A question solver plugin for OVOS

Project description

BM25 OpenVoiceOS Plugin
An OVOS (OpenVoiceOS) plugin designed to retrieve answers from a corpus of documents using the BM25 algorithm.
This plugin provides a lightweight baseline for various tasks (reranking, summarization, machine comprehension, retrieval)
ReRanking
ReRanking is a technique used to refine a list of potential answers by evaluating their relevance to a given query. This process is crucial in scenarios where multiple options or responses need to be assessed to determine the most appropriate one.
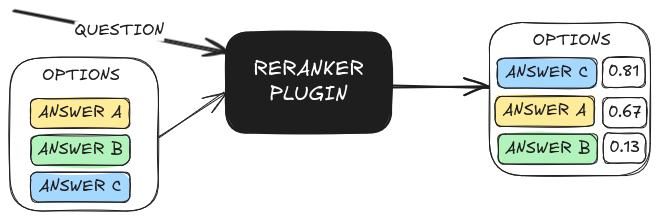
The solver ranks these options based on their similarity to the query itself and selects the most suitable one.
from ovos_bm25_solver import BM25MultipleChoiceSolver
solver = BM25MultipleChoiceSolver()
a = solver.rerank("what is the speed of light", [
"very fast", "10m/s", "the speed of light is C"
])
print(a)
# 2024-07-22 15:03:10.295 - OVOS - __main__:load_corpus:61 - DEBUG - indexed 3 documents
# 2024-07-22 15:03:10.297 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 1 (score: 0.7198746800422668): the speed of light is C
# 2024-07-22 15:03:10.297 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 2 (score: 0.0): 10m/s
# 2024-07-22 15:03:10.297 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 3 (score: 0.0): very fast
# [(0.7198747, 'the speed of light is C'), (0.0, '10m/s'), (0.0, 'very fast')]
# NOTE: select_answer is part of the MultipleChoiceSolver base class and uses rerank internally
a = solver.select_answer("what is the speed of light", [
"very fast", "10m/s", "the speed of light is C"
])
print(a) # the speed of light is C
Machine Comprehension
In text extraction and machine comprehension tasks, BM25EvidenceSolverPlugin enables the identification of specific sentences within a larger body of text that directly address a user's query.
For example, in a scenario where a user queries about the number of rovers exploring Mars, BM25EvidenceSolverPlugin scans the provided text passage, ranks sentences based on their relevance, and extracts the most informative sentence.
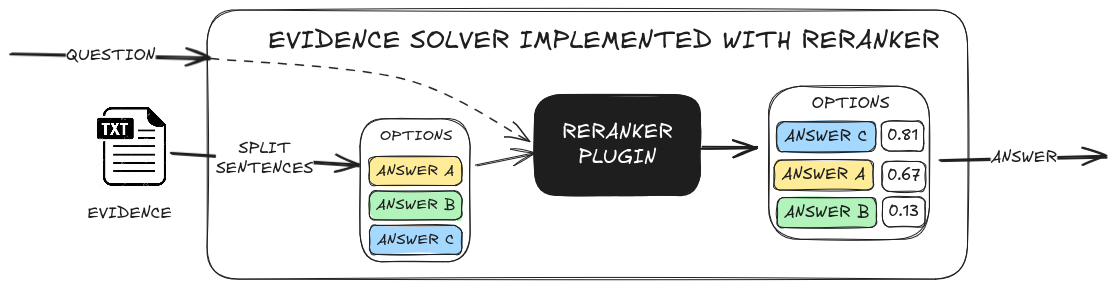
from ovos_bm25_solver import BM25EvidenceSolverPlugin
config = {
"lang": "en-us",
"min_conf": 0.4,
"n_answer": 1
}
solver = BM25EvidenceSolverPlugin(config)
text = """Mars is the fourth planet from the Sun. It is a dusty, cold, desert world with a very thin atmosphere.
Mars is also a dynamic planet with seasons, polar ice caps, canyons, extinct volcanoes, and evidence that it was even more active in the past.
Mars is one of the most explored bodies in our solar system, and it's the only planet where we've sent rovers to roam the alien landscape.
NASA currently has two rovers (Curiosity and Perseverance), one lander (InSight), and one helicopter (Ingenuity) exploring the surface of Mars.
"""
query = "how many rovers are currently exploring Mars"
answer = solver.get_best_passage(evidence=text, question=query)
print("Query:", query)
print("Answer:", answer)
# 2024-07-22 15:05:14.209 - OVOS - __main__:load_corpus:61 - DEBUG - indexed 5 documents
# 2024-07-22 15:05:14.209 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 1 (score: 1.39238703250885): NASA currently has two rovers (Curiosity and Perseverance), one lander (InSight), and one helicopter (Ingenuity) exploring the surface of Mars.
# 2024-07-22 15:05:14.210 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 2 (score: 0.38667747378349304): Mars is one of the most explored bodies in our solar system, and it's the only planet where we've sent rovers to roam the alien landscape.
# 2024-07-22 15:05:14.210 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 3 (score: 0.15732118487358093): Mars is the fourth planet from the Sun.
# 2024-07-22 15:05:14.210 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 4 (score: 0.10177625715732574): Mars is also a dynamic planet with seasons, polar ice caps, canyons, extinct volcanoes, and evidence that it was even more active in the past.
# 2024-07-22 15:05:14.210 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 5 (score: 0.0): It is a dusty, cold, desert world with a very thin atmosphere.
# Query: how many rovers are currently exploring Mars
# Answer: NASA currently has two rovers (Curiosity and Perseverance), one lander (InSight), and one helicopter (Ingenuity) exploring the surface of Mars.
In this example, BM25EvidenceSolverPlugin effectively identifies and retrieves the most relevant sentence from the
provided text that answers the query about the number of rovers exploring Mars.
This capability is essential for applications requiring information extraction from extensive textual content, such as
automated research assistants or content summarizers.
Summarizer
The BM25SummarizerPlugin performs extractive summarization by ranking and returning the most relevant sentences from the text, effectively generating a concise overview.
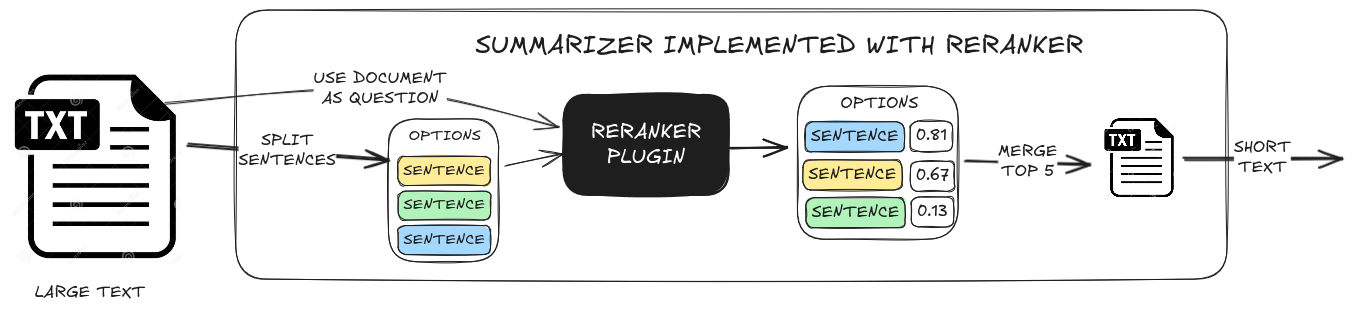
from ovos_bm25_solver import BM25SummarizerPlugin
solver = BM25SummarizerPlugin()
# Load a large text corpus, e.g., a documentation file
with open("../ovos-technical-manual/docs/150-personas.md") as f:
big_text = f.read()
# Get the summary
summary = solver.tldr(big_text, lang="en")
print(summary)
# | Component | Role |
# |----------------------|--------------------------------------------------------------|
# | **Solver Plugin** | Stateless text-to-text inference (e.g., Q&A, summarization). |
# | **Persona** | Named agent composed of ordered solver plugins. |
# | **Persona Server** | Expose personas to other Ollama/OpenAI compatible projects. |
# | **Persona Pipeline** | Handles persona activation and routing inside OVOS core. |
#
# Within `ovos-core`, the **[persona-pipeline](https://github.com/OpenVoiceOS/ovos-persona)** plugin handles all runtime logic for managing user interaction with AI agents.
#
# ### Key Features:
# - **Composition**: Each persona consists of a name, a list of solver plugins, and optional configuration for each.
# - **Chained Execution**: When a user question is received, the persona tries solvers one by one. If the first solver fails (returns `None`), the next one is tried until a response is generated.
# - **Customizable Behavior**: Different personas can emulate different personalities or knowledge domains by varying their solver stack.
Retrieval Chatbots (Custom Knowledge Base)
Retrieval chatbots use BM25CorpusSolver to provide answers to user queries by searching through a preloaded corpus of documents or QA pairs.
This package is meant to be used to create your own solvers with a dedicated corpus.
Using BM25CorpusSolver
To use the BM25CorpusSolver, you need to create an instance of the solver, load your corpus, and then query it.
from ovos_bm25_solver import BM25CorpusSolver
config = {
"lang": "en-us",
"min_conf": 0.4,
"n_answer": 2
}
solver = BM25CorpusSolver(config)
corpus = [
"a cat is a feline and likes to purr",
"a dog is the human's best friend and loves to play",
"a bird is a beautiful animal that can fly",
"a fish is a creature that lives in water and swims",
]
solver.load_corpus(corpus)
query = "does the fish purr like a cat?"
answer = solver.get_spoken_answer(query)
print(answer)
# Expected Output:
# 2024-07-19 20:03:29.979 - OVOS - ovos_plugin_manager.utils.config:get_plugin_config:40 - DEBUG - Loaded configuration: {'module': 'ovos-translate-plugin-server', 'lang': 'en-us'}
# 2024-07-19 20:03:30.024 - OVOS - __main__:load_corpus:28 - DEBUG - indexed 4 documents
# 2024-07-19 20:03:30.025 - OVOS - __main__:retrieve_from_corpus:37 - DEBUG - Rank 1 (score: 1.0584375858306885): a cat is a feline and likes to purr
# 2024-07-19 20:03:30.025 - OVOS - __main__:retrieve_from_corpus:37 - DEBUG - Rank 2 (score: 0.481589138507843): a fish is a creature that lives in water and swims
# a cat is a feline and likes to purr. a fish is a creature that lives in water and swims
Using BM25QACorpusSolver (Question/Answer Pairs)
This specialized solver matches the user's question to a question in the corpus and returns the corresponding answer.
import requests
from ovos_bm25_solver import BM25QACorpusSolver
# Load SQuAD dataset
corpus = {}
data = requests.get("https://github.com/chrischute/squad/raw/master/data/train-v2.0.json").json()
for s in data["data"]:
for p in s["paragraphs"]:
for qa in p["qas"]:
if "question" in qa and qa["answers"]:
corpus[qa["question"]] = qa["answers"][0]["text"]
# Load FreebaseQA dataset
data = requests.get("https://github.com/kelvin-jiang/FreebaseQA/raw/master/FreebaseQA-train.json").json()
for qa in data["Questions"]:
q = qa["ProcessedQuestion"]
a = qa["Parses"][0]["Answers"][0]["AnswersName"][0]
corpus[q] = a
# Initialize BM25QACorpusSolver with config
config = {
"lang": "en-us",
"min_conf": 0.4,
"n_answer": 1
}
solver = BM25QACorpusSolver(config)
solver.load_corpus(corpus)
query = "is there life on mars?"
answer = solver.get_spoken_answer(query)
print("Query:", query)
print("Answer:", answer)
# Expected Output:
# 86769 qa pairs imports from squad dataset
# 20357 qa pairs imports from freebaseQA dataset
# 2024-07-19 21:49:31.360 - OVOS - ovos_plugin_manager.language:create:233 - INFO - Loaded the Language Translation plugin ovos-translate-plugin-server
# 2024-07-19 21:49:31.360 - OVOS - ovos_plugin_manager.utils.config:get_plugin_config:40 - DEBUG - Loaded configuration: {'module': 'ovos-translate-plugin-server', 'lang': 'en-us'}
# 2024-07-19 21:49:32.759 - OVOS - __main__:load_corpus:61 - DEBUG - indexed 107126 documents
# Query: is there life on mars
# 2024-07-19 21:49:32.760 - OVOS - __main__:retrieve_from_corpus:70 - DEBUG - Rank 1 (score: 6.037893295288086): How is it postulated that Mars life might have evolved?
# 2024-07-19 21:49:32.760 - OVOS - __main__:retrieve_from_corpus:94 - DEBUG - closest question in corpus: How is it postulated that Mars life might have evolved?
# Answer: similar to Antarctic
In this example, BM25QACorpusSolver is used to load a large corpus of question-answer pairs from the SQuAD and FreebaseQA datasets. The solver retrieves the best matching answer for the given query.
Limitations of Retrieval Chatbots
Retrieval chatbots, while powerful, have certain limitations. These include:
- Dependence on Corpus Quality and Size: The accuracy of a retrieval chatbot heavily relies on the quality and comprehensiveness of the underlying corpus. A limited or biased corpus can lead to inaccurate or irrelevant responses.
- Static Knowledge Base: Unlike generative models, retrieval chatbots can't generate new information or answers. They can only retrieve and rephrase content from the pre-existing corpus.
- Contextual Understanding: While advanced algorithms like BM25 can rank documents based on relevance, they may still struggle with understanding nuanced or complex queries, especially those requiring deep contextual understanding.
- Scalability: As the size of the corpus increases, the computational resources required for indexing and retrieving relevant documents also increase, potentially impacting performance.
- Dynamic Updates: Keeping the corpus updated with the latest information can be challenging, especially in fast-evolving domains.
Despite these limitations, retrieval chatbots are effective for domains where the corpus is well-defined and relatively static, such as FAQs, documentation, and knowledge bases.
Example solvers
SquadQASolver
The SquadQASolver is a subclass of BM25QACorpusSolver that automatically loads and indexes the SQuAD dataset upon initialization.
This solver is suitable for usage with the ovos-persona framework.
from ovos_bm25_solver import SquadQASolver
s = SquadQASolver()
query = "is there life on mars"
print("Query:", query)
print("Answer:", s.spoken_answer(query))
# 2024-07-19 22:31:12.625 - OVOS - __main__:load_corpus:60 - DEBUG - indexed 86769 documents
# 2024-07-19 22:31:12.625 - OVOS - __main__:load_squad_corpus:119 - INFO - Loaded and indexed 86769 question-answer pairs from SQuAD dataset
# Query: is there life on mars
# 2024-07-19 22:31:12.628 - OVOS - __main__:retrieve_from_corpus:69 - DEBUG - Rank 1 (score: 6.334013938903809): How is it postulated that Mars life might have evolved?
# 2024-07-19 22:31:12.628 - OVOS - __main__:retrieve_from_corpus:93 - DEBUG - closest question in corpus: How is it postulated that Mars life might have evolved?
# Answer: similar to Antarctic
FreebaseQASolver
The FreebaseQASolver is a subclass of BM25QACorpusSolver that automatically loads and indexes the FreebaseQA dataset upon initialization.
This solver is suitable for usage with the ovos-persona framework.
from ovos_bm25_solver import FreebaseQASolver
s = FreebaseQASolver()
query = "What is the capital of France"
print("Query:", query)
print("Answer:", s.spoken_answer(query))
# 2024-07-19 22:31:09.468 - OVOS - __main__:load_corpus:60 - DEBUG - indexed 20357 documents
# Query: What is the capital of France
# 2024-07-19 22:31:09.468 - OVOS - __main__:retrieve_from_corpus:69 - DEBUG - Rank 1 (score: 5.996074199676514): what is the capital of france
# 2024-07-19 22:31:09.469 - OVOS - __main__:retrieve_from_corpus:93 - DEBUG - closest question in corpus: what is the capital of france
# Answer: paris
Integrating with Persona Framework
While this library is intended to use with your own corpus, it is possible to use the SquadQASolver and
FreebaseQASolver in the persona framework, you can define a persona configuration file and specify the solvers to be
used.
Here's an example of how to define a persona that uses the SquadQASolver and FreebaseQASolver:
- Create a persona configuration file, e.g.,
qa_persona.json:
{
"name": "QAPersona",
"solvers": [
"ovos-solver-squadqa-plugin",
"ovos-solver-freebaseqa-plugin",
"ovos-solver-failure-plugin"
]
}
- Run ovos-persona-server with the defined persona:
$ ovos-persona-server --persona qa_persona.json
In this example, the persona named "QAPersona" will first use the SquadQASolver to answer questions. If it cannot find
an answer, it will fall back to the FreebaseQASolver. Finally, it will use the ovos-solver-failure-plugin to ensure
it always responds with something, even if the previous solvers fail.
Check setup.py for reference in how to package your own corpus backed solvers
PLUGIN_ENTRY_POINTS = [
'ovos-solver-bm25-squad-plugin=ovos_bm25_solver:SquadQASolver',
'ovos-solver-bm25-freebase-plugin=ovos_bm25_solver:FreebaseQASolver'
]
Credits

This work was sponsored by VisioLab, part of Royal Dutch Visio, is the test, education, and research center in the field of (innovative) assistive technology for blind and visually impaired people and professionals. We explore (new) technological developments such as Voice, VR and AI and make the knowledge and expertise we gain available to everyone.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ovos_solver_bm25_plugin-0.1.0.tar.gz.
File metadata
- Download URL: ovos_solver_bm25_plugin-0.1.0.tar.gz
- Upload date:
- Size: 15.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
888c2c11472a8e3730287405a4fe18891cb1bdd32134deaa96685be8d422ab0e
|
|
| MD5 |
e5d527eb5695dfc0465da86df2ad1011
|
|
| BLAKE2b-256 |
a606356a3dcd437fd1923ab48b15ad5dc39b59dec8fe1f73b4190ee22f171e74
|
File details
Details for the file ovos_solver_bm25_plugin-0.1.0-py3-none-any.whl.
File metadata
- Download URL: ovos_solver_bm25_plugin-0.1.0-py3-none-any.whl
- Upload date:
- Size: 12.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
747d4387f5bbe6c70bd1890dce688fdec1e3f9a34cedfc7ca43d1d1d6b875c37
|
|
| MD5 |
8c317210d07c1faf317014627541ba1f
|
|
| BLAKE2b-256 |
d61be5bbb0bcd26df6832db4c7432864aa462b24115c3a65c4cec8b75d15d2b7
|







