A library for working with data submitted to the PDI.

Project description
OpenPDI 



OpenPDI is an unofficial effort to document and standardize data submitted to the Police Data Initiative (PDI). The goal is to make the data more accessible by addressing a number of issues related to a lack of standardization—namely,
- File types: While some agencies make use if the
Socrata Open Data API, many provide their data
in raw
.csv,.xlsx, or.xlsfiles of varying structures. - Column names: Many columns that represent the same data (e.g., the race police officer) are named differently across departments, cities, and states.
- Value formats: Dates, times, and other comparable fields are submitted in many different formats.
- Column availability: It's currently very difficult to identify data sources that contain certain columns—e.g., Use of Force data specifying the hire date of the involved officer(s).
Getting Started
Installation
$ pip install openpdi
Usage
| Dataset | ID | Source |
|---|---|---|
| Use of Force | uof |
https://www.policedatainitiative.org/datasets/use-of-force/ |
import csv
import openpdi
# The library has a single entry point:
dataset = openpdi.Dataset(
# The dataset ID (see the table above).
"uof",
# Limit the data sources to a specific state using its two-letter code.
#
# Default: `scope=[]`.
scope=["TX"],
# A list of columns that must be provided in every data source included in
# this dataset. See `openpdi/meta/{ID}/schema.json` for the available
# columns.
#
# Default: `columns=[]`.
columns=["reason"],
# If `True`, only return the user-specified columns -- i.e., those listed
# in the `columns` parameter.
#
# Default: `strict=False`.
strict=False)
# The names of the agencies included in this dataset:
print(dataset.agencies)
# The URLs of the external data sources inlcuded in this dataset:
print(dataset.sources)
# `gen` is a generator object for iterating over the CSV-formatted dataset.
gen = dataset.download()
# Write to a CSV file:
with open("dataset.csv", "w+") as f:
writer = csv.writer(f, delimiter=",", quoting=csv.QUOTE_ALL)
writer.writerows(gen)
Datasets
In an attempt to avoid unnecessary bloat (in terms of GBs), we don't actually store any PDI data in this repository. Instead, we store small, JSON-formatted descriptions of externally hosted datasets—for example, uof/CA/meta.json:
[
{
"url": "https://www.norwichct.org/Archive.aspx?AMID=61&Type=Recent",
"type": "csv",
"start": 1,
"columns": {
"date": {
"index": 0,
"specifier": "%m/%d/%Y"
},
"city": {
"raw": "Richmond"
},
"state": {
"raw": "CA"
},
"service_type": {
"index": 1
},
"force_type": {
"index": 10
},
"light_conditions": {
"index": 8
},
"weather_conditions": {
"index": 7
},
"reason": {
"index": 2
},
"officer_injured": {
"index": 6
},
"officer_race": {
"index": 9
},
"subject_injured": {
"index": 5
},
"aggravating_factors": {
"index": 3
},
"arrested": {
"index": 4
}
}
}
]
This file describes a Use of Force (uof) dataset from Richmond, CA. Each entry in the columns array maps a column from the externally-hosted data to a column in the dataset's schema file (uof/schema.json).
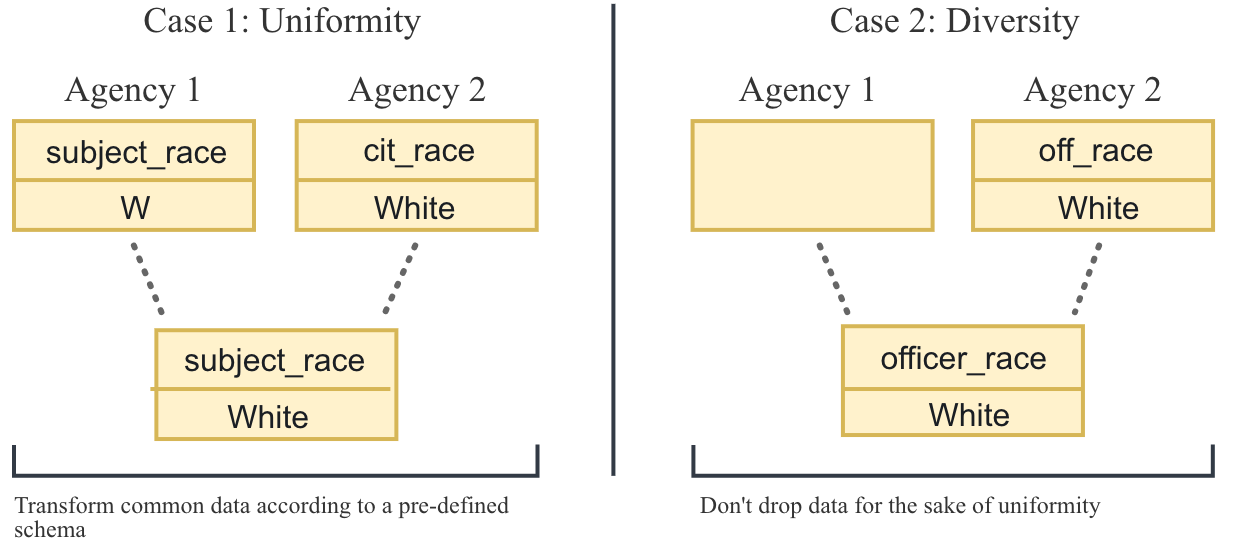
The schema.json file assigns a format to every possible column in a particular dataset, which is a Python function tasked with standardizing a raw column value (see openpdi/validators.py).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file openpdi-0.2.4.tar.gz.
File metadata
- Download URL: openpdi-0.2.4.tar.gz
- Upload date:
- Size: 14.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/47.3.1 requests-toolbelt/0.9.1 tqdm/4.47.0 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5f35e990ad228fe45fac1dca8b79c070265f63703b3d4ae07f44894402c541a2
|
|
| MD5 |
4c8396c5b5612498c58f0d10f88f3c32
|
|
| BLAKE2b-256 |
231479f8ed49b80a8ea3322e3e1ffbe1e5b887b557c09d57aa88f573e8ddfc83
|
File details
Details for the file openpdi-0.2.4-py2.py3-none-any.whl.
File metadata
- Download URL: openpdi-0.2.4-py2.py3-none-any.whl
- Upload date:
- Size: 18.7 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/47.3.1 requests-toolbelt/0.9.1 tqdm/4.47.0 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
273a4a3ea39e450a86f27856cea010535403ea351bd1d50a4f2ae62182a23b31
|
|
| MD5 |
d832ab2352c4f780b6842cc844932a9c
|
|
| BLAKE2b-256 |
f57659c1202c1cf5c795ae5abf179f2ccdfaf30af5f89d654555a5a2085fdb44
|







