Paddle-Pipelines: An End to End Natural Language Proceessing Development Kit Based on PaddleNLP

Project description
PaddleNLP Pipelines:NLP流水线系统
PaddleNLP Pipelines 是一个端到端NLP流水线系统框架,面向 NLP 全场景,帮助用户低门槛构建强大产品级系统。
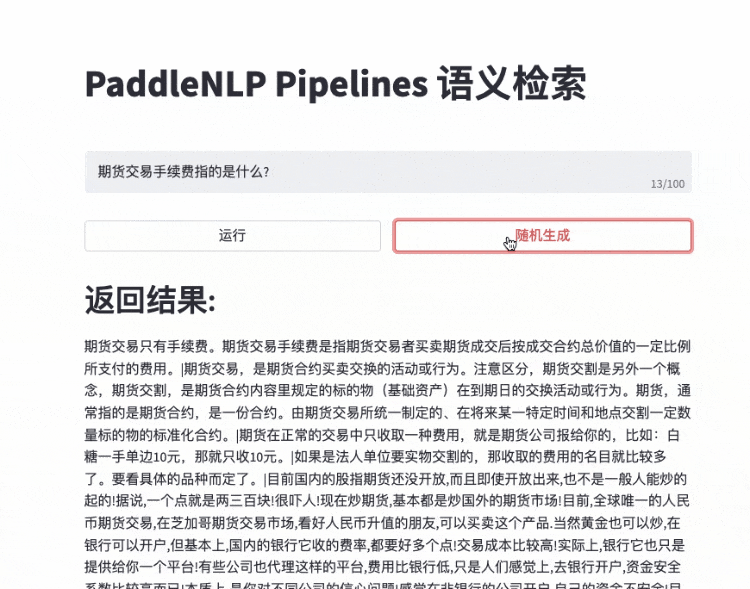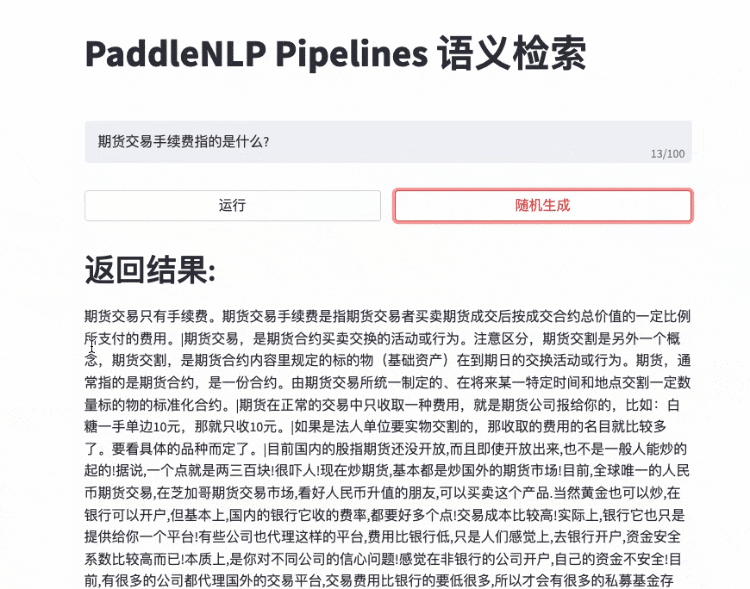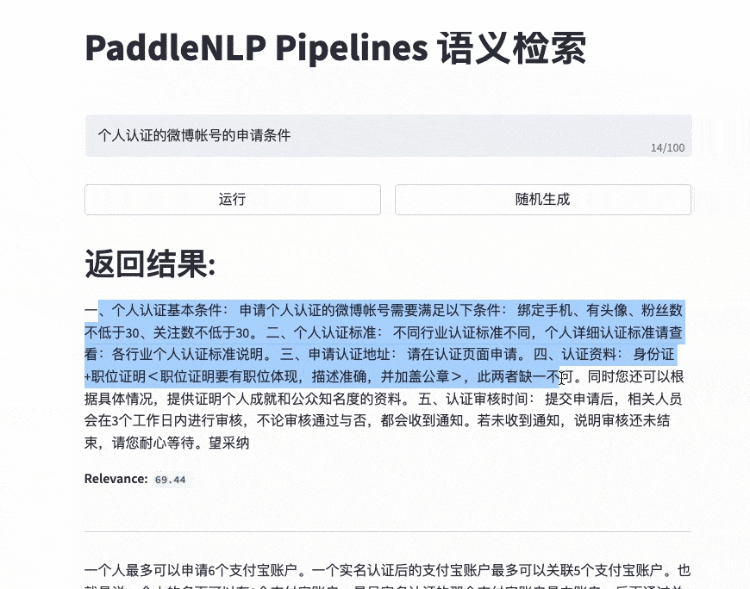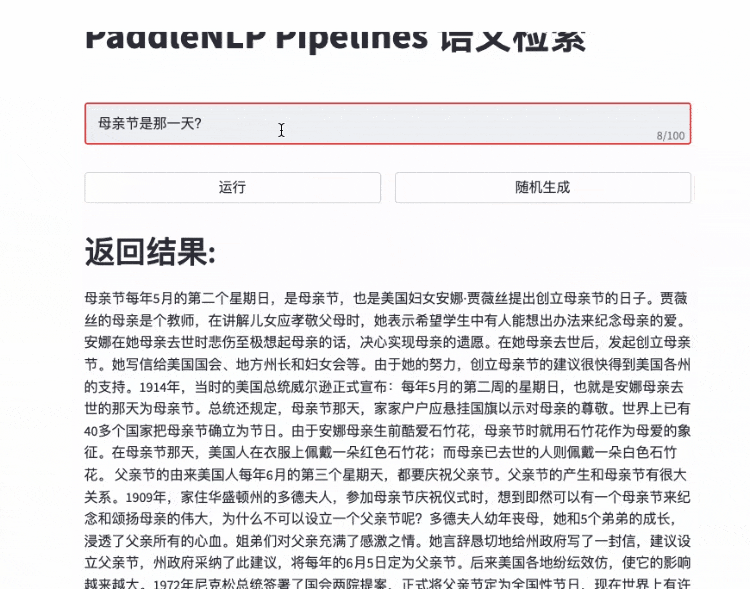
更多效果展示Demo请参考 效果展示
NLP流水线系统特色
-
全场景支持:依托灵活的插拔式组件产线化设计,支持各类 NLP 场景任务,包括:信息抽取、情感倾向分析、阅读理解、检索系统、问答系统、文本分类、文本生成等。
-
低门槛开发:依托丰富的预置组件,像搭积木一样快速构建产品级系统,预置组件覆盖文档解析、数据处理、模型组网、预测部署、Web 服务、UI 界面等全流程系统功能。
-
高精度预测:基于前沿的预训练模型、成熟的系统方案,可构建效果领先的产品级系统,如NLP流水线系统中预置的语义检索系统、阅读理解式智能问答系统等。
-
灵活可定制:除深度兼容 PaddleNLP 模型组件外,还可嵌入飞桨生态下任意模型、AI 开放平台算子、其它开源项目如 Elasticsearch 等作为基础组件,快速扩展,从而实现任意复杂系统的灵活定制开发。
Benchmarks
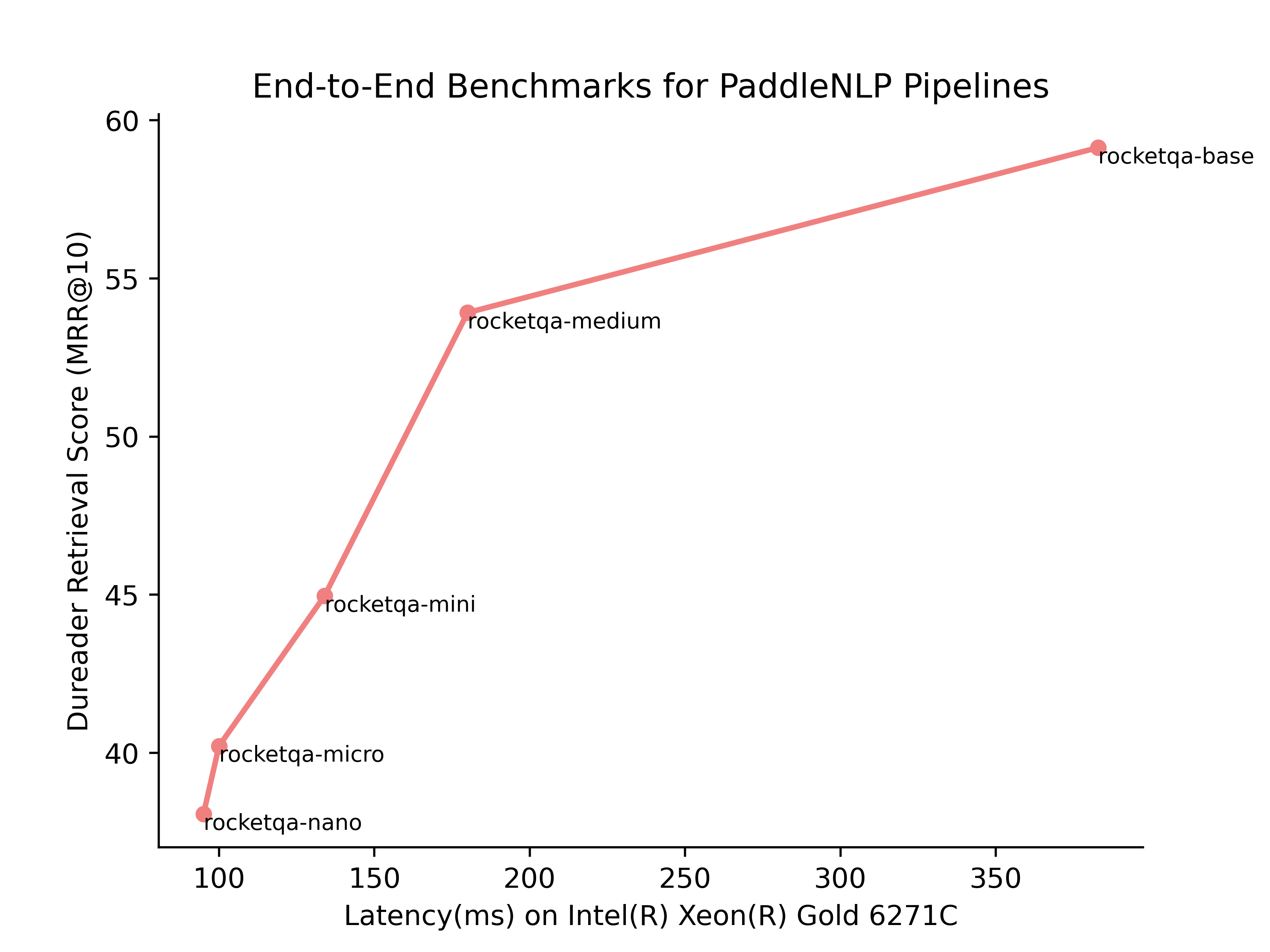
更多的Benchmarks的信息请参考文档Benchmarks
NLP流水线系统
PaddleNLP Pipelines NLP流水线系统针对 NLP 部分高频场景开源了经过充分打磨的产品级系统,并会不断开放其它场景的产品级系统,用户可以基于NLP流水线系统提供的系统能力快速开发出适配业务数据的产品。
- 快速搭建产品级语义检索系统:使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配
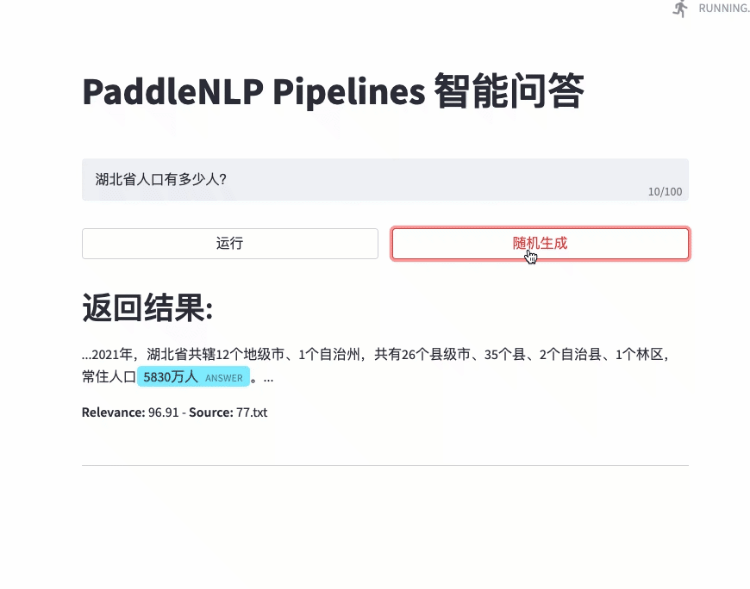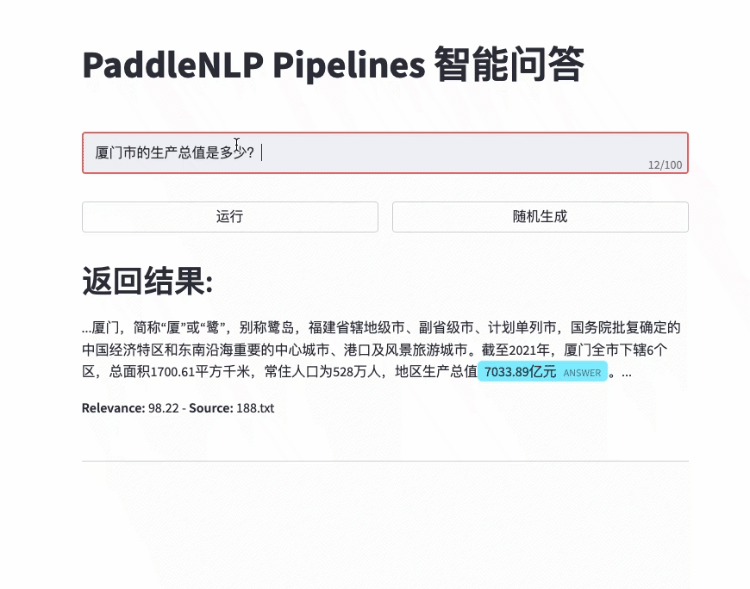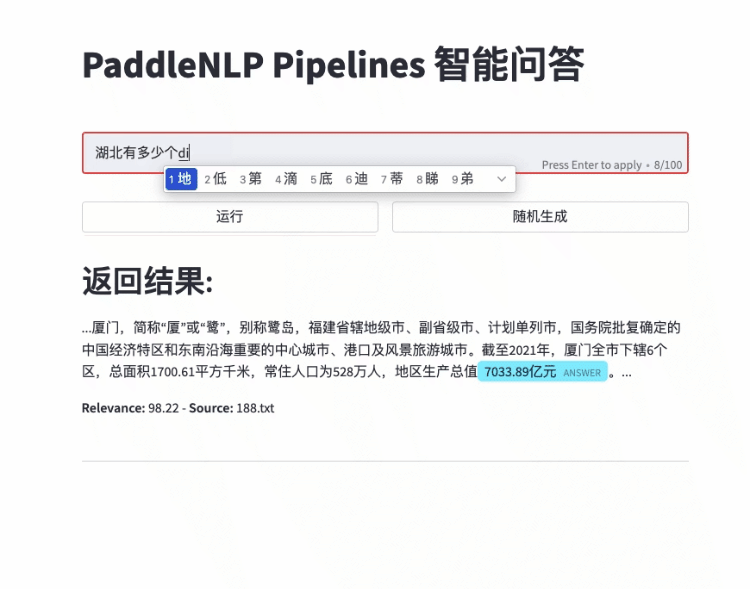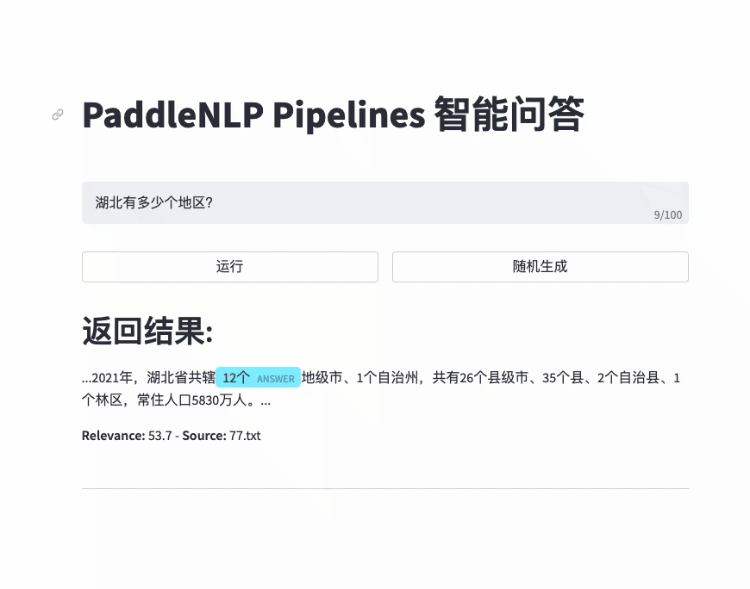
- 快速搭建产品级智能问答系统:用自然语言提问,即可获得精准答案片段
- 快速搭建产品级 FAQ 问答系统:用自然语言提问,匹配相关的高频问题,并返回匹配到的高频问题的答案
- 快速搭建产品级多模态信息抽取系统(即将开放,敬请期待)
效果展示
- 语义检索
- 智能问答
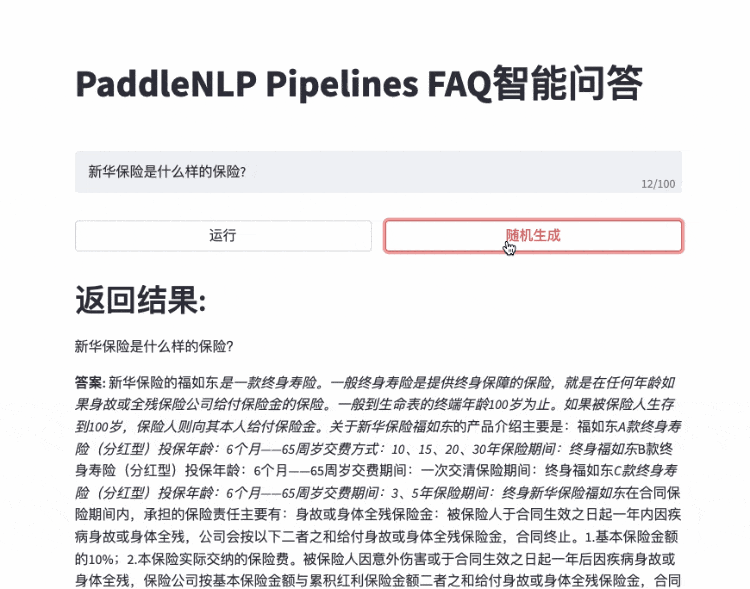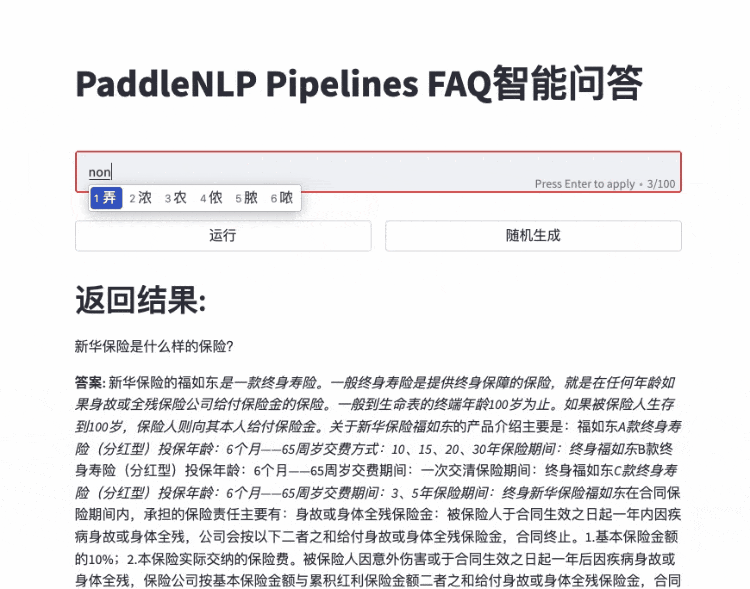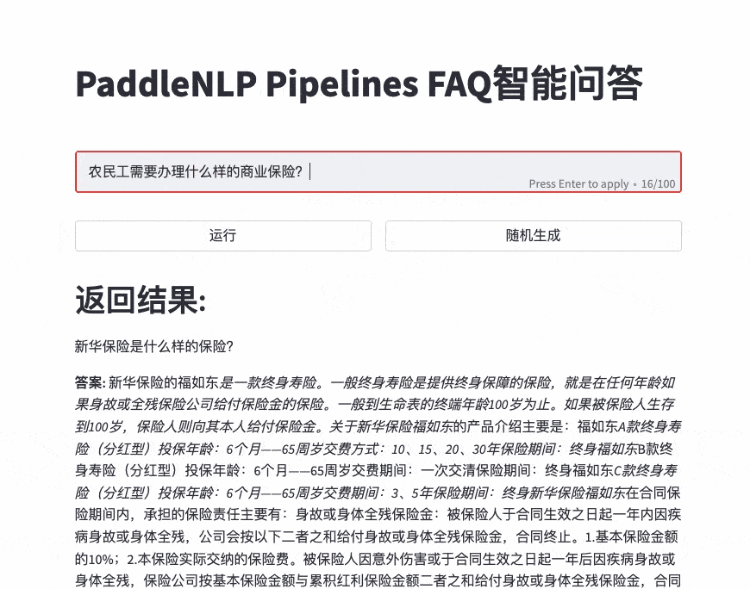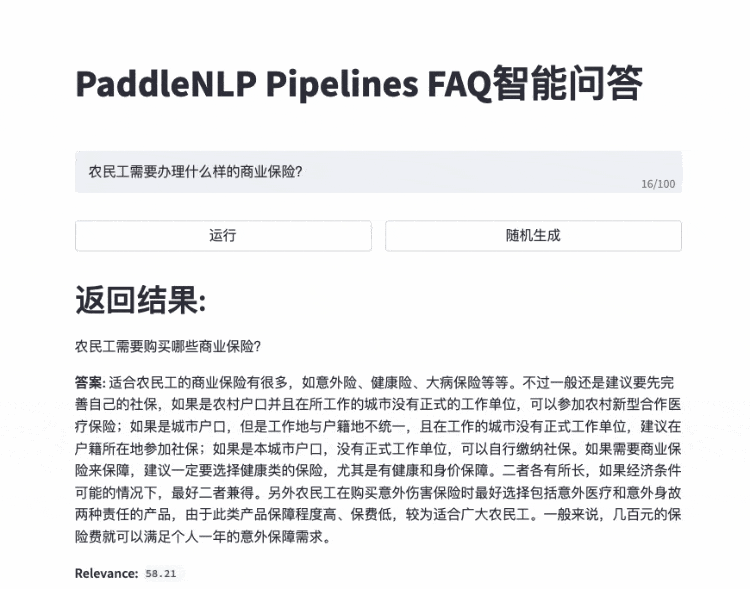
- FAQ智能问答
| :floppy_disk: 快速安装 | 安装 PaddleNLP Pipelines |
| :beginner: 快速体验 | 基于 Pipelines 快速搭建语义检索/智能问答等产品系统 |
| :man_office_worker: 用户案例 | 各行业用户基于PaddleNLP Pipelinse 构建的产品案例 |
| :mortar_board: Tutorials | 像搭积木一样一步步构建 NLP 流水线系统教程 |
| :bar_chart: Benchmarks | 针对各场景模型的性能、精度评测指标 |
| :telescope: Roadmap | PaddleNLP Pipelines 产品路线图 |
| :newspaper: 技术博客 | 阅读 PaddleNLP Pipelines 系列技术文章 |
| :vulcan_salute: 社区交流 | 官方微信群, GitHub Discussions |
:floppy_disk: 安装
Note: 因为 pipelines 依赖较多, 安装耗时大概 10 分钟左右,安装过程中请请耐心等待。
环境依赖
- python >= 3.7.3
- paddlenlp >= 2.2.1
- paddlepaddle >=2.3
- CUDA Version: 10.2
- NVIDIA Driver Version: 440.64.00
- Docker 18.03 以上
pip 安装
pip install --upgrade paddle-pipelines
源码安装
git clone https://github.com/PaddlePaddle/PaddleNLP.git
cd PaddleNLP/pipelines
python setup.py install
:beginner: 快速体验
快速开发
您可以参考如下示例像搭积木一样快速构建语义检索流水线,通过命令行终端输出快速体验流水线系统效果
from pipelines.document_stores import FAISSDocumentStore
from pipelines.nodes import DensePassageRetriever, ErnieRanker
# Step1: Preparing the data
documents = [
{'content': '金钱龟不分品种,只有生长地之分,在我国主要分布于广东、广西、福建、海南、香港、澳门等地,在国外主要分布于越南等亚热带国家和地区。',
'meta': {'name': 'test1.txt'}},
{'content': '衡量酒水的价格的因素很多的,酒水的血统(也就是那里产的,采用什么工艺等);存储的时间等等,酒水是一件很难标准化得商品,只要你敢要价,有买的那就值那个钱。',
'meta': {'name': 'test2.txt'}}
]
# Step2: Initialize a FaissDocumentStore to store texts of documents
document_store = FAISSDocumentStore(embedding_dim=768)
document_store.write_documents(documents)
# Step3: Initialize a DenseRetriever and build ANN index
retriever = DensePassageRetriever(document_store=document_store, query_embedding_model="rocketqa-zh-base-query-encoder",embed_title=False)
document_store.update_embeddings(retriever)
# Step4: Initialize a Ranker
ranker = ErnieRanker(model_name_or_path="rocketqa-base-cross-encoder")
# Step5: Initialize a SemanticSearchPipeline and ask questions
from pipelines import SemanticSearchPipeline
pipeline = SemanticSearchPipeline(retriever, ranker)
prediction = pipeline.run(query="衡量酒水的价格的因素有哪些?")
快速部署
您可以基于我们发布的 Docker 镜像一键部署智能文本流水线系统,通过 Web UI 快速体验。
启动 elastic search
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.3.3
docker run \
-d \
--name es02 \
--net elastic \
-p 9200:9200 \
-e discovery.type=single-node \
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"\
-e xpack.security.enabled=false \
-e cluster.routing.allocation.disk.threshold_enabled=false \
-it \
docker.elastic.co/elasticsearch/elasticsearch:8.3.3
部署 CPU 服务
对于Linux使用Docker的用户,使用下面的命令:
docker pull registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0
docker run -d --name paddlenlp_pipelines --net host -ti registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0
对于Windows&Macos上使用Docker的用户,用下面的命令:
docker pull registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin
docker run -d --name paddlenlp_pipelines -p 8891:8891 -p 8502:8502 -ti registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin
CPU 镜像下载大概耗时 10 分钟左右,容器启动成功后,等待3分钟左右,通过浏览器访问 http://127.0.0.1:8502 快速体验产品级语义检索服务。
部署 GPU 服务
docker pull registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7
nvidia-docker run -d --name paddlenlp_pipelines_gpu --net host -ti registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7
GPU 镜像下载大概耗时 15 分钟左右,容器启动成功后,等待1分钟左右,通过浏览器访问 http://127.0.0.1:8502 快速体验产品级语义检索服务。
对于国内用户,因为网络问题下载docker比较慢时,可使用百度提供的镜像:
| 环境 | 镜像 Tag | 运行平台 |
|---|---|---|
| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0 | Linux |
| CPU | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
| CUDA10.2 + cuDNN 7 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
| CUDA11.2 + cuDNN 8 | registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
如果您的机器不在中国大陆地区,我们推荐您使用DockerHub的镜像:
| 环境 | 镜像 Tag | 运行平台 |
|---|---|---|
| CPU | paddlepaddle/paddlenlp:2.4.0 | Linux |
| CPU | paddlepaddle/paddlenlp:2.4.0.windows.darwin | Windows&Macos |
| CUDA10.2 + cuDNN 7 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda10.2-cudnn7 | Linux |
| CUDA11.2 + cuDNN 8 | paddlepaddle/paddlenlp:2.4.0-gpu-cuda11.2-cudnn8 | Linux |
对于智能问答应用,请参考Docker文档docker文档,只需做少量的修改,就可以完成智能问答应用的部署。
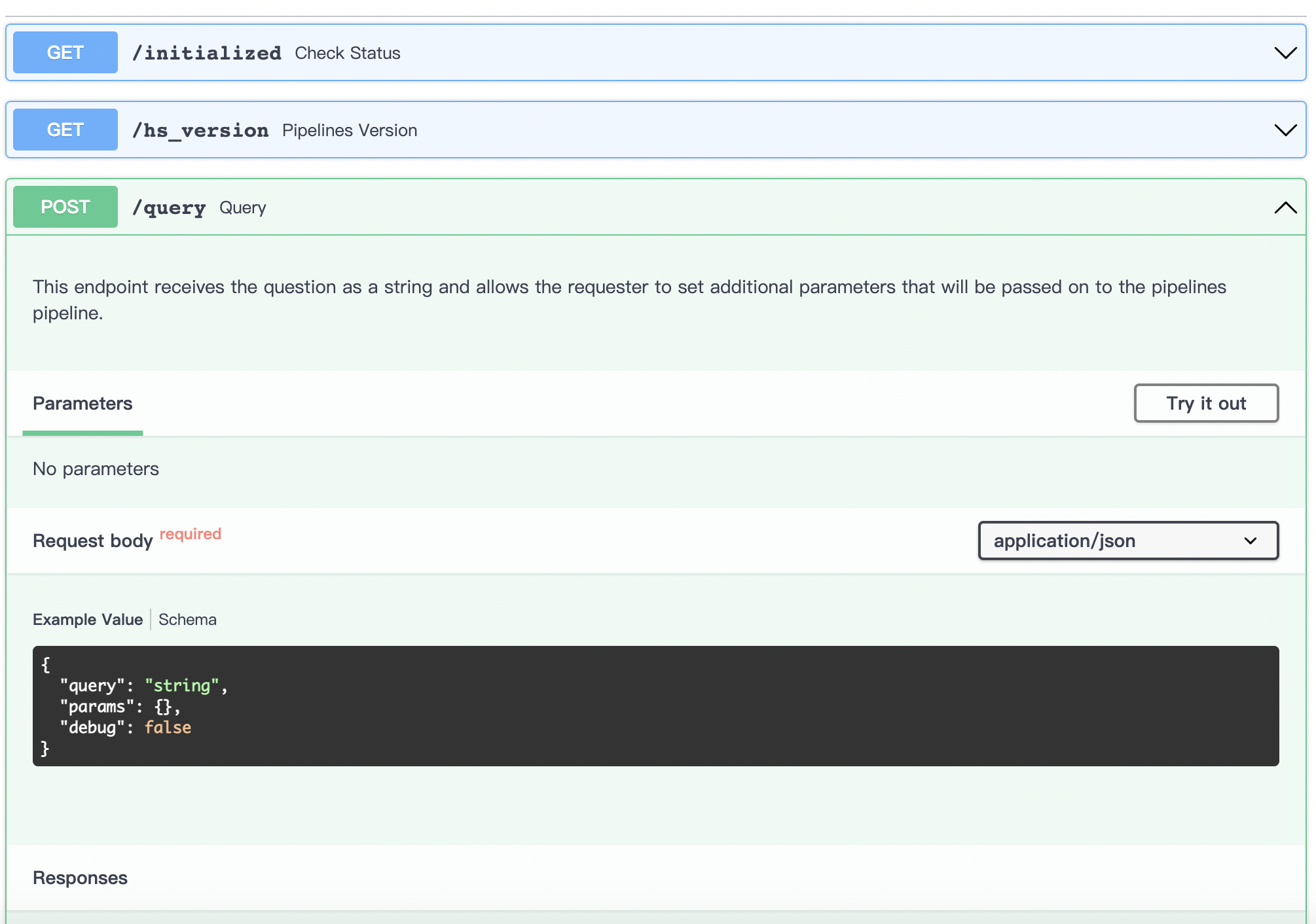
REST API
Pipelines可以服务化,通过HTTP接口的形式供其他程序进行调用,Pipelines提供了Swagger API方便用户查询接口文档,从而把Pipelines的能力接入到自己的应用系统中,只需要在启动REST API后通过浏览器访问 http://127.0.0.1:8891/docs
:man_office_worker: 用户案例
案例1: 寻规-工程规范搜索引擎
寻规,是一款基于飞桨 PaddleNLP Pipelines 构建的建筑工程规范搜索引擎。大幅提升了工程设计人员工作效率。
查询效率提升 36~60 倍
相比市面当前的工程规范查询系统/网站,平均查询到一条规范条款要 3~5 分钟,而基于 PaddleNLP Pipelines 构建的寻规检索系统,平均查询到一条规范条款仅需 5 秒左右,搜索时间大幅缩短,仅规范查询效率方面就提升36~60 倍!
查询精度大幅提升
市面现已有的工程规范查询系统解决方案一直延续着传统关键字词匹配的查询方式,依赖用户对查询结果进行自行排序、筛选、鉴别,有时甚至还要再次由工程设计人员耗费一定时间精力人工查阅工程规范文件后,才能最终确认是否为想要查询的规范条款。传统规范查询系统至少需要进行 3~5 次查询才能找到用户想要的规范条款,而寻规系统是基于强大预训练模型构建起来的语义检索系统,针对 80% 的规范查询需求仅 1 次查询 就能精确命中查询意图,并返回真正符合工程设计人员查询意图的结果!
:mortar_board: Tutorials
- Tutorial 1 - Pipelines Windows视频安装教程
- Tutorial 2 - 语义检索 Pipeline: AIStudio notebook | Python
- Tutorial 3 - 智能问答 Pipeline: AIStudio notebook | Python
- Tutorial 4 - FAQ智能问答 Pipeline: AIStudio notebook | Python
- Tutorial 5 - Pipelines 快速上手二次开发教程: AIStudio notebook
:vulcan_salute: 社区交流
微信扫描二维码并填写问卷之后,加入交流群与来自各行各业的小伙伴交流学习吧~

:heart: Acknowledge
我们借鉴了 Deepset.ai Haystack 优秀的框架设计,在此对Haystack作者及其开源社区表示感谢。
We learn form the excellent framework design of Deepset.ai Haystack, and we would like to express our thanks to the authors of Haystack and their open source community.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file paddle-pipelines-0.6.2.tar.gz.
File metadata
- Download URL: paddle-pipelines-0.6.2.tar.gz
- Upload date:
- Size: 248.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3b0f0bc43e409eb1fe6ec9f6655c85ae94907fcd38905e7686e873255caf32fc
|
|
| MD5 |
307bd3d59c61678651eb0b0cec686335
|
|
| BLAKE2b-256 |
87d03585cfb0635dda0107f6f33caf57e4196a07d63fb6f2eb59fed29f9b62c7
|
File details
Details for the file paddle_pipelines-0.6.2-py3-none-any.whl.
File metadata
- Download URL: paddle_pipelines-0.6.2-py3-none-any.whl
- Upload date:
- Size: 346.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
806ef386865b71189de9f068905a7cffd90cb054eb744c1de275b9d6aadc2acc
|
|
| MD5 |
c34840bde709a882869c17aae87750a9
|
|
| BLAKE2b-256 |
d01fc555c380d5e0dbcb110e860d45657710ae50e45659320b7aca5645ed3caa
|







