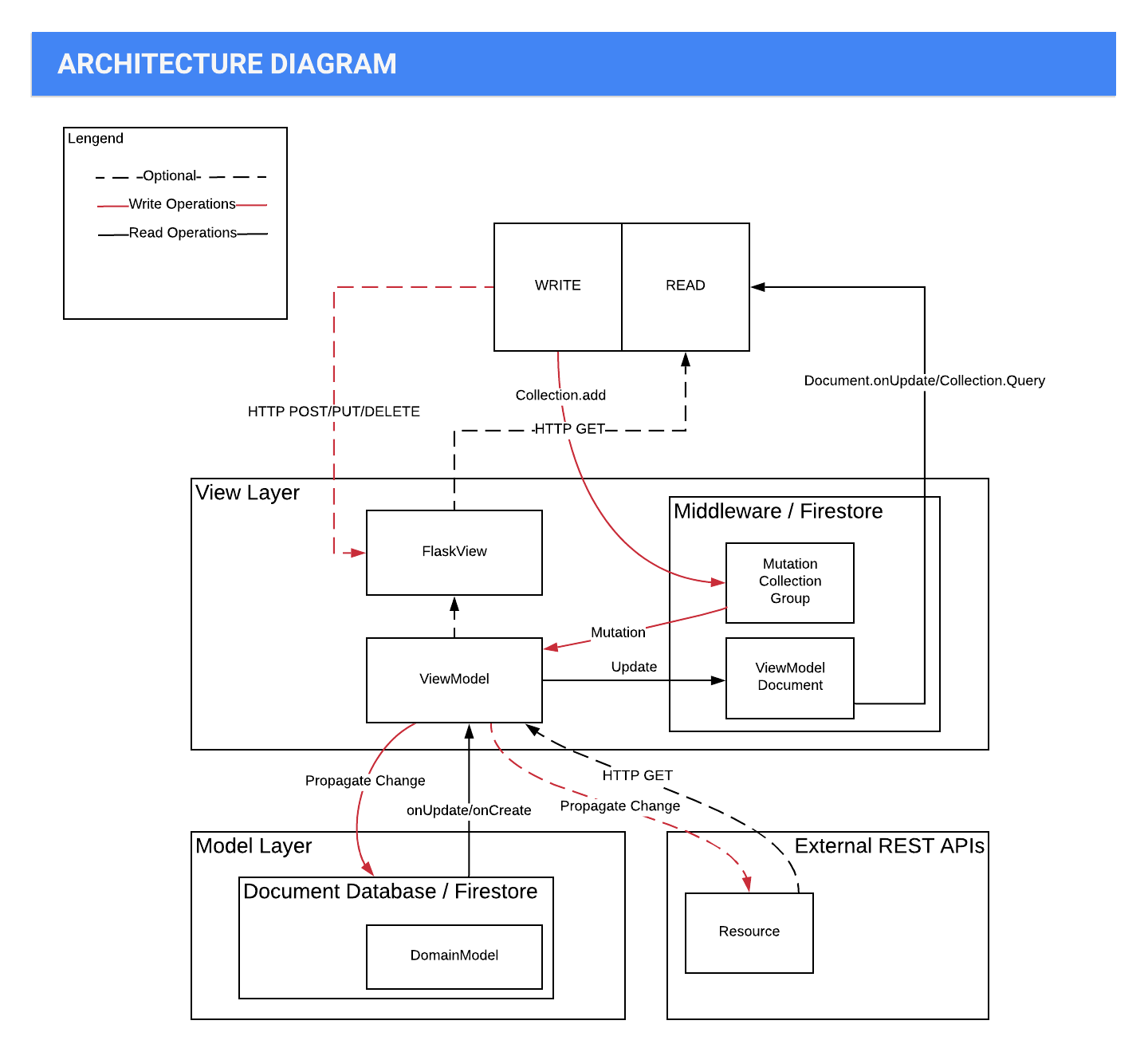
Contributing
Pull requests are welcome.
Please make sure to update tests as appropriate.
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file onto-0.0.1.tar.gz.
File metadata
- Download URL: onto-0.0.1.tar.gz
- Upload date:
- Size: 148.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/46.0.0 requests-toolbelt/0.9.1 tqdm/4.49.0 CPython/3.8.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b34376e682d126ec1b8ffe44b73769d3399a487ad1ea37559be5fca99920a302
|
|
| MD5 |
279e76ba72f24daa2023687ce48039e3
|
|
| BLAKE2b-256 |
947ce092ced8fd0d0f36fb65c72ef38eb1a2ba205e9cf8a305bb5fb5b8fbbc22
|







