PDF text extractor.

Project description
pdftxt
The goal of this project is to provide an api to extract text from specific regions of a pdf document/page and a cli to assist identifying the location of text within a document.
Installation
... pip install pdftxt
Basic Command Line Usage
Let's say we have a PDF file (PDF-DOC.pdf) that looks like this:

The pdftxt command:
... pdftxt PDF-DOC.pdf
Will output a visual layout of the pdf document's pages and text elements to an html page:
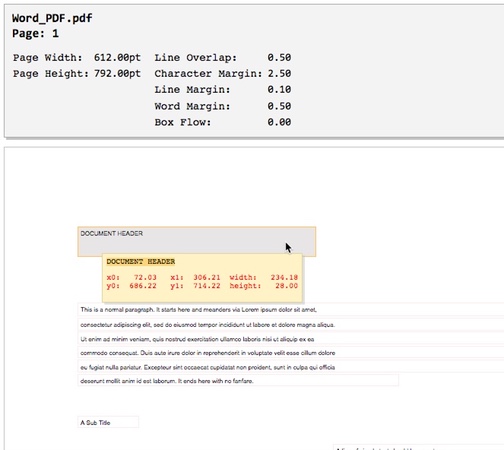
API Usage
from pathlib import Path
from pdftxt import api
filepath = 'tests/Word_PDF.pdf'
with api.PdfTxtContext(filepath) as pdf:
for page in pdf:
# To fetch text objects from specific region
# of the page, first define the region:
region = api.Region(400, 300, 512, 317)
# Initialize layout parameters:
params = api.PdfTxtParams()
# Then analyze that area of the page for text objects:
text = page.analyze(region, params)
# Do whatever it is we need to do with the results:
for txt in text:
print(txt.text)


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pdftxt-0.3.2.tar.gz.
File metadata
- Download URL: pdftxt-0.3.2.tar.gz
- Upload date:
- Size: 13.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/0.12.11 CPython/3.6.2 Darwin/17.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
768cbd8caa754493d58100bca3ee97bf423f14212e93164169549a83a358bf83
|
|
| MD5 |
e6c1b66a5860bb8a5b38a8d13f4a38a1
|
|
| BLAKE2b-256 |
921d4d6702d16e9db6994a4cacf9daba215093deb0d380c2cdf3e616e1b0c7d7
|
File details
Details for the file pdftxt-0.3.2-py3-none-any.whl.
File metadata
- Download URL: pdftxt-0.3.2-py3-none-any.whl
- Upload date:
- Size: 44.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/0.12.11 CPython/3.6.2 Darwin/17.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d80ae0dc3a33b097d2ca7f51fb97db4451287cc75c49078c29544cce0d1f6bec
|
|
| MD5 |
1a437ab1cdcb8944da2fe64b06db0cfe
|
|
| BLAKE2b-256 |
9e2751efbdc795d4a83435da586cbe154946627ff879c99f616cd5487c93ce8a
|







